Julia LLM Leaderboard
v0.2.0
Comparison of Julia language generation capabilities of various Large Language Models
definition.tomlWelcome to the Julia Code Generation Benchmark Repository!
This project is designed for the Julia community to compare the code generation capabilities of various AI models. Unlike academic benchmarks, our focus is practicality and simplicity: "Generate code, run it, and see if it works(-ish)."
This repository aims to understand how different AI models and prompting strategies perform in generating syntactically correct Julia code to guide users in choosing the best model for their needs.
Itchy fingers? Jump to examples/ or just run your own benchmark with run_benchmark() (eg, examples/code_gen_benchmark.jl).
Test cases are defined in a definition.toml file, providing a standard structure for each test. If you want to contribute a test case, please follow the instructions in the Contributing Your Test Case section.
Each model's and prompt's performance is evaluated based on several criteria:
At the moment, all criteria are weighed equally and each test case can earn a maximum of 100 points. If a code passes all criteria, it gets 100/100 points. If it fails one criterion (eg, all unit tests), it gets 75/100 points. If it fails two criteria (eg, it runs but all examples and unit tests are broken), it gets 50 points, and so on.
To provide a glimpse of the repository's functionality, we have included example results for the first 14 test cases. Open the documentation for the full results and a deep dive on each test case.
Warning
These scores might change as we evolve the supporting functionality and add more models.
Remember that the benchmark is quite challenging for any model - a single extra space or parentheses and the score might become 0 (="unable to parse")!
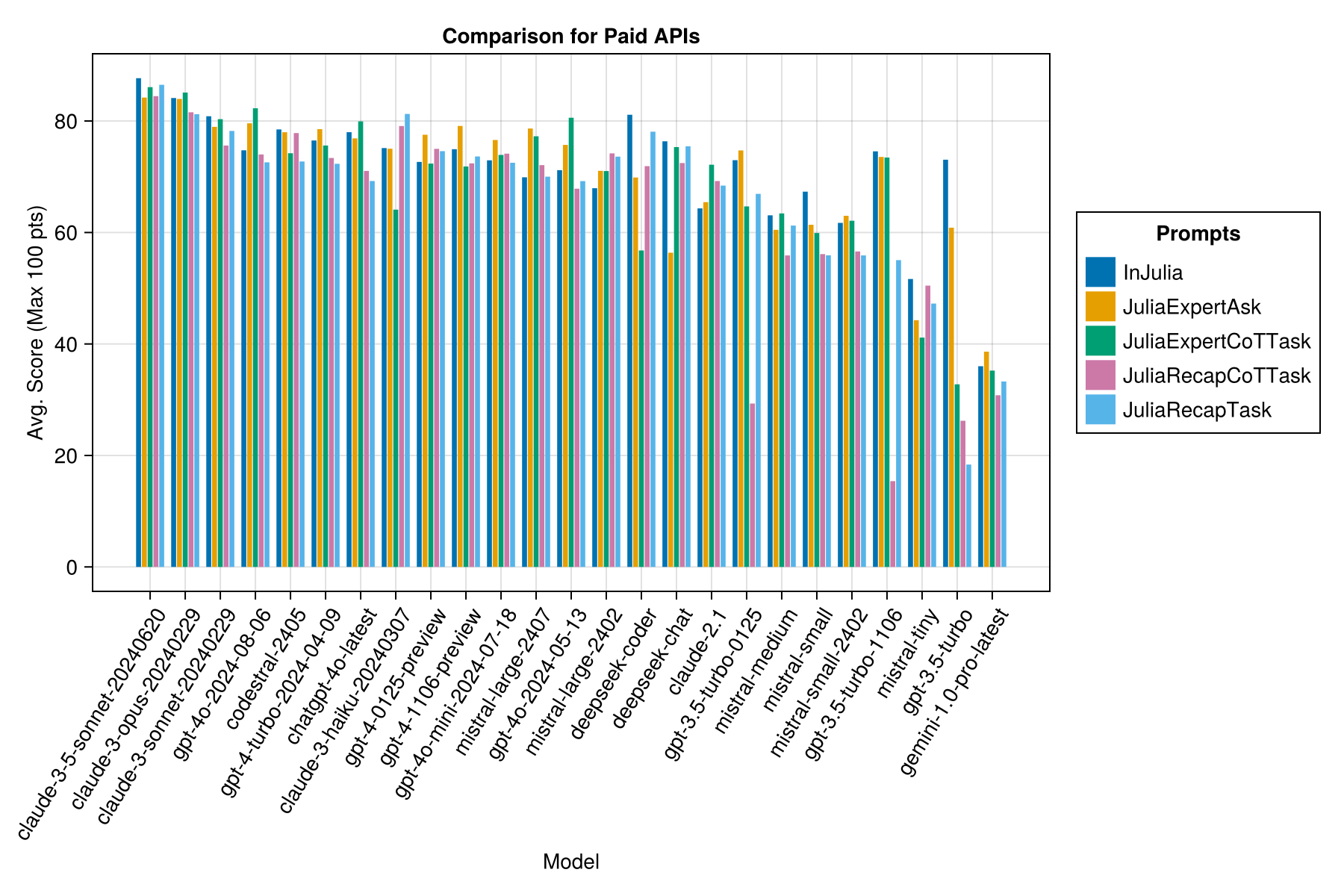
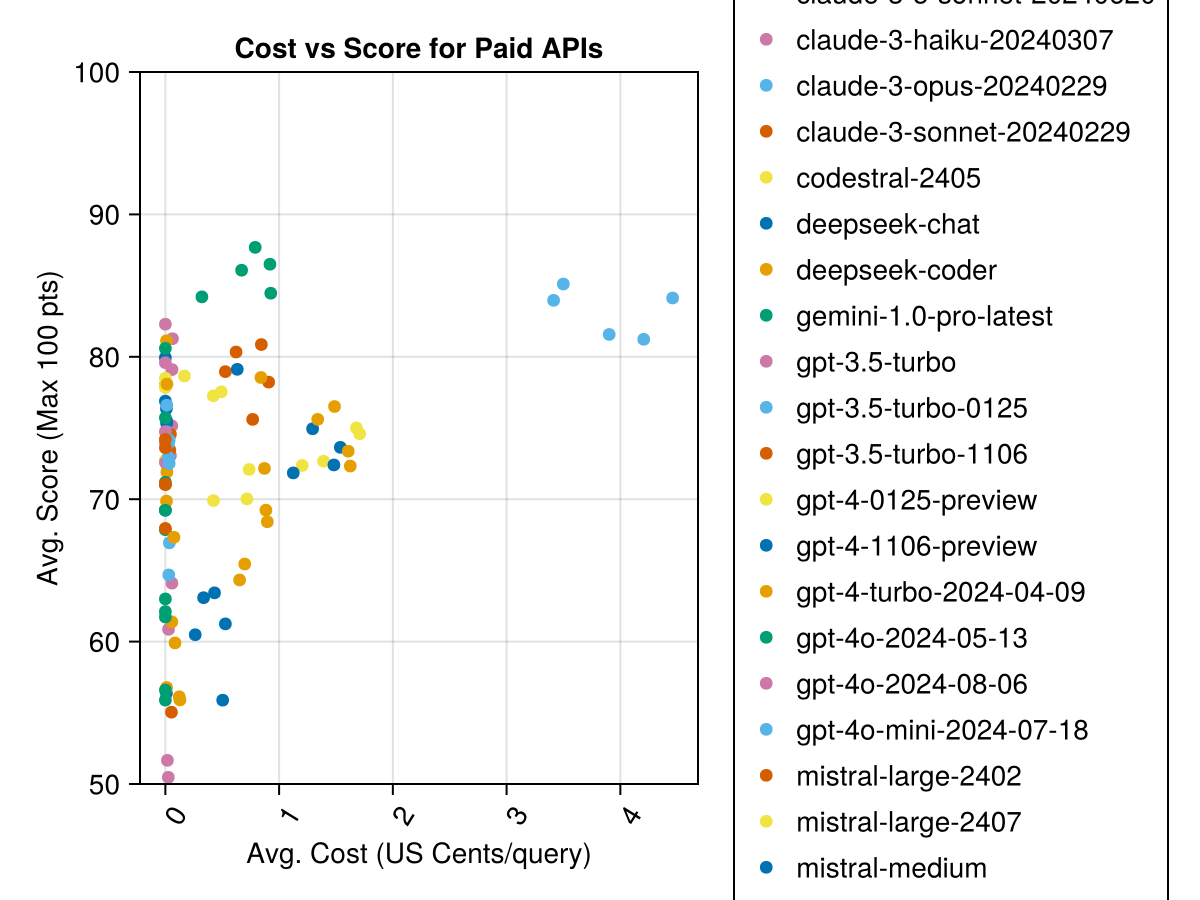
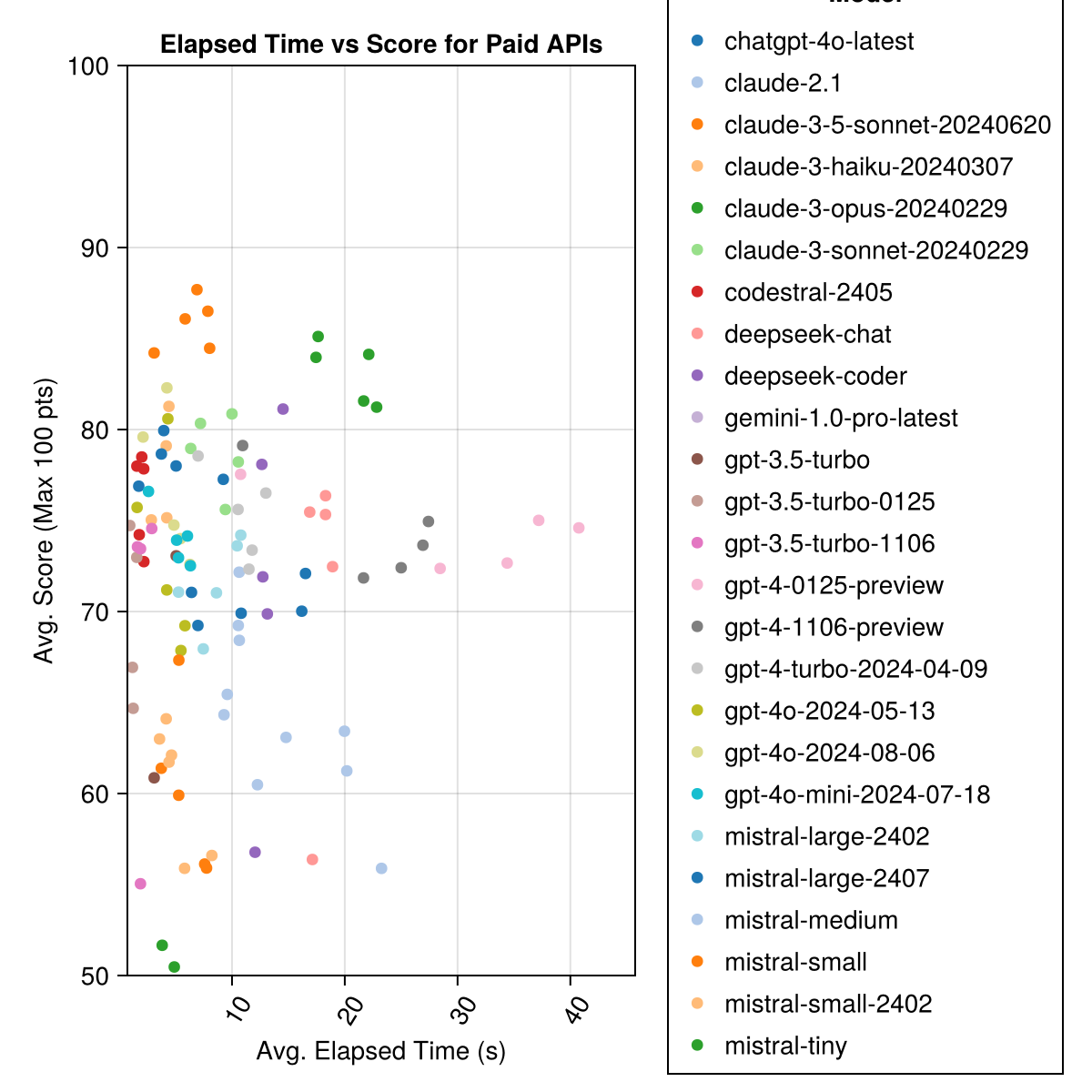
Claude 3.5 Sonnet is the highest-performing model. For the best value-for-money, look to Mistral Codestral, Claude 3 Haiku and, recently released, GPT 4o mini (60% cheaper than GPT3.5!!!).
| Model | Elapsed | Score | Score Std Deviation | Count Zero Score | Count Full Score | Cost Cents |
|---|---|---|---|---|---|---|
| claude-3-5-sonnet-20240620 | 6.3 | 85.8 | 21.1 | 13 | 355 | 0.73 |
| claude-3-opus-20240229 | 20.3 | 83.2 | 19.6 | 2 | 329 | 3.9 |
| claude-3-sonnet-20240229 | 8.7 | 78.8 | 26.2 | 22 | 308 | 0.73 |
| gpt-4o-2024-08-06 | 4.6 | 76.6 | 27.9 | 26 | 310 | 0.0 |
| codestral-2405 | 1.9 | 76.3 | 29.3 | 33 | 276 | 0.0 |
| gpt-4-turbo-2024-04-09 | 10.8 | 75.3 | 29.6 | 38 | 290 | 1.38 |
| chatgpt-4o-latest | 4.8 | 75.0 | 27.9 | 25 | 263 | 0.0 |
| claude-3-haiku-20240307 | 4.0 | 74.9 | 27.2 | 9 | 261 | 0.05 |
| gpt-4-0125-preview | 30.3 | 74.4 | 30.3 | 39 | 284 | 1.29 |
| gpt-4-1106-preview | 22.4 | 74.4 | 29.9 | 19 | 142 | 1.21 |
| gpt-4o-mini-2024-07-18 | 5.1 | 74.0 | 29.4 | 32 | 276 | 0.03 |
| mistral-large-2407 | 11.3 | 73.6 | 29.5 | 15 | 137 | 0.49 |
| gpt-4o-2024-05-13 | 4.3 | 72.9 | 29.1 | 29 | 257 | 0.0 |
| deepseek-coder | 13.0 | 71.6 | 32.6 | 39 | 115 | 0.01 |
| mistral-large-2402 | 8.5 | 71.6 | 27.2 | 13 | 223 | 0.0 |
| deepseek-chat | 17.9 | 71.3 | 32.9 | 30 | 140 | 0.01 |
| claude-2.1 | 10.1 | 67.9 | 30.8 | 47 | 229 | 0.8 |
| gpt-3.5-turbo-0125 | 1.2 | 61.7 | 36.6 | 125 | 192 | 0.03 |
| mistral-medium | 18.1 | 60.8 | 33.2 | 22 | 90 | 0.41 |
| mistral-small | 5.9 | 60.1 | 30.2 | 27 | 76 | 0.09 |
| mistral-small-2402 | 5.3 | 59.9 | 29.4 | 31 | 169 | 0.0 |
| gpt-3.5-turbo-1106 | 2.1 | 58.4 | 39.2 | 82 | 97 | 0.04 |
| mistral-tiny | 4.6 | 46.9 | 32.0 | 75 | 42 | 0.02 |
| gpt-3.5-turbo | 3.6 | 42.3 | 38.2 | 132 | 54 | 0.04 |
| gemini-1.0-pro-latest | 4.2 | 34.8 | 27.4 | 181 | 25 | 0.0 |
Note: From mid-February 2024, "gpt-3.5-turbo" will point to the latest release, "gpt-3.5-turbo-0125" (deprecating the June release).
Same information, but as a bar chart:
In addition, we can consider the performance (score) versus the cost (measured in US cents):
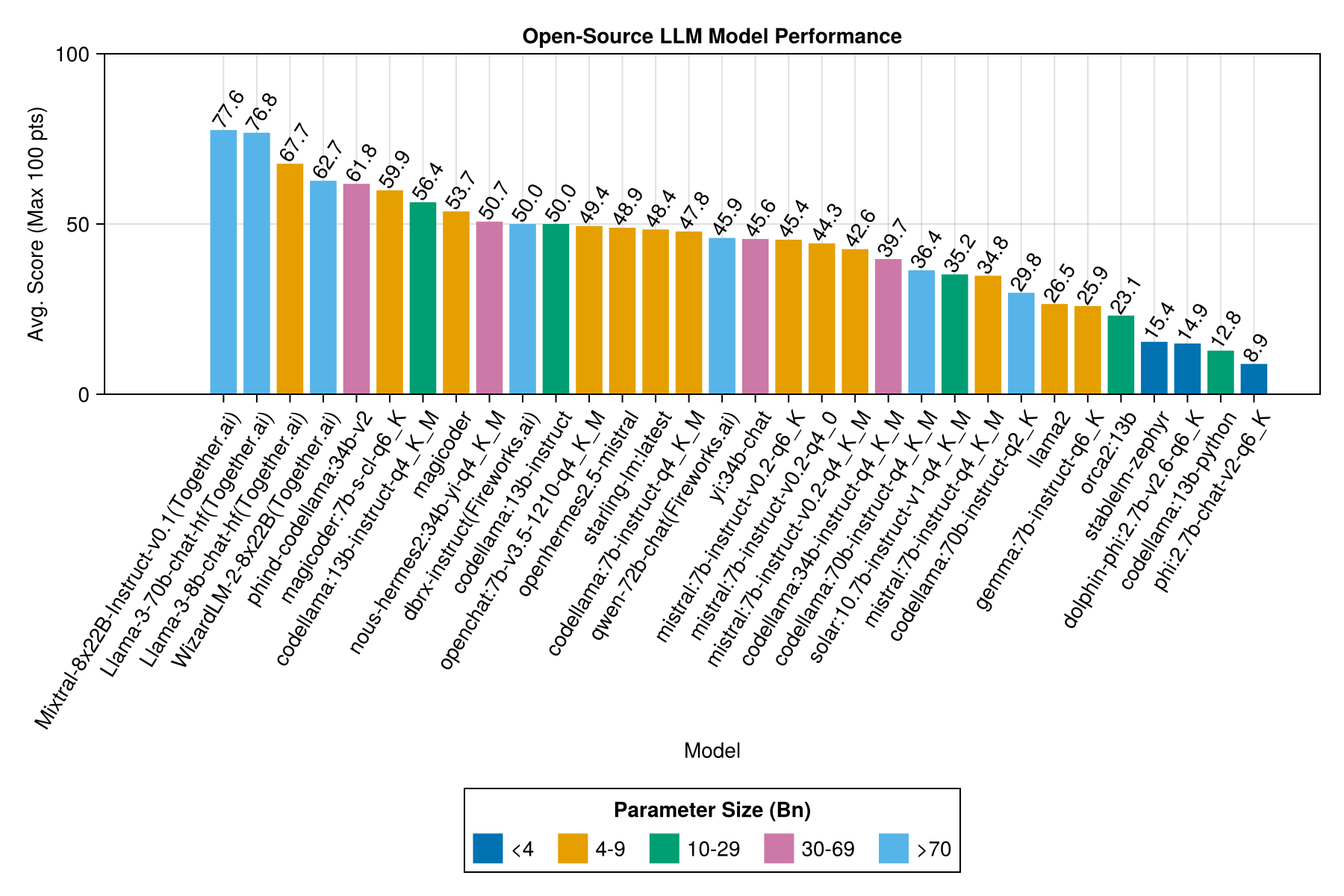
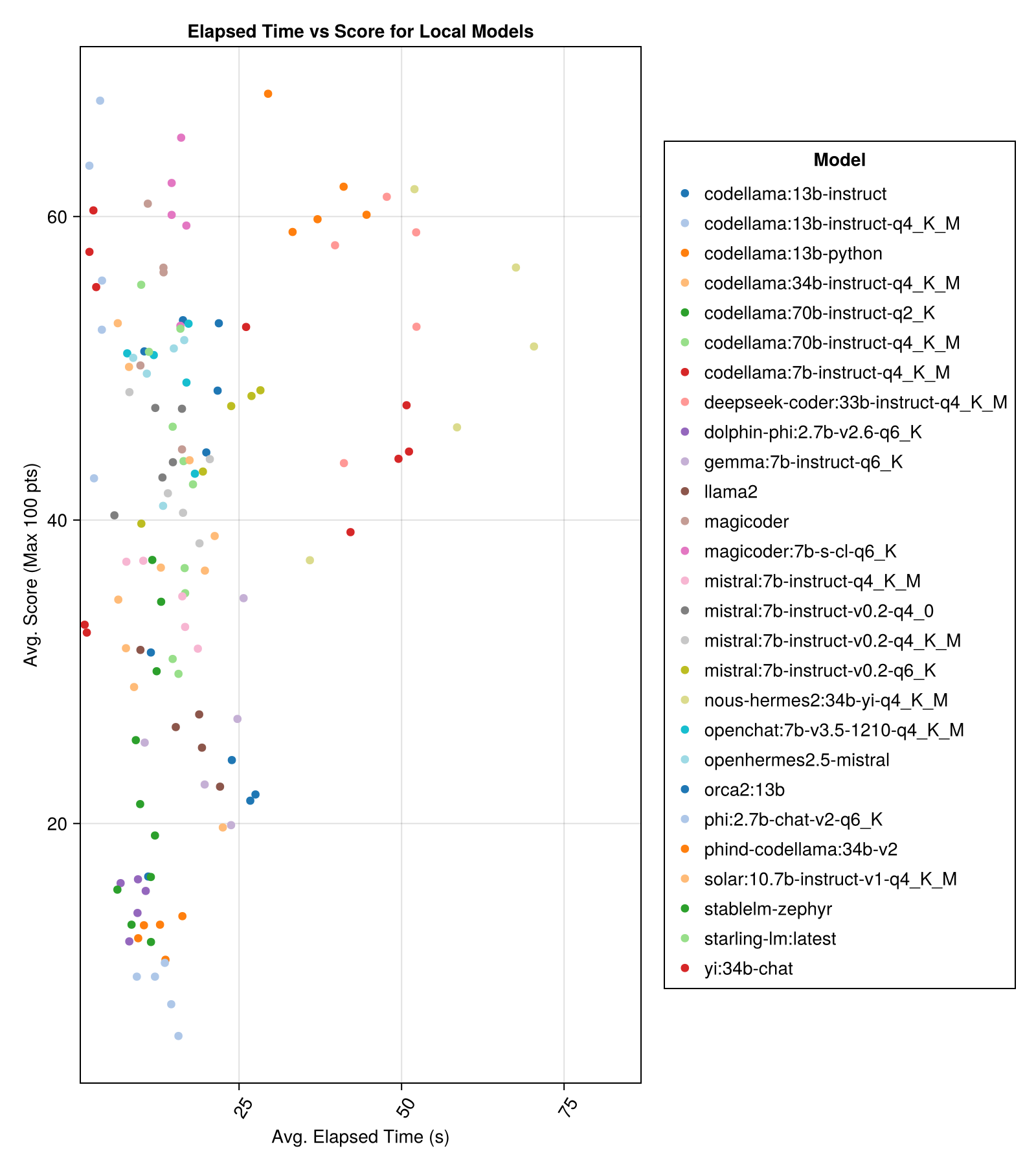
Locally-hosted models are generally not as good as the best paid APIs, but they are getting close! Note that the "mistral-small" is already available to be run locally and there will be many future finetunes!
Note
Big thank you to 01.ai and Jun Tian in particular for providing the compute for several parts of this benchmark!
The best trade-off performance vs size is the latest Meta llama3 8bn. Otherwise, the leading model is Mixtral-8x22bn.
| Model | Elapsed | Elapsed Median | Score | Score Median | Score Std Deviation | Count Zero Score | Count Full Score |
|---|---|---|---|---|---|---|---|
| Mixtral-8x22B-Instruct-v0.1(Together.ai) | 14.1 | 11.0 | 77.6 | 90.0 | 25.8 | 5.0 | 151.0 |
| Llama-3-70b-chat-hf(Together.ai) | 4.3 | 4.1 | 76.8 | 88.3 | 25.2 | 0.0 | 160.0 |
| Llama-3-8b-chat-hf(Together.ai) | 1.5 | 1.4 | 67.7 | 66.7 | 26.4 | 5.0 | 70.0 |
| WizardLM-2-8x22B(Together.ai) | 34.7 | 31.0 | 62.7 | 60.0 | 33.8 | 33.0 | 118.0 |
| phind-codellama:34b-v2 | 37.1 | 36.4 | 61.8 | 62.5 | 33.5 | 36.0 | 58.0 |
| magicoder:7b-s-cl-q6_K | 15.6 | 15.8 | 59.9 | 60.0 | 29.9 | 18.0 | 35.0 |
| codellama:13b-instruct-q4_K_M | 3.2 | 3.0 | 56.4 | 54.6 | 33.0 | 56.0 | 61.0 |
| deepseek-coder:33b-instruct-q4_K_M | 46.7 | 44.6 | 55.0 | 50.0 | 36.8 | 62.0 | 68.0 |
| magicoder | 12.8 | 10.7 | 53.7 | 50.0 | 33.2 | 49.0 | 52.0 |
| nous-hermes2:34b-yi-q4_K_M | 56.8 | 52.8 | 50.7 | 50.0 | 34.7 | 78.0 | 56.0 |
| dbrx-instruct(Fireworks.ai) | 3.7 | 3.6 | 50.0 | 50.0 | 41.2 | 121.0 | 75.0 |
| codellama:13b-instruct | 18.1 | 16.7 | 50.0 | 50.0 | 34.4 | 65.0 | 44.0 |
| openchat:7b-v3.5-1210-q4_K_M | 14.4 | 13.7 | 49.4 | 50.0 | 30.3 | 48.0 | 23.0 |
| openhermes2.5-mistral | 12.9 | 12.2 | 48.9 | 50.0 | 31.3 | 55.0 | 27.0 |
| starling-lm:latest | 13.7 | 12.5 | 48.4 | 50.0 | 30.2 | 58.0 | 26.0 |
| codellama:7b-instruct-q4_K_M | 2.1 | 2.0 | 47.8 | 50.0 | 35.3 | 95.0 | 38.0 |
| qwen-72b-chat(Fireworks.ai) | 3.2 | 3.8 | 45.9 | 50.0 | 38.8 | 117.0 | 63.0 |
| yi:34b-chat | 43.9 | 41.3 | 45.6 | 50.0 | 30.5 | 45.0 | 34.0 |
| mistral:7b-instruct-v0.2-q6_K | 21.7 | 20.9 | 45.4 | 50.0 | 31.3 | 44.0 | 23.0 |
| mistral:7b-instruct-v0.2-q4_0 | 12.4 | 12.3 | 44.3 | 50.0 | 30.6 | 75.0 | 32.0 |
| mistral:7b-instruct-v0.2-q4_K_M | 15.6 | 15.1 | 42.6 | 50.0 | 28.6 | 71.0 | 23.0 |
| codellama:34b-instruct-q4_K_M | 7.5 | 6.8 | 39.7 | 50.0 | 36.1 | 127.0 | 35.0 |
| codellama:70b-instruct-q4_K_M | 16.3 | 13.8 | 36.4 | 0.0 | 41.2 | 179.0 | 58.0 |
| solar:10.7b-instruct-v1-q4_K_M | 18.8 | 17.7 | 35.2 | 50.0 | 31.1 | 107.0 | 10.0 |
| mistral:7b-instruct-q4_K_M | 13.9 | 13.0 | 34.8 | 50.0 | 26.5 | 80.0 | 0.0 |
| codellama:70b-instruct-q2_K | 11.2 | 9.4 | 29.8 | 0.0 | 37.7 | 198.0 | 29.0 |
| llama2 | 17.1 | 16.3 | 26.5 | 25.0 | 26.5 | 131.0 | 0.0 |
| gemma:7b-instruct-q6_K | 20.9 | 22.1 | 25.9 | 25.0 | 25.2 | 147.0 | 2.0 |
| orca2:13b | 20.1 | 18.3 | 23.1 | 0.0 | 30.6 | 166.0 | 11.0 |
| stablelm-zephyr | 9.9 | 7.7 | 15.4 | 0.0 | 23.5 | 192.0 | 1.0 |
| dolphin-phi:2.7b-v2.6-q6_K | 8.9 | 8.4 | 14.9 | 0.0 | 22.9 | 188.0 | 0.0 |
| codellama:13b-python | 12.5 | 10.7 | 12.8 | 0.0 | 22.1 | 155.0 | 0.0 |
| phi:2.7b-chat-v2-q6_K | 13.0 | 11.6 | 8.9 | 0.0 | 19.4 | 222.0 | 0.0 |
Same information, but as a bar chart:
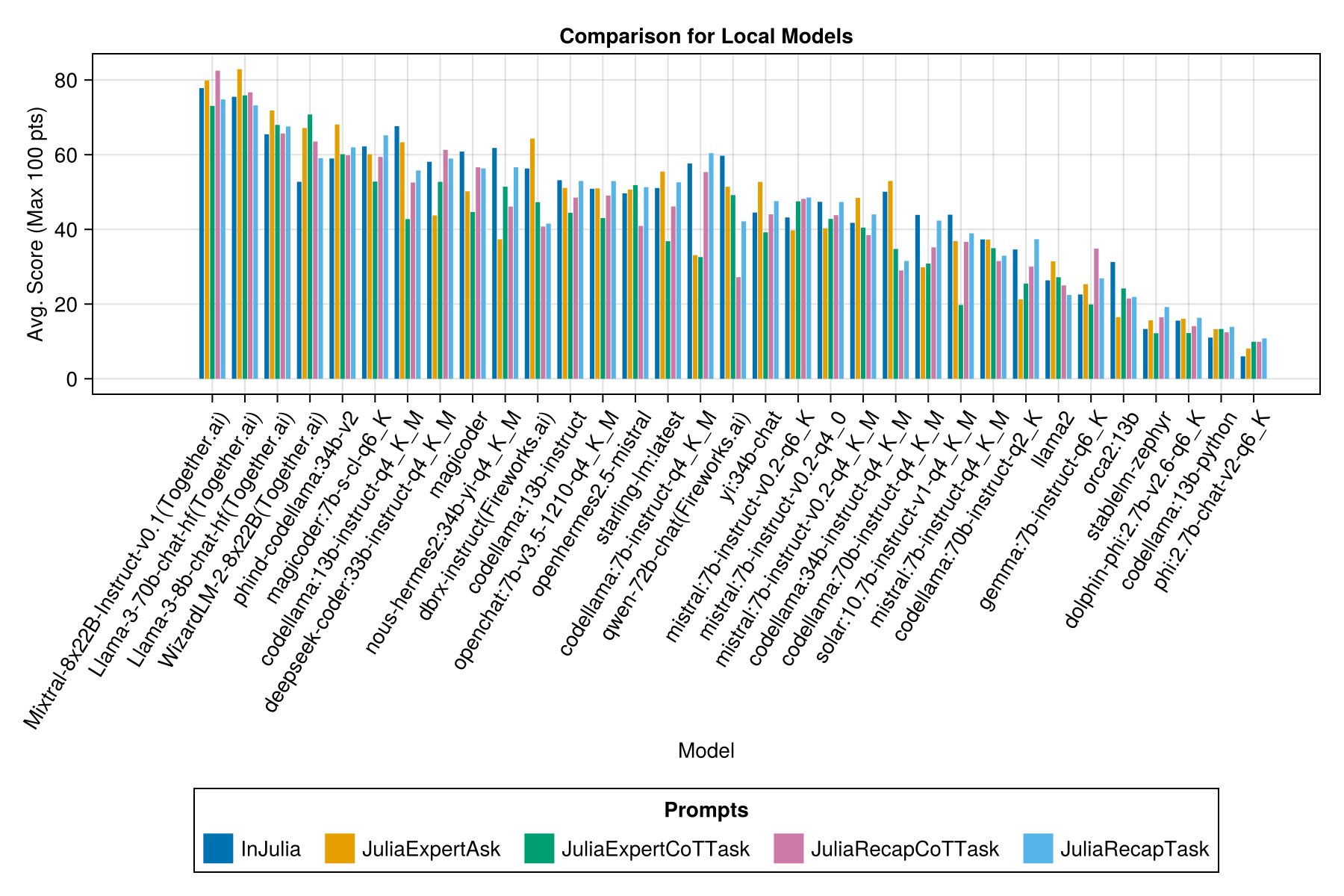
And with a separate bar for each prompt template:
Note
Qwen-1.5 models have been removed from the overviews as the underlying model on Ollama repository (and HF) is not correct and has very low performance.
Note
I have noticed that some evals in Ollama/llama.cpp now score slightly higher now than in Dec-23, so it's on a roadmap to re-run the above evals.
Clearly, the paid APIs win (the latest release: GPT-3.5-Turbo-1106), but that's not the whole story.
We hope to be able to provide some guidance around prompting strategies, eg, when is it better to use a "JuliaExpert*" prompt template vs an "In Julia, answer XYZ" prompt.
Learnings so far:
| Prompt Template | Elapsed (s, average) | Elapsed (s, median) | Avg. Score (Max 100 pts) | Median Score (Max 100 pts) |
|---|---|---|---|---|
| InJulia | 14.0 | 9.6 | 55.2 | 50.0 |
| JuliaExpertAsk | 9.9 | 6.4 | 53.8 | 50.0 |
| JuliaRecapTask | 16.7 | 11.5 | 52.0 | 50.0 |
| JuliaExpertCoTTask | 15.4 | 10.4 | 49.5 | 50.0 |
| JuliaRecapCoTTask | 16.1 | 11.3 | 48.6 | 50.0 |
Note: The XML-based templates are tested only for Claude 3 models (Haiku and Sonnet), that's why we removed them from the comparison.
Make your own analysis with examples/summarize_results.jl!
scripts/code_gen_benchmark.jl for the example of previous evaluations.Want to run some experiments and save the results? Check out examples/experiment_hyperparameter_scan.jl!
Want to review some of the past benchmark runs? Check out examples/summarize_results.jl for overall statistics and examples/debugging_results.jl for reviewing the individual conversations/model responses.
To contribute a test case:
code_generation/category/test_case_name/definition.toml.code_generation/category/test case/model/evaluation__PROMPT__STRATEGY__TIMESTAMP.json and code_generation/category/test case/model/conversation__PROMPT__STRATEGY__TIMESTAMP.jsondefinition.tomlRequired fields in definition.toml include:
my_function(1, 2)).@test X = Z statements.There are several optional fields:
The above fields can improve re-use of code across the examples/unit tests.
See an example in examples/create_definition.jl.
You can validate your test case definitions with validate_definition().
Please PR and add any relevant and MOSTLY CORRECT conversations with/in/about Julia in folder julia_conversations/.
The goal is to have a collection of conversations that are useful for finetuning Julia knowledge in smaller models.
We highly value community input. If you have suggestions or ideas for improvement, please open an issue. All contributions are welcome!


