Julia LLM Leaderboard
v0.2.0
Vergleich der Fähigkeiten der Julia -Spracherzeugung verschiedener Großsprachenmodelle
definition.tomlWillkommen im Repository der Julia Code Generation Benchmark!
Dieses Projekt ist für die Julia -Community konzipiert, um die Funktionen der Codegenerierung verschiedener KI -Modelle zu vergleichen. Im Gegensatz zu akademischen Benchmarks liegt unser Fokus auf Praktikabilität und Einfachheit: "Generieren Sie Code, führen Sie ihn aus und sehen Sie, ob es funktioniert (-ISH)."
Dieses Repository soll verstehen, wie unterschiedliche KI -Modelle und -anlaufstrategien bei der Generierung syntaktisch korrekter Julia -Code durchgeführt werden, um Benutzer bei der Auswahl des besten Modells für ihre Anforderungen zu führen.
Juckende Finger? Springen Sie zu examples/ oder führen Sie einfach Ihren eigenen Benchmark mit run_benchmark() (z. B. examples/code_gen_benchmark.jl ) aus.
Testfälle werden in einer definition.toml definiert, die für jeden Test eine Standardstruktur bereitstellt. Wenn Sie einen Testfall beitragen möchten, befolgen Sie bitte die Anweisungen im Abschnitt mit dem Testfall.
Die Leistung jedes Modells und der Eingabeaufforderung wird anhand mehrerer Kriterien bewertet:
Derzeit werden alle Kriterien gleich gewogen und jeder Testfall kann maximal 100 Punkte verdienen. Wenn ein Code alle Kriterien übergibt, erhalten er 100/100 Punkte. Wenn es ein Kriterium (z. B. alle Unit -Tests) fehlschlägt, erhalten Sie 75/100 Punkte. Wenn es zwei Kriterien fehlschlägt (z. B. läuft es, aber alle Beispiele und Unit -Tests sind gebrochen), erhalten es 50 Punkte und so weiter.
Um einen Einblick in die Funktionalität des Repositorys zu geben, haben wir Beispielergebnisse für die ersten 14 Testfälle aufgenommen. Öffnen Sie die Dokumentation für die vollständigen Ergebnisse und einen tiefen Tauchgang in jedem Testfall.
Warnung
Diese Bewertungen können sich ändern, wenn wir die unterstützende Funktionalität entwickeln und weitere Modelle hinzufügen.
Denken Sie daran, dass der Benchmark für jedes Modell eine große Herausforderung darstellt - ein einziger zusätzlicher Raum oder Klammern und die Punktzahl könnten 0 werden (= "nicht in der Lage, analysieren")!
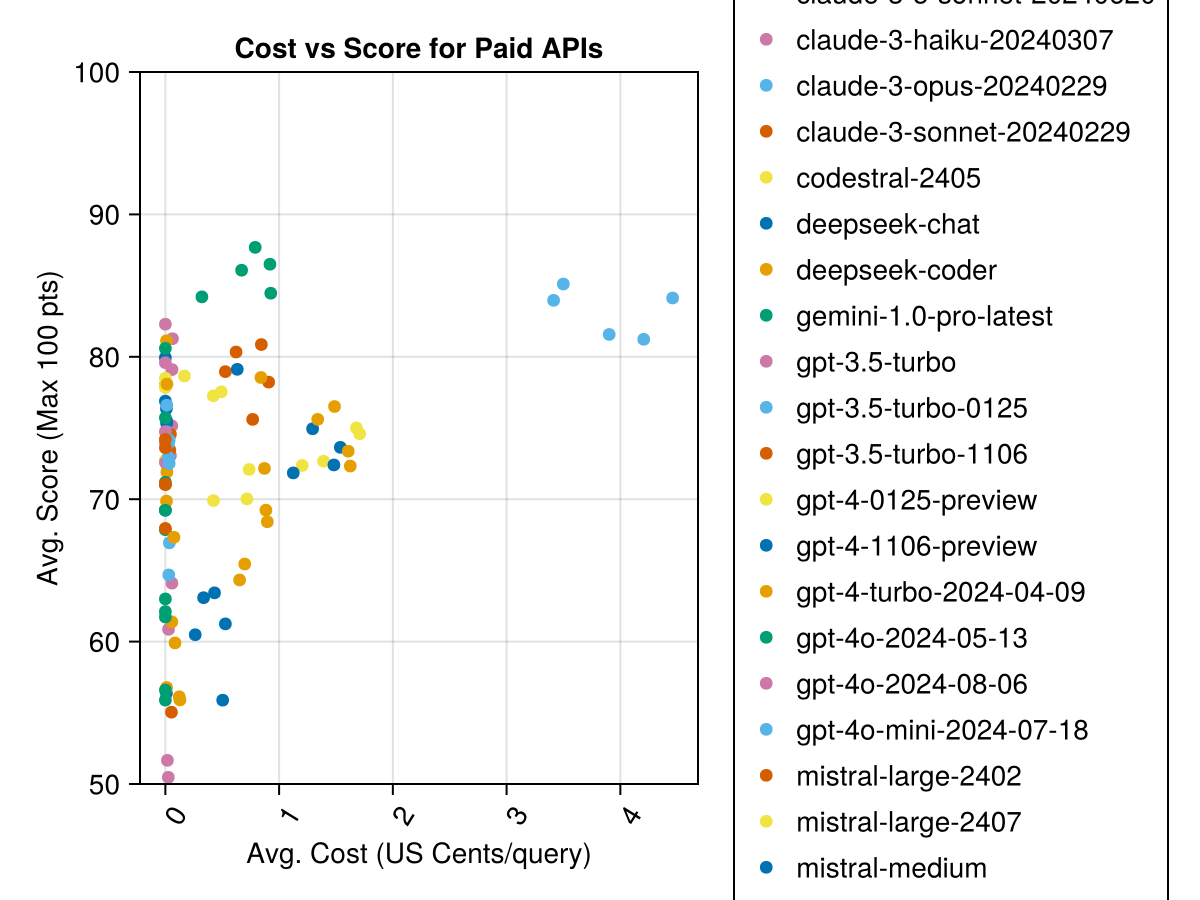
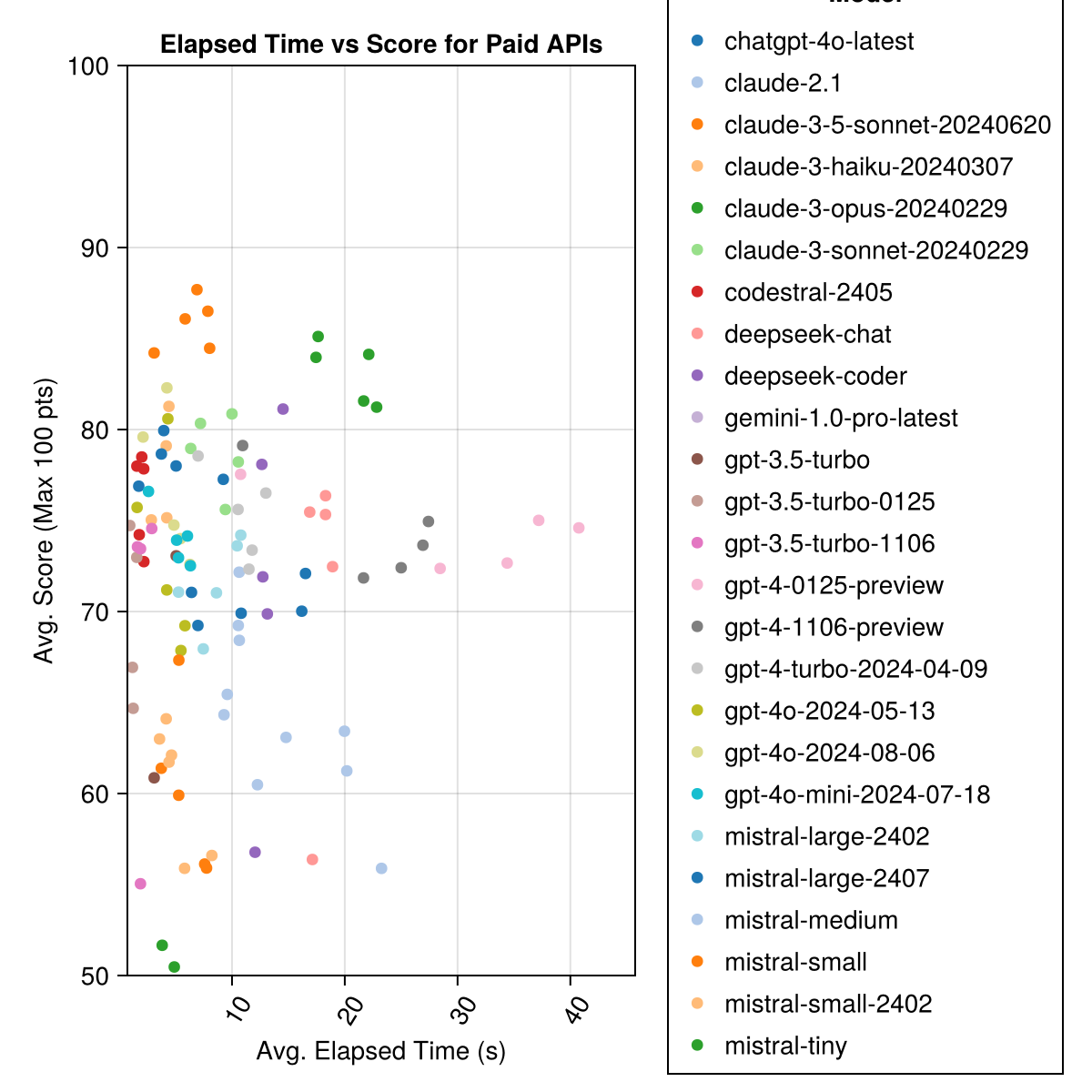
Claude 3.5 Sonett ist das höchste Modell. Für das beste Preis-Leistungs-Verhältnis finden Sie die Mistral Codestral, Claude 3 Haiku und kürzlich veröffentlicht GPT 4O Mini (60% billiger als GPT3.5 !!!).
| Modell | Verstrichen | Punktzahl | Score STD -Abweichung | Count Zero Score | Zählen Sie die volle Punktzahl | Kostet cent |
|---|---|---|---|---|---|---|
| Claude-3-5-SONNET-20240620 | 6.3 | 85,8 | 21.1 | 13 | 355 | 0,73 |
| Claude-3-opus-20240229 | 20.3 | 83.2 | 19.6 | 2 | 329 | 3.9 |
| Claude-3-sonnet-20240229 | 8.7 | 78,8 | 26.2 | 22 | 308 | 0,73 |
| GPT-4O-2024-08-06 | 4.6 | 76,6 | 27.9 | 26 | 310 | 0,0 |
| Codestral-2405 | 1.9 | 76,3 | 29.3 | 33 | 276 | 0,0 |
| GPT-4-Turbo-2024-04-09 | 10.8 | 75,3 | 29.6 | 38 | 290 | 1.38 |
| CHATGPT-4O-LATEST | 4.8 | 75,0 | 27.9 | 25 | 263 | 0,0 |
| Claude-3-Haiku-20240307 | 4.0 | 74,9 | 27.2 | 9 | 261 | 0,05 |
| GPT-4-0125-Präview | 30.3 | 74.4 | 30.3 | 39 | 284 | 1.29 |
| GPT-4-1106-Präview | 22.4 | 74.4 | 29.9 | 19 | 142 | 1.21 |
| GPT-4O-Mini-2024-07-18 | 5.1 | 74,0 | 29.4 | 32 | 276 | 0,03 |
| Mistral-Large-2407 | 11.3 | 73.6 | 29,5 | 15 | 137 | 0,49 |
| GPT-4O-2024-05-13 | 4.3 | 72.9 | 29.1 | 29 | 257 | 0,0 |
| Deepseek-Coder | 13.0 | 71.6 | 32.6 | 39 | 115 | 0,01 |
| Mistral-Large-2402 | 8.5 | 71.6 | 27.2 | 13 | 223 | 0,0 |
| Deepseek-Chat | 17.9 | 71.3 | 32.9 | 30 | 140 | 0,01 |
| Claude-2.1 | 10.1 | 67,9 | 30.8 | 47 | 229 | 0,8 |
| GPT-3,5-Turbo-0125 | 1.2 | 61.7 | 36.6 | 125 | 192 | 0,03 |
| Mistral-Medium | 18.1 | 60.8 | 33.2 | 22 | 90 | 0,41 |
| Mistral-Small | 5.9 | 60.1 | 30.2 | 27 | 76 | 0,09 |
| Mistral-Small-2402 | 5.3 | 59,9 | 29.4 | 31 | 169 | 0,0 |
| GPT-3,5-Turbo-1106 | 2.1 | 58,4 | 39.2 | 82 | 97 | 0,04 |
| Mistral-Tiny | 4.6 | 46,9 | 32.0 | 75 | 42 | 0,02 |
| GPT-3,5-Turbo | 3.6 | 42.3 | 38.2 | 132 | 54 | 0,04 |
| Gemini-1.0-pro-latest | 4.2 | 34.8 | 27.4 | 181 | 25 | 0,0 |
Hinweis: Ab Mitte Februar 2024 wird "GPT-3,5-Turbo" auf die neueste Veröffentlichung "GPT-3,5-Turbo-0125" (Abschaffung der Veröffentlichung im Juni) verweisen.
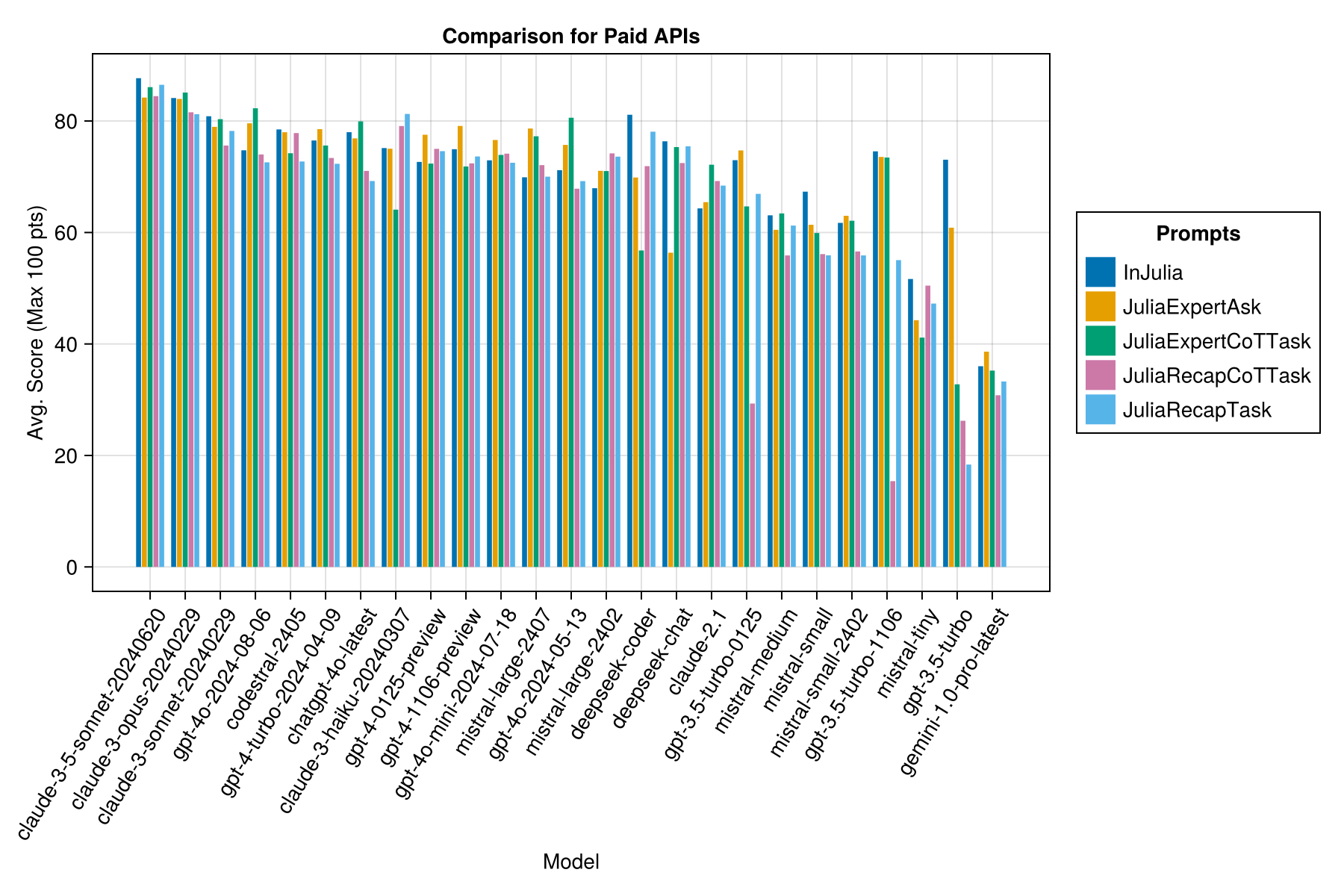
Gleiche Informationen, aber als Balkendiagramm:
Darüber hinaus können wir die Leistung (Punktzahl) im Vergleich zu den Kosten (gemessen in US -Cent) betrachten:
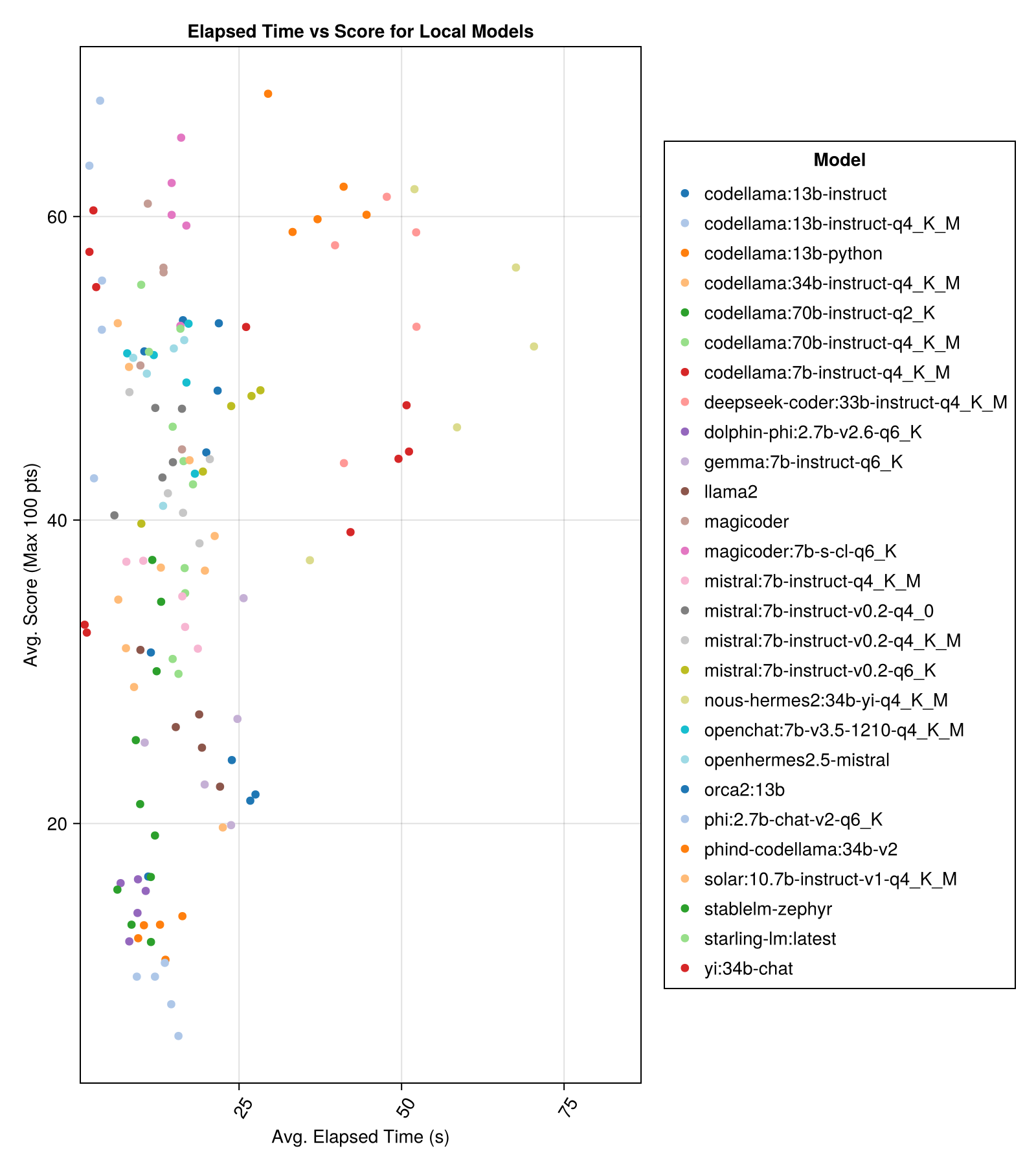
Vor Ort gehostete Modelle sind im Allgemeinen nicht so gut wie die am besten bezahlten APIs, aber sie kommen näher! Beachten Sie, dass der "Mistral-Small" bereits vor Ort verfügbar ist und es viele zukünftige Finetunes geben wird!
Notiz
Vielen Dank an 01.ai und Jun Tian, insbesondere für die Bereitstellung des Berechnens für einige Teile dieses Benchmarks!
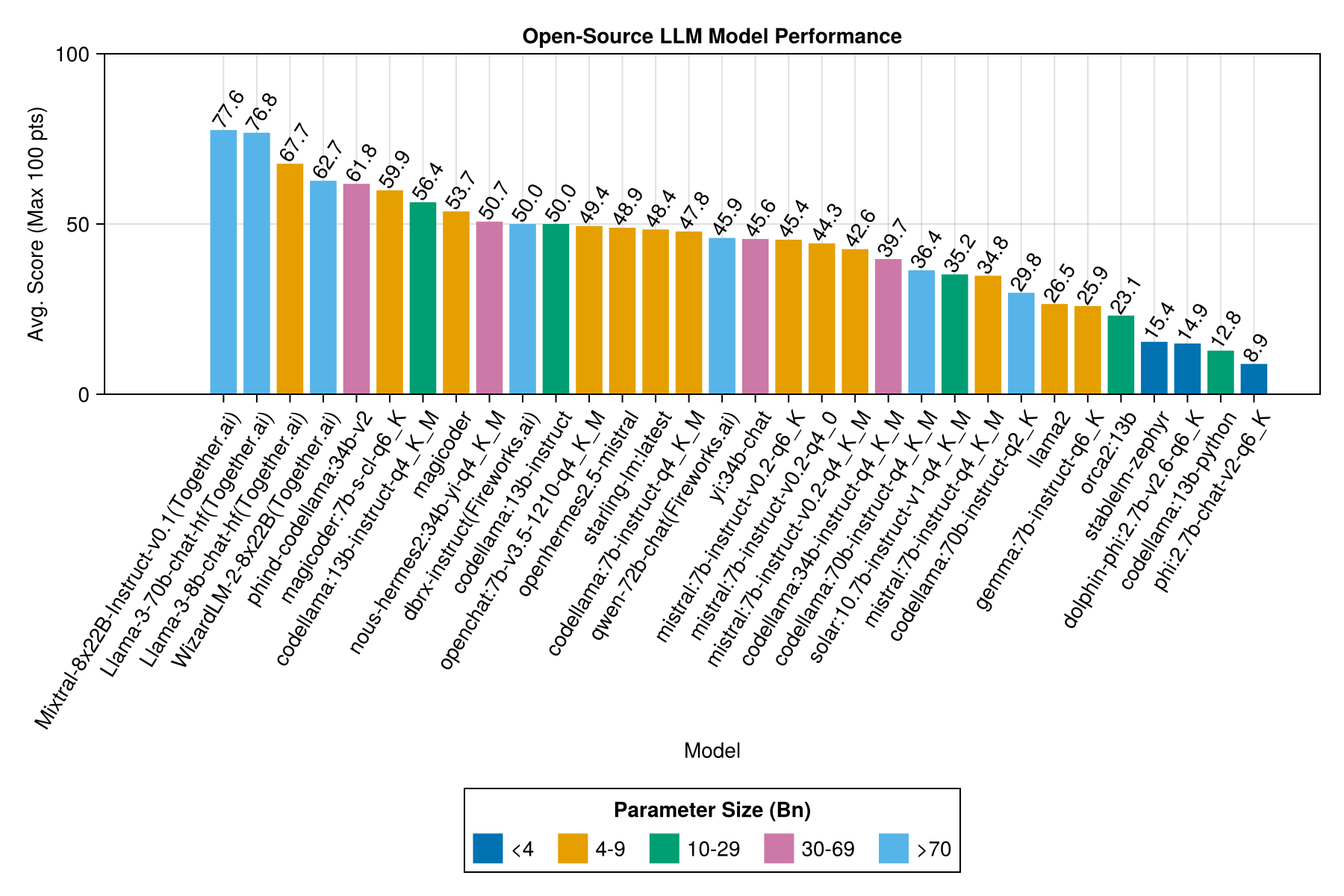
Die beste Kompromisse gegen die Größe ist die neueste Meta Lama3 8Bn. Andernfalls ist das führende Modell Mixtral-8x22Bn.
| Modell | Verstrichen | Verstrichene Median | Punktzahl | Punktzahlmedian | Score STD -Abweichung | Count Zero Score | Zählen Sie die volle Punktzahl |
|---|---|---|---|---|---|---|---|
| MIMTRAL-8X22B-ISTRUCT-V0.1 (zusammen.ai) | 14.1 | 11.0 | 77,6 | 90.0 | 25.8 | 5.0 | 151.0 |
| LAMA-3-70B-CHAT-HF (zusammen.ai) | 4.3 | 4.1 | 76,8 | 88.3 | 25.2 | 0,0 | 160.0 |
| LAMA-3-8B-CHAT-HF (zusammen.ai) | 1.5 | 1.4 | 67,7 | 66,7 | 26.4 | 5.0 | 70.0 |
| WizardLM-2-8x22b (zusammen.ai) | 34.7 | 31.0 | 62.7 | 60.0 | 33.8 | 33.0 | 118.0 |
| Phind-Codellama: 34b-V2 | 37.1 | 36.4 | 61,8 | 62,5 | 33.5 | 36.0 | 58.0 |
| Magicoder: 7B-S-Cl-Q6_K | 15.6 | 15.8 | 59,9 | 60.0 | 29.9 | 18.0 | 35.0 |
| Codellama: 13B-Instruct-Q4_K_M | 3.2 | 3.0 | 56,4 | 54.6 | 33.0 | 56.0 | 61.0 |
| Deepseek-Coder: 33B-Instruct-Q4_K_M | 46,7 | 44,6 | 55.0 | 50.0 | 36.8 | 62.0 | 68.0 |
| Magicoder | 12.8 | 10.7 | 53.7 | 50.0 | 33.2 | 49,0 | 52.0 |
| Nous-Hermes2: 34b-yi-q4_k_m | 56,8 | 52,8 | 50.7 | 50.0 | 34.7 | 78.0 | 56.0 |
| DBRX-Instruct (Fireworks.ai) | 3.7 | 3.6 | 50.0 | 50.0 | 41.2 | 121.0 | 75,0 |
| Codellama: 13b-Instruktur | 18.1 | 16.7 | 50.0 | 50.0 | 34.4 | 65.0 | 44.0 |
| OpenChat: 7B-V3.5-1210-Q4_K_M | 14.4 | 13.7 | 49,4 | 50.0 | 30.3 | 48.0 | 23.0 |
| Openhermes2.5-MISTRAL | 12.9 | 12.2 | 48,9 | 50.0 | 31.3 | 55.0 | 27.0 |
| STARLING-LM: Neueste | 13.7 | 12.5 | 48,4 | 50.0 | 30.2 | 58.0 | 26.0 |
| Codellama: 7B-Instruct-Q4_K_M | 2.1 | 2.0 | 47,8 | 50.0 | 35.3 | 95.0 | 38.0 |
| QWEN-72B-CHAT (Fireworks.ai) | 3.2 | 3.8 | 45,9 | 50.0 | 38,8 | 117.0 | 63.0 |
| yi: 34b-chat | 43.9 | 41.3 | 45,6 | 50.0 | 30,5 | 45,0 | 34.0 |
| Mistral: 7B-Instruct-V0.2-Q6_K | 21.7 | 20.9 | 45,4 | 50.0 | 31.3 | 44.0 | 23.0 |
| Mistral: 7B-Instruct-V0.2-Q4_0 | 12.4 | 12.3 | 44.3 | 50.0 | 30.6 | 75,0 | 32.0 |
| Mistral: 7B-Instruct-V0.2-Q4_K_M | 15.6 | 15.1 | 42.6 | 50.0 | 28.6 | 71.0 | 23.0 |
| Codellama: 34B-Instruct-Q4_K_M | 7.5 | 6.8 | 39.7 | 50.0 | 36.1 | 127.0 | 35.0 |
| Codellama: 70B-Instruct-Q4_K_M | 16.3 | 13.8 | 36.4 | 0,0 | 41.2 | 179.0 | 58.0 |
| Solar: 10.7b-Instruct-V1-Q4_K_M | 18.8 | 17.7 | 35.2 | 50.0 | 31.1 | 107.0 | 10.0 |
| Mistral: 7B-Instruct-Q4_K_M | 13.9 | 13.0 | 34.8 | 50.0 | 26,5 | 80.0 | 0,0 |
| Codellama: 70B-Instruct-Q2_K | 11.2 | 9.4 | 29.8 | 0,0 | 37.7 | 198.0 | 29.0 |
| LAMA22 | 17.1 | 16.3 | 26,5 | 25.0 | 26,5 | 131.0 | 0,0 |
| Gemma: 7B-Instruct-Q6_K | 20.9 | 22.1 | 25.9 | 25.0 | 25.2 | 147.0 | 2.0 |
| Orca2: 13b | 20.1 | 18.3 | 23.1 | 0,0 | 30.6 | 166.0 | 11.0 |
| Stablelm-Zephyr | 9.9 | 7.7 | 15.4 | 0,0 | 23.5 | 192.0 | 1.0 |
| Delphin-Phi: 2.7b-V2.6-Q6_K | 8.9 | 8.4 | 14.9 | 0,0 | 22.9 | 188.0 | 0,0 |
| Codellama: 13b-Python | 12.5 | 10.7 | 12.8 | 0,0 | 22.1 | 155.0 | 0,0 |
| PHI: 2,7B-CHAT-V2-Q6_K | 13.0 | 11.6 | 8.9 | 0,0 | 19.4 | 222.0 | 0,0 |
Gleiche Informationen, aber als Balkendiagramm:
Und mit einer separaten Balken für jede schnelle Vorlage: 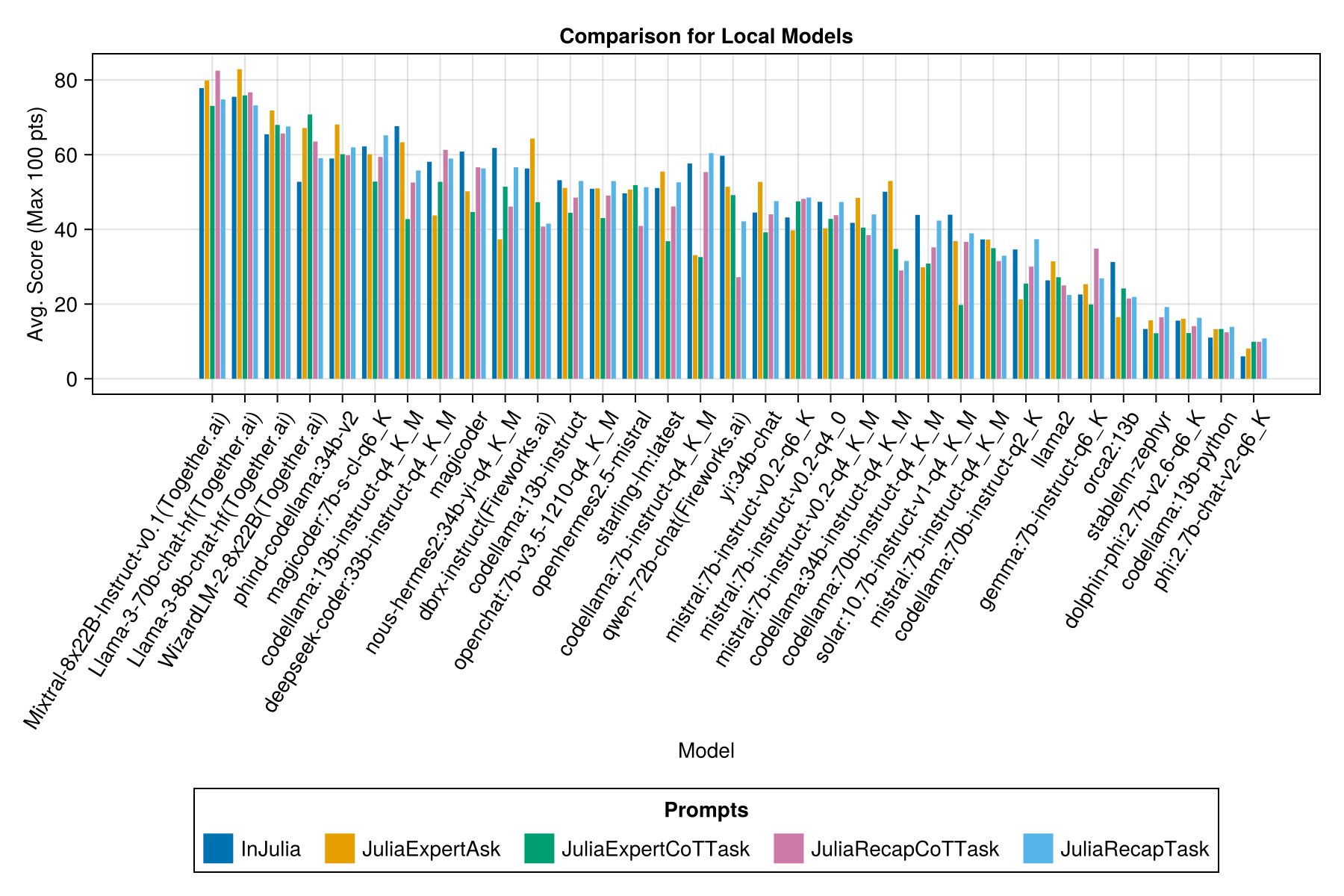
Notiz
QWEN-1.5-Modelle wurden aus den Übersichten entfernt, da das zugrunde liegende Modell im OLLAMA-Repository (und HF) nicht korrekt ist und eine sehr geringe Leistung aufweist.
Notiz
Ich habe festgestellt, dass einige Evals in Ollama/lama.cpp jetzt etwas höher als in Dezember-23 punkten. Es ist also auf einer Roadmap, um die oben genannten Evals erneut auszuführen.
Offensichtlich, der bezahlte APIs-Sieg (die neueste Veröffentlichung: GPT-3,5-Turbo-1106), aber das ist nicht die ganze Geschichte.
Wir hoffen, in der Lage zu sein, einige Anleitungen zur Aufforderung zu Strategien zu geben, z. B. wann ist es besser, eine "Juliaexpert*" “-Propplate gegen ein" in Julia, Antwort XYZ "zu verwenden.
Erkenntnisse bisher:
| Schnellvorlage | Verstrichen (s, Durchschnitt) | Verstrichen (s, Median) | Avg. Punktzahl (max 100 Punkte) | Median Score (max 100 Punkte) |
|---|---|---|---|---|
| Injulia | 14.0 | 9.6 | 55.2 | 50.0 |
| Juliaexpertask | 9.9 | 6.4 | 53,8 | 50.0 |
| Juliarecaptask | 16.7 | 11.5 | 52.0 | 50.0 |
| Juliaexpertcottask | 15.4 | 10.4 | 49,5 | 50.0 |
| Juliarecapcottask | 16.1 | 11.3 | 48.6 | 50.0 |
Hinweis: Die XML-basierten Vorlagen werden nur für Claude 3-Modelle (Haiku und Sonett) getestet. Deshalb haben wir sie aus dem Vergleich entfernt.
Machen Sie Ihre eigene Analyse mit examples/summarize_results.jl !
scripts/code_gen_benchmark.jl für das Beispiel früherer Bewertungen. Möchten Sie einige Experimente durchführen und die Ergebnisse speichern? Schauen Sie sich examples/experiment_hyperparameter_scan.jl an!
Möchten Sie einige der vergangenen Benchmark -Läufe überprüfen? Weitere Informationen zu den einzelnen Gesprächen/Modellantworten finden Sie unter examples/summarize_results.jl für Gesamtstatistiken und examples/debugging_results.jl .
Einen Testfall beizutragen:
code_generation/category/test_case_name/definition.toml .code_generation/category/test case/model/evaluation__PROMPT__STRATEGY__TIMESTAMP.json und code_generation/category/test case/model/conversation__PROMPT__STRATEGY__TIMESTAMP.json Pfaddefinition.toml Erforderliche Felder in definition.toml enthalten:
my_function(1, 2) ).@test X = Z -Anweisungen bereitgestellt wird.Es gibt mehrere optionale Felder:
Die obigen Felder können die Wiederverwendung des Codes in den Beispielen/Unit-Tests verbessern.
Siehe ein Beispiel in examples/create_definition.jl . Sie können Ihre Test -Fall -Definitionen mit validate_definition() validieren.
Bitte pR und fügen Sie alle relevanten und meist korrekten Gespräche mit/in/um Julia in Ordner julia_conversations/ hinzu.
Ziel ist es, eine Sammlung von Gesprächen zu führen, die für das Finetuning Julia -Wissen in kleineren Modellen nützlich sind.
Wir schätzen die Community -Eingabe. Wenn Sie Vorschläge oder Verbesserungsideen haben, öffnen Sie bitte ein Problem. Alle Beiträge sind willkommen!


