Julia LLM Leaderboard
v0.2.0
Perbandingan kemampuan generasi bahasa Julia dari berbagai model bahasa besar
definition.tomlSelamat datang di Julia Code Generation Benchmark Repository!
Proyek ini dirancang untuk komunitas Julia untuk membandingkan kemampuan pembuatan kode dari berbagai model AI. Tidak seperti tolok ukur akademik, fokus kami adalah kepraktisan dan kesederhanaan: "Hasilkan kode, jalankan, dan lihat apakah itu berhasil (-ish)."
Repositori ini bertujuan untuk memahami bagaimana model AI dan strategi yang berbeda berkinerja dalam menghasilkan kode Julia yang benar secara sintaksis untuk memandu pengguna dalam memilih model terbaik untuk kebutuhan mereka.
Jari gatal? Lompat ke examples/ atau cukup jalankan tolok ukur Anda sendiri dengan run_benchmark() (misalnya, examples/code_gen_benchmark.jl ).
Kasus uji didefinisikan dalam file definition.toml , menyediakan struktur standar untuk setiap tes. Jika Anda ingin menyumbangkan kasus uji, silakan ikuti instruksi di bagian kasus uji yang berkontribusi.
Setiap model dan kinerja prompt dievaluasi berdasarkan beberapa kriteria:
Saat ini, semua kriteria ditimbang sama dan setiap test case dapat memperoleh maksimum 100 poin. Jika kode melewati semua kriteria, ia mendapat 100/100 poin. Jika gagal satu kriteria (misalnya, semua tes unit), ia mendapat 75/100 poin. Jika gagal dua kriteria (misalnya, itu berjalan tetapi semua contoh dan tes unit rusak), ia mendapat 50 poin, dan sebagainya.
Untuk memberikan sekilas fungsionalitas repositori, kami telah menyertakan hasil contoh untuk 14 kasus uji pertama. Buka dokumentasi untuk hasil lengkap dan penyelaman mendalam pada setiap test case.
Peringatan
Skor ini mungkin berubah saat kami mengembangkan fungsi pendukung dan menambahkan lebih banyak model.
Ingatlah bahwa tolok ukurnya cukup menantang untuk model apa pun - satu ruang tambahan atau tanda kurung dan skornya mungkin menjadi 0 (= "tidak dapat diurai")!
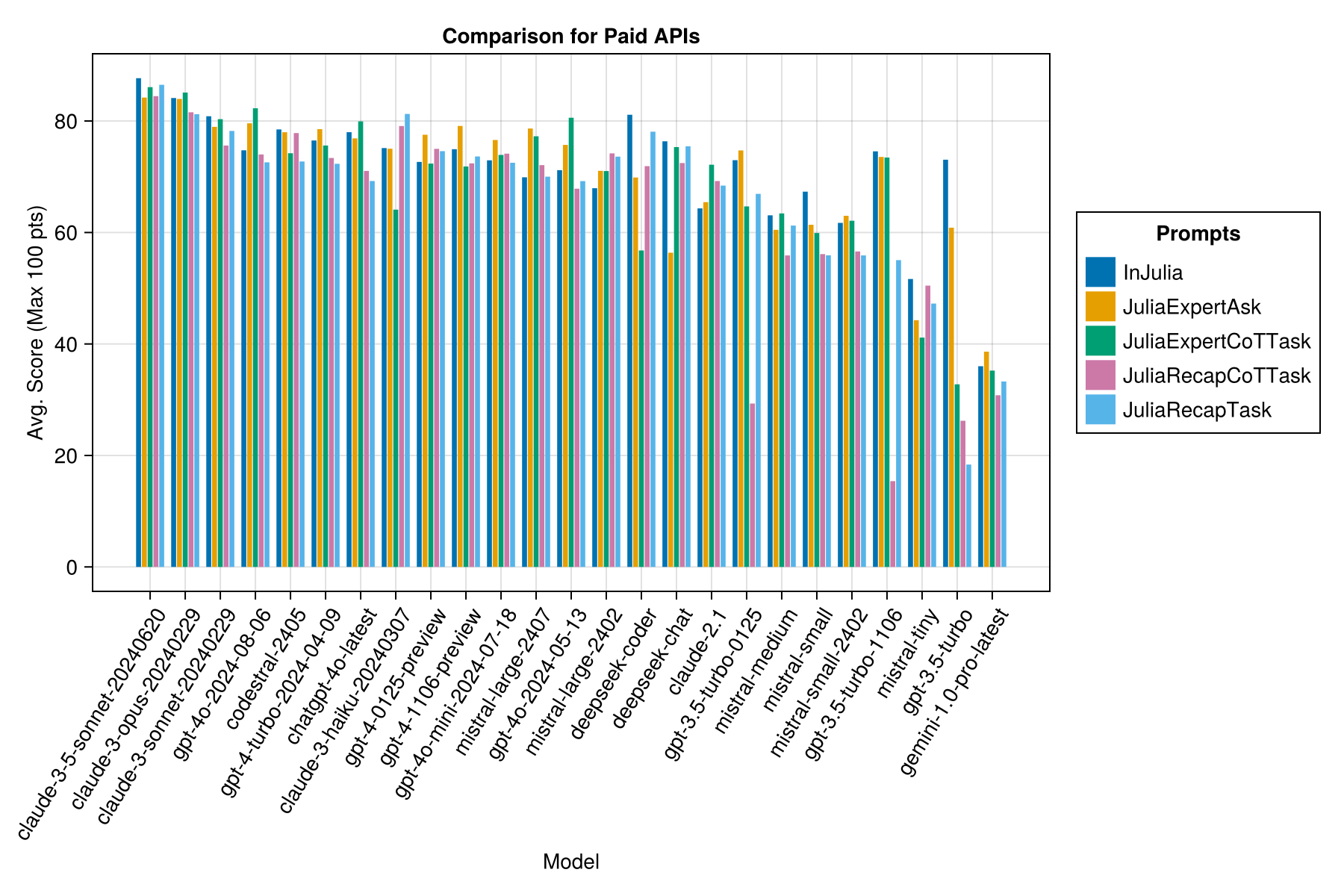
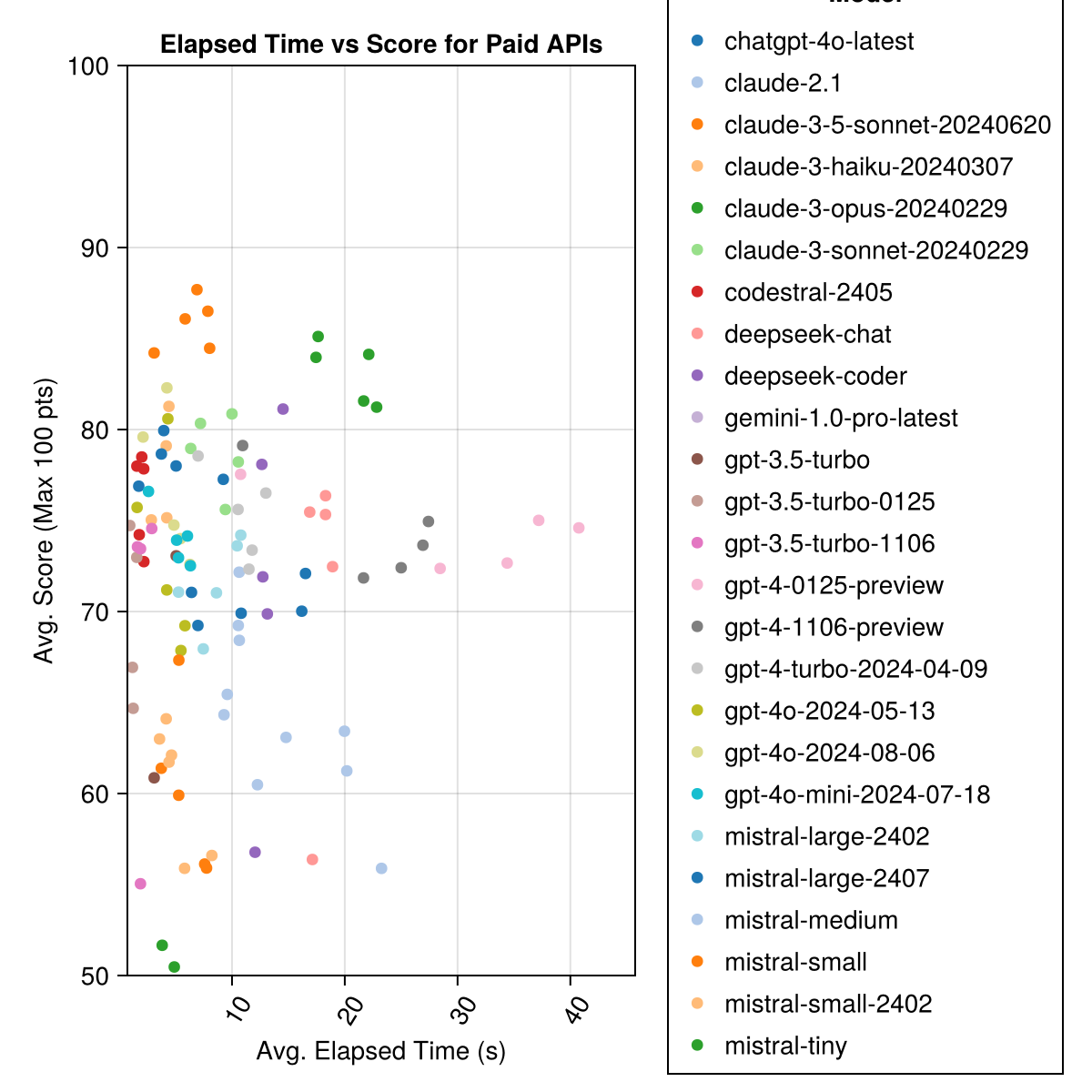
Claude 3.5 Sonnet adalah model berkinerja tertinggi. Untuk nilai-untuk-uang terbaik, lihat codestral mistral, Claude 3 haiku dan, baru-baru ini dirilis, GPT 4O mini (60% lebih murah daripada GPT3.5 !!!).
| Model | Berlalu | Skor | Skor STD Deviation | Hitung skor nol | Hitung skor penuh | Biaya sen |
|---|---|---|---|---|---|---|
| Claude-3-5-Sonnet-20240620 | 6.3 | 85.8 | 21.1 | 13 | 355 | 0.73 |
| Claude-3-Opus-20240229 | 20.3 | 83.2 | 19.6 | 2 | 329 | 3.9 |
| Claude-3-Sonnet-20240229 | 8.7 | 78.8 | 26.2 | 22 | 308 | 0.73 |
| GPT-4O-2024-08-06 | 4.6 | 76.6 | 27.9 | 26 | 310 | 0,0 |
| Codestral-2405 | 1.9 | 76.3 | 29.3 | 33 | 276 | 0,0 |
| GPT-4-TURBO-2024-04-09 | 10.8 | 75.3 | 29.6 | 38 | 290 | 1.38 |
| chatgpt-4o-latest | 4.8 | 75.0 | 27.9 | 25 | 263 | 0,0 |
| Claude-3-haiku-20240307 | 4.0 | 74.9 | 27.2 | 9 | 261 | 0,05 |
| GPT-4-0125-preview | 30.3 | 74.4 | 30.3 | 39 | 284 | 1.29 |
| GPT-4-1106-preview | 22.4 | 74.4 | 29.9 | 19 | 142 | 1.21 |
| GPT-4O-Mini-2024-07-18 | 5.1 | 74.0 | 29.4 | 32 | 276 | 0,03 |
| Mistral-Large-2407 | 11.3 | 73.6 | 29.5 | 15 | 137 | 0.49 |
| GPT-4O-2024-05-13 | 4.3 | 72.9 | 29.1 | 29 | 257 | 0,0 |
| Deepseek-Coder | 13.0 | 71.6 | 32.6 | 39 | 115 | 0,01 |
| Mistral-Large-2402 | 8.5 | 71.6 | 27.2 | 13 | 223 | 0,0 |
| Deepseek-Cat | 17.9 | 71.3 | 32.9 | 30 | 140 | 0,01 |
| Claude-2.1 | 10.1 | 67.9 | 30.8 | 47 | 229 | 0.8 |
| GPT-3.5-TURBO-0125 | 1.2 | 61.7 | 36.6 | 125 | 192 | 0,03 |
| Midral-Medium | 18.1 | 60.8 | 33.2 | 22 | 90 | 0.41 |
| Mistral-Small | 5.9 | 60.1 | 30.2 | 27 | 76 | 0,09 |
| Mistral-Small-2402 | 5.3 | 59.9 | 29.4 | 31 | 169 | 0,0 |
| GPT-3.5-turbo-1106 | 2.1 | 58.4 | 39.2 | 82 | 97 | 0,04 |
| Mistral-kecil | 4.6 | 46.9 | 32.0 | 75 | 42 | 0,02 |
| GPT-3.5-turbo | 3.6 | 42.3 | 38.2 | 132 | 54 | 0,04 |
| Gemini-1.0-pro-latest | 4.2 | 34.8 | 27.4 | 181 | 25 | 0,0 |
Catatan: Dari pertengahan Februari 2024, "GPT-3.5-Turbo" akan menunjuk ke rilis terbaru, "GPT-3.5-Turbo-0125" (mencela rilis Juni).
Informasi yang sama, tetapi sebagai bagan batang:
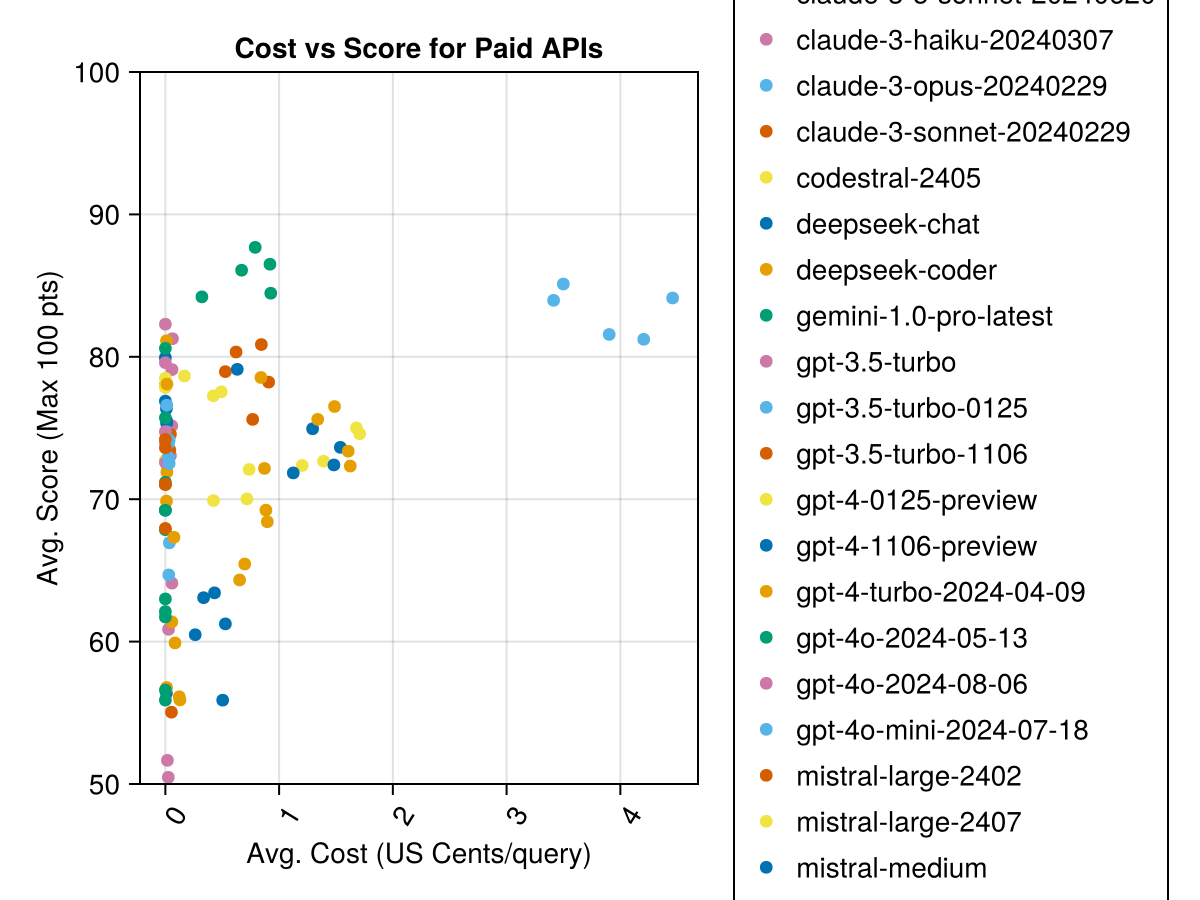
Selain itu, kita dapat mempertimbangkan kinerja (skor) versus biaya (diukur dalam sen AS):
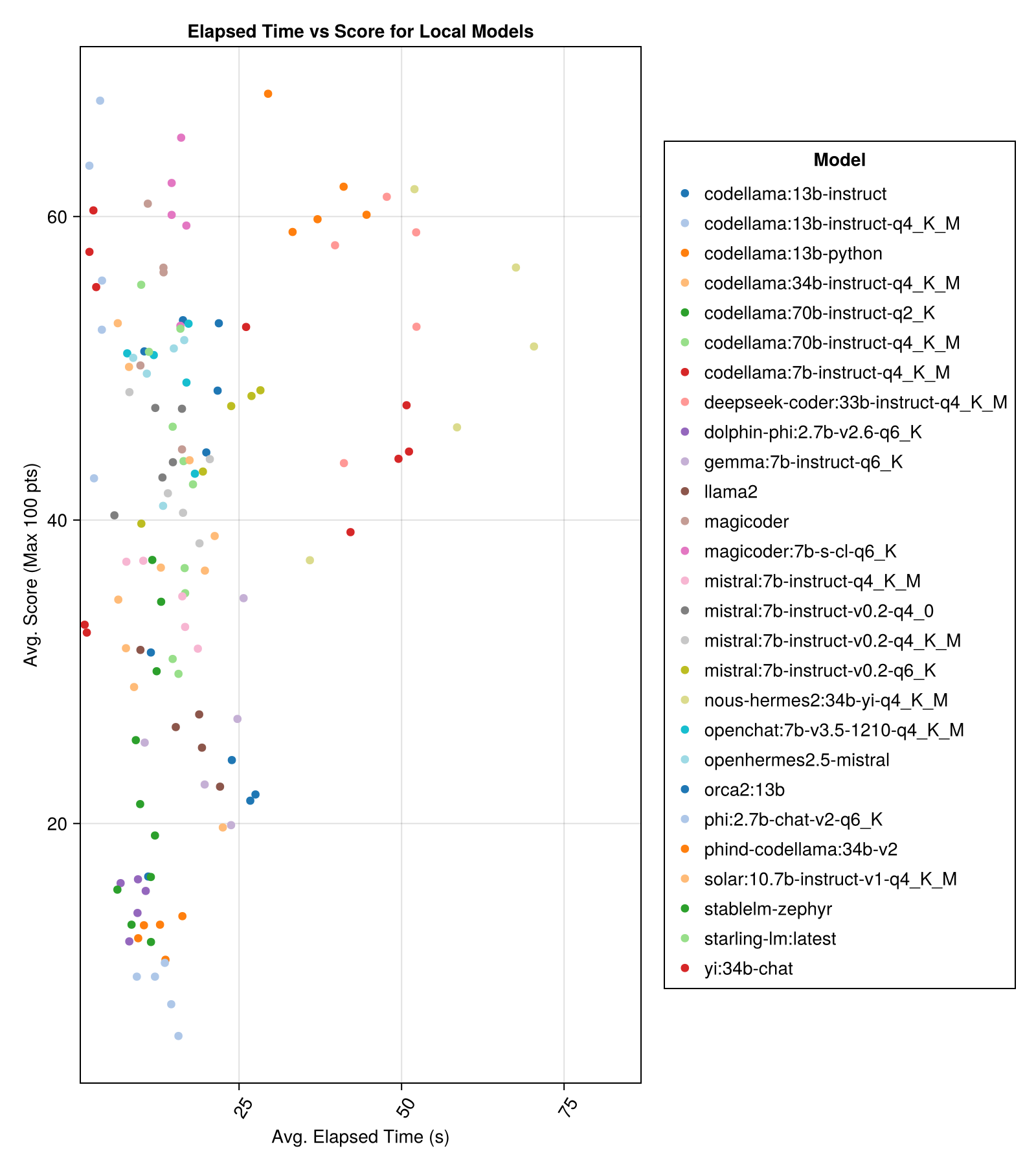
Model yang diselenggarakan secara lokal umumnya tidak sebagus API berbayar terbaik, tetapi mereka semakin dekat! Perhatikan bahwa "Mistral-Small" sudah tersedia untuk dijalankan secara lokal dan akan ada banyak finetunes di masa depan!
Catatan
Terima kasih banyak untuk 01.ai dan Jun Tian khususnya karena memberikan komputasi untuk beberapa bagian dari tolok ukur ini!
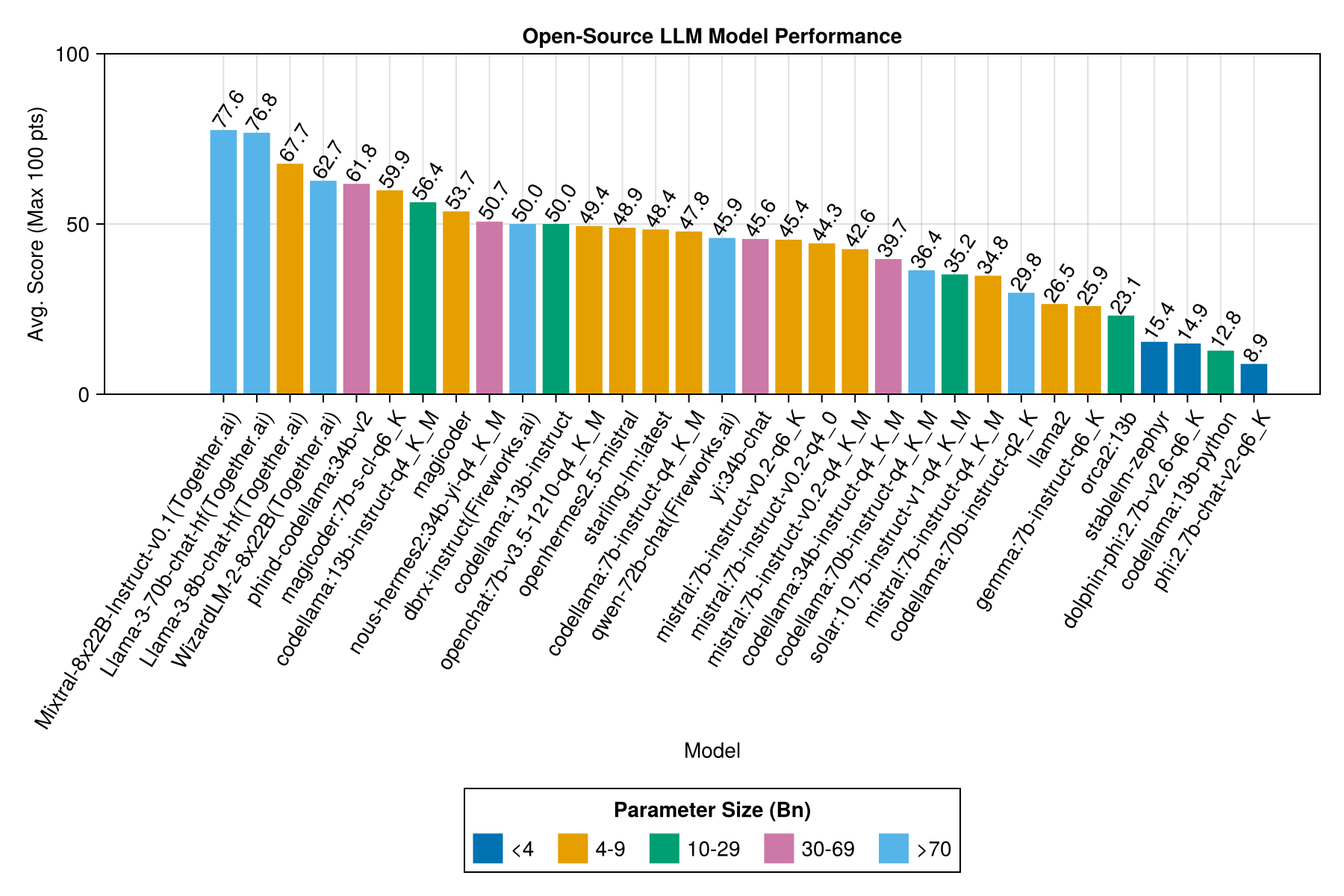
Kinerja trade-off terbaik vs ukuran adalah meta llama3 8bn terbaru. Kalau tidak, model terkemuka adalah Mixtral-8x22bn.
| Model | Berlalu | Median yang berlalu | Skor | Skor median | Skor STD Deviation | Hitung skor nol | Hitung skor penuh |
|---|---|---|---|---|---|---|---|
| MIXTRAL-8X22B-INSTRUCT-V0.1 (Together.AI) | 14.1 | 11.0 | 77.6 | 90.0 | 25.8 | 5.0 | 151.0 |
| Llama-3-70b-chat-hf (bersama.ai) | 4.3 | 4.1 | 76.8 | 88.3 | 25.2 | 0,0 | 160.0 |
| Llama-3-8b-chat-hf (bersama.ai) | 1.5 | 1.4 | 67.7 | 66.7 | 26.4 | 5.0 | 70.0 |
| Wizardlm-2-8x22b (bersama.ai) | 34.7 | 31.0 | 62.7 | 60.0 | 33.8 | 33.0 | 118.0 |
| Phind-Codellama: 34B-V2 | 37.1 | 36.4 | 61.8 | 62.5 | 33.5 | 36.0 | 58.0 |
| Magicoder: 7b-s-cl-q6_k | 15.6 | 15.8 | 59.9 | 60.0 | 29.9 | 18.0 | 35.0 |
| Codellama: 13b-instruct-q4_k_m | 3.2 | 3.0 | 56.4 | 54.6 | 33.0 | 56.0 | 61.0 |
| Deepseek-Coder: 33b-instruct-q4_k_m | 46.7 | 44.6 | 55.0 | 50.0 | 36.8 | 62.0 | 68.0 |
| Magicoder | 12.8 | 10.7 | 53.7 | 50.0 | 33.2 | 49.0 | 52.0 |
| nous-hermes2: 34b-yi-q4_k_m | 56.8 | 52.8 | 50.7 | 50.0 | 34.7 | 78.0 | 56.0 |
| DBRX-instruct (Fireworks.ai) | 3.7 | 3.6 | 50.0 | 50.0 | 41.2 | 121.0 | 75.0 |
| Codellama: 13B-instruct | 18.1 | 16.7 | 50.0 | 50.0 | 34.4 | 65.0 | 44.0 |
| OpenChat: 7B-V3.5-1210-Q4_K_M | 14.4 | 13.7 | 49.4 | 50.0 | 30.3 | 48.0 | 23.0 |
| OpenHermes2.5-mistral | 12.9 | 12.2 | 48.9 | 50.0 | 31.3 | 55.0 | 27.0 |
| Starling-LM: Terbaru | 13.7 | 12.5 | 48.4 | 50.0 | 30.2 | 58.0 | 26.0 |
| Codellama: 7b-instruct-q4_k_m | 2.1 | 2.0 | 47.8 | 50.0 | 35.3 | 95.0 | 38.0 |
| QWEN-72B-CHAT (Fireworks.ai) | 3.2 | 3.8 | 45.9 | 50.0 | 38.8 | 117.0 | 63.0 |
| Yi: 34B-CHAT | 43.9 | 41.3 | 45.6 | 50.0 | 30.5 | 45.0 | 34.0 |
| Mistral: 7b-instruct-v0.2-q6_k | 21.7 | 20.9 | 45.4 | 50.0 | 31.3 | 44.0 | 23.0 |
| Mistral: 7B-instruct-V0.2-Q4_0 | 12.4 | 12.3 | 44.3 | 50.0 | 30.6 | 75.0 | 32.0 |
| Mistral: 7b-instruct-v0.2-q4_k_m | 15.6 | 15.1 | 42.6 | 50.0 | 28.6 | 71.0 | 23.0 |
| Codellama: 34b-instruct-q4_k_m | 7.5 | 6.8 | 39.7 | 50.0 | 36.1 | 127.0 | 35.0 |
| Codellama: 70b-instruct-q4_k_m | 16.3 | 13.8 | 36.4 | 0,0 | 41.2 | 179.0 | 58.0 |
| Solar: 10.7b-instruct-v1-q4_k_m | 18.8 | 17.7 | 35.2 | 50.0 | 31.1 | 107.0 | 10.0 |
| Mistral: 7b-instruct-q4_k_m | 13.9 | 13.0 | 34.8 | 50.0 | 26.5 | 80.0 | 0,0 |
| Codellama: 70b-instruct-q2_k | 11.2 | 9.4 | 29.8 | 0,0 | 37.7 | 198.0 | 29.0 |
| llama2 | 17.1 | 16.3 | 26.5 | 25.0 | 26.5 | 131.0 | 0,0 |
| Gemma: 7b-instruct-q6_k | 20.9 | 22.1 | 25.9 | 25.0 | 25.2 | 147.0 | 2.0 |
| orca2: 13b | 20.1 | 18.3 | 23.1 | 0,0 | 30.6 | 166.0 | 11.0 |
| Stablelm-Zephyr | 9.9 | 7.7 | 15.4 | 0,0 | 23.5 | 192.0 | 1.0 |
| DOLPHIN-PHI: 2.7B-V2.6-Q6_K | 8.9 | 8.4 | 14.9 | 0,0 | 22.9 | 188.0 | 0,0 |
| Codellama: 13B-Python | 12.5 | 10.7 | 12.8 | 0,0 | 22.1 | 155.0 | 0,0 |
| PHI: 2.7B-CHAT-V2-Q6_K | 13.0 | 11.6 | 8.9 | 0,0 | 19.4 | 222.0 | 0,0 |
Informasi yang sama, tetapi sebagai bagan batang:
Dan dengan bilah terpisah untuk setiap template prompt: 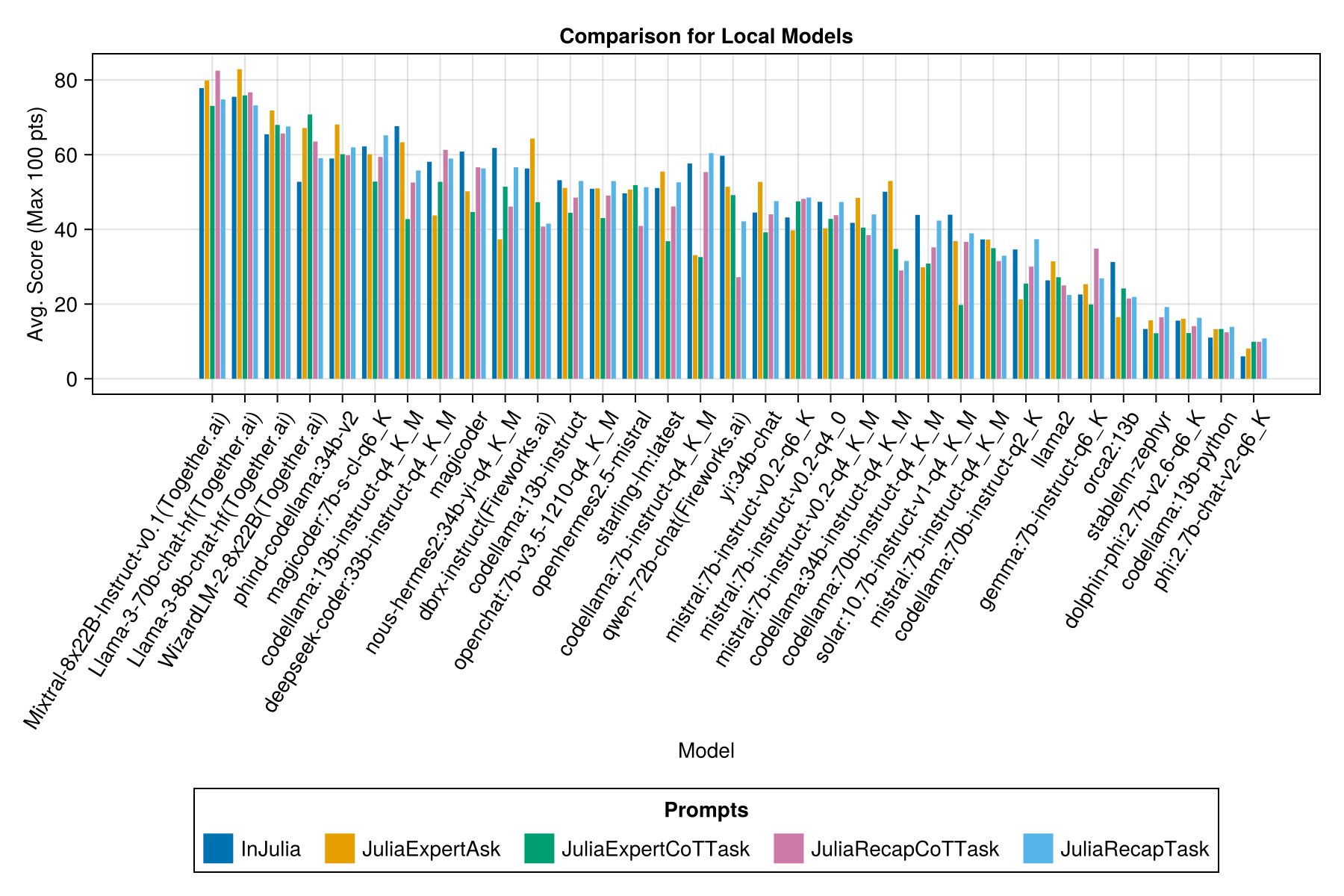
Catatan
Model QWEN-1..5 telah dihapus dari ikhtisar sebagai model yang mendasari Repositori Ollama (dan HF) tidak benar dan memiliki kinerja yang sangat rendah.
Catatan
Saya telah memperhatikan bahwa beberapa eval di ollama/llama.cpp sekarang skor sedikit lebih tinggi sekarang daripada pada Des-23, jadi ada di peta jalan untuk menjalankan kembali eval di atas.
Jelas, kemenangan API berbayar (rilis terbaru: GPT-3.5-turbo-1106), tapi itu bukan keseluruhan cerita.
Kami berharap dapat memberikan beberapa panduan seputar strategi yang mendorong, misalnya, kapan lebih baik menggunakan template "JuliaExpert*" yang cepat vs "di Julia, menjawab xyz" prompt.
Pembelajaran sejauh ini:
| Template cepat | Berlalu (s, rata -rata) | Berlalu (s, median) | Rata -rata. Skor (maks 100 poin) | Skor median (maks 100 poin) |
|---|---|---|---|---|
| Injulia | 14.0 | 9.6 | 55.2 | 50.0 |
| JuliaExperTask | 9.9 | 6.4 | 53.8 | 50.0 |
| Juliarecaptask | 16.7 | 11.5 | 52.0 | 50.0 |
| JuliaExpertcottask | 15.4 | 10.4 | 49.5 | 50.0 |
| Juliarecapcotkask | 16.1 | 11.3 | 48.6 | 50.0 |
Catatan: Templat berbasis XML hanya diuji untuk model Claude 3 (haiku dan sonnet), itulah sebabnya kami menghapusnya dari perbandingan.
Buat analisis Anda sendiri dengan examples/summarize_results.jl !
scripts/code_gen_benchmark.jl untuk contoh evaluasi sebelumnya. Ingin menjalankan beberapa percobaan dan menyimpan hasilnya? Lihat examples/experiment_hyperparameter_scan.jl !
Ingin meninjau beberapa tolok ukur masa lalu? Lihat examples/summarize_results.jl untuk keseluruhan statistik dan examples/debugging_results.jl untuk meninjau respons percakapan/model individu.
Untuk menyumbangkan kasus uji:
code_generation/category/test_case_name/definition.toml .code_generation/category/test case/model/evaluation__PROMPT__STRATEGY__TIMESTAMP.json dan code_generation/category/test case/model/conversation__PROMPT__STRATEGY__TIMESTAMP.jsondefinition.toml Bidang yang diperlukan dalam definition.toml meliputi:
my_function(1, 2) ).@test X = Z .Ada beberapa bidang opsional:
Bidang di atas dapat meningkatkan penggunaan kembali kode di seluruh contoh/tes unit.
Lihat contoh dalam examples/create_definition.jl . Anda dapat memvalidasi definisi kasus uji Anda dengan validate_definition() .
Silakan PR dan tambahkan percakapan yang relevan dan sebagian besar benar dengan/di/tentang Julia di folder julia_conversations/ .
Tujuannya adalah untuk memiliki kumpulan percakapan yang berguna untuk pengetahuan Julia yang lebih besar dalam model yang lebih kecil.
Kami sangat menghargai masukan komunitas. Jika Anda memiliki saran atau ide untuk perbaikan, silakan buka masalah. Semua kontribusi dipersilakan!


