audio2img
1.0.0
โครงการนี้มีวัตถุประสงค์เพื่อปรับแต่งโมเดลเครื่องเข้ารหัสเสียง WAV2VEC2BERT เพื่อสร้างการฝังเสียงที่สามารถใช้แทนการเข้ารหัสข้อความ คลิป แบบดั้งเดิมได้ ด้วยการรวมการฝังเสียงเราสามารถใช้ประโยชน์จากคุณสมบัติที่เป็นเอกลักษณ์ของข้อมูลเสียงเพื่อปลดล็อกความเป็นไปได้ใหม่สำหรับโมเดล การแพร่กระจายที่เสถียร

- นางแบบบนใบหน้ากอด | สมุดบันทึกการฝึกอบรม
เสียงมีข้อมูลมากมายที่มักไม่ได้ใช้งานขยายไปไกลกว่าสิ่งที่เราจินตนาการไว้ ด้วยการเพิ่มขึ้นของรูปแบบ การแพร่กระจายแฝง และความสามารถในการกำเนิดที่น่าประทับใจของพวกเขาจึงมีความสนใจเพิ่มขึ้นในการสำรวจเทคนิคการปรับสภาพที่หลากหลาย วิธีการที่พบบ่อยที่สุดเกี่ยวข้องกับการใช้ คลิป (การฝึกฝนภาษาแบบภาษาที่ตัดกัน) การเข้ารหัสข้อความเพื่อปรับสภาพแบบจำลอง อย่างไรก็ตามข้อมูลเสียงนำเสนอแหล่งข้อมูลที่หลากหลายและหลากหลายซึ่งสามารถปรับปรุงกระบวนการปรับอากาศได้อย่างมีนัยสำคัญ







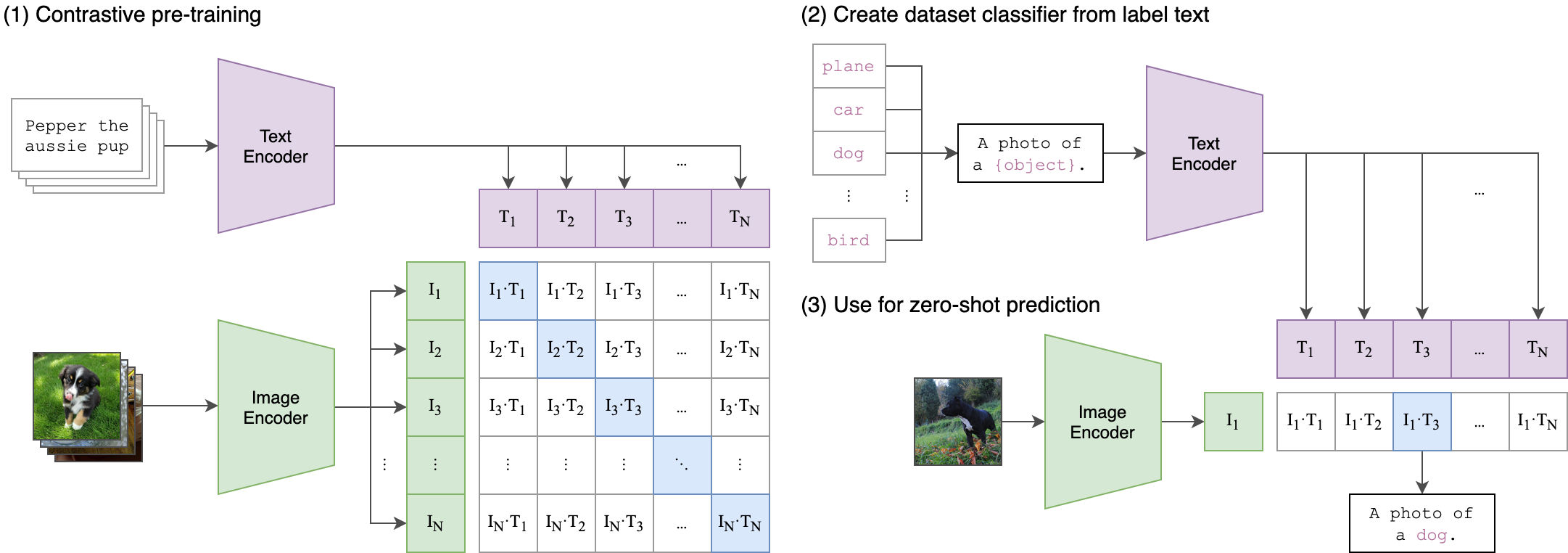
แนวคิดหลักที่อยู่เบื้องหลังกระบวนการฝึกอบรมของเราคือการบรรลุ การจัดตำแหน่งข้ามรูปแบบ ระหว่างการฝังเสียงและข้อความโดยใช้ สถาปัตยกรรมสองสตรีม สิ่งนี้เกี่ยวข้องกับการใช้ประโยชน์จาก ClipTextModel ที่ทรงพลังในการสร้างการฝังข้อความที่ทำหน้าที่เป็นฉลากจริงสำหรับการฝังเสียงที่ผลิตโดยโมเดล WAV2VEC2BERT ของเรา นี่คือคำอธิบายโดยละเอียด:
สถาปัตยกรรมสองสตรีม:
- สตรีมข้อความ: เราใช้ cliptextmodel เพื่อสร้างการฝังข้อความสำหรับอินพุตข้อความที่กำหนด การฝังตัวเหล่านี้จับข้อมูลความหมายที่หลากหลายและทำหน้าที่เป็น ฉลากความจริงภาคพื้นดิน
- สตรีมเสียง: โมเดล WAV2VEC2BERT ของเราใช้ ตัวเข้ารหัสคุณสมบัติ convolutional ตามด้วย เครือข่ายหม้อแปลง เพื่อประมวลผลอินพุตเสียงและสร้างการฝังเสียงที่สอดคล้องกัน
การจัดแนวข้ามโมเดล:
- ObjectIF: เป้าหมายหลักของการฝึกอบรมคือการจัดเรียงเสียงฝังตัวกับข้อความที่ฝังอยู่ใน พื้นที่ฝังตัวที่ใช้ร่วมกัน สิ่งนี้ทำให้มั่นใจได้ว่าอินพุตเสียงและข้อความที่คล้ายคลึงกันมีการแมปใกล้กัน
-ฟังก์ชั่นการสูญเสีย: เราบรรลุการจัดตำแหน่งนี้โดยใช้ การสูญเสียความคมชัด ซึ่งกระตุ้นให้โมเดลนำการฝังตัวของคู่ข้อความเสียงที่ตรงกัน เข้าใกล้ ในขณะที่ ผลัก ดันการฝังตัวของคู่ที่ไม่ตรงกัน
สิ่งนี้คล้ายกับวิธีที่โมเดล คลิป ดั้งเดิมได้รับการฝึกฝนให้จัดตำแหน่งคู่ข้อความภาพ ความแตกต่างคือในรูปแบบ คลิป OpenAI การสูญเสียความคมชัดถูกคำนวณโดยใช้ โทเค็น [CLS] ในขณะที่เราจะใช้การสูญเสียความคมชัดใน ระดับลำดับ
ภาพนี้สามารถอธิบายตรรกะที่อยู่เบื้องหลังการสูญเสียนี้:
ห้องสมุด Transformers ใช้สำหรับการฝึกอบรม "จุดตรวจสอบ Facebook/W2V-Bert-2.0" ถูกโหลดเป็นรุ่น ก่อน หน้า การเตรียมข้อมูลรายละเอียดการฝึกอบรมและพารามิเตอร์ที่ใช้สามารถพบได้ในสมุดบันทึก Train_me.ipynb :
model = Wav2Vec2BertModel . from_pretrained (
"facebook/w2v-bert-2.0" ,
add_adapter = True ,
adapter_kernel_size = 3 ,
adapter_stride = 2 ,
num_adapter_layers = 2 ,
layerdrop = 0.0 ,
) def Contrastive_loss ( embeddings1 , embeddings2 , temperature = 0.15 ):
cos_sim = torch . cosine_similarity ( embeddings1 . unsqueeze ( 1 ), embeddings2 . unsqueeze ( 0 ), dim = - 1 )
cos_sim = cos_sim / temperature
labels = torch . arange ( embeddings1 . size ( 0 )). unsqueeze ( 1 ). repeat ( 1 , embeddings1 . size ( 1 )). to ( embeddings1 . device )
loss = F . cross_entropy ( cos_sim , labels )
return loss
class TrainBert ( Trainer ):
def __init__ ( self , * args , ** kwargs ):
super (). __init__ ( * args , ** kwargs )
def compute_loss ( self , model , inputs , return_outputs = False ):
labels = inputs . pop ( "text_embeddings" )
outputs = model ( ** inputs )
outputs = outputs . last_hidden_state
loss = Contrastive_loss ( outputs , labels )
outputs = ( loss , outputs )
return outputs if return_outputs else lossNB: ขนาดแบทช์ เป็น พารามิเตอร์ที่สำคัญ ในการปรับแต่งเนื่องจากกำหนดจำนวน ตัวอย่างเชิงลบ ที่ส่งผ่านไปยังแบบจำลอง
pip install -r requirements.txtCKPT 1728 หรือ CKPT 2016
Wav2Vec2BertModel . from_pretrained ( 'youzarsif/wav2vec2bert_2_diffusion' )หรือ
Wav2Vec2BertModel . from_pretrained ( 'youzarsif/wav2vec2bert_2_diffusion_ckpt_1728' )อย่าลังเลที่จะใช้การเปลี่ยนแปลงใด ๆ ของ การแพร่กระจายที่เสถียร ควบคุมเน็ต หรือโมเดลที่คล้ายกันตราบใดที่พวกเขาใช้ ตัวเข้ารหัสคลิป เดียวกัน
StableDiffusionPipeline . from_pretrained ( "stabilityai/stable-diffusion-2-1" )python3 app.pyสร้างและเรียกใช้ภาพ Docker โดยตรง:
docker build -t app.py .
docker run -p 7860:7860 app.py ในระหว่างการฝึกอบรมพบว่าชุดข้อมูลที่ใช้นั้นมี คำอธิบายประกอบไม่ดี และพึ่งพาฉลากทั่วไป การใช้ชุดข้อมูล ที่หลากหลาย และ ได้รับการปรับปรุงที่ดีขึ้น จะช่วยเพิ่ม ประสิทธิภาพ ของโมเดล
นอกจากนี้เนื่องจากข้อ จำกัด ของทรัพยากรจึงมีการใช้อะแดปเตอร์ Convolution ขนาดเล็ก การใช้ อะแดปเตอร์ที่ใหญ่กว่า เพื่อให้ตรงกับความยาวลำดับสูงสุด ของคลิป สามารถปรับปรุงประสิทธิภาพของโมเดลได้อย่างแน่นอนเนื่องจากช่วยให้โมเดลสามารถ รวบรวม ข้อมูลเพิ่มเติมได้
https://github.com/stability-ai/stablediffusion/tree/main
https://github.com/openai/clip/tree/main
https://huggingface.co/docs/transformers/en/model_doc/wav2vec2-bert


