audio2img
1.0.0
Este proyecto tiene como objetivo ajustar un modelo de codificador de audio WAV2VEC2BERT para generar incrustaciones de audio que se pueden usar en lugar del codificador de texto clip tradicional. Al integrar los incrustaciones de audio, podemos aprovechar las propiedades únicas de los datos de audio para desbloquear nuevas posibilidades para modelos de difusión estables .

? Modelo en la cara abrazada | Cuaderno de entrenamiento
El audio contiene una gran cantidad de información que a menudo queda sin explotar, extendiendo mucho más allá de lo que normalmente imaginamos. Con el aumento de los modelos de difusión latente y sus impresionantes capacidades generativas, existe un creciente interés en explorar diversas técnicas de acondicionamiento. El enfoque más común implica el uso de codificadores de texto de clip (pre-entrenamiento de imagen de lenguaje contrastante) para acondicionar el modelo. Sin embargo, los datos de audio ofrecen una fuente de información rica y multifacética que puede mejorar significativamente el proceso de acondicionamiento.







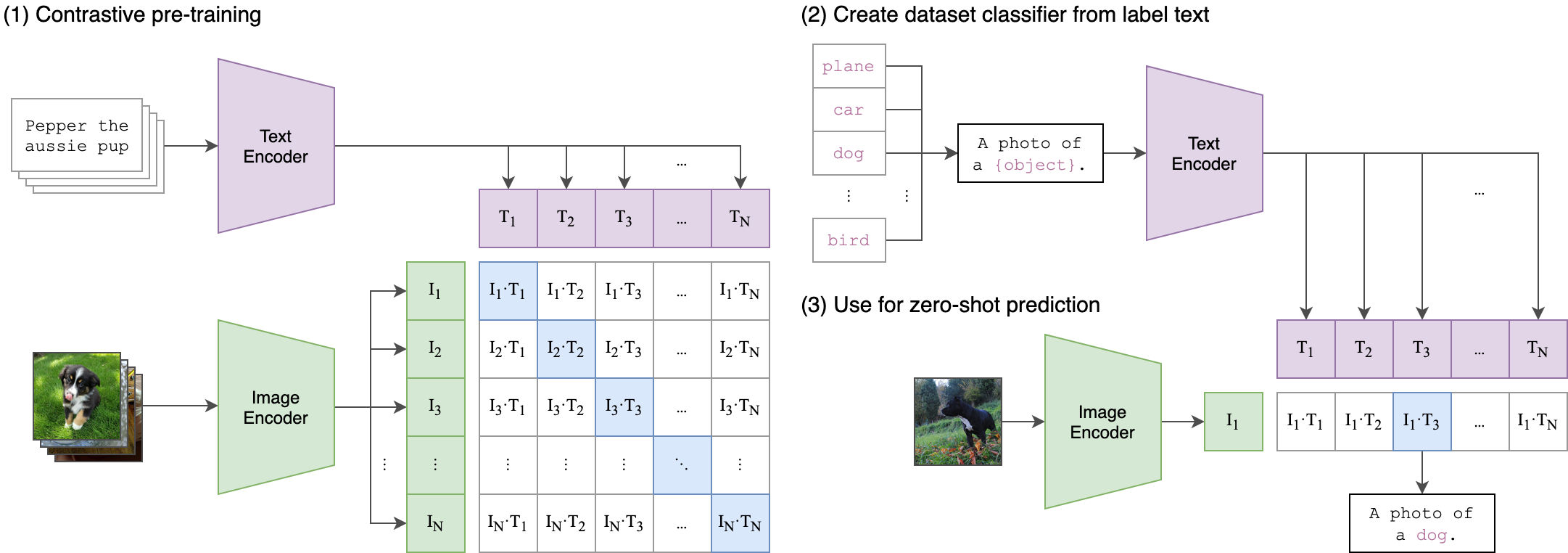
La idea central detrás de nuestro proceso de capacitación es lograr una alineación intermodal entre el audio y las integridades de texto utilizando una arquitectura de dos corrientes . Esto implica aprovechar el potente clipTextModel para generar embedidas de texto que sirven como etiquetas verdaderas para los incrustaciones de audio producidos por nuestro modelo WAV2VEC2Bert . Aquí hay una explicación detallada:
Arquitectura de dos transmisiones:
- Estruto de texto: usamos el clipTextModel para generar integridades de texto para entradas de texto dadas. Estas embedidas capturan información semántica rica y sirven como etiquetas de verdad de tierra .
- Transmisión de audio: nuestro modelo WAV2VEC2Bert usa el codificador de características convolucionales seguido de una red de transformadores para procesar las entradas de audio y generar incrustaciones de audio correspondientes.
Alineación de modalidad cruzada:
- Objecti: el objetivo principal de la capacitación es alinear los incrustaciones de audio con los incrustaciones de texto en un espacio de incrustación compartido . Esto asegura que las entradas de audio y texto semánticamente similares se mapearan entre sí.
-Función de pérdida: logramos esta alineación utilizando la pérdida de contraste que alienta al modelo a acercar los pares de audio de audio a juego mientras se separan las incrustaciones de pares no coincidentes.
Esto es similar a cómo se entrenó el modelo de clip original para alinear los pares de texto de imagen. La diferencia es que en el modelo de clip de OpenAI , la pérdida de contraste se calculó utilizando el token [CLS] , mientras que aplicaremos la pérdida de contraste en el nivel de secuencia .
Esta imagen puede explicar la lógica detrás de esta pérdida:
La biblioteca Transformers se utilizó para la capacitación. El punto de control "Facebook/W2V-Bert-2.0" se cargó como modelo inicial de petróleo . La preparación de datos, los detalles de capacitación y los hiperparámetros utilizados se pueden encontrar en el cuaderno Train_Me.ipynb :
model = Wav2Vec2BertModel . from_pretrained (
"facebook/w2v-bert-2.0" ,
add_adapter = True ,
adapter_kernel_size = 3 ,
adapter_stride = 2 ,
num_adapter_layers = 2 ,
layerdrop = 0.0 ,
) def Contrastive_loss ( embeddings1 , embeddings2 , temperature = 0.15 ):
cos_sim = torch . cosine_similarity ( embeddings1 . unsqueeze ( 1 ), embeddings2 . unsqueeze ( 0 ), dim = - 1 )
cos_sim = cos_sim / temperature
labels = torch . arange ( embeddings1 . size ( 0 )). unsqueeze ( 1 ). repeat ( 1 , embeddings1 . size ( 1 )). to ( embeddings1 . device )
loss = F . cross_entropy ( cos_sim , labels )
return loss
class TrainBert ( Trainer ):
def __init__ ( self , * args , ** kwargs ):
super (). __init__ ( * args , ** kwargs )
def compute_loss ( self , model , inputs , return_outputs = False ):
labels = inputs . pop ( "text_embeddings" )
outputs = model ( ** inputs )
outputs = outputs . last_hidden_state
loss = Contrastive_loss ( outputs , labels )
outputs = ( loss , outputs )
return outputs if return_outputs else lossNB: el tamaño de lotes es un hiperparámetro crucial para sintonizar, ya que define cuántas muestras negativas pasan al modelo.
pip install -r requirements.txtCKPT 1728 o CKPT 2016
Wav2Vec2BertModel . from_pretrained ( 'youzarsif/wav2vec2bert_2_diffusion' )o
Wav2Vec2BertModel . from_pretrained ( 'youzarsif/wav2vec2bert_2_diffusion_ckpt_1728' )Siéntase libre de usar cualquier variación de difusión estable , control de control o modelos similares, siempre que utilicen el mismo codificador de clip .
StableDiffusionPipeline . from_pretrained ( "stabilityai/stable-diffusion-2-1" )python3 app.pyConstruir y ejecutar directamente la imagen de Docker:
docker build -t app.py .
docker run -p 7860:7860 app.py Durante el entrenamiento, se observó que el conjunto de datos utilizado estaba mal anotado y dependido de etiquetas genéricas. Utilizar un conjunto de datos más diverso y bien elaborado mejorará el rendimiento del modelo.
Además, debido a las limitaciones de recursos, se utilizó un pequeño adaptador de convolución. El uso de un adaptador más grande para que coincida con la longitud de la secuencia de clip Max puede mejorar el rendimiento del modelo, ya que permite que el modelo capture más información.
https://github.com/stability-ai/stablediffusion/tree/main
https://github.com/openai/clip/tree/main
https://huggingface.co/docs/transformers/en/model_doc/wav2vec2-bert


