audio2img
1.0.0
이 프로젝트는 WAV2VEC2BERT 오디오 인코더 모델을 미세 조정하여 전통적인 클립 텍스트 인코더 대신 사용할 수있는 오디오 임베딩을 생성하는 것을 목표로합니다. 오디오 임베딩을 통합하여 오디오 데이터의 고유 한 특성을 활용하여 안정적인 확산 모델에 대한 새로운 가능성을 잠금 해제 할 수 있습니다.

? 포옹 얼굴 모델 | 훈련 노트북
오디오에는 종종 우리가 상상하는 것 이상으로 확장되는 풍부한 정보가 포함되어 있습니다. 잠재 확산 모델과 인상적인 생성 기능의 증가로 다양한 컨디셔닝 기술을 탐색하는 데 관심이 커지고 있습니다. 가장 일반적인 접근법은 클립 (대비 언어 이미지 사전 훈련) 텍스트 인코더를 사용하여 모델을 조정하는 것입니다. 그러나 오디오 데이터는 컨디셔닝 프로세스를 크게 향상시킬 수있는 풍부하고 다각적 인 정보 소스를 제공합니다.







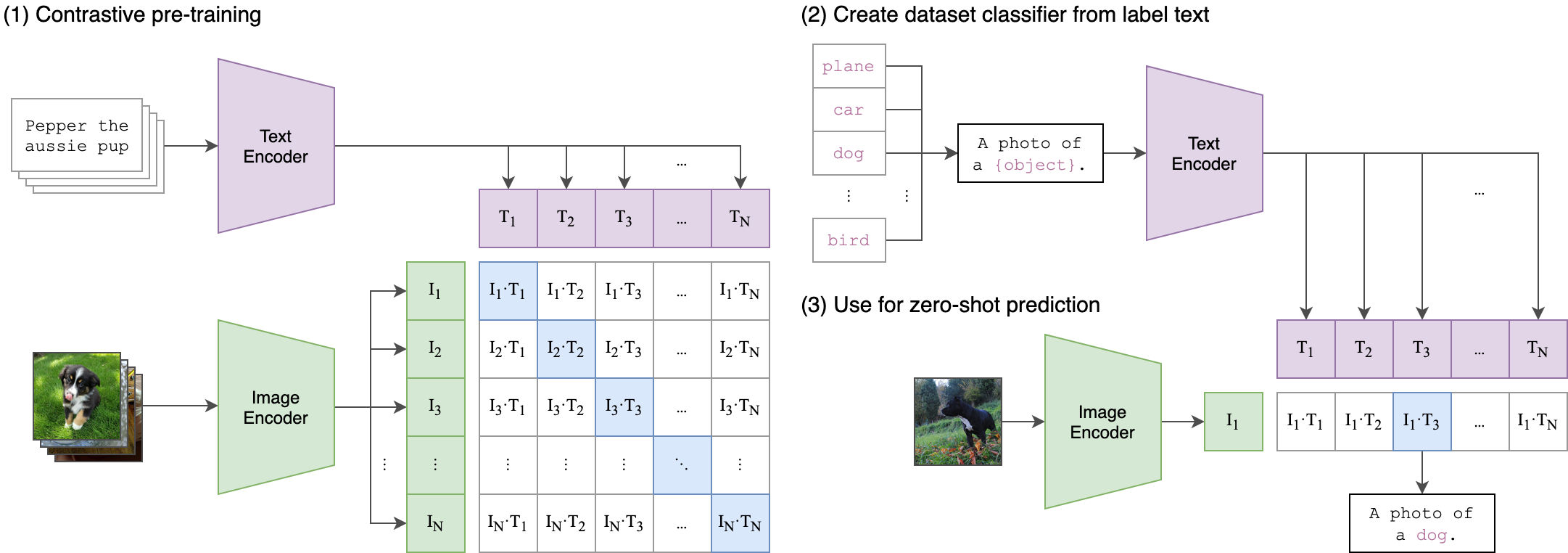
훈련 과정의 핵심 아이디어는 2 스트림 아키텍처를 사용하여 오디오와 텍스트 임베딩 사이의 교차 모달 정렬을 달성하는 것입니다. 여기에는 강력한 ClipTextModel을 활용하여 WAV2VEC2BERT 모델에서 생성 된 오디오 임베딩에 대한 진정한 레이블 역할을하는 텍스트 임베드를 생성하는 것이 포함됩니다. 자세한 설명은 다음과 같습니다.
2 스트림 아키텍처 :
- 텍스트 스트림 : ClipTextModel을 사용하여 주어진 텍스트 입력에 대한 텍스트 임베드를 생성합니다. 이 임베딩은 풍부한 의미 정보를 포착하고 지상 진실 레이블 역할을합니다.
- 오디오 스트림 : WAV2VEC2BERT 모델은 Convolutional Feature Encoder를 사용하고 Transformer 네트워크를 사용하여 오디오 입력을 처리하고 해당 오디오 임베딩을 생성합니다.
교차 양식 정렬 :
- Objectif : 교육의 주요 목표는 오디오 임베딩을 공유 임베딩 공간 에 텍스트 임베딩과 정렬하는 것입니다. 이를 통해 의미 적으로 유사한 오디오 및 텍스트 입력이 서로 가까이 매핑되도록합니다.
-손실 기능 : 대조적 인 손실을 사용 하여이 정렬을 달성하여 모델이 일치하는 오디오 텍스트 쌍의 임베딩을 더 가까이 가져 오는 동안 비 매칭 쌍의 임베딩을 밀어 넣을 수 있도록 장려합니다.
이것은 원래 클립 모델이 이미지 텍스트 쌍을 정렬하도록 훈련 된 방법과 유사합니다. 차이점은 OpenAI 클립 모델에서 대비 손실이 [CLS] 토큰을 사용하여 계산되었으며, 시퀀스 수준 에서 대비 손실을 적용한다는 것입니다.
이 이미지는이 손실의 논리를 설명 할 수 있습니다.
트랜스포머 라이브러리는 훈련에 사용되었습니다. "Facebook/W2V-Bert-2.0" 체크 포인트는 초기 사전 제한 모델로로드되었습니다. 데이터 준비, 훈련 세부 정보 및 사용 된 하이퍼 파라미터는 TRAIN_ME.IPYNB 노트에서 찾을 수 있습니다.
model = Wav2Vec2BertModel . from_pretrained (
"facebook/w2v-bert-2.0" ,
add_adapter = True ,
adapter_kernel_size = 3 ,
adapter_stride = 2 ,
num_adapter_layers = 2 ,
layerdrop = 0.0 ,
) def Contrastive_loss ( embeddings1 , embeddings2 , temperature = 0.15 ):
cos_sim = torch . cosine_similarity ( embeddings1 . unsqueeze ( 1 ), embeddings2 . unsqueeze ( 0 ), dim = - 1 )
cos_sim = cos_sim / temperature
labels = torch . arange ( embeddings1 . size ( 0 )). unsqueeze ( 1 ). repeat ( 1 , embeddings1 . size ( 1 )). to ( embeddings1 . device )
loss = F . cross_entropy ( cos_sim , labels )
return loss
class TrainBert ( Trainer ):
def __init__ ( self , * args , ** kwargs ):
super (). __init__ ( * args , ** kwargs )
def compute_loss ( self , model , inputs , return_outputs = False ):
labels = inputs . pop ( "text_embeddings" )
outputs = model ( ** inputs )
outputs = outputs . last_hidden_state
loss = Contrastive_loss ( outputs , labels )
outputs = ( loss , outputs )
return outputs if return_outputs else lossNB : 배치 크기는 모델에 얼마나 많은 음의 샘플이 전달되는지 정의하기 때문에 조정하는 데 중요한 과파라머 입니다.
pip install -r requirements.txtCKPT 1728 또는 CKPT 2016
Wav2Vec2BertModel . from_pretrained ( 'youzarsif/wav2vec2bert_2_diffusion' )또는
Wav2Vec2BertModel . from_pretrained ( 'youzarsif/wav2vec2bert_2_diffusion_ckpt_1728' )동일한 클립 인코더를 사용하는 한 안정적인 확산 , 컨트롤 넷 또는 유사한 모델의 변형을 자유롭게 사용하십시오.
StableDiffusionPipeline . from_pretrained ( "stabilityai/stable-diffusion-2-1" )python3 app.pyDocker 이미지를 직접 빌드하고 실행합니다.
docker build -t app.py .
docker run -p 7860:7860 app.py 훈련하는 동안 사용 된 데이터 세트가 제대로 주석이 부족하여 일반 레이블에 의존하는 것으로 관찰되었습니다. 보다 다양 하고 잘 부활 된 데이터 세트를 사용하면 모델의 성능이 향상됩니다.
또한 자원 제한으로 인해 작은 컨볼 루션 어댑터가 사용되었습니다. 클립 최대 시퀀스 길이와 일치하도록 더 큰 어댑터를 사용하면 모델이 더 많은 정보를 캡처 할 수 있으므로 모델 성능을 향상시킬 수 있습니다.
https://github.com/stability-ai/stableiffusion/tree/main
https://github.com/openai/clip/tree/main
https://huggingface.co/docs/transformers/en/model_doc/wav2vec2-bert


