audio2img
1.0.0
Этот проект направлен на то, чтобы точно настроить модель звука wav2vec2bert Audio Encoder, чтобы создать аудио встраивания, которые можно использовать вместо традиционного энкодера текста клипа . Интегрируя аудио встраивания, мы можем использовать уникальные свойства аудиоданных, чтобы разблокировать новые возможности для стабильных диффузионных моделей.

? Модель на обнимающем лицо | Тренировочный блокнот
Аудио содержит огромное количество информации, которая часто остается неиспользованной, выходящей далеко за рамки того, что мы обычно представляем. С ростом моделей скрытой диффузии и их впечатляющими генеративными возможностями, существует растущий интерес к изучению различных методов обучения. Наиболее распространенный подход включает в себя использование энкодеров CLIP (контрастного языкового изображения). Тем не менее, аудиоданные предлагают богатый и многогранный источник информации, который может значительно улучшить процесс кондиционирования.







Основной идеей нашего обучения является достижение межмодального выравнивания между аудио и текстовыми встроениями с использованием двухсторонней архитектуры . Это включает в себя использование мощного ClipTextModel для генерации текстовых встроений, которые служат истинными метками для аудио встраивания, созданных нашей моделью Wav2Vec2bert . Вот подробное объяснение:
Архитектура с двумя потоками:
- Поток текста: мы используем ClipTextModel для генерации текстовых встроений для данных текстовых вводов. Эти встраивания отражают богатую семантическую информацию и служат основными ярлыками истины .
- Audio Stream: наша модель Wav2vec2bert Использует энкодер для сверточной функции, за которым следует сеть трансформатора для процессов аудио входов и генерирования соответствующих аудио встраиваний.
Выравнивание кросс-модальности:
- Objectif: Основная цель обучения - выравнивать аудио встраивания с текстами встроенных в общее пространство встраивания . Это гарантирует, что семантически похожие аудио и текстовые входы отображаются рядом друг с другом.
-Функция потерь: мы достигаем этого выравнивания, используя контрастные потери , что побуждает модель привязывать встроенные встроенные аудио текстовые пары, разделяя встроенные встроенные пары.
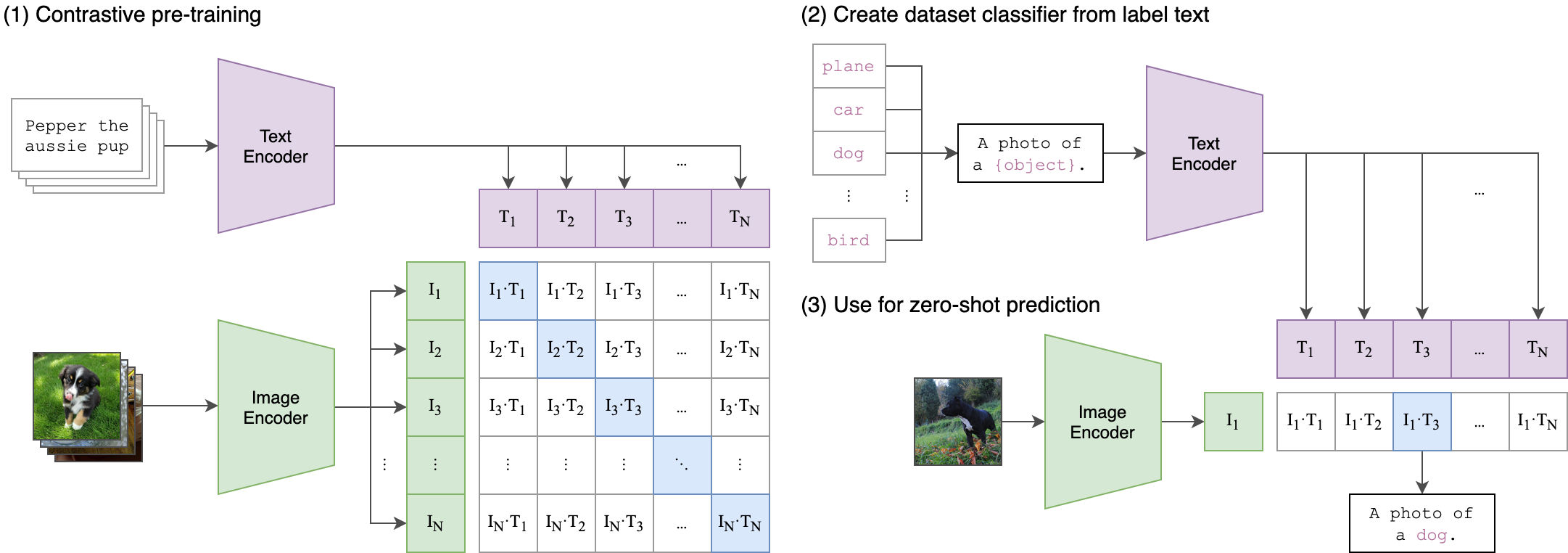
Это похоже на то, как оригинальная модель клипа была обучена выравниванию пар изображений. Разница состоит в том, что в модели клипа Openai контрастирующие потери были рассчитаны с использованием токена [CLS] , в то время как мы будем применять контрастные потери на уровне последовательности .
Это изображение может объяснить логику этой потери:
Библиотека Трансформеров использовалась для обучения. «Facebook/W2V-BERT-2.0». Контрольная точка была загружена в качестве начальной предварительной модели. Подготовка данных, детали обучения и используемые гиперпараметры можно найти в ноутбуке Train_me.ipynb :
model = Wav2Vec2BertModel . from_pretrained (
"facebook/w2v-bert-2.0" ,
add_adapter = True ,
adapter_kernel_size = 3 ,
adapter_stride = 2 ,
num_adapter_layers = 2 ,
layerdrop = 0.0 ,
) def Contrastive_loss ( embeddings1 , embeddings2 , temperature = 0.15 ):
cos_sim = torch . cosine_similarity ( embeddings1 . unsqueeze ( 1 ), embeddings2 . unsqueeze ( 0 ), dim = - 1 )
cos_sim = cos_sim / temperature
labels = torch . arange ( embeddings1 . size ( 0 )). unsqueeze ( 1 ). repeat ( 1 , embeddings1 . size ( 1 )). to ( embeddings1 . device )
loss = F . cross_entropy ( cos_sim , labels )
return loss
class TrainBert ( Trainer ):
def __init__ ( self , * args , ** kwargs ):
super (). __init__ ( * args , ** kwargs )
def compute_loss ( self , model , inputs , return_outputs = False ):
labels = inputs . pop ( "text_embeddings" )
outputs = model ( ** inputs )
outputs = outputs . last_hidden_state
loss = Contrastive_loss ( outputs , labels )
outputs = ( loss , outputs )
return outputs if return_outputs else lossNB: Размер партии является важным гиперпараметром для настройки, так как он определяет, сколько отрицательных образцов передается в модель.
pip install -r requirements.txtCKPT 1728 или CKPT 2016
Wav2Vec2BertModel . from_pretrained ( 'youzarsif/wav2vec2bert_2_diffusion' )или
Wav2Vec2BertModel . from_pretrained ( 'youzarsif/wav2vec2bert_2_diffusion_ckpt_1728' )Не стесняйтесь использовать любые вариации стабильной диффузии , контрольной сети или аналогичных моделей, если они используют один и тот же энкодер .
StableDiffusionPipeline . from_pretrained ( "stabilityai/stable-diffusion-2-1" )python3 app.pyПрямо построить и запустить изображение Docker:
docker build -t app.py .
docker run -p 7860:7860 app.py Во время обучения было отмечено, что используемый набор данных был плохо аннотирован и полагался на общие этикетки. Использование более разнообразного и хорошо подтвержденного набора данных повысит производительность модели.
Кроме того, из -за ограничений ресурсов использовался небольшой сверток адаптер. Использование большего адаптера в соответствии с длиной максимальной последовательности клипа может действительно улучшить производительность модели, поскольку он позволяет модели собирать больше информации.
https://github.com/stability-ai/stablediffusion/tree/main
https://github.com/openai/clip/tree/main
https://huggingface.co/docs/transformers/en/model_doc/wav2vec2-bert


