audio2img
1.0.0
يهدف هذا المشروع إلى ضبط نموذج تشفير الصوت WAV2VEC2BERT لإنشاء تضمينات صوتية يمكن استخدامها بدلاً من ترميز نص مقطع تقليدي. من خلال دمج تضمينات الصوت ، يمكننا الاستفادة من الخصائص الفريدة لبيانات الصوت لإلغاء تأمين إمكانيات جديدة لنماذج الانتشار المستقرة .

؟ نموذج على معانقة الوجه | دفتر التدريب
يحتوي الصوت على ثروة من المعلومات التي غالبًا ما لا يتم استغلالها ، ويمتد إلى أبعد من ما نتخيله عادة. مع ظهور نماذج الانتشار الكامنة وقدراتها التوليدية المثيرة للإعجاب ، هناك اهتمام متزايد باستكشاف تقنيات تكييف متنوعة. ينطوي النهج الأكثر شيوعًا على استخدام مشابك (صورة ما قبل التدريب اللغوية المتباينة) لشرح النموذج. ومع ذلك ، توفر بيانات الصوت مصدرًا غنيًا ومتعدد الأوجه للمعلومات يمكن أن يعزز عملية التكييف بشكل كبير.







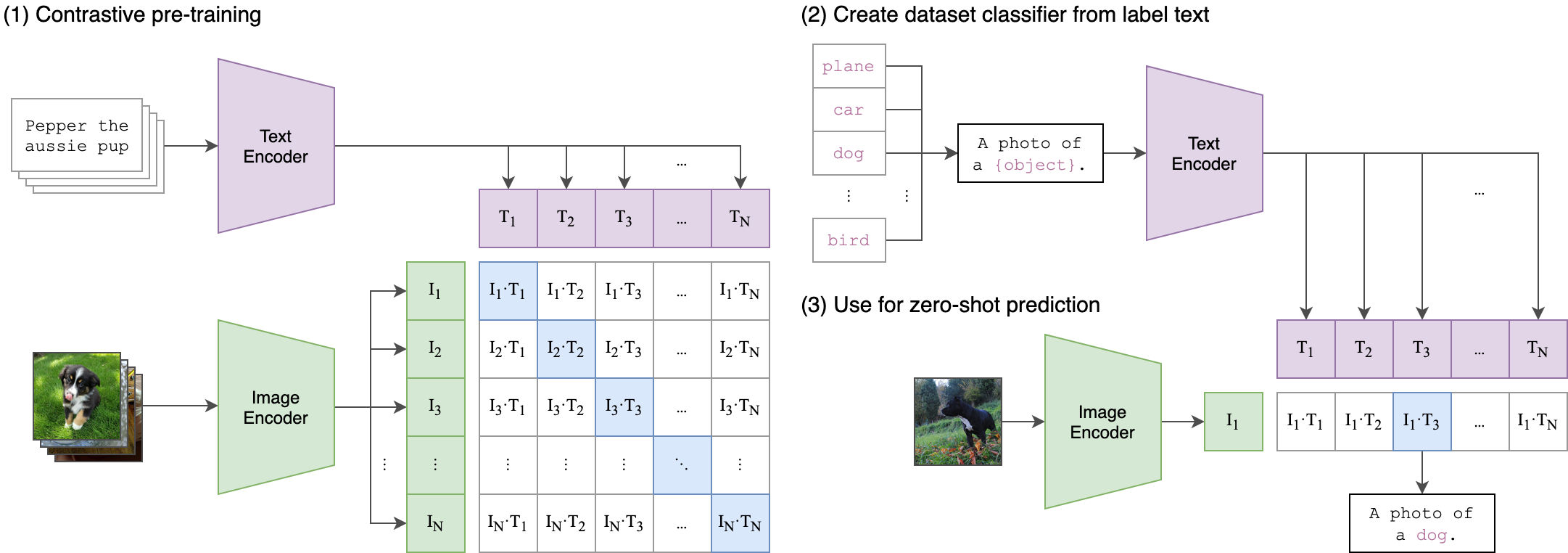
تتمثل الفكرة الأساسية وراء عملية التدريب لدينا في تحقيق توافق عبر الوسائط بين تضمينات الصوت والنص باستخدام بنية ثنائية المباراة . يتضمن ذلك الاستفادة من ClipTextModel القوي لإنشاء تضمينات نصية تعمل كعلامات حقيقية للتضمينات الصوتية التي ينتجها نموذج WAV2VEC2BERT الخاص بنا. إليك شرح مفصل:
الهندسة المعمارية ذات الثياب:
- دفق النص: نستخدم ClipTextModel لإنشاء تضمينات نصية لإدخال نص معين. هذه التضمينات تلتقط المعلومات الدلالية الغنية وتكون بمثابة ملصقات الحقيقة الأرضية .
- دفق الصوت: استخدم نموذج WAV2VEC2BERT الخاص بنا تشفير الميزات التلافيفية تليها شبكة محولات لمعالجة المدخلات الصوتية وإنشاء تضمينات الصوت المقابلة.
محاذاة العرض المتقاطع:
- الكائن: الهدف الأساسي للتدريب هو محاذاة تضمينات الصوت مع تضمينات النص في مساحة تضمين مشتركة . هذا يضمن أن يتم تعيين مدخلات الصوت والنص المشابهة بشكل دلالي بالقرب من بعضها البعض.
-وظيفة الخسارة: نحقق هذه المحاذاة باستخدام فقدان التباين الذي يشجع النموذج على جعل تضمينات مطابقة أزواج النص الصوتي أقرب مع الانفصال عن تضمينات الأزواج غير المتطابقة.
هذا مشابه لكيفية تدريب طراز المقطع الأصلي لمحاذاة أزواج نص الصورة. الفرق هو أنه في نموذج مقطع Openai ، تم حساب فقدان التباين باستخدام رمز [CLS] ، بينما سنطبق فقدان التباين على مستوى التسلسل .
يمكن أن تفسر هذه الصورة المنطق وراء هذه الخسارة:
تم استخدام مكتبة Transformers للتدريب. تم تحميل نقطة التفتيش "Facebook/W2V-Bert-2.0" كنموذج مبني أولي. يمكن العثور على إعداد البيانات ، وتفاصيل التدريب ، ومفرطات الفصائل المستخدمة في دفتر Train_me.ipynb :
model = Wav2Vec2BertModel . from_pretrained (
"facebook/w2v-bert-2.0" ,
add_adapter = True ,
adapter_kernel_size = 3 ,
adapter_stride = 2 ,
num_adapter_layers = 2 ,
layerdrop = 0.0 ,
) def Contrastive_loss ( embeddings1 , embeddings2 , temperature = 0.15 ):
cos_sim = torch . cosine_similarity ( embeddings1 . unsqueeze ( 1 ), embeddings2 . unsqueeze ( 0 ), dim = - 1 )
cos_sim = cos_sim / temperature
labels = torch . arange ( embeddings1 . size ( 0 )). unsqueeze ( 1 ). repeat ( 1 , embeddings1 . size ( 1 )). to ( embeddings1 . device )
loss = F . cross_entropy ( cos_sim , labels )
return loss
class TrainBert ( Trainer ):
def __init__ ( self , * args , ** kwargs ):
super (). __init__ ( * args , ** kwargs )
def compute_loss ( self , model , inputs , return_outputs = False ):
labels = inputs . pop ( "text_embeddings" )
outputs = model ( ** inputs )
outputs = outputs . last_hidden_state
loss = Contrastive_loss ( outputs , labels )
outputs = ( loss , outputs )
return outputs if return_outputs else lossNB: حجم الدُفعة هو مقياس فرطمي حاسم لضبطه ، لأنه يحدد عدد العينات السلبية التي يتم تمريرها إلى النموذج.
pip install -r requirements.txtCKPT 1728 أو CKPT 2016
Wav2Vec2BertModel . from_pretrained ( 'youzarsif/wav2vec2bert_2_diffusion' )أو
Wav2Vec2BertModel . from_pretrained ( 'youzarsif/wav2vec2bert_2_diffusion_ckpt_1728' )لا تتردد في استخدام أي اختلاف في الانتشار المستقر ، أو ControlNet ، أو نماذج مماثلة ، طالما أنها تستخدم نفس تشفير القصاصة .
StableDiffusionPipeline . from_pretrained ( "stabilityai/stable-diffusion-2-1" )python3 app.pyبناء وتشغيل صورة Docker مباشرة:
docker build -t app.py .
docker run -p 7860:7860 app.py أثناء التدريب ، لوحظ أن مجموعة البيانات المستخدمة تم شرحها بشكل سيئ واعتمد على الملصقات العامة. سيؤدي استخدام مجموعة بيانات أكثر تنوعًا ومؤسسة جيدًا إلى تعزيز أداء النموذج.
بالإضافة إلى ذلك ، بسبب قيود الموارد ، تم استخدام محول تلال صغير. يمكن أن يؤدي استخدام محول أكبر لمطابقة طول تسلسل مقطع MAX إلى تحسين أداء النموذج ، لأنه يسمح للنموذج بالتقاط المزيد من المعلومات.
https://github.com/stability-ai/stablediffusion/tree/main
https://github.com/openai/clip/tree/main
https://huggingface.co/docs/transformers/en/model_doc/wav2vec2-bert


