Julia LLM Leaderboard
v0.2.0
朱莉婭語言產生能力的各種大型語言模型的比較
definition.toml解剖學歡迎來到Julia Code Generation Benchmark存儲庫!
該項目旨在為朱莉婭社區比較各種AI模型的代碼生成功能。與學術基準不同,我們的重點是實用性和簡單性:“生成代碼,運行它,看看它是否有效(-ish)。”
該存儲庫旨在了解不同的AI模型和促使策略在生成句法正確正確的朱莉婭代碼方面如何執行,以指導用戶為其需求選擇最佳模型。
癢的手指?跳到examples/或僅使用run_benchmark() (例如examples/code_gen_benchmark.jl )運行自己的基準標。
測試用例是在definition.toml中定義的。toml文件,為每個測試提供標準結構。如果您想貢獻測試案例,請按照貢獻您的測試案例部分中的說明進行操作。
根據幾個標準評估每個模型和提示的性能:
目前,所有標準都平等地稱重,每個測試案例最多可獲得100點。如果代碼通過所有條件,則獲得100/100點。如果失敗一個標準(例如,所有單位測試),則獲得75/100點。如果它失敗了兩個標準(例如,它運行,但所有示例和單位測試都破壞了),則獲得50分,依此類推。
為了瞥見存儲庫的功能,我們包括了前14個測試用例的示例結果。打開完整結果的文檔,並對每個測試案例進行深入研究。
警告
隨著我們發展支持功能並添加更多模型,這些分數可能會發生變化。
請記住,對於任何型號,基準標準都很具有挑戰性 - 一個額外的空間或括號,分數可能會變為0(=“無法解析”)!
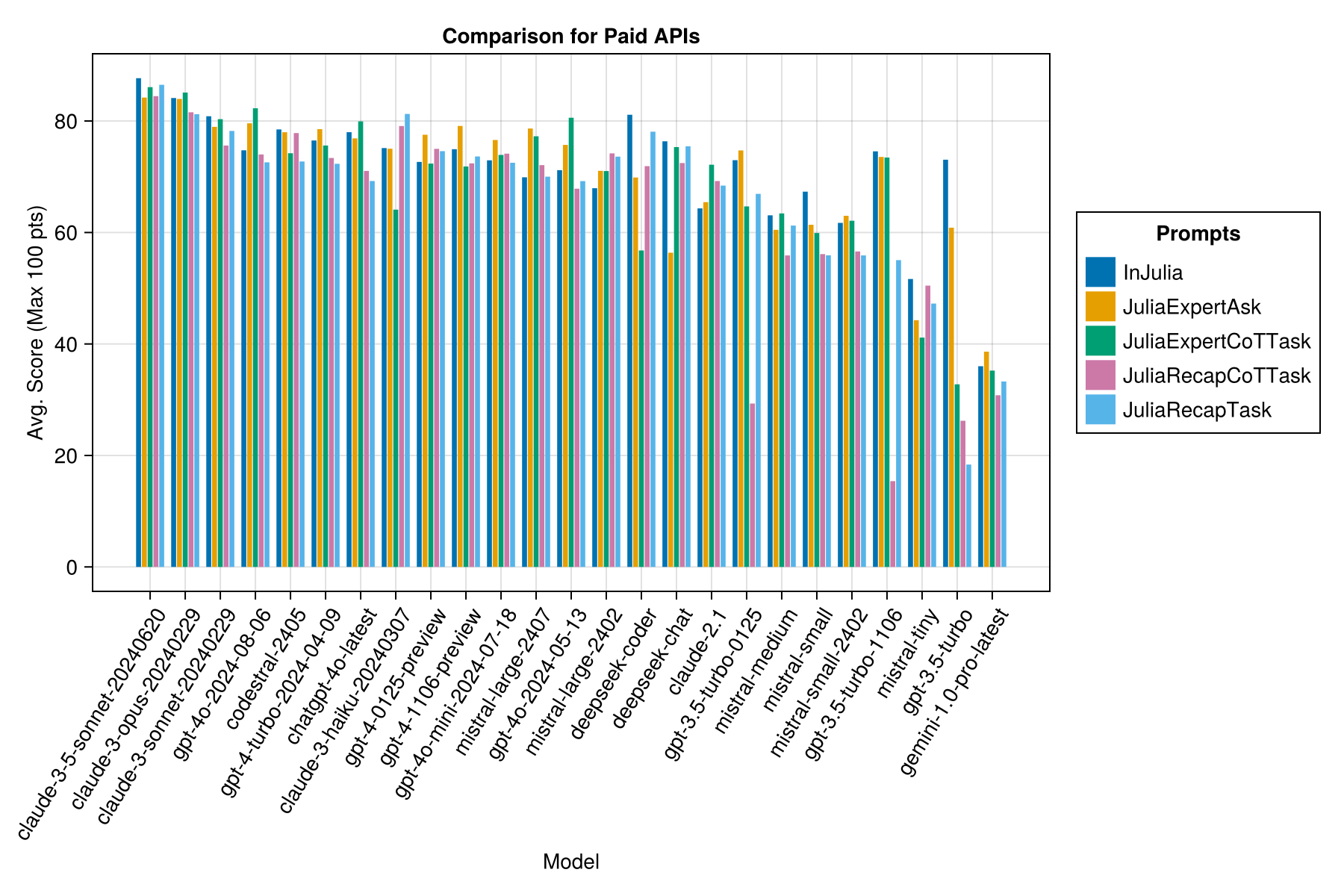
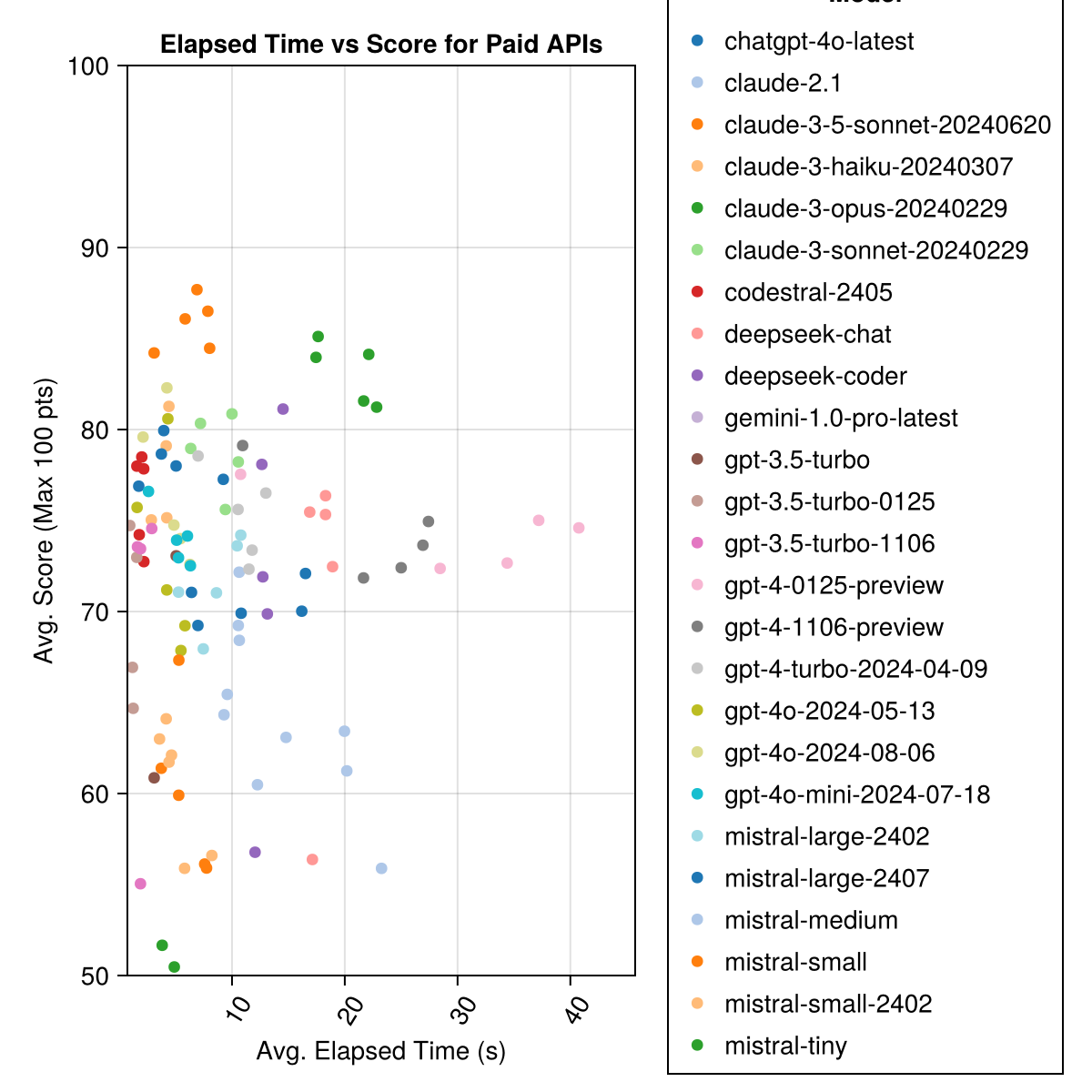
Claude 3.5十四行詩是表現最高的模型。為了獲得最佳價值的貨幣,請尋找Mistral Codestral,Claude 3 Haiku,最近發布的是GPT 4O Mini(比GPT3.5便宜60%!!!)。
| 模型 | 過去 | 分數 | 得分性病偏差 | 計數零分數 | 計數完整分數 | 費用為Cents |
|---|---|---|---|---|---|---|
| Claude-3-5-Sonnet-20240620 | 6.3 | 85.8 | 21.1 | 13 | 355 | 0.73 |
| Claude-3-Opus-20240229 | 20.3 | 83.2 | 19.6 | 2 | 329 | 3.9 |
| Claude-3-Sonnet-20240229 | 8.7 | 78.8 | 26.2 | 22 | 308 | 0.73 |
| GPT-4O-2024-08-06 | 4.6 | 76.6 | 27.9 | 26 | 310 | 0.0 |
| Codestral-2405 | 1.9 | 76.3 | 29.3 | 33 | 276 | 0.0 |
| GPT-4-Turbo-2024-04-09 | 10.8 | 75.3 | 29.6 | 38 | 290 | 1.38 |
| chatgpt-4o-latest | 4.8 | 75.0 | 27.9 | 25 | 263 | 0.0 |
| Claude-3-Haiku-20240307 | 4.0 | 74.9 | 27.2 | 9 | 261 | 0.05 |
| GPT-4-0125-Qureview | 30.3 | 74.4 | 30.3 | 39 | 284 | 1.29 |
| GPT-4-1106-preiview | 22.4 | 74.4 | 29.9 | 19 | 142 | 1.21 |
| GPT-4O-MINI-2024-07-18 | 5.1 | 74.0 | 29.4 | 32 | 276 | 0.03 |
| Mistral-Large-2407 | 11.3 | 73.6 | 29.5 | 15 | 137 | 0.49 |
| GPT-4O-2024-05-13 | 4.3 | 72.9 | 29.1 | 29 | 257 | 0.0 |
| DeepSeek-Coder | 13.0 | 71.6 | 32.6 | 39 | 115 | 0.01 |
| Mistral-Large-2402 | 8.5 | 71.6 | 27.2 | 13 | 223 | 0.0 |
| DeepSeek-Chat | 17.9 | 71.3 | 32.9 | 30 | 140 | 0.01 |
| Claude-2.1 | 10.1 | 67.9 | 30.8 | 47 | 229 | 0.8 |
| GPT-3.5-Turbo-0125 | 1.2 | 61.7 | 36.6 | 125 | 192 | 0.03 |
| Mistral-Medium | 18.1 | 60.8 | 33.2 | 22 | 90 | 0.41 |
| Mistral-small | 5.9 | 60.1 | 30.2 | 27 | 76 | 0.09 |
| Mistral-Small-2402 | 5.3 | 59.9 | 29.4 | 31 | 169 | 0.0 |
| GPT-3.5-Turbo-11106 | 2.1 | 58.4 | 39.2 | 82 | 97 | 0.04 |
| 微小的 | 4.6 | 46.9 | 32.0 | 75 | 42 | 0.02 |
| GPT-3.5-Turbo | 3.6 | 42.3 | 38.2 | 132 | 54 | 0.04 |
| Gemini-1.0-Pro-Latest | 4.2 | 34.8 | 27.4 | 181 | 25 | 0.0 |
注意:從2024年2月中旬開始,“ GPT-3.5-Turbo”將指向最新版本,“ GPT-3.5-Turbo-0125”(否定了6月份的版本)。
相同的信息,但作為條形圖:
此外,我們可以考慮性能(得分)與成本(以美分為中衡量的成本):
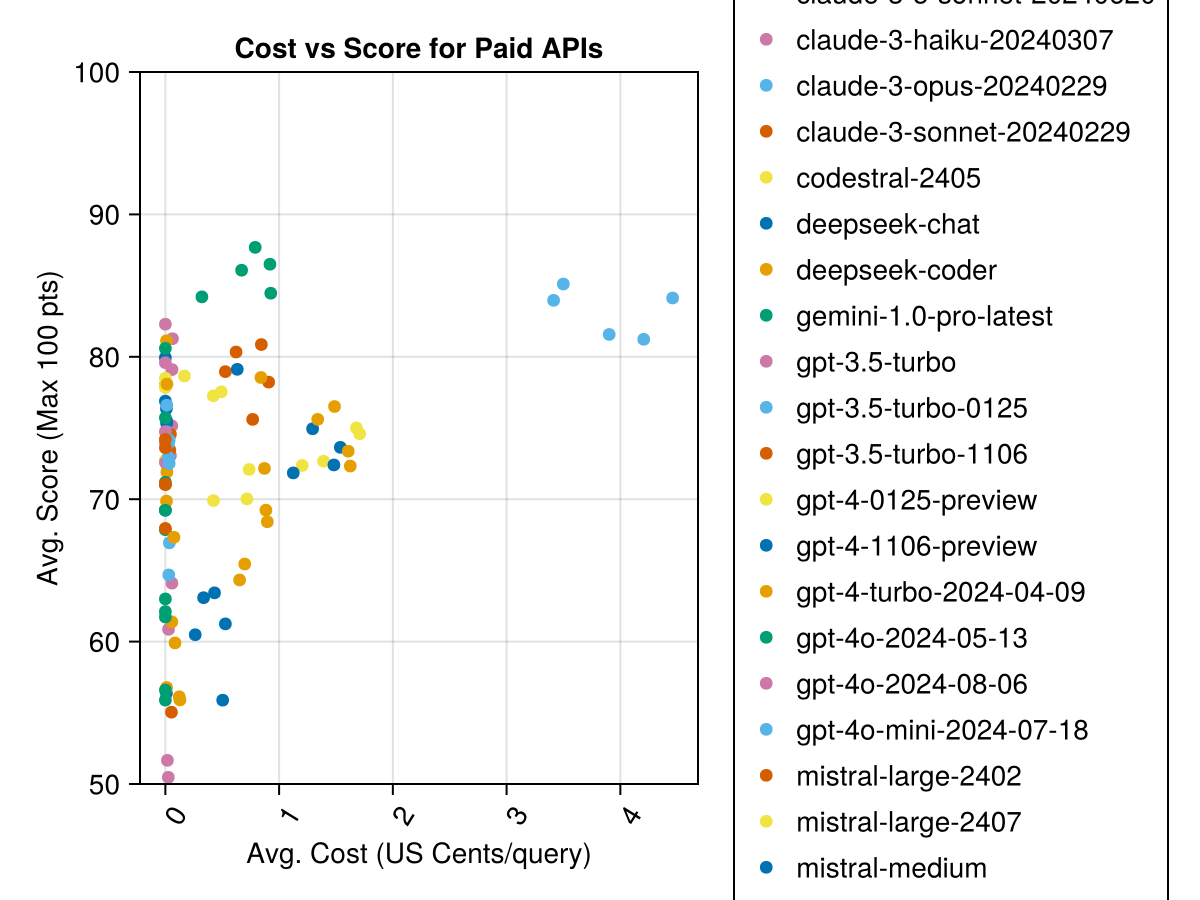
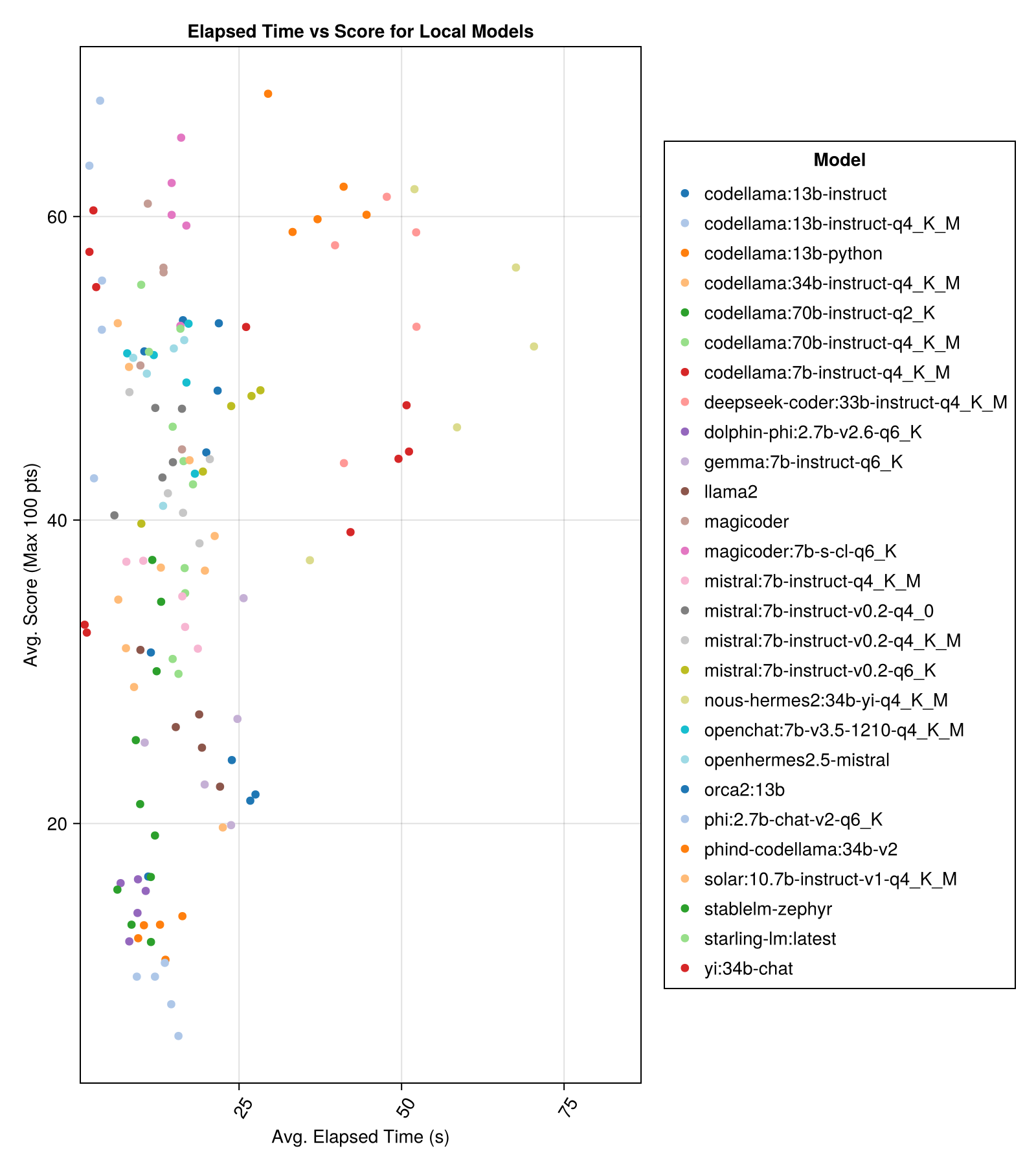
當地託管的車型通常不如付費最高的API好,但是它們越來越接近!請注意,“ Mistral-Small”已經可以在本地運行,並且將來會有許多未來的登錄!
筆記
非常感謝01.ai和Jun Tian,特別是為此基準的幾個部分提供了計算!
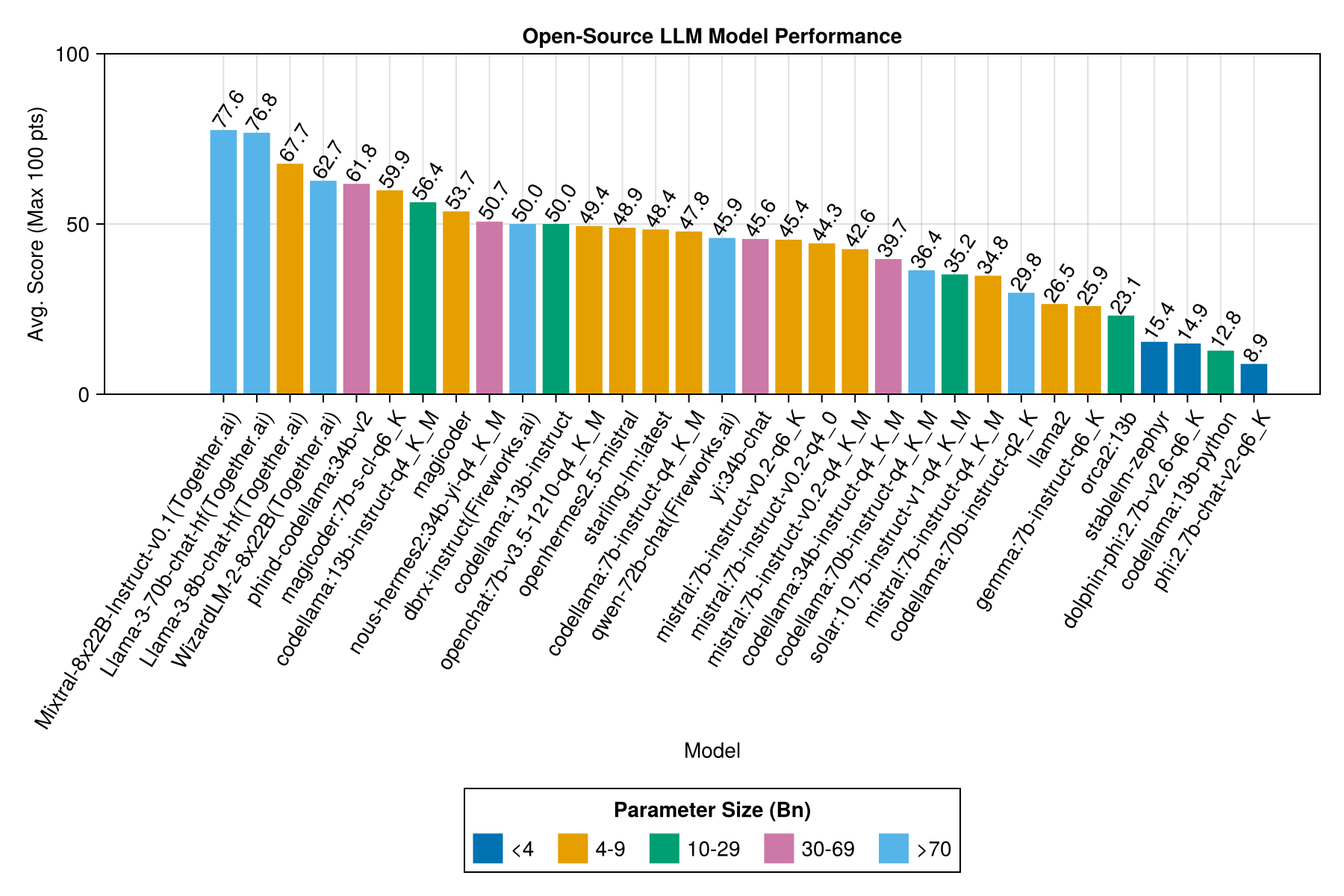
最好的權衡表現與尺寸是最新的Meta Llama3 80億。否則,領先的模型是Mixtral-8x22億。
| 模型 | 過去 | 經過的中位數 | 分數 | 得分中位數 | 得分性病偏差 | 計數零分數 | 計數完整分數 |
|---|---|---|---|---|---|---|---|
| Mixtral-8x22b-instruct-v0.1(一起) | 14.1 | 11.0 | 77.6 | 90.0 | 25.8 | 5.0 | 151.0 |
| Llama-3-70B-Chat-HF(一起) | 4.3 | 4.1 | 76.8 | 88.3 | 25.2 | 0.0 | 160.0 |
| Llama-3-8B-Chat-HF(一起) | 1.5 | 1.4 | 67.7 | 66.7 | 26.4 | 5.0 | 70.0 |
| wizardlm-2-8x22b(一起) | 34.7 | 31.0 | 62.7 | 60.0 | 33.8 | 33.0 | 118.0 |
| Phind-Codellama:34B-V2 | 37.1 | 36.4 | 61.8 | 62.5 | 33.5 | 36.0 | 58.0 |
| MagicOder:7B-S-CL-Q6_K | 15.6 | 15.8 | 59.9 | 60.0 | 29.9 | 18.0 | 35.0 |
| Codellama:13B-Instruct-Q4_K_M | 3.2 | 3.0 | 56.4 | 54.6 | 33.0 | 56.0 | 61.0 |
| DeepSeek-coder:33b-instruct-q4_k_m | 46.7 | 44.6 | 55.0 | 50.0 | 36.8 | 62.0 | 68.0 |
| 魔術師 | 12.8 | 10.7 | 53.7 | 50.0 | 33.2 | 49.0 | 52.0 |
| nous-hermes2:34b-yi-q4_k_m | 56.8 | 52.8 | 50.7 | 50.0 | 34.7 | 78.0 | 56.0 |
| DBRX-Instruct(Fireworks.ai) | 3.7 | 3.6 | 50.0 | 50.0 | 41.2 | 121.0 | 75.0 |
| Codellama:13B教學 | 18.1 | 16.7 | 50.0 | 50.0 | 34.4 | 65.0 | 44.0 |
| OpenChat:7B-V3.5-1210-Q4_K_M | 14.4 | 13.7 | 49.4 | 50.0 | 30.3 | 48.0 | 23.0 |
| openhermes2.5-任性 | 12.9 | 12.2 | 48.9 | 50.0 | 31.3 | 55.0 | 27.0 |
| Starling-LM:最新 | 13.7 | 12.5 | 48.4 | 50.0 | 30.2 | 58.0 | 26.0 |
| codellama:7b-instruct-q4_k_m | 2.1 | 2.0 | 47.8 | 50.0 | 35.3 | 95.0 | 38.0 |
| QWEN-72B-CHAT(Fireworks.ai) | 3.2 | 3.8 | 45.9 | 50.0 | 38.8 | 117.0 | 63.0 |
| yi:34b-chat | 43.9 | 41.3 | 45.6 | 50.0 | 30.5 | 45.0 | 34.0 |
| MISTRAL:7b-Instruct-V0.2-Q6_K | 21.7 | 20.9 | 45.4 | 50.0 | 31.3 | 44.0 | 23.0 |
| Mistral:7b-Instruct-V0.2-Q4_0 | 12.4 | 12.3 | 44.3 | 50.0 | 30.6 | 75.0 | 32.0 |
| MISTRAL:7b-Instruct-V0.2-Q4_K_M | 15.6 | 15.1 | 42.6 | 50.0 | 28.6 | 71.0 | 23.0 |
| codellama:34b-instruct-q4_k_m | 7.5 | 6.8 | 39.7 | 50.0 | 36.1 | 127.0 | 35.0 |
| Codellama:70B-Instruct-Q4_K_M | 16.3 | 13.8 | 36.4 | 0.0 | 41.2 | 179.0 | 58.0 |
| 太陽能:10.7b-instruct-v1-q4_k_m | 18.8 | 17.7 | 35.2 | 50.0 | 31.1 | 107.0 | 10.0 |
| MISTRAL:7b-Instruct-Q4_K_M | 13.9 | 13.0 | 34.8 | 50.0 | 26.5 | 80.0 | 0.0 |
| Codellama:70B-Instruct-Q2_K | 11.2 | 9.4 | 29.8 | 0.0 | 37.7 | 198.0 | 29.0 |
| Llama2 | 17.1 | 16.3 | 26.5 | 25.0 | 26.5 | 131.0 | 0.0 |
| Gemma:7b-instruct-Q6_K | 20.9 | 22.1 | 25.9 | 25.0 | 25.2 | 147.0 | 2.0 |
| orca2:13b | 20.1 | 18.3 | 23.1 | 0.0 | 30.6 | 166.0 | 11.0 |
| Stablelm-Zephyr | 9.9 | 7.7 | 15.4 | 0.0 | 23.5 | 192.0 | 1.0 |
| Dolphin-Phi:2.7b-V2.6-Q6_K | 8.9 | 8.4 | 14.9 | 0.0 | 22.9 | 188.0 | 0.0 |
| Codellama:13b-python | 12.5 | 10.7 | 12.8 | 0.0 | 22.1 | 155.0 | 0.0 |
| phi:2.7b-chat-v2-q6_k | 13.0 | 11.6 | 8.9 | 0.0 | 19.4 | 222.0 | 0.0 |
相同的信息,但作為條形圖:
每個提示模板都有一個單獨的欄: 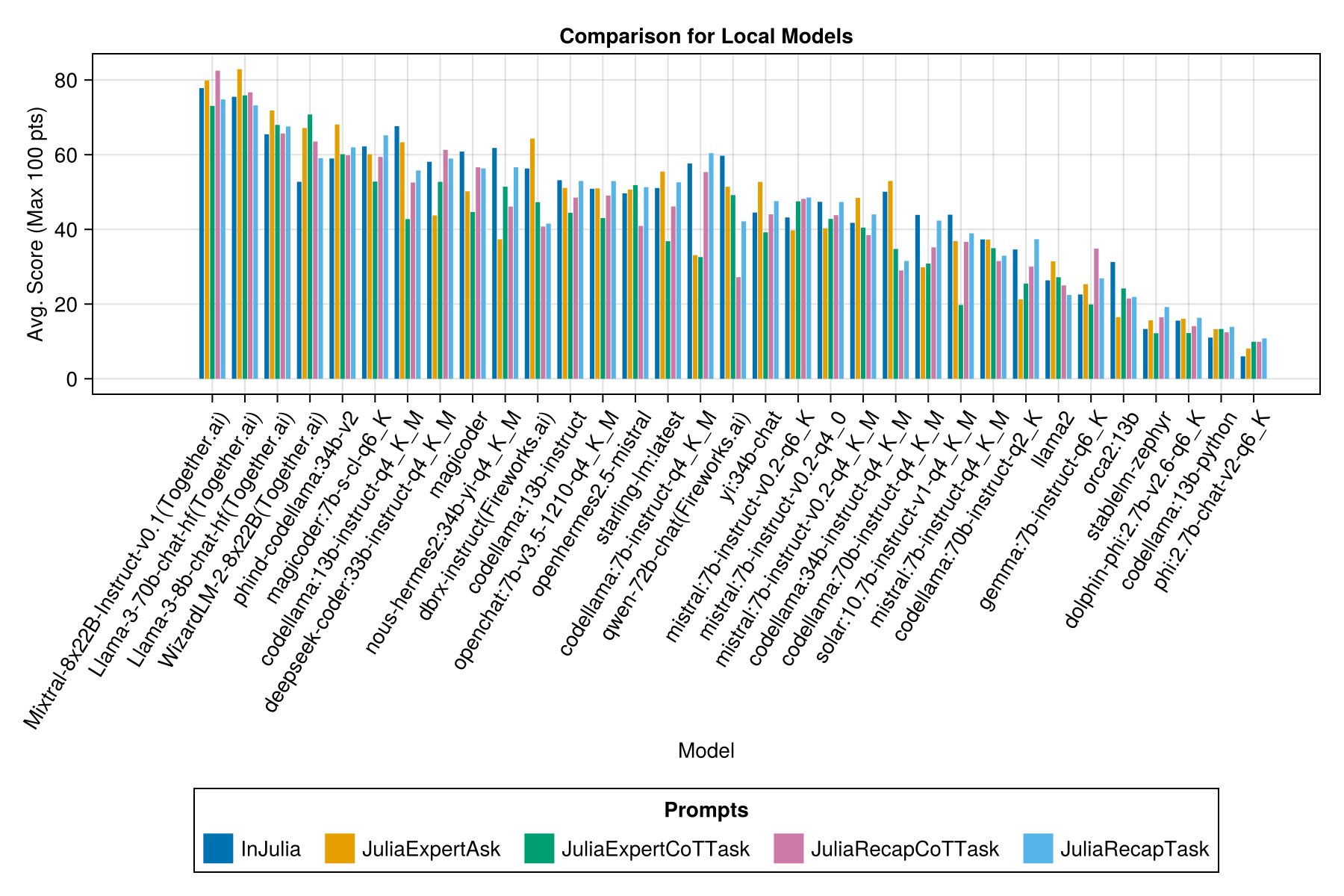
筆記
QWEN-1.5模型已從概述中刪除,因為Ollama存儲庫(和HF)上的基礎模型不正確,並且性能非常低。
筆記
我已經註意到,現在Ollama/Llama.cpp中的某些EVALS現在得分略高於12月23日,因此在路線圖上重新運行上述EVALS的路線圖。
顯然,付費的API獲勝(最新版本:GPT-3.5-Turbo-11106),但這不是全部。
我們希望能夠圍繞提示策略提供一些指導,例如,最好使用“ Juliaexpert*”提示模板與“ Julia中的“ juliaexpert”,請回答XYZ”提示。
到目前為止的學習:
| 提示模板 | 經過(s,平均) | 經過(S,中值) | avg。得分(最大100分) | 中值得分(最大100分) |
|---|---|---|---|---|
| Indulia | 14.0 | 9.6 | 55.2 | 50.0 |
| JuliaExpertask | 9.9 | 6.4 | 53.8 | 50.0 |
| JuliareCaptask | 16.7 | 11.5 | 52.0 | 50.0 |
| JuliaexpertCottask | 15.4 | 10.4 | 49.5 | 50.0 |
| Juliarecapcottask | 16.1 | 11.3 | 48.6 | 50.0 |
注意:基於XML的模板僅針對Claude 3模型(Haiku and Sonnet)測試,這就是為什麼我們將其從比較中刪除。
用examples/summarize_results.jl進行自己的分析!
scripts/code_gen_benchmark.jl以前的評估示例。想運行一些實驗並保存結果嗎?查看examples/experiment_hyperparameter_scan.jl !
是否想查看過去的一些基準運行?查看examples/summarize_results.jl有關整體統計信息和examples/debugging_results.jl以查看單個對話/模型響應。
貢獻測試案例:
code_generation/category/test_case_name/definition.toml 。code_generation/category/test case/model/evaluation__PROMPT__STRATEGY__TIMESTAMP.json和code_generation/category/test case/model/conversation__PROMPT__STRATEGY__TIMESTAMP.jsondefinition.toml解剖學definition.toml中的必需字段。toml包括:
my_function(1, 2) )作為可執行語句的向量提供。@test X = Z語句的向量提供的代碼。有幾個可選字段:
以上字段可以改善示例/單元測試中代碼的重複使用。
請參閱examples/create_definition.jl中的示例。您可以使用validate_definition()驗證測試案例定義。
請pr,並在文件夾julia_conversations/中添加與/in/of Aof Julia的任何相關且主要是正確的對話。
目的是進行一系列對話集合,這些對話可用於較小模型中的朱莉婭知識。
我們高度重視社區的投入。如果您有改進的建議或想法,請打開問題。歡迎所有貢獻!


