Julia LLM Leaderboard
v0.2.0
Сравнение возможностей генерации языка Юлии различных крупных языковых моделей
definition.tomlДобро пожаловать в хранилище генерации кода Юлии!
Этот проект предназначен для сообщества Юлии, чтобы сравнить возможности генерации кода различных моделей искусственного интеллекта. В отличие от академических критериев, наше внимание уделяется практичности и простоте: «Создайте код, запустите его и посмотрите, работает ли он (-ish)».
Этот репозиторий направлено на то, чтобы понять, как различные модели ИИ и стратегии подсказки работают при создании синтаксически правильного кода Юлии, чтобы направлять пользователей при выборе лучшей модели для их потребностей.
Зудящие пальцы? Перейдите к examples/ или просто запустите свой собственный эталон с помощью run_benchmark() (например, examples/code_gen_benchmark.jl ).
Тестовые примеры определены в файле definition.toml , предоставляя стандартную структуру для каждого теста. Если вы хотите внести тестовый пример, пожалуйста, следуйте инструкциям в разделе «Соответствие в вашем тестовом примере».
Производительность каждой модели и подсказки оценивается на основе нескольких критериев:
На данный момент все критерии взвешиваются одинаково, и каждый тестовый пример может заработать максимум 100 баллов. Если код выполняет все критерии, он получает 100/100 баллов. Если он не удается один критерий (например, все модульные тесты), он получает 75/100 баллов. Если он не выполняет два критерия (например, он работает, но все примеры и модульные тесты сломаны), он получает 50 баллов и так далее.
Чтобы дать представление о функциональности хранилища, мы включили пример результатов для первых 14 тестовых случаев. Откройте документацию для полных результатов и глубокое погружение по каждому тестовому примеру.
Предупреждение
Эти оценки могут измениться, когда мы развиваем функциональность поддержки и добавляем больше моделей.
Помните, что эталон довольно сложный для любой модели - одно дополнительное пространство или скобки, и счет может стать 0 (= «Невозможно разобрать»)!
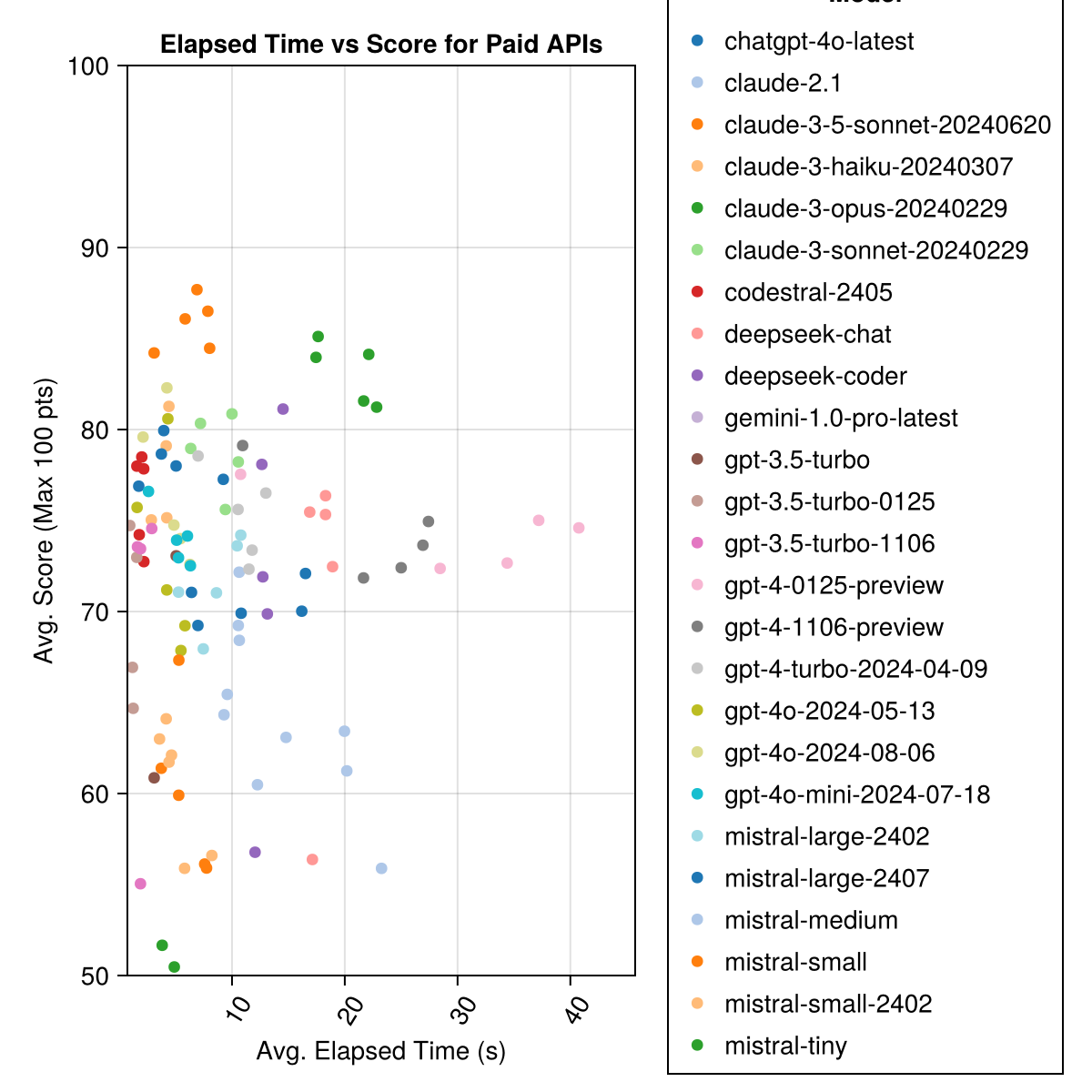
Claude 3.5 Sonnet-модель с самым высоким показателем. Для наилучшей ценности для денег посмотрите на Mistral Codestral, Claude 3 Haiku и, недавно выпущенный, GPT 4O Mini (60% дешевле, чем GPT3.5 !!!).
| Модель | Прошло | Счет | Оценка отклонений STD | Счет нулевой оценка | Считайте полную оценку | Стоимость центов |
|---|---|---|---|---|---|---|
| Claude-3-5-Sonnet-201240620 | 6.3 | 85,8 | 21.1 | 13 | 355 | 0,73 |
| Claude-3-Opus-201240229 | 20.3 | 83,2 | 19.6 | 2 | 329 | 3.9 |
| Claude-3-Sonnet-20240229 | 8.7 | 78.8 | 26.2 | 22 | 308 | 0,73 |
| GPT-4o-2024-08-06 | 4.6 | 76.6 | 27,9 | 26 | 310 | 0,0 |
| Codestral-2405 | 1.9 | 76.3 | 29.3 | 33 | 276 | 0,0 |
| GPT-4-Turbo-2024-04-09 | 10.8 | 75.3 | 29,6 | 38 | 290 | 1.38 |
| Chatgpt-4o-latest | 4.8 | 75.0 | 27,9 | 25 | 263 | 0,0 |
| Claude-3-haiku-201240307 | 4.0 | 74,9 | 27.2 | 9 | 261 | 0,05 |
| GPT-4-0125-Preview | 30.3 | 74.4 | 30.3 | 39 | 284 | 1.29 |
| GPT-4-1106-Preview | 22.4 | 74.4 | 29,9 | 19 | 142 | 1.21 |
| GPT-4O-MINI-2024-07-18 | 5.1 | 74.0 | 29,4 | 32 | 276 | 0,03 |
| Мистраль-Ларж-2407 | 11.3 | 73,6 | 29,5 | 15 | 137 | 0,49 |
| GPT-4o-2024-05-13 | 4.3 | 72,9 | 29.1 | 29 | 257 | 0,0 |
| DeepSeek-Coder | 13.0 | 71.6 | 32,6 | 39 | 115 | 0,01 |
| Мистраль-Ларж-2402 | 8.5 | 71.6 | 27.2 | 13 | 223 | 0,0 |
| DeepSeek-Chat | 17.9 | 71.3 | 32,9 | 30 | 140 | 0,01 |
| Клод-2,1 | 10.1 | 67.9 | 30.8 | 47 | 229 | 0,8 |
| GPT-3.5-Turbo-0125 | 1.2 | 61.7 | 36.6 | 125 | 192 | 0,03 |
| Миштраль-Мидий | 18.1 | 60,8 | 33,2 | 22 | 90 | 0,41 |
| Мистраль-Смалл | 5.9 | 60.1 | 30.2 | 27 | 76 | 0,09 |
| Мистраль-Смалл-2402 | 5.3 | 59,9 | 29,4 | 31 | 169 | 0,0 |
| GPT-3.5-Turbo-1106 | 2.1 | 58.4 | 39.2 | 82 | 97 | 0,04 |
| Мистерал-пятнистый | 4.6 | 46.9 | 32,0 | 75 | 42 | 0,02 |
| GPT-3.5-Turbo | 3.6 | 42.3 | 38.2 | 132 | 54 | 0,04 |
| Близнецы-1,0-про-лат | 4.2 | 34,8 | 27.4 | 181 | 25 | 0,0 |
Примечание. С середины февраля 2024 года «GPT-3.5-Turbo» укажет на последний выпуск «GPT-3.5-Turbo-0125» (выпустив июньский релиз).
Та же информация, но в качестве барной карты:
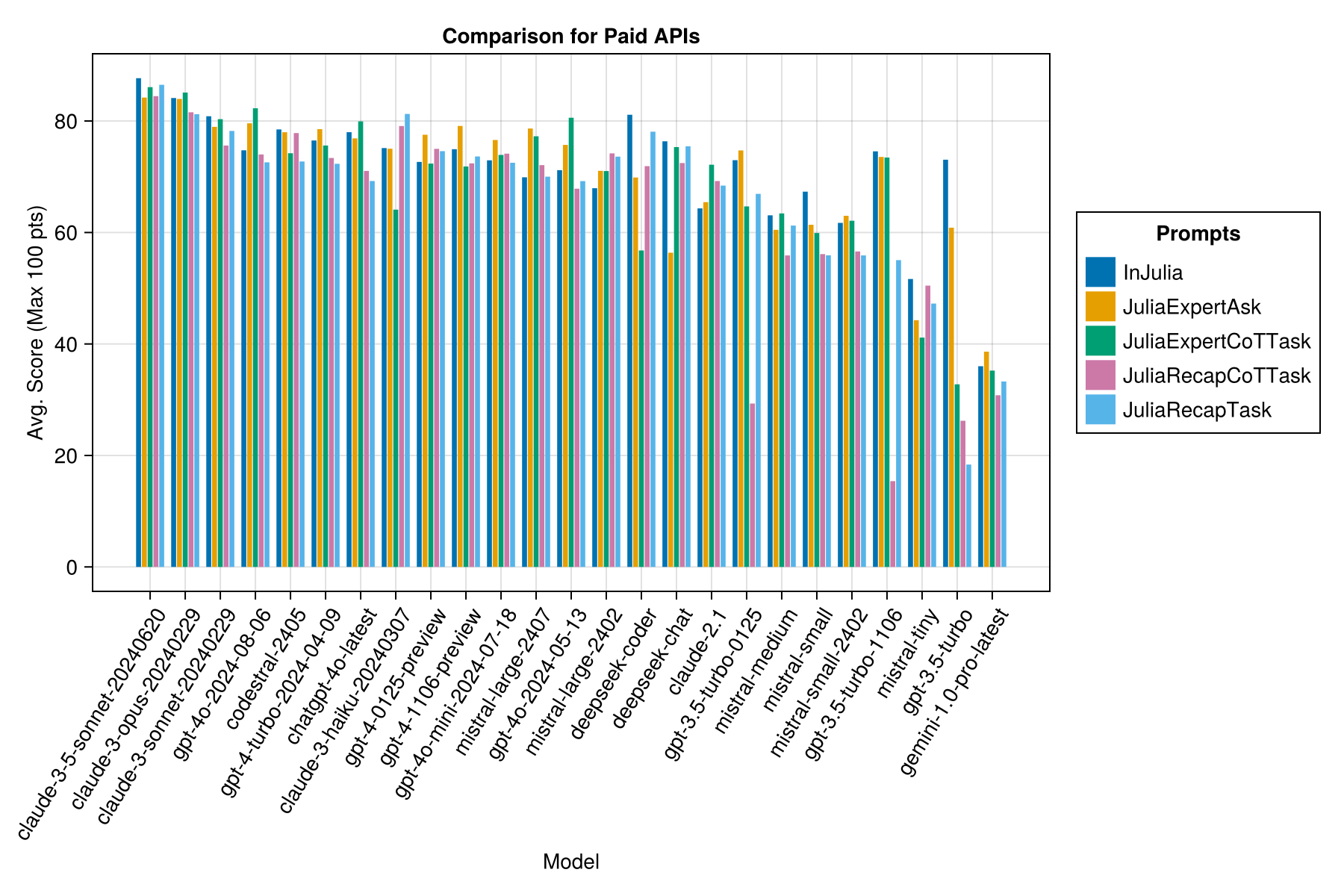
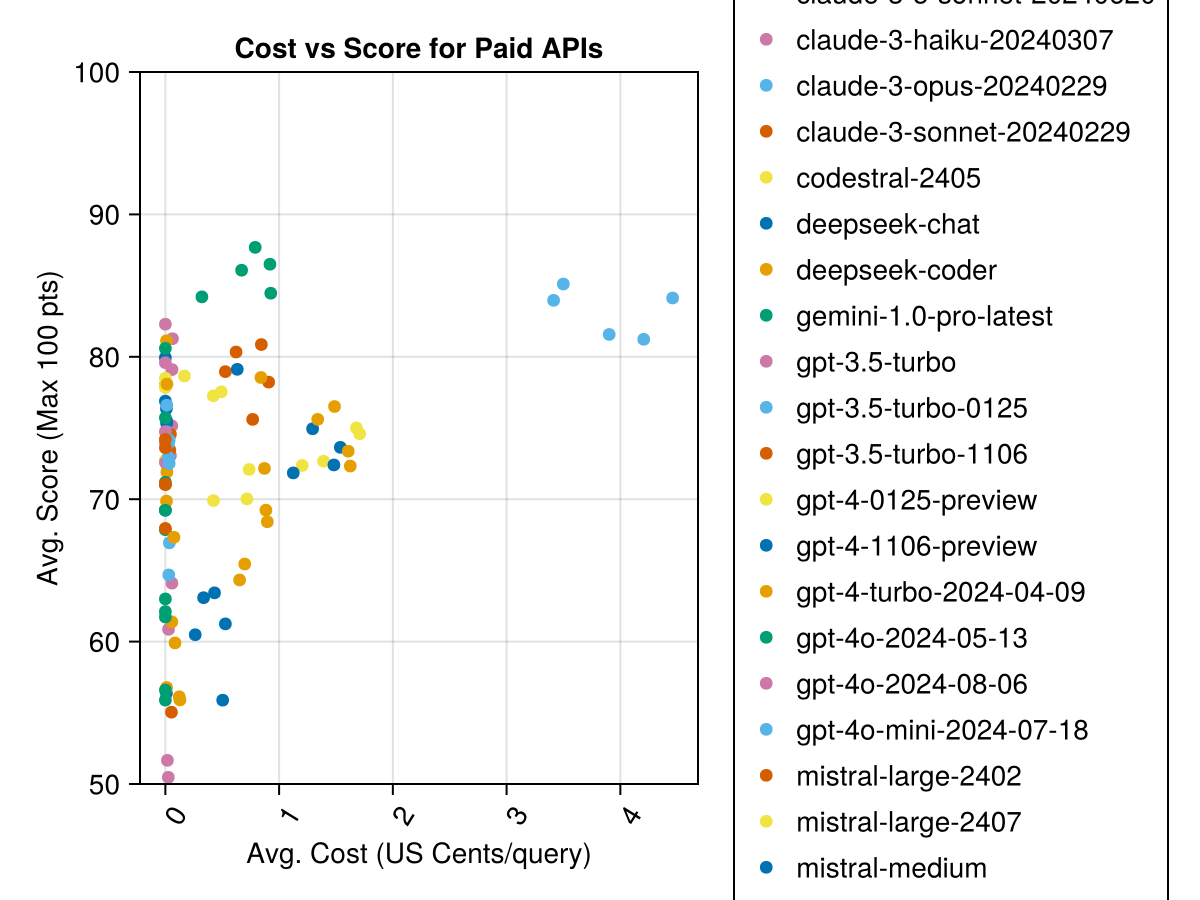
Кроме того, мы можем рассмотреть производительность (оценка) по сравнению с стоимостью (измеренная в центах США):
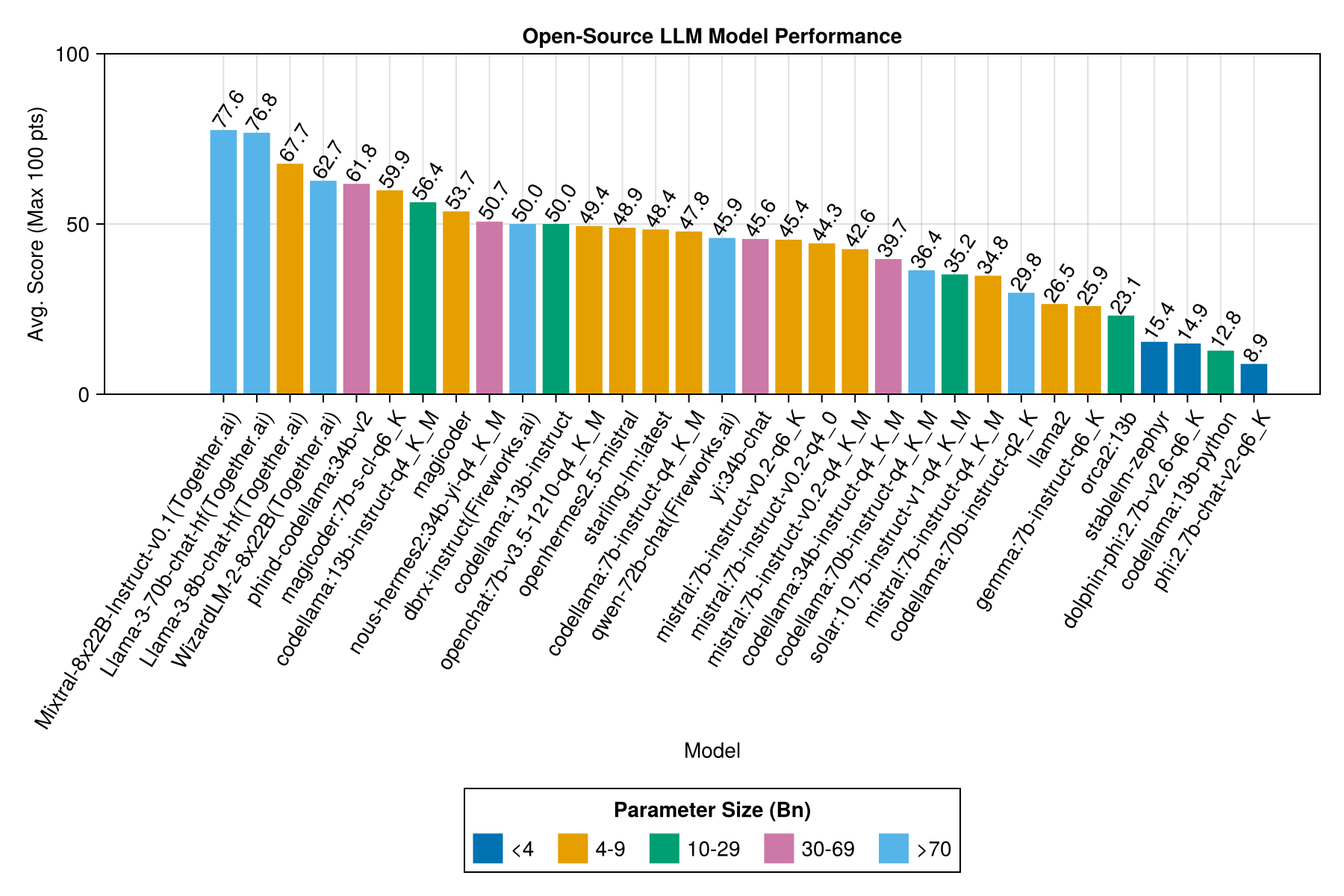
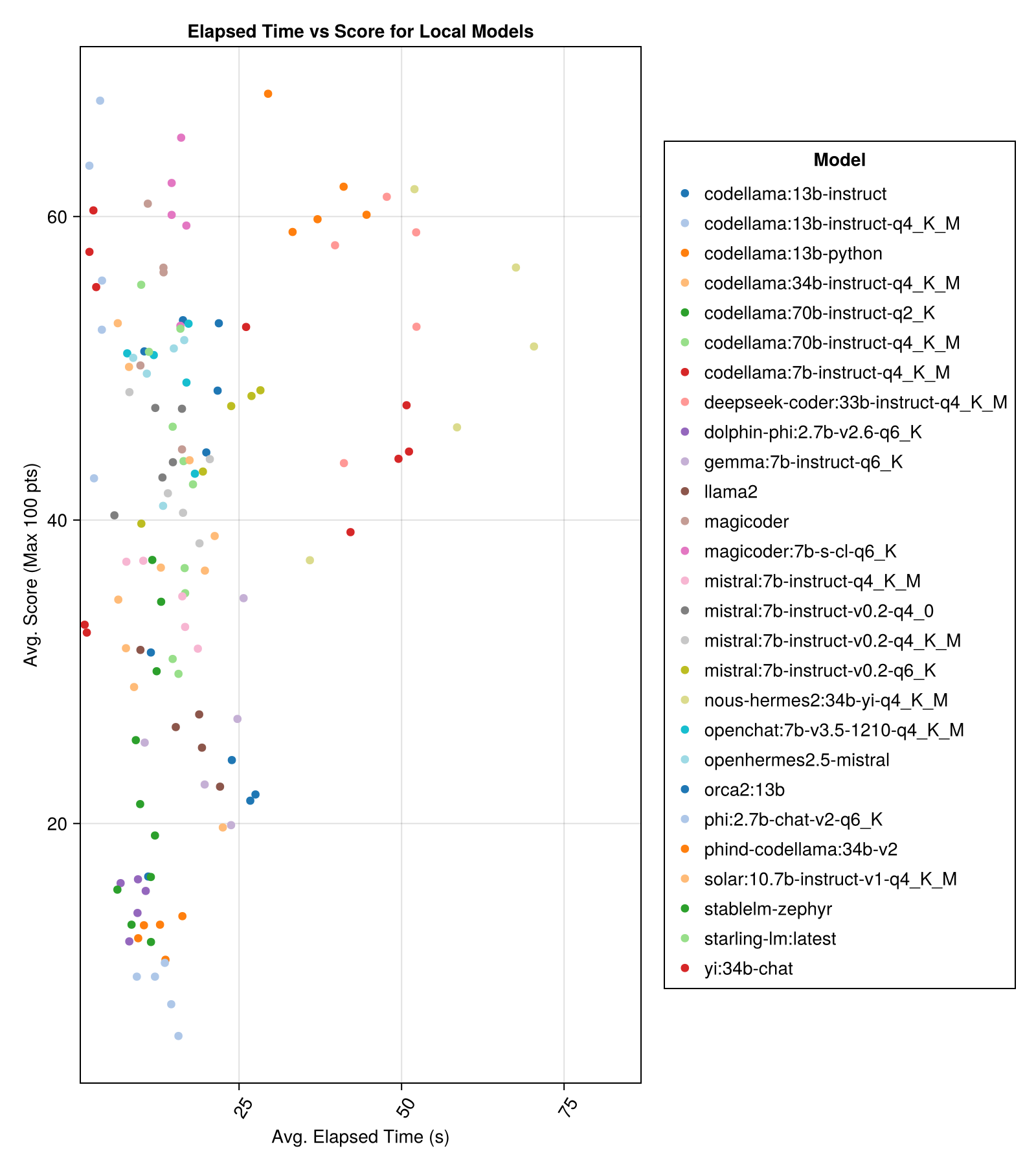
Местные модели, как правило, не так хороши, как лучшие платные API, но они приближаются! Обратите внимание, что «Мистерал-Смалл» уже доступен для запуска на местном уровне, и будет много будущих финал!
Примечание
Большое спасибо 01.ai и Jun Tian, в частности, за предоставление вычислителя для нескольких частей этого эталона!
Лучший компромисс против размера-это последний Meta Llama3 8bn. В противном случае, ведущей моделью является Mixtral-8x22bn.
| Модель | Прошло | Прошедший медиана | Счет | Медиана счета | Оценка отклонений STD | Счет нулевой оценка | Считайте полную оценку |
|---|---|---|---|---|---|---|---|
| Mixtral-8x22b-Instruct-V0.1 (keela.ai) | 14.1 | 11.0 | 77.6 | 90.0 | 25.8 | 5.0 | 151.0 |
| Llama-3-70b-chat-hf (keela.ai) | 4.3 | 4.1 | 76.8 | 88.3 | 25.2 | 0,0 | 160.0 |
| Llama-3-8b-chat-hf (keeld.ai) | 1.5 | 1.4 | 67.7 | 66.7 | 26.4 | 5.0 | 70.0 |
| Wizardlm-2-8x22b (keally.ai) | 34.7 | 31.0 | 62,7 | 60.0 | 33,8 | 33,0 | 118.0 |
| Phind-Codellama: 34B-V2 | 37.1 | 36.4 | 61.8 | 62,5 | 33,5 | 36.0 | 58.0 |
| Magicoder: 7b-s-cl-q6_k | 15.6 | 15.8 | 59,9 | 60.0 | 29,9 | 18.0 | 35,0 |
| Коделлама: 13b-instruct-q4_k_m | 3.2 | 3.0 | 56.4 | 54,6 | 33,0 | 56.0 | 61.0 |
| DeepSeek-Coder: 33B-Instruct-Q4_K_M | 46.7 | 44,6 | 55,0 | 50.0 | 36.8 | 62,0 | 68.0 |
| Magicoder | 12.8 | 10.7 | 53,7 | 50.0 | 33,2 | 49,0 | 52,0 |
| nous-hermes2: 34b-yi-q4_k_m | 56.8 | 52,8 | 50,7 | 50.0 | 34.7 | 78.0 | 56.0 |
| DBRX-Инструкция (Fireworks.ai) | 3.7 | 3.6 | 50.0 | 50.0 | 41.2 | 121.0 | 75.0 |
| Коделлама: 13b-включение | 18.1 | 16.7 | 50.0 | 50.0 | 34.4 | 65,0 | 44,0 |
| OpenChat: 7B-V3.5-1210-Q4_K_M | 14.4 | 13.7 | 49,4 | 50.0 | 30.3 | 48.0 | 23.0 |
| OpenHermes2.5-Mistral | 12.9 | 12.2 | 48.9 | 50.0 | 31.3 | 55,0 | 27.0 |
| Starling-LM: Последний | 13.7 | 12.5 | 48.4 | 50.0 | 30.2 | 58.0 | 26.0 |
| Коделлама: 7b-Instruct-Q4_K_M | 2.1 | 2.0 | 47.8 | 50.0 | 35,3 | 95.0 | 38.0 |
| Qwen-72B-чат (Fireworks.ai) | 3.2 | 3.8 | 45,9 | 50.0 | 38.8 | 117.0 | 63,0 |
| YI: 34B-чат | 43,9 | 41.3 | 45,6 | 50.0 | 30,5 | 45,0 | 34.0 |
| MISTRAL: 7B-Instruct-V0.2-Q6_K | 21,7 | 20.9 | 45,4 | 50.0 | 31.3 | 44,0 | 23.0 |
| MISTRAL: 7B-Instruct-V0.2-Q4_0 | 12.4 | 12.3 | 44.3 | 50.0 | 30.6 | 75.0 | 32,0 |
| MISTRAL: 7B-Instruct-V0.2-Q4_K_M | 15.6 | 15.1 | 42,6 | 50.0 | 28.6 | 71.0 | 23.0 |
| Коделлама: 34B-Instruct-Q4_K_M | 7,5 | 6.8 | 39,7 | 50.0 | 36.1 | 127.0 | 35,0 |
| Коделлама: 70B-Instruct-Q4_K_M | 16.3 | 13.8 | 36.4 | 0,0 | 41.2 | 179,0 | 58.0 |
| Солнечная: 10.7b-instruct-v1-q4_k_m | 18.8 | 17.7 | 35,2 | 50.0 | 31.1 | 107.0 | 10.0 |
| MISTRAL: 7B-Instruct-Q4_K_M | 13.9 | 13.0 | 34,8 | 50.0 | 26.5 | 80.0 | 0,0 |
| Коделлама: 70B-Instruct-Q2_K | 11.2 | 9.4 | 29,8 | 0,0 | 37.7 | 198.0 | 29,0 |
| лама2 | 17.1 | 16.3 | 26.5 | 25.0 | 26.5 | 131.0 | 0,0 |
| Джемма: 7b-Instruct-Q6_K | 20.9 | 22.1 | 25.9 | 25.0 | 25.2 | 147.0 | 2.0 |
| orca2: 13b | 20.1 | 18.3 | 23.1 | 0,0 | 30.6 | 166.0 | 11.0 |
| Стаблм-Зефир | 9.9 | 7.7 | 15.4 | 0,0 | 23.5 | 192.0 | 1.0 |
| Dolphin-Phi: 2,7B-V2.6-Q6_K | 8.9 | 8.4 | 14.9 | 0,0 | 22.9 | 188.0 | 0,0 |
| Коделлама: 13b-питон | 12.5 | 10.7 | 12.8 | 0,0 | 22.1 | 155,0 | 0,0 |
| PHI: 2,7B-Chat-V2-Q6_K | 13.0 | 11.6 | 8.9 | 0,0 | 19.4 | 222.0 | 0,0 |
Та же информация, но в качестве барной карты:
И с отдельной полосой для каждого шаблона приглашения: 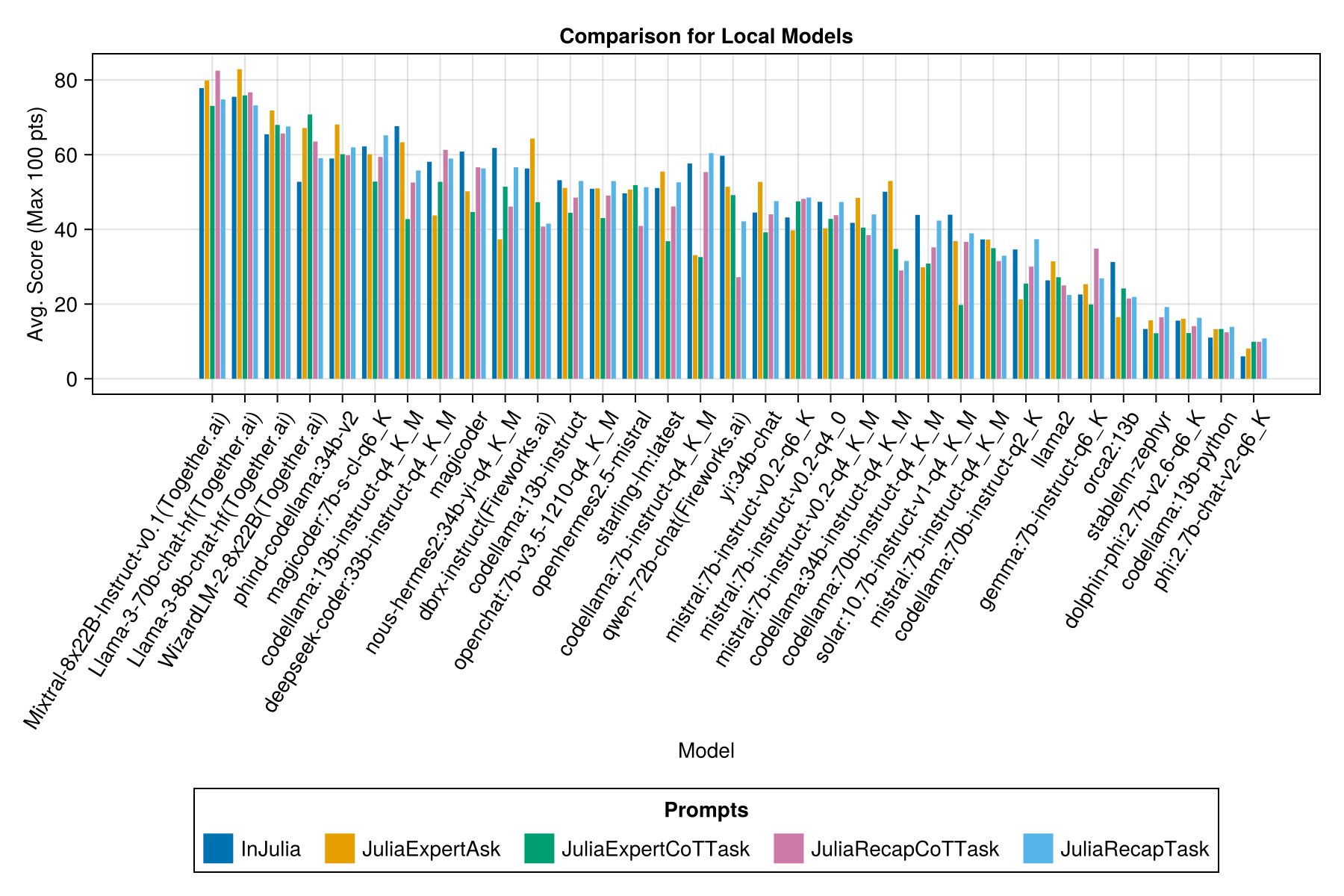
Примечание
Модели QWEN-1.5 были удалены из обзоров, поскольку базовая модель в репозитории Ollama (и HF) не является правильной и имеет очень низкую производительность.
Примечание
Я заметил, что некоторые эвалы в Ollama/Llama.cpp теперь набирают немного выше, чем в декабре-23, так что это на дорожной карте, чтобы повторно запустить вышеуказанные Evals.
Очевидно, что платная победа API (последний релиз: GPT-3.5-Turbo-1106), но это не вся история.
Мы надеемся, что сможем предоставить некоторое руководство по поводу стратегий подсказки, например, когда лучше использовать быстрый шаблон «juliaexpert*» против «в Юлии, ответьте XYZ».
Познание пока:
| Быстрый шаблон | Прошло (S, средний) | Истек (с, медиана) | Ав. Счет (максимум 100 баллов) | Средний балл (максимум 100 баллов) |
|---|---|---|---|---|
| Индуцированная | 14.0 | 9.6 | 55,2 | 50.0 |
| Juliaexpertask | 9.9 | 6.4 | 53,8 | 50.0 |
| Juliarecaptask | 16.7 | 11,5 | 52,0 | 50.0 |
| Juliaexpertcottask | 15.4 | 10.4 | 49,5 | 50.0 |
| Julearecapcottask | 16.1 | 11.3 | 48.6 | 50.0 |
Примечание. Шаблоны на основе XML тестируются только для моделей Claude 3 (Haiku и Sonnet), поэтому мы удалили их из сравнения.
Сделайте свой собственный анализ с examples/summarize_results.jl !
scripts/code_gen_benchmark.jl для примера предыдущих оценок. Хотите провести некоторые эксперименты и сохранить результаты? Проверьте examples/experiment_hyperparameter_scan.jl !
Хотите просмотреть некоторые из прошлых тестов? Проверьте examples/summarize_results.jl для общей статистики и examples/debugging_results.jl
Чтобы внести тестовый пример:
code_generation/category/test_case_name/definition.toml .code_generation/category/test case/model/evaluation__PROMPT__STRATEGY__TIMESTAMP.json и code_generation/category/test case/model/conversation__PROMPT__STRATEGY__TIMESTAMP.jsondefinition.toml Требуемые поля в definition.toml включают:
my_function(1, 2) ).@test X = Z операторов.Есть несколько дополнительных полей:
Приведенные выше поля могут улучшить повторное использование кода в примерах/модульных тестах.
См. Пример в examples/create_definition.jl . Вы можете проверить определения тестового примера с помощью validate_definition() .
Пожалуйста, PR и добавьте любые соответствующие и в основном правильные разговоры с/в/вокруг Джулии в папке julia_conversations/ .
Цель состоит в том, чтобы иметь набор разговоров, которые полезны для создания знаний Джулии в небольших моделях.
Мы высоко ценим ввод сообщества. Если у вас есть предложения или идеи для улучшения, откройте проблему. Все взносы приветствуются!


