Julia LLM Leaderboard
v0.2.0
다양한 대형 언어 모델의 Julia 언어 생성 기능 비교
definition.toml 의 해부학Julia Code Generation 벤치 마크 리포지토리에 오신 것을 환영합니다!
이 프로젝트는 Julia 커뮤니티가 다양한 AI 모델의 코드 생성 기능을 비교하도록 설계되었습니다. 학문적 벤치 마크와 달리 우리의 초점은 실용성과 단순성입니다. "코드 생성, 실행 및 그것이 작동하는지 확인하십시오 (-ish)."
이 저장소는 다른 AI 모델과 프롬프트 전략이 구문 적으로 올바른 Julia 코드를 생성하여 사용자가 자신의 요구에 가장 적합한 모델을 선택하도록 안내하는 방법을 이해하는 것을 목표로합니다.
가려운 손가락? run_benchmark() (예 : examples/code_gen_benchmark.jl )를 사용하여 examples/ 또는 자신의 벤치 마크를 실행하십시오.
테스트 케이스는 definition.toml 파일에 정의되어 각 테스트에 대한 표준 구조를 제공합니다. 테스트 사례를 기여하려면 테스트 사례 섹션의 지침을 따르십시오.
각 모델과 프롬프트의 성능은 몇 가지 기준에 따라 평가됩니다.
현재 모든 기준은 동일하게 무게를 측정하고 각 테스트 사례는 최대 100 점을 얻을 수 있습니다. 코드가 모든 기준을 전달하면 100/100 포인트가됩니다. 하나의 기준 (예 : 모든 단위 테스트)이 실패하면 75/100 포인트가됩니다. 두 가지 기준에 실패하면 (예 : 실행되지만 모든 예제 및 단위 테스트가 고장 나면) 50 점을 얻습니다.
저장소 기능을 엿볼 수 있도록 처음 14 개의 테스트 사례에 대한 예제 결과를 포함 시켰습니다. 전체 결과와 각 테스트 사례에 대한 깊은 다이빙에 대한 문서를 엽니 다 .
경고
지원 기능을 발전시키고 더 많은 모델을 추가함에 따라 이러한 점수는 변경 될 수 있습니다.
벤치 마크는 모든 모델에 대해 매우 어려운 일입니다. 단일 추가 공간 또는 괄호이며 점수는 0 (= "구문 분석 할 수 없음")이 될 수 있습니다!
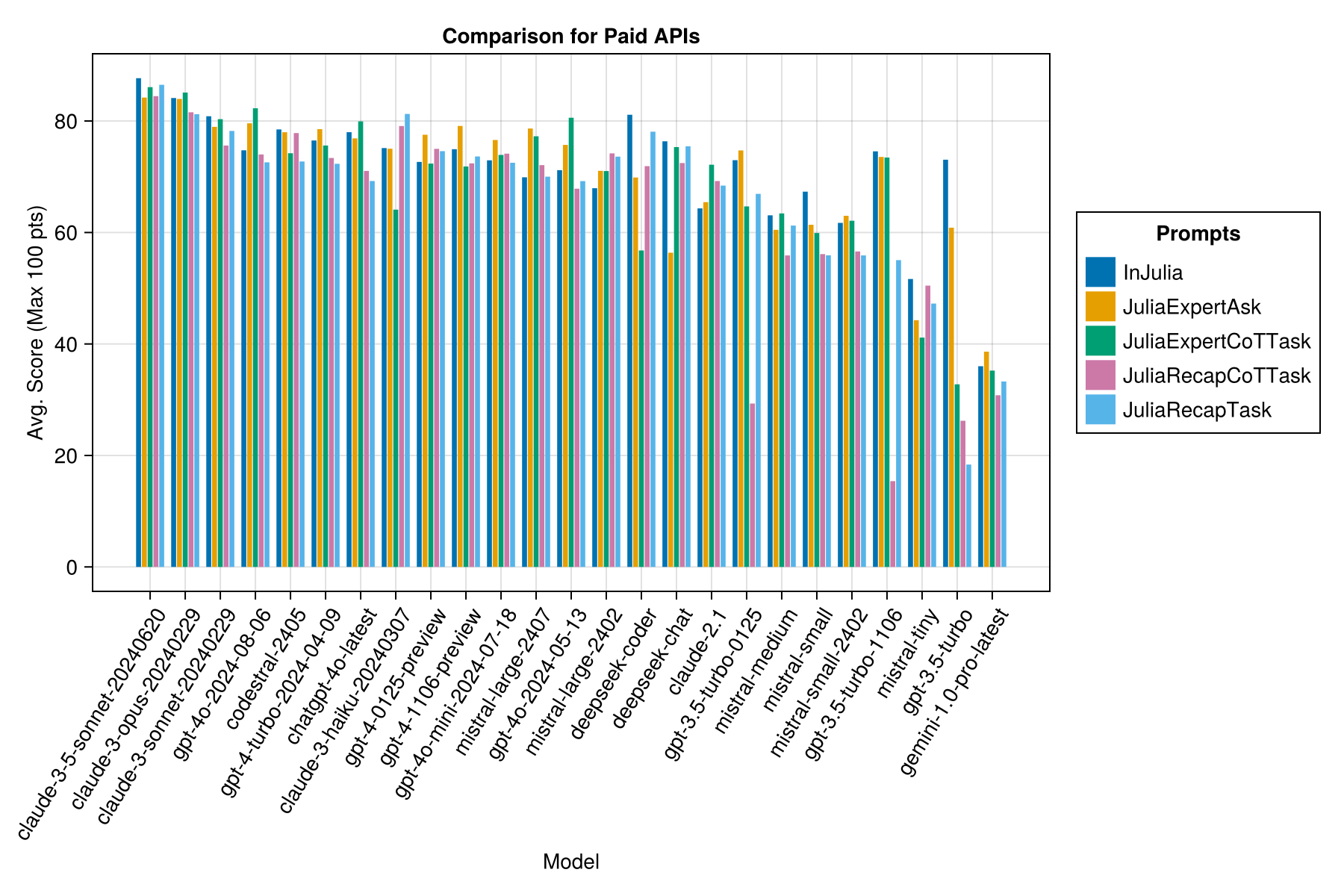
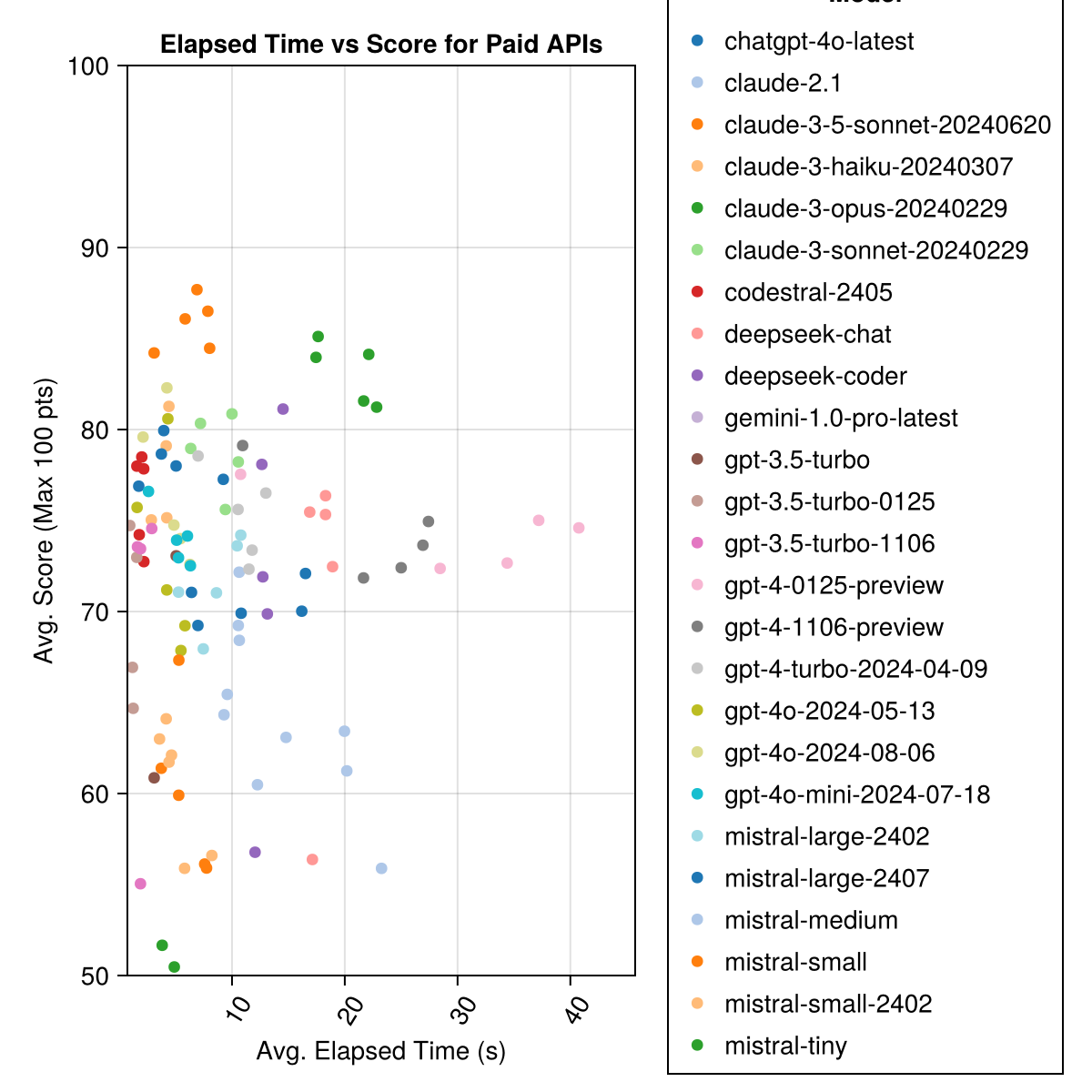
Claude 3.5 Sonnet은 가장 높은 성능 모델입니다. 최상의 가치를 얻으려면 Mistral Codestral, Claude 3 Haiku 및 최근에 발표 된 GPT 4O MINI (GPT3.5보다 60% 저렴)를 찾으십시오.
| 모델 | 경과 | 점수 | 점수 STD 편차 | 0 점수를 계산하십시오 | 전체 점수를 계산하십시오 | 비용 센트 |
|---|---|---|---|---|---|---|
| Claude-3-5-Sonnet-20240620 | 6.3 | 85.8 | 21.1 | 13 | 355 | 0.73 |
| Claude-3-Opus-20240229 | 20.3 | 83.2 | 19.6 | 2 | 329 | 3.9 |
| Claude-3-Sonnet-20240229 | 8.7 | 78.8 | 26.2 | 22 | 308 | 0.73 |
| GPT-4O-2024-08-06 | 4.6 | 76.6 | 27.9 | 26 | 310 | 0.0 |
| Codestral-2405 | 1.9 | 76.3 | 29.3 | 33 | 276 | 0.0 |
| GPT-4-TURBO-2024-04-09 | 10.8 | 75.3 | 29.6 | 38 | 290 | 1.38 |
| chatgpt-4o-latest | 4.8 | 75.0 | 27.9 | 25 | 263 | 0.0 |
| Claude-3-Haiku-20240307 | 4.0 | 74.9 | 27.2 | 9 | 261 | 0.05 |
| GPT-4-0125-- 검색 | 30.3 | 74.4 | 30.3 | 39 | 284 | 1.29 |
| GPT-4-1106-- 검색 | 22.4 | 74.4 | 29.9 | 19 | 142 | 1.21 |
| GPT-4O-MINI-2024-07-18 | 5.1 | 74.0 | 29.4 | 32 | 276 | 0.03 |
| Mistral-Large-2407 | 11.3 | 73.6 | 29.5 | 15 | 137 | 0.49 |
| GPT-4O-2024-05-13 | 4.3 | 72.9 | 29.1 | 29 | 257 | 0.0 |
| Deepseek 코더 | 13.0 | 71.6 | 32.6 | 39 | 115 | 0.01 |
| Mistral-Large-2402 | 8.5 | 71.6 | 27.2 | 13 | 223 | 0.0 |
| Deepseek-Chat | 17.9 | 71.3 | 32.9 | 30 | 140 | 0.01 |
| 클로드 -2.1 | 10.1 | 67.9 | 30.8 | 47 | 229 | 0.8 |
| GPT-3.5-Turbo-0125 | 1.2 | 61.7 | 36.6 | 125 | 192 | 0.03 |
| 미산 | 18.1 | 60.8 | 33.2 | 22 | 90 | 0.41 |
| 불행 | 5.9 | 60.1 | 30.2 | 27 | 76 | 0.09 |
| Mistral-Small-2402 | 5.3 | 59.9 | 29.4 | 31 | 169 | 0.0 |
| GPT-3.5-Turbo-1106 | 2.1 | 58.4 | 39.2 | 82 | 97 | 0.04 |
| 불신 | 4.6 | 46.9 | 32.0 | 75 | 42 | 0.02 |
| GPT-3.5 터보 | 3.6 | 42.3 | 38.2 | 132 | 54 | 0.04 |
| Gemini-1.0-Pro-Latest | 4.2 | 34.8 | 27.4 | 181 | 25 | 0.0 |
참고 : 2024 년 2 월 중순부터 "GPT-3.5-Turbo"는 최신 릴리스 "GPT-3.5-Turbo-0125"(6 월 릴리스를 이상하지 않음)를 가리 킵니다.
동일한 정보이지만 막대 차트 :
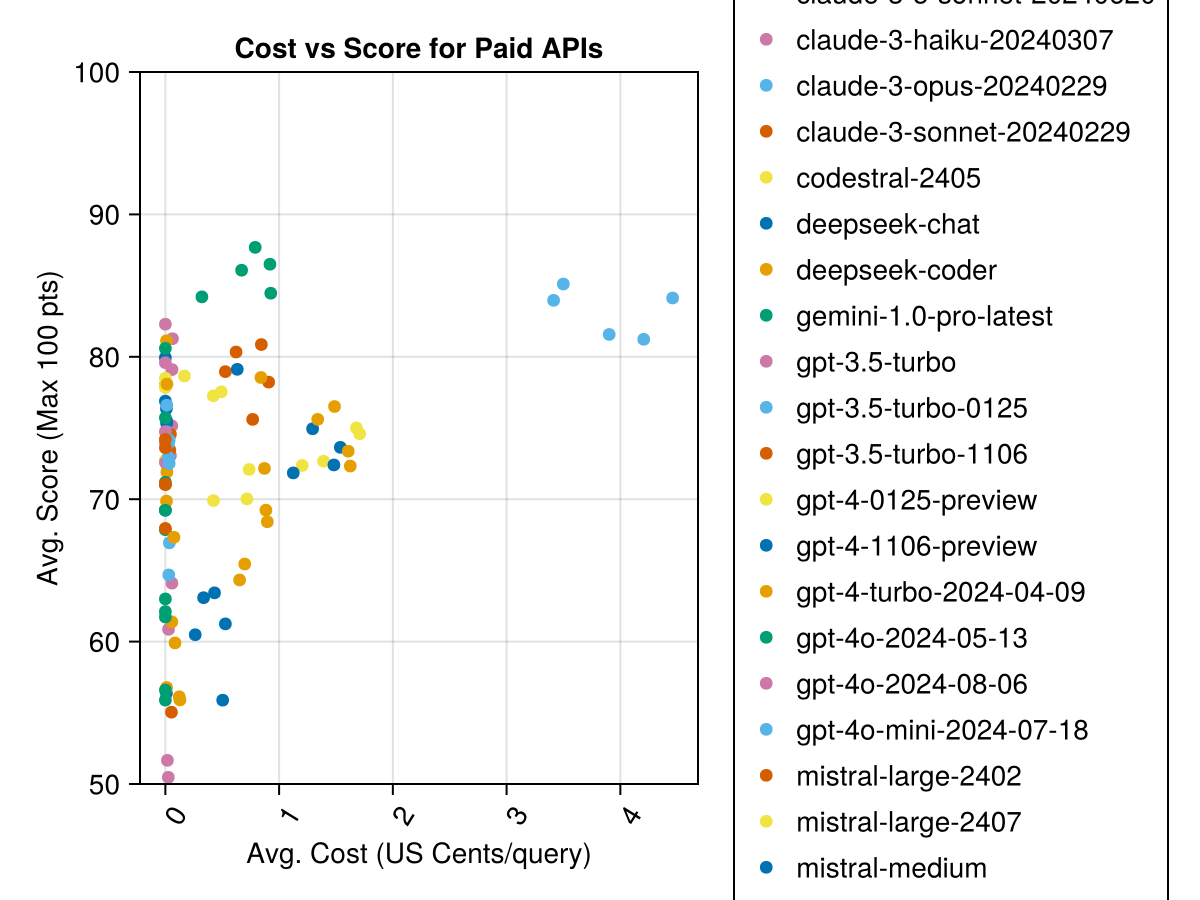
또한 성능 (점수) 대 비용 (미국 센트로 측정)을 고려할 수 있습니다.
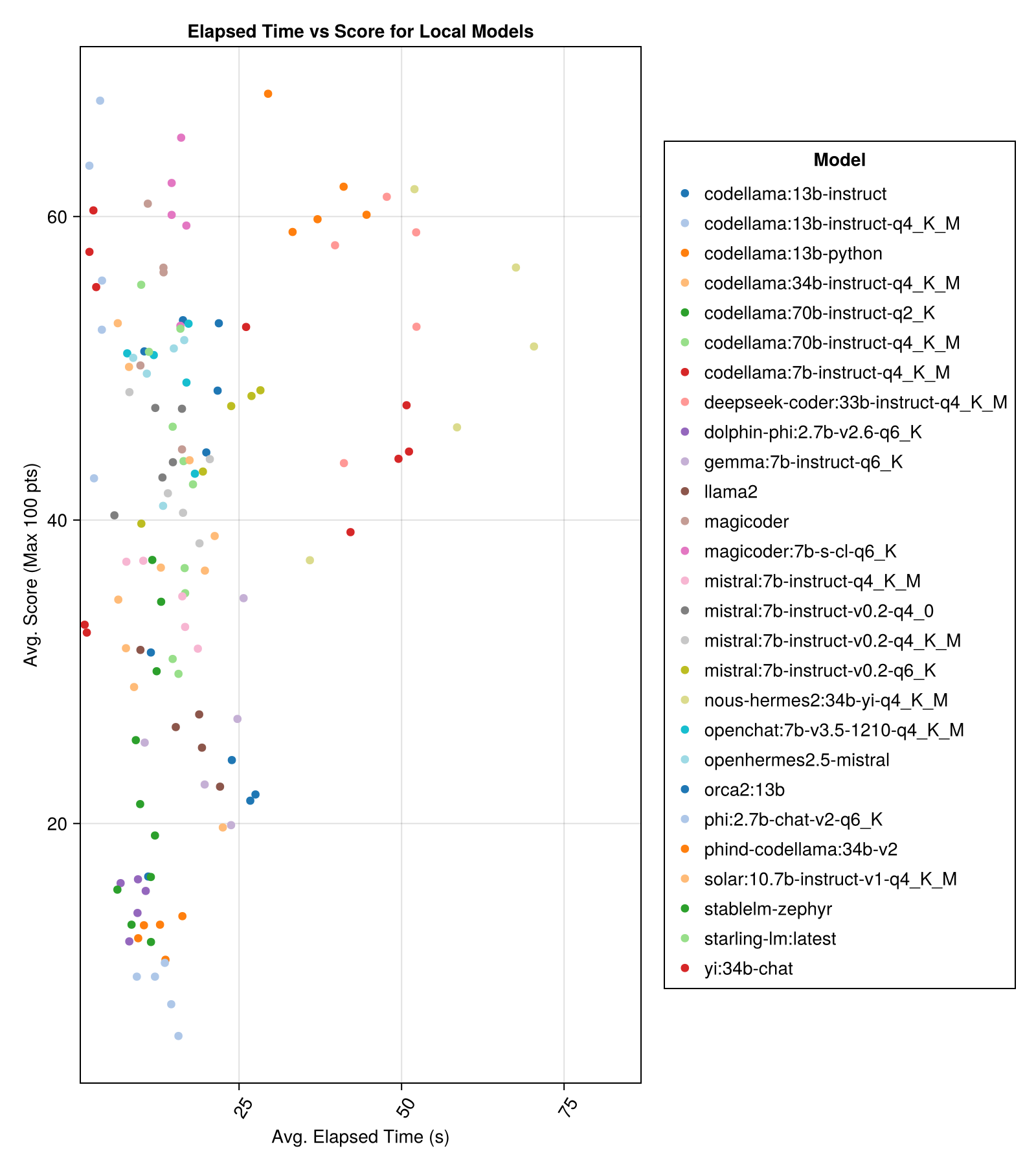
로컬에서 호스팅 된 모델은 일반적으로 최고의 유료 API만큼 좋지는 않지만 가까워지고 있습니다! "Mistral-Small"은 이미 로컬로 실행할 수 있으며 미래의 Finetunes가 많이있을 것입니다!
메모
이 벤치 마크의 여러 부분에 대한 컴퓨팅을 제공해 주신 01.ai와 Jun Tian에게 큰 감사를드립니다!
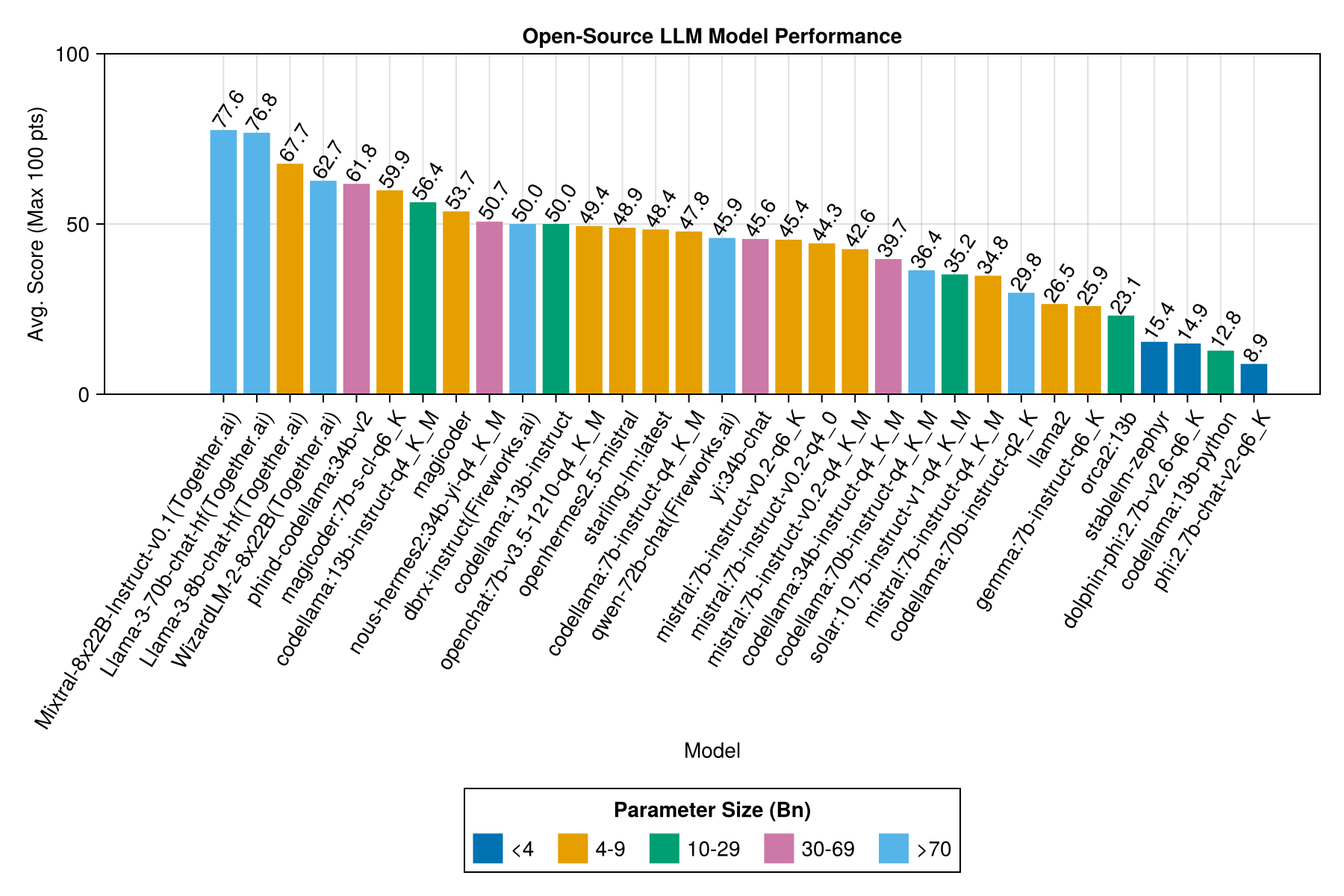
최고의 트레이드 오프 성능 대 크기는 최신 Meta LLAMA3 8BN입니다. 그렇지 않으면 주요 모델은 Mixtral-8x22bn입니다.
| 모델 | 경과 | 경과 중앙값 | 점수 | 점수 중앙값 | 점수 STD 편차 | 0 점수를 계산하십시오 | 전체 점수를 계산하십시오 |
|---|---|---|---|---|---|---|---|
| mixtral-8x22b- 비 구역 -V0.1 (함께 .ai) | 14.1 | 11.0 | 77.6 | 90.0 | 25.8 | 5.0 | 151.0 |
| llama-3-70B-Chat-HF (함께 .ai) | 4.3 | 4.1 | 76.8 | 88.3 | 25.2 | 0.0 | 160.0 |
| llama-3-8b-chat-HF (함께 .ai) | 1.5 | 1.4 | 67.7 | 66.7 | 26.4 | 5.0 | 70.0 |
| Wizardlm-2-8x22b (함께 .ai) | 34.7 | 31.0 | 62.7 | 60.0 | 33.8 | 33.0 | 118.0 |
| Phind-Codellama : 34B-V2 | 37.1 | 36.4 | 61.8 | 62.5 | 33.5 | 36.0 | 58.0 |
| Magicoder : 7B-S-Cl-Q6_K | 15.6 | 15.8 | 59.9 | 60.0 | 29.9 | 18.0 | 35.0 |
| Codellama : 13B-Instruct-Q4_K_M | 3.2 | 3.0 | 56.4 | 54.6 | 33.0 | 56.0 | 61.0 |
| DeepSeek-Coder : 33B-Instruct-Q4_K_M | 46.7 | 44.6 | 55.0 | 50.0 | 36.8 | 62.0 | 68.0 |
| Magicoder | 12.8 | 10.7 | 53.7 | 50.0 | 33.2 | 49.0 | 52.0 |
| Nous-Hermes2 : 34B-YI-Q4_K_M | 56.8 | 52.8 | 50.7 | 50.0 | 34.7 | 78.0 | 56.0 |
| DBRX-Instruct (불꽃 놀이) | 3.7 | 3.6 | 50.0 | 50.0 | 41.2 | 121.0 | 75.0 |
| Codellama : 13b-instruct | 18.1 | 16.7 | 50.0 | 50.0 | 34.4 | 65.0 | 44.0 |
| OpenChat : 7B-V3.5-1210-Q4_K_M | 14.4 | 13.7 | 49.4 | 50.0 | 30.3 | 48.0 | 23.0 |
| OpenHermes2.5-mistral | 12.9 | 12.2 | 48.9 | 50.0 | 31.3 | 55.0 | 27.0 |
| Starling-LM : 최신 | 13.7 | 12.5 | 48.4 | 50.0 | 30.2 | 58.0 | 26.0 |
| Codellama : 7B-Instruct-Q4_K_M | 2.1 | 2.0 | 47.8 | 50.0 | 35.3 | 95.0 | 38.0 |
| Qwen-72B-Chat (Fire Works.ai) | 3.2 | 3.8 | 45.9 | 50.0 | 38.8 | 117.0 | 63.0 |
| YI : 34B-Chat | 43.9 | 41.3 | 45.6 | 50.0 | 30.5 | 45.0 | 34.0 |
| MISTRAL : 7B-Instruct-V0.2-Q6_K | 21.7 | 20.9 | 45.4 | 50.0 | 31.3 | 44.0 | 23.0 |
| MISTRAL : 7B-Instruct-V0.2-Q4_0 | 12.4 | 12.3 | 44.3 | 50.0 | 30.6 | 75.0 | 32.0 |
| MISTRAL : 7B-Instruct-V0.2-Q4_K_M | 15.6 | 15.1 | 42.6 | 50.0 | 28.6 | 71.0 | 23.0 |
| Codellama : 34B-Instruct-Q4_K_M | 7.5 | 6.8 | 39.7 | 50.0 | 36.1 | 127.0 | 35.0 |
| Codellama : 70B-Instruct-Q4_K_M | 16.3 | 13.8 | 36.4 | 0.0 | 41.2 | 179.0 | 58.0 |
| 태양 : 10.7B- 비교 -V1-Q4_K_M | 18.8 | 17.7 | 35.2 | 50.0 | 31.1 | 107.0 | 10.0 |
| MISTRAL : 7B-Instruct-Q4_K_M | 13.9 | 13.0 | 34.8 | 50.0 | 26.5 | 80.0 | 0.0 |
| Codellama : 70b-Instruct-Q2_K | 11.2 | 9.4 | 29.8 | 0.0 | 37.7 | 198.0 | 29.0 |
| llama2 | 17.1 | 16.3 | 26.5 | 25.0 | 26.5 | 131.0 | 0.0 |
| Gemma : 7B-Instruct-Q6_K | 20.9 | 22.1 | 25.9 | 25.0 | 25.2 | 147.0 | 2.0 |
| ORCA2 : 13B | 20.1 | 18.3 | 23.1 | 0.0 | 30.6 | 166.0 | 11.0 |
| Stablelm-Zephyr | 9.9 | 7.7 | 15.4 | 0.0 | 23.5 | 192.0 | 1.0 |
| 돌고래 -PHI : 2.7B-v2.6-Q6_K | 8.9 | 8.4 | 14.9 | 0.0 | 22.9 | 188.0 | 0.0 |
| Codellama : 13B-Python | 12.5 | 10.7 | 12.8 | 0.0 | 22.1 | 155.0 | 0.0 |
| PHI : 2.7B-Chat-V2-Q6_K | 13.0 | 11.6 | 8.9 | 0.0 | 19.4 | 222.0 | 0.0 |
동일한 정보이지만 막대 차트 :
각 프롬프트 템플릿마다 별도의 막대가 있습니다. 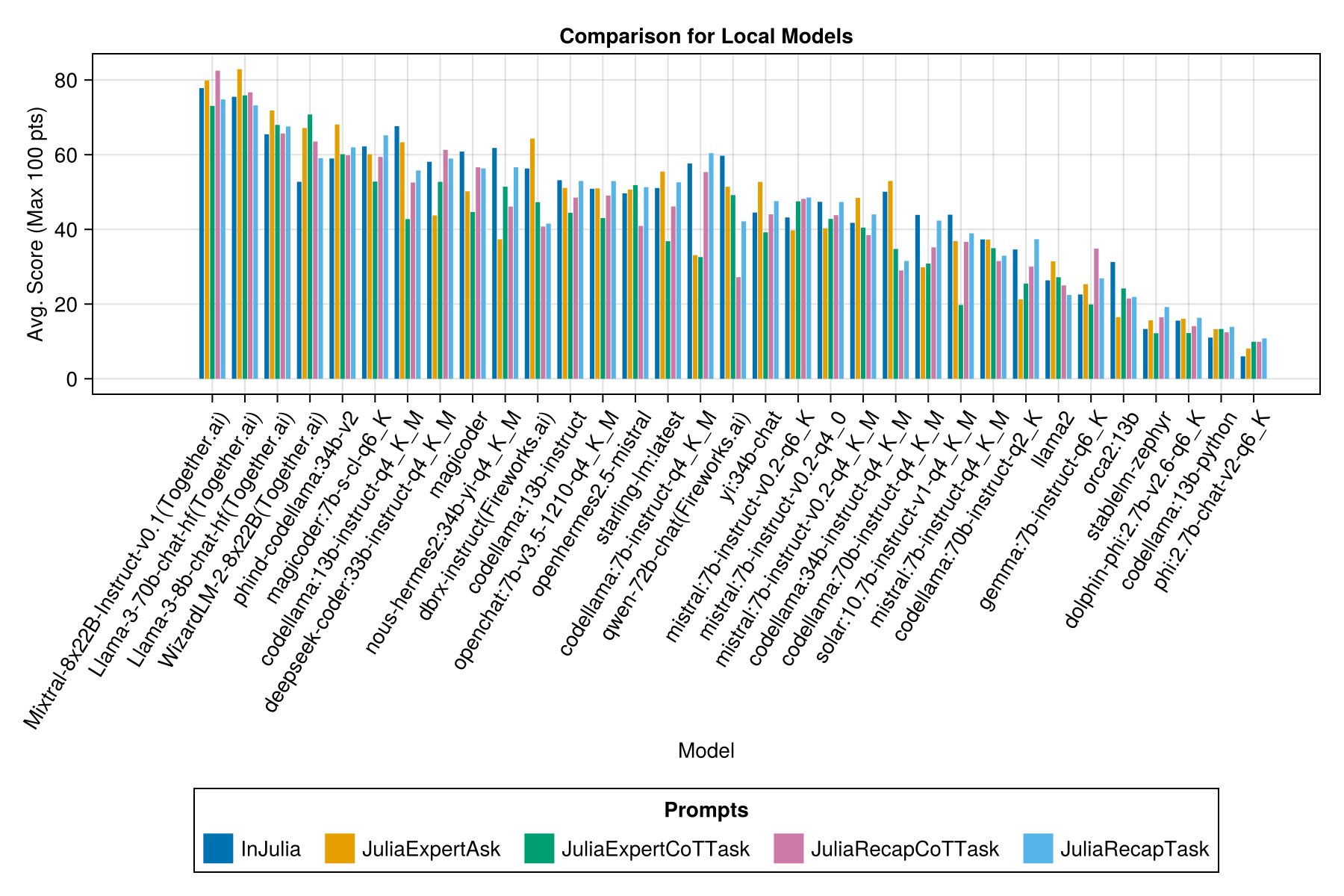
메모
Ollama Repository (및 HF)의 기본 모델이 정확하지 않으며 성능이 매우 낮기 때문에 Qwen-1.5 모델이 개요에서 제거되었습니다.
메모
나는 Ollama/llama.cpp의 일부 EVAL이 이제 12 월 23 일보다 약간 높은 점수를 얻은 것을 알았으므로 위의 evals를 다시 실행하는 로드맵에 있습니다.
분명히 유료 API가 승리 (최신 릴리스 : GPT-3.5-Turbo-11106)이지만 전체 이야기는 아닙니다.
우리는 "JuliaExpert*"프롬프트 템플릿을 사용하는 것이 언제 더 낫습니까? XYZ XYZ "프롬프트를"JuliaExpert*"프롬프트 템플릿을 사용하는 것이 언제 더 나은지에 대한 지침을 제공 할 수 있기를 희망합니다.
지금까지 학습 :
| 프롬프트 템플릿 | 경과 (S, 평균) | 경과 (S, 중앙값) | avg. 점수 (최대 100 점) | 중간 점수 (최대 100 점) |
|---|---|---|---|---|
| 부상 | 14.0 | 9.6 | 55.2 | 50.0 |
| JuliaExperTask | 9.9 | 6.4 | 53.8 | 50.0 |
| 줄리아 캡스크 | 16.7 | 11.5 | 52.0 | 50.0 |
| JuliaExpertcottask | 15.4 | 10.4 | 49.5 | 50.0 |
| Juliarecapcottask | 16.1 | 11.3 | 48.6 | 50.0 |
참고 : XML 기반 템플릿은 Claude 3 모델 (Haiku 및 Sonnet)에 대해서만 테스트되므로 비교에서 제거했습니다.
examples/summarize_results.jl 로 나만의 분석을하십시오!
scripts/code_gen_benchmark.jl 점검하십시오. 실험을 실행하고 결과를 저장하고 싶습니까? examples/experiment_hyperparameter_scan.jl 확인하십시오!
과거 벤치 마크 실행 중 일부를 검토하고 싶습니까? 개별 대화/모델 응답을 검토하려면 전체 통계 및 examples/debugging_results.jl _results.jl에 대해서는 examples/summarize_results.jl 확인하십시오.
테스트 사례를 기여하려면 :
code_generation/category/test_case_name/definition.toml 에 따라 중첩 된 폴더를 만듭니다.code_generation/category/test case/model/evaluation__PROMPT__STRATEGY__TIMESTAMP.json 및 code_generation/category/test case/model/conversation__PROMPT__STRATEGY__TIMESTAMP.json 과 같은 모델 이름으로 중첩 된 경로에 저장합니다.definition.toml 의 해부학 definition.toml 의 필수 필드 .toml은 다음과 같습니다.
my_function(1, 2) )을 사용하여 실행 가능한 진술의 벡터로 제공되는 테스트 시나리오.@test X = Z 문의 벡터로 제공되는 코드를 검증하기위한 테스트.몇 가지 선택 필드가 있습니다.
위의 필드는 예/단위 테스트에서 코드 재사용을 개선 할 수 있습니다.
examples/create_definition.jl 의 예를 참조하십시오. validate_definition() 로 테스트 사례 정의를 검증 할 수 있습니다.
폴더 julia_conversations/ 에서 Julia와 관련하여/in/About Julia와 관련하여 관련성 있고 대부분 올바른 대화를 추가하십시오.
목표는 소규모 모델에서 Julia 지식을 미세 조정하는 데 유용한 대화 모음을 보는 것입니다.
우리는 지역 사회 입력을 많이 가치가 있습니다. 개선을위한 제안이나 아이디어가 있으면 문제를여십시오. 모든 기부금을 환영합니다!


