audio2img
1.0.0
Dieses Projekt zielt darauf ab, ein WAV2VEC2BERT- Audio-Encoder-Modell zu optimieren, um Audio-Einbettungen zu generieren, die anstelle des herkömmlichen Clip- Text-Encoders verwendet werden können. Durch die Integration von Audio -Einbettungen können wir die einzigartigen Eigenschaften von Audiodaten nutzen, um neue Möglichkeiten für stabile Diffusionsmodelle freizuschalten.

? Modell auf Umarmung Face | Schulungsnotizbuch
Audio enthält eine Fülle von Informationen, die oft ungenutzt werden und weit über das hinausgehen, was wir normalerweise vorstellen. Mit dem Aufkommen latenter Diffusionsmodelle und ihren beeindruckenden generativen Fähigkeiten besteht ein wachsendes Interesse an der Erforschung verschiedener Konditionstechniken. Der häufigste Ansatz besteht darin, Textcodierer der CLIP (kontrastive Sprachbild-Voraberziehung) zu verwenden, um das Modell zu konditionieren. Audiodaten bieten jedoch eine reichhaltige und facettenreiche Informationsquelle, die den Konditionierungsprozess erheblich verbessern kann.







Die Kernidee hinter unserem Trainingsprozess besteht darin, eine quermodale Ausrichtung zwischen Audio- und Texteinbettungen mithilfe einer Zwei-Stream-Architektur zu erreichen. Dies beinhaltet die Nutzung des leistungsstarken ClipTextModel , um Texteinbettungen zu generieren, die als echte Bezeichnungen für die Audio -Einbettungen dienen, die von unserem WAV2V2VEC2bert -Modell erstellt wurden. Hier ist eine detaillierte Erklärung:
Zwei-Stream-Architektur:
- Textstream: Wir verwenden das ClipTextModel , um Texteinbettungen für bestimmte Texteingaben zu generieren. Diese Einbettungen erfassen reiche semantische Informationen und dienen als Bodenwahrheitsbezeichnungen .
- Audio -Stream: Unser WAV2VEC2BERT -Modell Verwenden Sie Faltungsfunktionscodierer, gefolgt von einem Transformator -Netzwerk, um Audioeingänge zu verarbeiten und entsprechende Audio -Einbettungen zu generieren.
Cross-Modality-Ausrichtung:
- Objektiv: Das Hauptziel des Trainings ist es, die Audio -Einbettungen mit den Texteinbettungen in einem gemeinsamen Einbettungsraum auszurichten. Dies stellt sicher, dass semantisch ähnliche Audio- und Texteingaben nahe beieinander abgebildet sind.
.
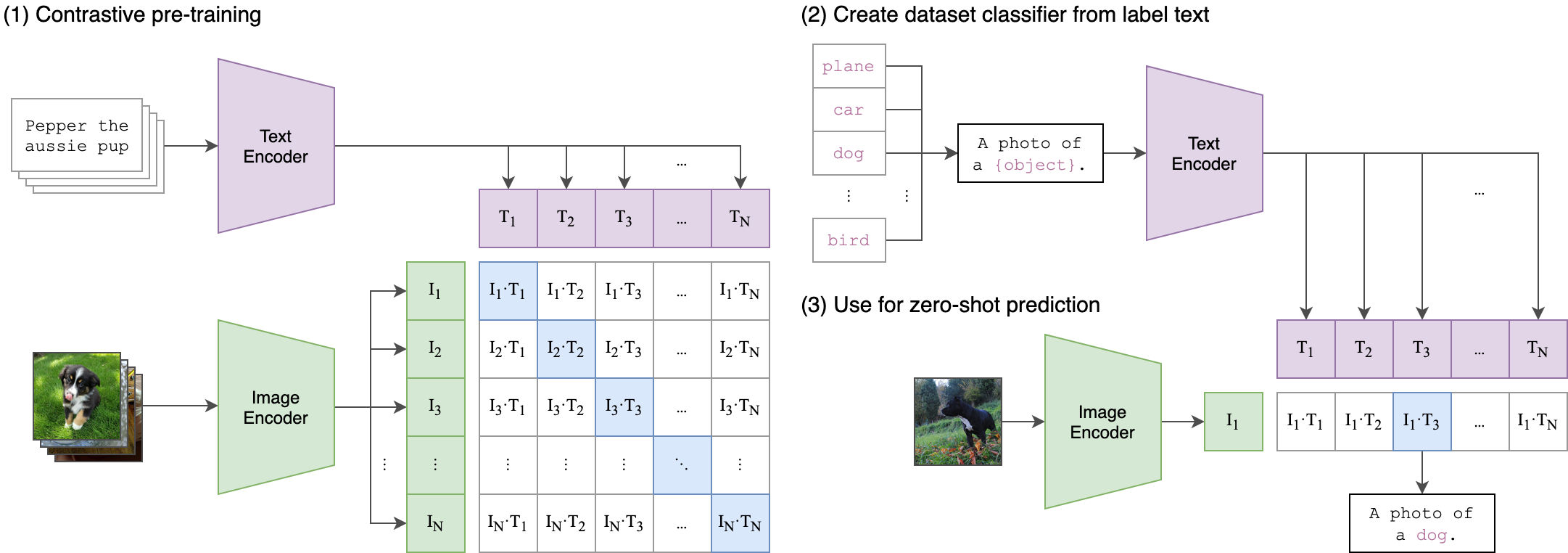
Dies ist ähnlich wie das Original -Clip- Modell geschult wurde, um Bild-Text-Paare auszurichten. Der Unterschied besteht darin, dass im OpenAI -Clip -Modell kontrastive Verlust unter Verwendung des [CLS] -Tokens berechnet wurde, während wir kontrastiven Verlust auf Sequenzebene anwenden werden.
Dieses Bild kann die Logik hinter diesem Verlust erklären:
Die Transformers Library wurde für das Training verwendet. "Facebook/W2V-Bert-2.0" wurde als anfängliches Modell geladen. Datenvorbereitung, Trainingsdetails und die verwendeten Hyperparameter finden Sie im Notebook für train_me.ipynb :
model = Wav2Vec2BertModel . from_pretrained (
"facebook/w2v-bert-2.0" ,
add_adapter = True ,
adapter_kernel_size = 3 ,
adapter_stride = 2 ,
num_adapter_layers = 2 ,
layerdrop = 0.0 ,
) def Contrastive_loss ( embeddings1 , embeddings2 , temperature = 0.15 ):
cos_sim = torch . cosine_similarity ( embeddings1 . unsqueeze ( 1 ), embeddings2 . unsqueeze ( 0 ), dim = - 1 )
cos_sim = cos_sim / temperature
labels = torch . arange ( embeddings1 . size ( 0 )). unsqueeze ( 1 ). repeat ( 1 , embeddings1 . size ( 1 )). to ( embeddings1 . device )
loss = F . cross_entropy ( cos_sim , labels )
return loss
class TrainBert ( Trainer ):
def __init__ ( self , * args , ** kwargs ):
super (). __init__ ( * args , ** kwargs )
def compute_loss ( self , model , inputs , return_outputs = False ):
labels = inputs . pop ( "text_embeddings" )
outputs = model ( ** inputs )
outputs = outputs . last_hidden_state
loss = Contrastive_loss ( outputs , labels )
outputs = ( loss , outputs )
return outputs if return_outputs else lossNB: Die Batchgröße ist ein entscheidender Hyperparameter , um zu stimmen, wie viele negative Proben an das Modell übergeben werden.
pip install -r requirements.txtCKPT 1728 oder CKPT 2016
Wav2Vec2BertModel . from_pretrained ( 'youzarsif/wav2vec2bert_2_diffusion' )oder
Wav2Vec2BertModel . from_pretrained ( 'youzarsif/wav2vec2bert_2_diffusion_ckpt_1728' )Fühlen Sie sich frei, jede Variation stabiler Diffusion , Steuerung oder ähnlichen Modellen zu verwenden, solange sie denselben Clip -Encoder verwenden.
StableDiffusionPipeline . from_pretrained ( "stabilityai/stable-diffusion-2-1" )python3 app.pyErstellen und führen Sie das Docker -Bild direkt auf:
docker build -t app.py .
docker run -p 7860:7860 app.py Während des Trainings wurde festgestellt, dass der verwendete Datensatz schlecht kommentiert war und sich auf generische Etiketten stützte. Die Verwendung eines vielfältigeren und gut elektrischen Datensatzes erhöht die Leistung des Modells.
Darüber hinaus wurde aufgrund von Ressourcenbeschränkungen ein kleiner Faltungsadapter verwendet. Die Verwendung eines größeren Adapters für die Übereinstimmung mit der MAX -Sequenzlänge von Clip kann tatsächlich die Modellleistung verbessern, da das Modell mehr Informationen erfassen kann.
https://github.com/stability-ai/stablediffusion/tree/main
https://github.com/openai/clip/tree/main
https://huggingface.co/docs/transformers/en/model_doc/wav2vec2-tbert


