Julia LLM Leaderboard
v0.2.0
การเปรียบเทียบความสามารถในการสร้างภาษาจูเลียของแบบจำลองภาษาขนาดใหญ่ที่หลากหลาย
definition.tomlยินดีต้อนรับสู่พื้นที่เก็บข้อมูลเกณฑ์มาตรฐาน Julia Code Generation!
โครงการนี้ออกแบบมาสำหรับชุมชนจูเลียเพื่อเปรียบเทียบความสามารถในการสร้างรหัสของโมเดล AI ต่างๆ ซึ่งแตกต่างจากมาตรฐานการศึกษาการมุ่งเน้นของเราคือการปฏิบัติจริงและความเรียบง่าย: "สร้างรหัสเรียกใช้และดูว่ามันใช้งานได้หรือไม่ (-ish)"
พื้นที่เก็บข้อมูลนี้มีวัตถุประสงค์เพื่อทำความเข้าใจว่าโมเดล AI และกลยุทธ์การแจ้งเตือนที่แตกต่างกันนั้นมีความแตกต่างในการสร้างรหัสจูเลียที่ถูกต้องเพื่อเป็นแนวทางให้ผู้ใช้ในการเลือกแบบจำลองที่ดีที่สุดสำหรับความต้องการของพวกเขา
นิ้วมือ? ข้ามไปที่ examples/ หรือเพียงเรียกใช้เบนช์มาร์กของคุณเองด้วย run_benchmark() (เช่น examples/code_gen_benchmark.jl )
กรณีทดสอบถูกกำหนดไว้ในไฟล์ definition.toml ให้โครงสร้างมาตรฐานสำหรับการทดสอบแต่ละครั้ง หากคุณต้องการมีส่วนร่วมในกรณีทดสอบโปรดทำตามคำแนะนำในส่วนกรณีทดสอบของคุณ
ประสิทธิภาพของแต่ละรุ่นและพรอมต์ได้รับการประเมินตามเกณฑ์หลายประการ:
ในขณะนี้เกณฑ์ทั้งหมดมีการชั่งน้ำหนักเท่า ๆ กันและแต่ละกรณีการทดสอบสามารถได้รับสูงสุด 100 คะแนน หากรหัสผ่านเกณฑ์ทั้งหมดจะได้รับ 100/100 คะแนน ถ้ามันล้มเหลวหนึ่งเกณฑ์ (เช่นการทดสอบหน่วยทั้งหมด) จะได้รับคะแนน 75/100 หากมันล้มเหลวสองเกณฑ์ (เช่นมันทำงาน แต่ตัวอย่างและการทดสอบหน่วยทั้งหมดเสีย) จะได้รับ 50 คะแนนและอื่น ๆ
เพื่อให้เห็นการทำงานของที่เก็บเราได้รวมตัวอย่างผลลัพธ์สำหรับกรณีทดสอบ 14 กรณีแรก เปิดเอกสาร สำหรับผลลัพธ์เต็มรูปแบบและการดำน้ำลึกในแต่ละกรณีทดสอบ
คำเตือน
คะแนนเหล่านี้อาจเปลี่ยนแปลงได้เมื่อเราพัฒนาฟังก์ชั่นการสนับสนุนและเพิ่มโมเดลเพิ่มเติม
โปรดจำไว้ว่าเกณฑ์มาตรฐานค่อนข้างท้าทายสำหรับรุ่นใด ๆ - พื้นที่พิเศษหรือวงเล็บเดียวและคะแนนอาจกลายเป็น 0 (= "ไม่สามารถแยกวิเคราะห์ได้")!
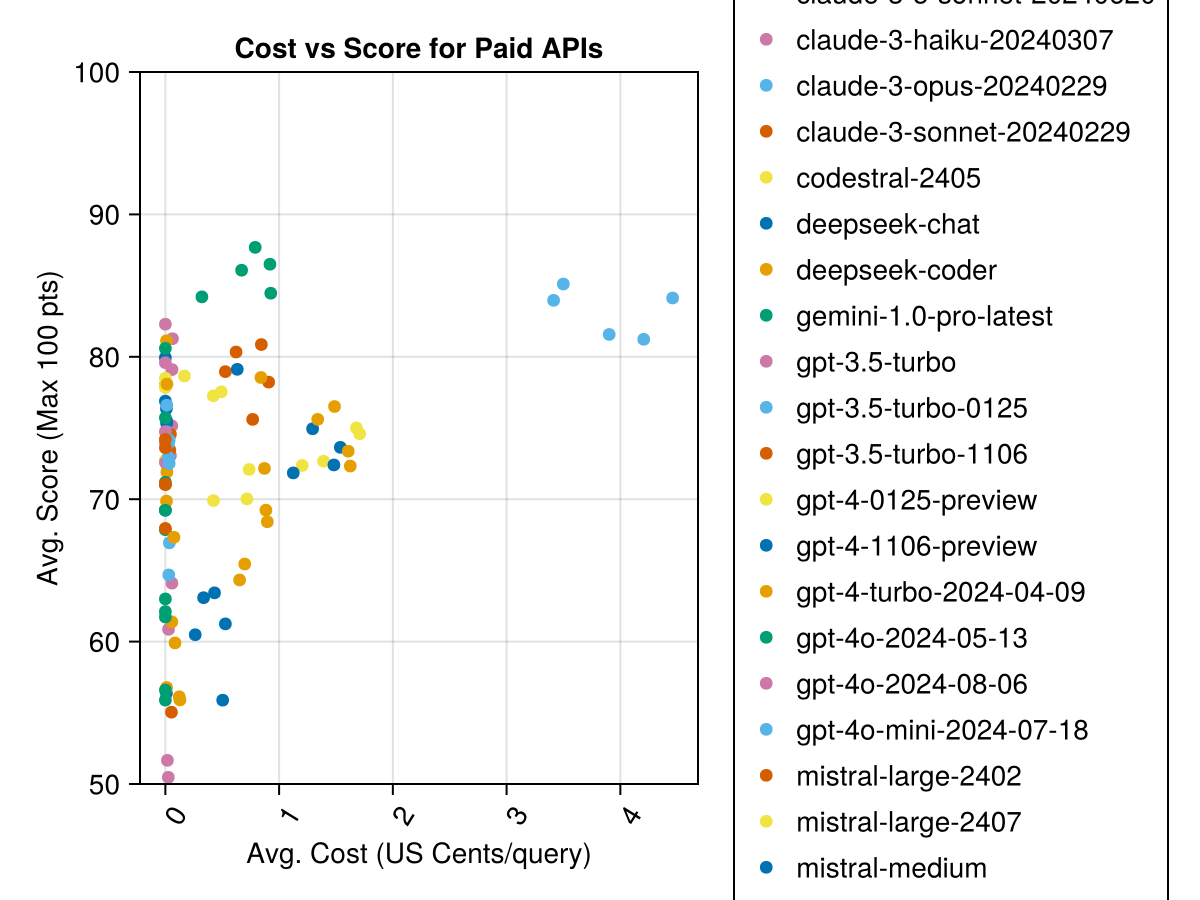
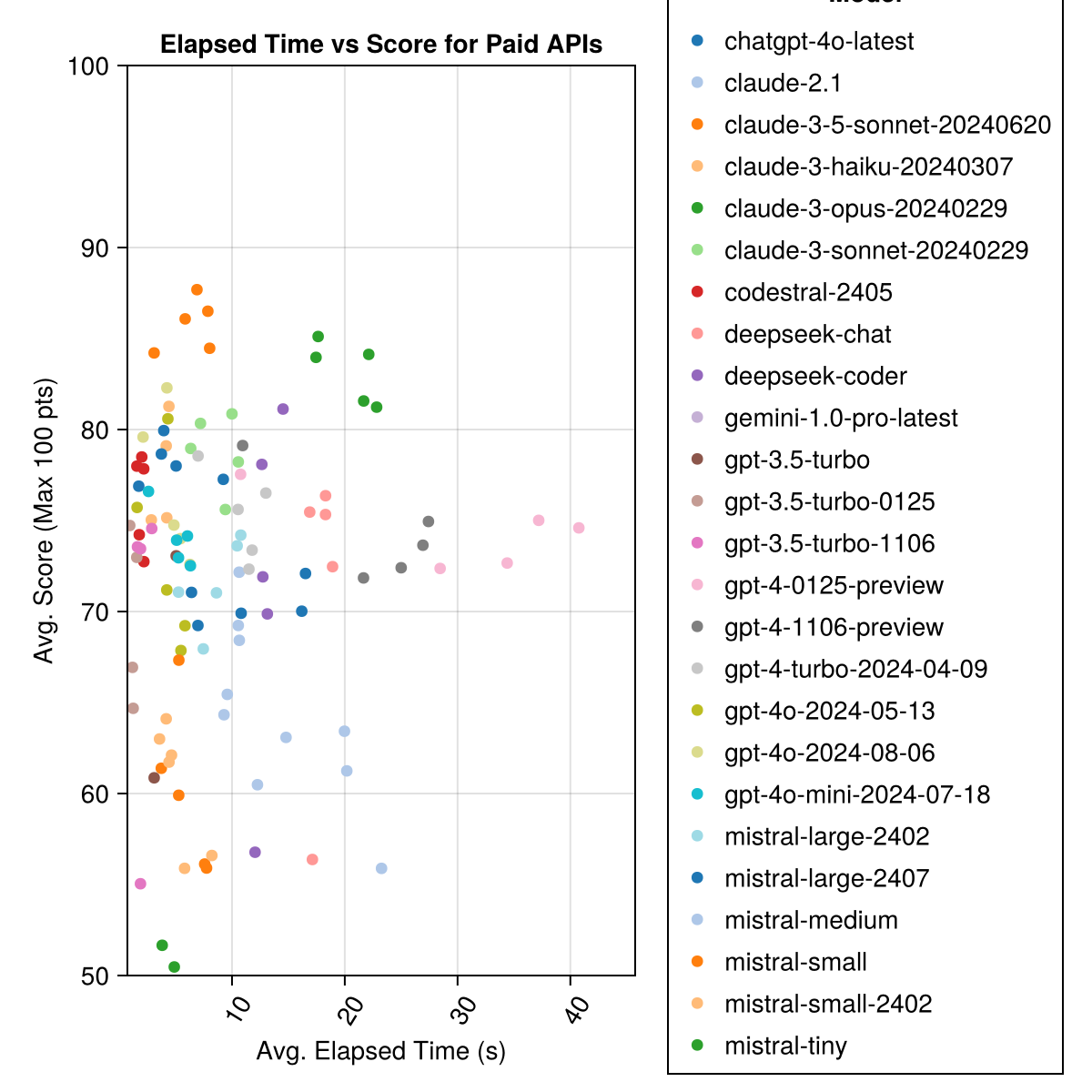
Claude 3.5 Sonnet เป็นรุ่นที่มีประสิทธิภาพสูงสุด สำหรับค่านิยมที่ดีที่สุดสำหรับเงินให้มองหา Mistral Codestral, Claude 3 Haiku และเปิดตัวเมื่อเร็ว ๆ นี้ GPT 4O Mini (ราคาถูกกว่า 60% กว่า GPT3.5 !!!)
| แบบอย่าง | ที่ผ่านไป | คะแนน | คะแนนการเบี่ยงเบน std | นับคะแนนศูนย์ | นับคะแนนเต็ม | ค่าใช้จ่ายเซ็นต์ |
|---|---|---|---|---|---|---|
| Claude-3-5-Sonnet-201240620 | 6.3 | 85.8 | 21.1 | 13 | 355 | 0.73 |
| Claude-3-Opus-201240229 | 20.3 | 83.2 | 19.6 | 2 | 329 | 3.9 |
| Claude-3-Sonnet-201240229 | 8.7 | 78.8 | 26.2 | 22 | 308 | 0.73 |
| GPT-4O-20124-08-06 | 4.6 | 76.6 | 27.9 | 26 | 310 | 0.0 |
| CODESTRAL-2405 | 1.9 | 76.3 | 29.3 | 33 | 276 | 0.0 |
| GPT-4-Turbo-20124-04-09 | 10.8 | 75.3 | 29.6 | 38 | 290 | 1.38 |
| chatgpt-4o-latest | 4.8 | 75.0 | 27.9 | 25 | 263 | 0.0 |
| Claude-3-Haiku-201240307 | 4.0 | 74.9 | 27.2 | 9 | 261 | 0.05 |
| GPT-4-0125-PREVIEW | 30.3 | 74.4 | 30.3 | 39 | 284 | 1.29 |
| GPT-4-1106-PREVIEW | 22.4 | 74.4 | 29.9 | 19 | 142 | 1.21 |
| GPT-4O-MINI-20124-07-18 | 5.1 | 74.0 | 29.4 | 32 | 276 | 0.03 |
| Mistral-Large-2407 | 11.3 | 73.6 | 29.5 | 15 | 137 | 0.49 |
| GPT-4O-20124-05-13 | 4.3 | 72.9 | 29.1 | 29 | 257 | 0.0 |
| เขื่อนลึก | 13.0 | 71.6 | 32.6 | 39 | 115 | 0.01 |
| Mistral-Large-2302 | 8.5 | 71.6 | 27.2 | 13 | 223 | 0.0 |
| แชทลึก | 17.9 | 71.3 | 32.9 | 30 | 140 | 0.01 |
| Claude-2.1 | 10.1 | 67.9 | 30.8 | 47 | 229 | 0.8 |
| GPT-3.5-turbo-0125 | 1.2 | 61.7 | 36.6 | 125 | 192 | 0.03 |
| มิสทรัล-ปานกลาง | 18.1 | 60.8 | 33.2 | 22 | 90 | 0.41 |
| มวิภาค | 5.9 | 60.1 | 30.2 | 27 | 76 | 0.09 |
| MISTRAL-SMALL-2402 | 5.3 | 59.9 | 29.4 | 31 | 169 | 0.0 |
| GPT-3.5-turbo-1106 | 2.1 | 58.4 | 39.2 | 82 | 97 | 0.04 |
| ผิดพลาด | 4.6 | 46.9 | 32.0 | 75 | 42 | 0.02 |
| GPT-3.5-turbo | 3.6 | 42.3 | 38.2 | 132 | 54 | 0.04 |
| Gemini-1.0-pro-latest | 4.2 | 34.8 | 27.4 | 181 | 25 | 0.0 |
หมายเหตุ: ตั้งแต่กลางเดือนกุมภาพันธ์ 2567 "GPT-3.5-turbo" จะชี้ไปที่การเปิดตัวล่าสุด "GPT-3.5-Turbo-0125" (ลดราคาในเดือนมิถุนายน)
ข้อมูลเดียวกัน แต่เป็นแผนภูมิแท่ง:
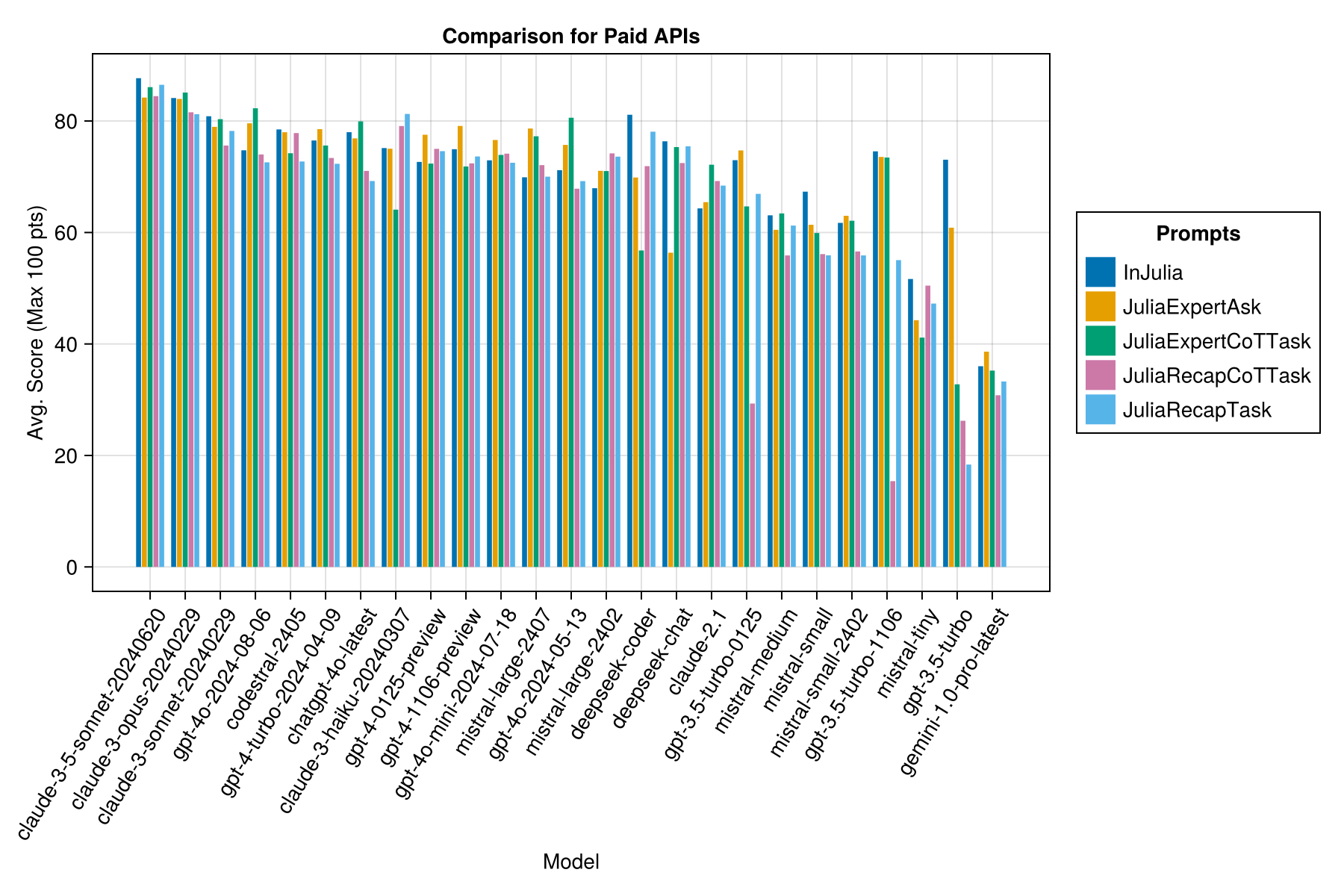
นอกจากนี้เราสามารถพิจารณาประสิทธิภาพ (คะแนน) เมื่อเทียบกับค่าใช้จ่าย (วัดในสหรัฐอเมริกาเซ็นต์):
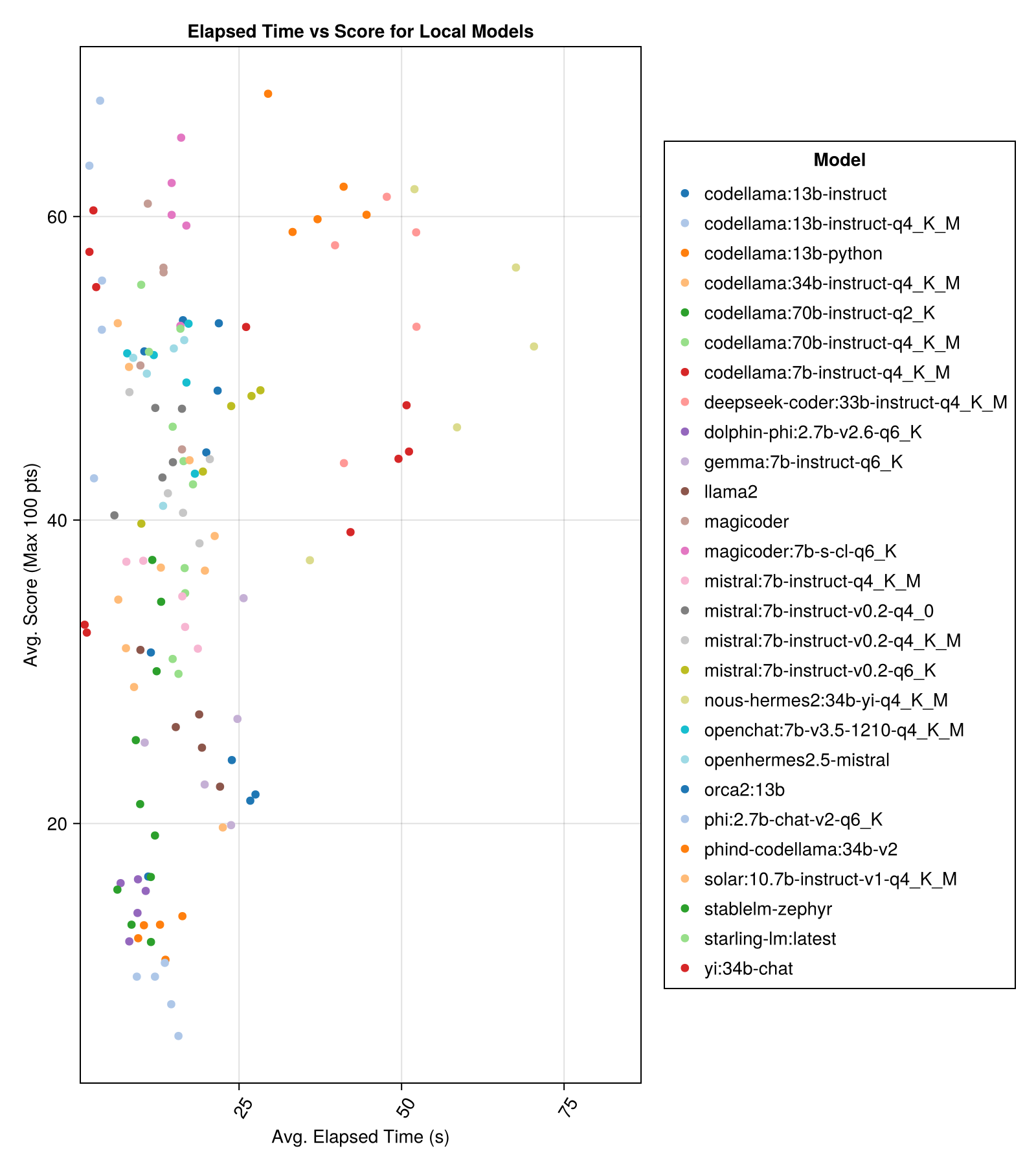
โดยทั่วไปโมเดลโฮสต์ในท้องถิ่นมักจะไม่ดีเท่า API ที่ได้รับค่าจ้างที่ดีที่สุด แต่พวกเขาเข้าใกล้! โปรดทราบว่า "mistral-small" มีอยู่แล้วที่จะทำงานในท้องถิ่นและจะมี finetunes ในอนาคตมากมาย!
บันทึก
ขอบคุณมากสำหรับ 01.ai และ Jun Tian โดยเฉพาะอย่างยิ่งสำหรับการคำนวณสำหรับหลายส่วนของเกณฑ์มาตรฐานนี้!
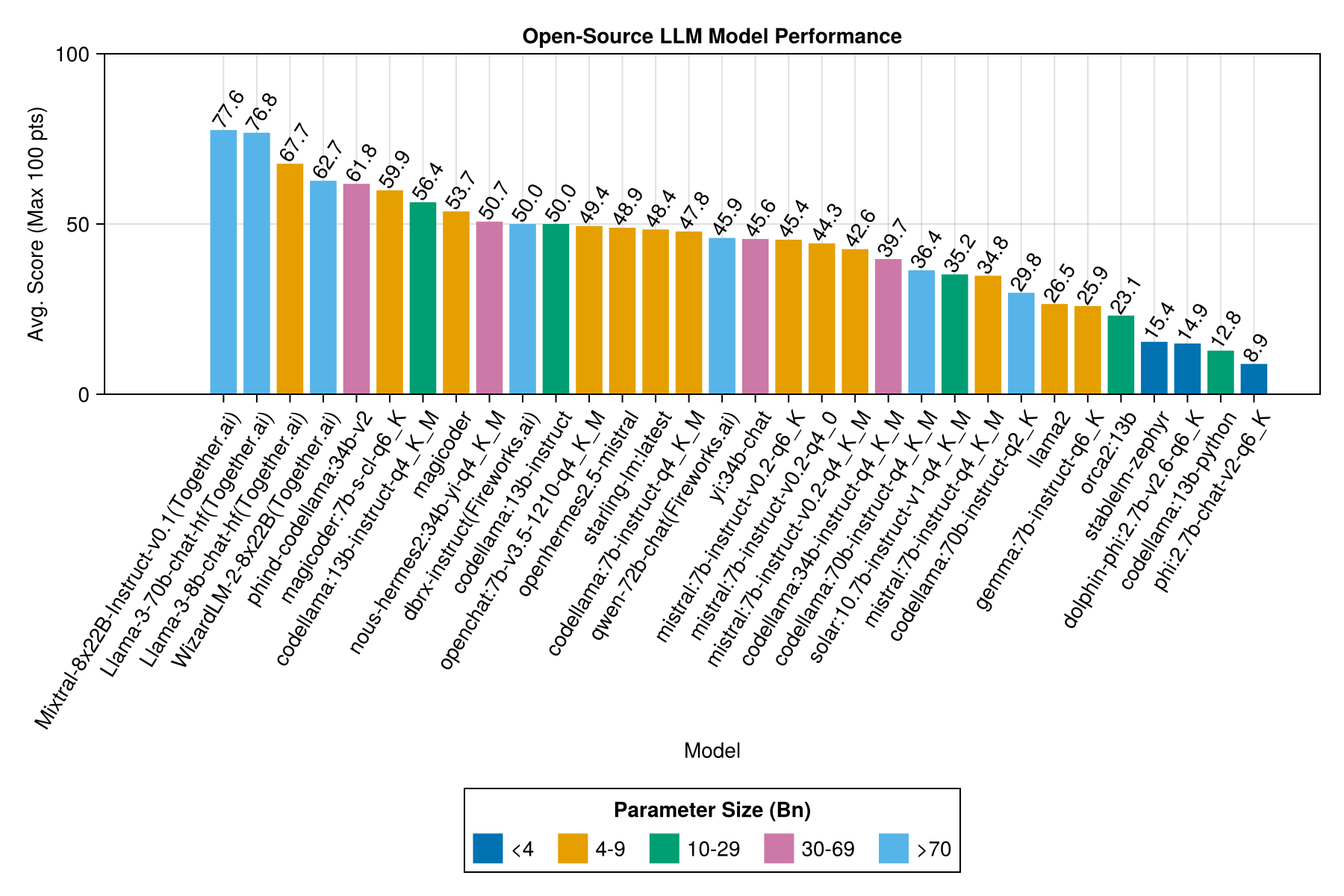
ประสิทธิภาพการแลกเปลี่ยนที่ดีที่สุดเทียบกับขนาดคือ Meta Llama3 8bn ล่าสุด มิฉะนั้นโมเดลชั้นนำคือ Mixtral-8x22bn
| แบบอย่าง | ที่ผ่านไป | ค่ามัธยฐานที่ผ่านไป | คะแนน | คะแนนเฉลี่ย | คะแนนการเบี่ยงเบน std | นับคะแนนศูนย์ | นับคะแนนเต็ม |
|---|---|---|---|---|---|---|---|
| MixTRAL-8X22B-Instruct-V0.1 (ร่วมกัน) | 14.1 | 11.0 | 77.6 | 90.0 | 25.8 | 5.0 | 151.0 |
| LLAMA-3-70B-Chat-HF (รวมกัน) | 4.3 | 4.1 | 76.8 | 88.3 | 25.2 | 0.0 | 160.0 |
| llama-3-8b-chat-hf (ร่วมกัน) | 1.5 | 1.4 | 67.7 | 66.7 | 26.4 | 5.0 | 70.0 |
| Wizardlm-2-8x22b (ร่วมกัน) | 34.7 | 31.0 | 62.7 | 60.0 | 33.8 | 33.0 | 118.0 |
| Phind-Codellama: 34B-V2 | 37.1 | 36.4 | 61.8 | 62.5 | 33.5 | 36.0 | 58.0 |
| Magicoder: 7b-s-cl-q6_k | 15.6 | 15.8 | 59.9 | 60.0 | 29.9 | 18.0 | 35.0 |
| Codellama: 13b-Instruct-q4_k_m | 3.2 | 3.0 | 56.4 | 54.6 | 33.0 | 56.0 | 61.0 |
| Deepseek-Coder: 33b-Instruct-q4_k_m | 46.7 | 44.6 | 55.0 | 50.0 | 36.8 | 62.0 | 68.0 |
| เครื่องมายากล | 12.8 | 10.7 | 53.7 | 50.0 | 33.2 | 49.0 | 52.0 |
| nous-hermes2: 34b-yi-q4_k_m | 56.8 | 52.8 | 50.7 | 50.0 | 34.7 | 78.0 | 56.0 |
| DBRX-Instruct (Fireworks.AI) | 3.7 | 3.6 | 50.0 | 50.0 | 41.2 | 121.0 | 75.0 |
| Codellama: 13b-Instruct | 18.1 | 16.7 | 50.0 | 50.0 | 34.4 | 65.0 | 44.0 |
| OpenChat: 7B-V3.5-1210-Q4_K_M | 14.4 | 13.7 | 49.4 | 50.0 | 30.3 | 48.0 | 23.0 |
| OpenHermes2.5-mistral | 12.9 | 12.2 | 48.9 | 50.0 | 31.3 | 55.0 | 27.0 |
| Starling-LM: ล่าสุด | 13.7 | 12.5 | 48.4 | 50.0 | 30.2 | 58.0 | 26.0 |
| Codellama: 7b-Instruct-q4_k_m | 2.1 | 2.0 | 47.8 | 50.0 | 35.3 | 95.0 | 38.0 |
| QWEN-72B-Chat (Fireworks.ai) | 3.2 | 3.8 | 45.9 | 50.0 | 38.8 | 117.0 | 63.0 |
| ยี่: 34b-chat | 43.9 | 41.3 | 45.6 | 50.0 | 30.5 | 45.0 | 34.0 |
| MISTRAL: 7B-Instruct-V0.2-Q6_K | 21.7 | 20.9 | 45.4 | 50.0 | 31.3 | 44.0 | 23.0 |
| MISTRAL: 7B-Instruct-V0.2-Q4_0 | 12.4 | 12.3 | 44.3 | 50.0 | 30.6 | 75.0 | 32.0 |
| MISTRAL: 7B-Instruct-V0.2-Q4_K_M | 15.6 | 15.1 | 42.6 | 50.0 | 28.6 | 71.0 | 23.0 |
| Codellama: 34b-Instruct-q4_k_m | 7.5 | 6.8 | 39.7 | 50.0 | 36.1 | 127.0 | 35.0 |
| Codellama: 70b-Instruct-q4_k_m | 16.3 | 13.8 | 36.4 | 0.0 | 41.2 | 179.0 | 58.0 |
| SOLAR: 10.7B-Instruct-V1-Q4_K_M | 18.8 | 17.7 | 35.2 | 50.0 | 31.1 | 107.0 | 10.0 |
| Mistral: 7b-Instruct-q4_k_m | 13.9 | 13.0 | 34.8 | 50.0 | 26.5 | 80.0 | 0.0 |
| Codellama: 70b-Instruct-q2_k | 11.2 | 9.4 | 29.8 | 0.0 | 37.7 | 198.0 | 29.0 |
| Llama2 | 17.1 | 16.3 | 26.5 | 25.0 | 26.5 | 131.0 | 0.0 |
| Gemma: 7b-Instruct-q6_k | 20.9 | 22.1 | 25.9 | 25.0 | 25.2 | 147.0 | 2.0 |
| orca2: 13b | 20.1 | 18.3 | 23.1 | 0.0 | 30.6 | 166.0 | 11.0 |
| Stablelm-Zephyr | 9.9 | 7.7 | 15.4 | 0.0 | 23.5 | 192.0 | 1.0 |
| Dolphin-Phi: 2.7b-v2.6-q6_k | 8.9 | 8.4 | 14.9 | 0.0 | 22.9 | 188.0 | 0.0 |
| Codellama: 13b-Python | 12.5 | 10.7 | 12.8 | 0.0 | 22.1 | 155.0 | 0.0 |
| PHI: 2.7B-Chat-V2-Q6_K | 13.0 | 11.6 | 8.9 | 0.0 | 19.4 | 222.0 | 0.0 |
ข้อมูลเดียวกัน แต่เป็นแผนภูมิแท่ง:
และด้วยแถบแยกต่างหากสำหรับแต่ละเทมเพลตพร้อม: 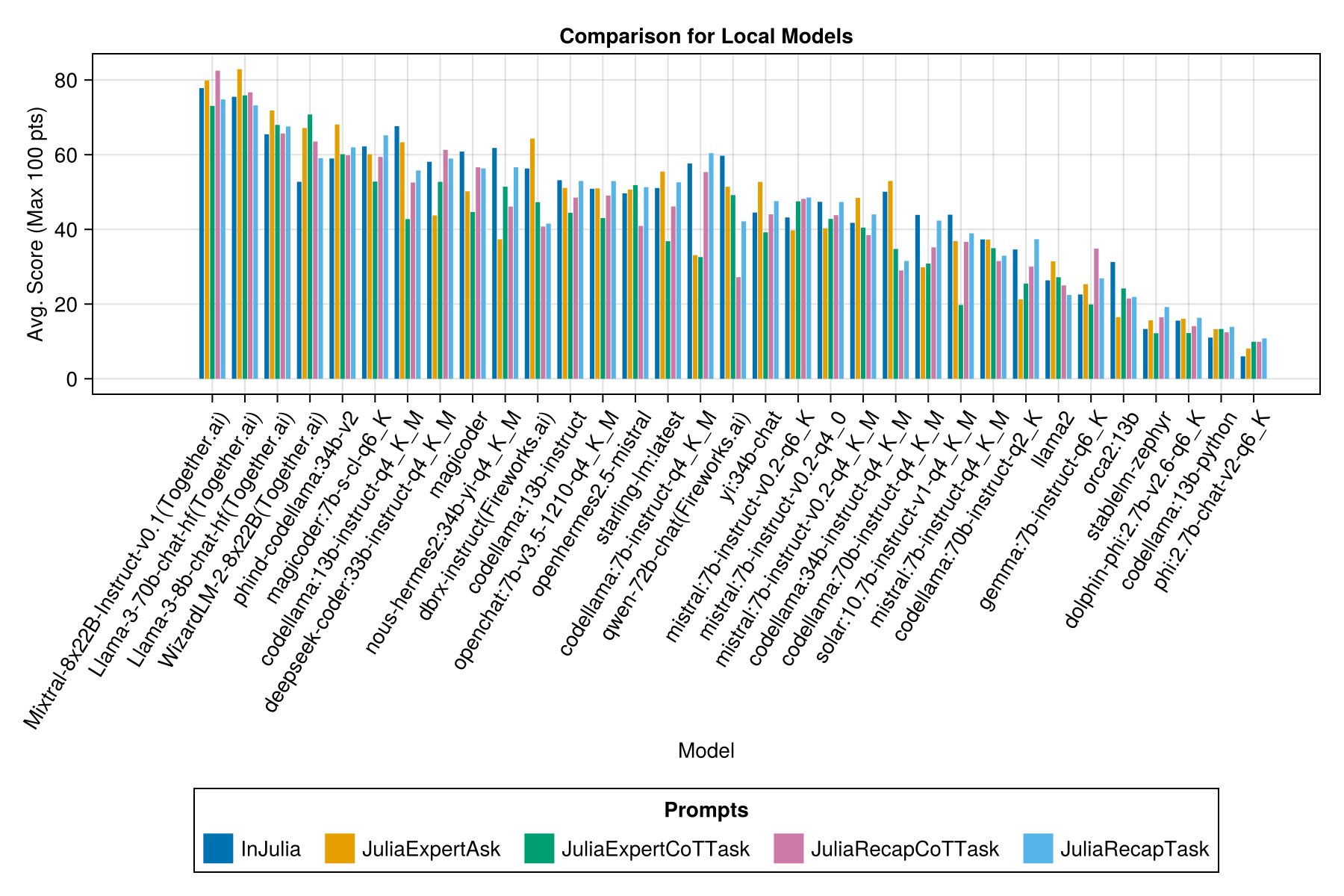
บันทึก
รุ่น Qwen-1.5 ถูกลบออกจากภาพรวมเนื่องจากโมเดลพื้นฐานใน Ollama Repository (และ HF) ไม่ถูกต้องและมีประสิทธิภาพต่ำมาก
บันทึก
ฉันสังเกตเห็นว่า Evals บางตัวใน Ollama/Llama.cpp ตอนนี้ทำคะแนนได้สูงกว่าในวันที่ 23 ธันวาคมเล็กน้อยดังนั้นมันจึงเป็นแผนงานที่จะเรียกใช้ Evals ข้างต้นอีกครั้ง
เห็นได้ชัดว่า APIs ที่ได้รับค่าตอบแทน (การเปิดตัวล่าสุด: GPT-3.5-turbo-1106) แต่นั่นไม่ใช่เรื่องราวทั้งหมด
เราหวังว่าจะสามารถให้คำแนะนำเกี่ยวกับกลยุทธ์การแจ้งเตือนเช่นเมื่อใดที่จะใช้เทมเพลต "Juliaexpert*" เมื่อเทียบกับ "ใน Julia, คำตอบ XYZ"
การเรียนรู้จนถึงตอนนี้:
| เทมเพลตพรอมต์ | ผ่านไป (S, เฉลี่ย) | ผ่านไป (S, ค่ามัธยฐาน) | avg. คะแนน (สูงสุด 100 pts) | คะแนนเฉลี่ย (สูงสุด 100 แต้ม) |
|---|---|---|---|---|
| การติดเชื้อ | 14.0 | 9.6 | 55.2 | 50.0 |
| Juliaexpertask | 9.9 | 6.4 | 53.8 | 50.0 |
| Juliarecaptask | 16.7 | 11.5 | 52.0 | 50.0 |
| juliaexpertcottask | 15.4 | 10.4 | 49.5 | 50.0 |
| Juliarecapcottask | 16.1 | 11.3 | 48.6 | 50.0 |
หมายเหตุ: เทมเพลตที่ใช้ XML ได้รับการทดสอบเฉพาะสำหรับรุ่น Claude 3 (Haiku และ Sonnet) นั่นคือเหตุผลที่เราลบออกจากการเปรียบเทียบ
ทำการวิเคราะห์ของคุณเองด้วย examples/summarize_results.jl !
scripts/code_gen_benchmark.jl สำหรับตัวอย่างของการประเมินก่อนหน้านี้ ต้องการเรียกใช้การทดลองและบันทึกผลลัพธ์หรือไม่? ตรวจสอบ examples/experiment_hyperparameter_scan.jl !
ต้องการตรวจสอบการทำงานของเกณฑ์มาตรฐานที่ผ่านมาหรือไม่? ตรวจสอบ examples/summarize_results.jl สำหรับสถิติโดยรวมและ examples/debugging_results.jl สำหรับการตรวจสอบการสนทนา/การตอบสนองแบบจำลองแต่ละครั้ง
เพื่อสนับสนุนกรณีทดสอบ:
code_generation/category/test_case_name/definition.tomlcode_generation/category/test case/model/evaluation__PROMPT__STRATEGY__TIMESTAMP.json ผล __prompt__strategy__timestamp.json และ code_generation/category/test case/model/conversation__PROMPT__STRATEGY__TIMESTAMP.jsondefinition.toml ฟิลด์ที่จำเป็นใน definition.toml รวมถึง:
my_function(1, 2) )@test X = Zมีหลายฟิลด์เสริม:
ฟิลด์ข้างต้นสามารถปรับปรุงการใช้รหัสซ้ำผ่านตัวอย่าง/การทดสอบหน่วย
ดูตัวอย่างใน examples/create_definition.jl คุณสามารถตรวจสอบความถูกต้องของคำจำกัดความกรณีทดสอบของคุณด้วย validate_definition()
โปรดประชาสัมพันธ์และเพิ่มการสนทนาที่เกี่ยวข้องและถูกต้องส่วนใหญ่กับ/in/เกี่ยวกับ Julia ในโฟลเดอร์ julia_conversations/
เป้าหมายคือการมีคอลเลกชันของการสนทนาที่มีประโยชน์สำหรับความรู้ Julia ในรูปแบบขนาดเล็ก
เราให้ความสำคัญกับการป้อนข้อมูลของชุมชน หากคุณมีข้อเสนอแนะหรือแนวคิดสำหรับการปรับปรุงโปรดเปิดปัญหา ยินดีต้อนรับการมีส่วนร่วมทั้งหมด!


