Julia LLM Leaderboard
v0.2.0
さまざまな大手言語モデルのジュリア語生成能力の比較
definition.tomlの解剖学。TOMLジュリアコードジェネレーションベンチマークリポジトリへようこそ!
このプロジェクトは、ジュリアコミュニティがさまざまなAIモデルのコード生成機能を比較するために設計されています。アカデミックベンチマークとは異なり、私たちの焦点は実用性とシンプルさです。「コードを生成し、実行し、それが機能するかどうかを確認します(-ish)。」
このリポジトリは、さまざまなAIモデルとプロンプト戦略がどのように機能するかを理解することを目的としています。ジュリアコードを構文的に修正して、ユーザーがニーズに最適なモデルを選択する際にガイドすることを目的としています。
かゆみのある指? run_benchmark() (例: examples/code_gen_benchmark.jl )を使用してexamples/にジャンプしてください。
テストケースは、 definition.tomlファイルで定義されており、各テストの標準構造を提供します。テストケースを提供する場合は、テストケースの貢献セクションの指示に従ってください。
各モデルとプロンプトのパフォーマンスは、いくつかの基準に基づいて評価されます。
現時点では、すべての基準が均等に計量されており、各テストケースは最大100ポイントを獲得できます。コードがすべての基準を渡すと、100/100ポイントが得られます。 1つの基準(たとえば、すべての単体テスト)に障害が発生した場合、75/100ポイントが得られます。 2つの基準に失敗した場合(たとえば、実行されますが、すべての例と単体テストが壊れています)、50ポイントなどがあります。
リポジトリの機能を垣間見るために、最初の14のテストケースの結果を例に掲載しました。完全な結果のドキュメントを開き、各テストケースに深く潜ります。
警告
これらのスコアは、サポート機能を進化させ、モデルを追加するにつれて変化する可能性があります。
ベンチマークはあらゆるモデルにとって非常に挑戦的であることを忘れないでください - 単一の余分なスペースまたは括弧では、スコアが0になる可能性があります(=「解析できません」)。
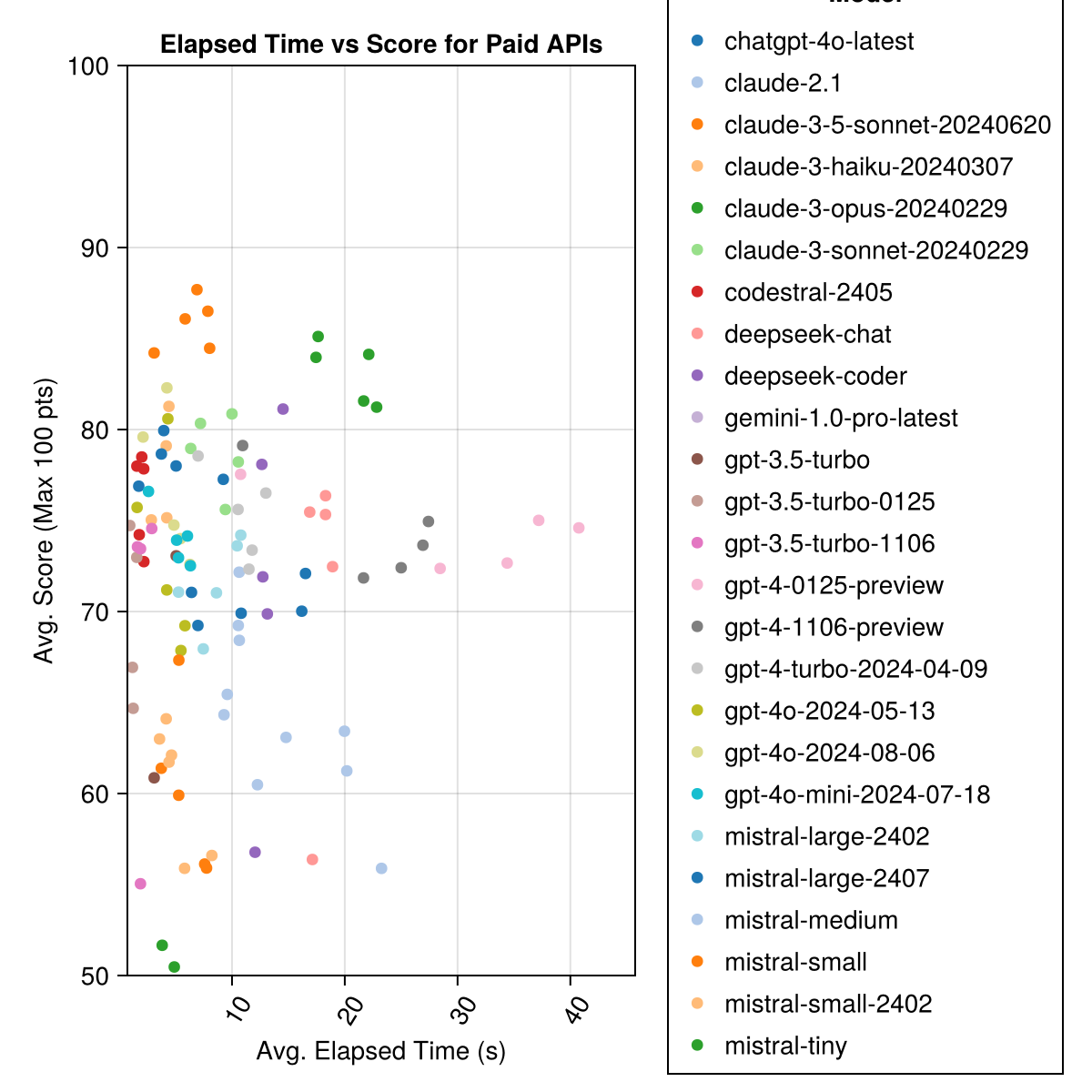
Claude 3.5ソネットは、最高のパフォーマンスモデルです。最高の価値を得るには、ミストラルコードストラル、クロード3ハイク、そして最近リリースされたGPT 4o Mini(GPT3.5よりも60%安い!!!)をご覧ください。
| モデル | 経過 | スコア | スコアSTD偏差 | ゼロスコアをカウントします | フルスコアをカウントします | コストセント |
|---|---|---|---|---|---|---|
| Claude-3-5-Sonnet-20240620 | 6.3 | 85.8 | 21.1 | 13 | 355 | 0.73 |
| Claude-3-OPUS-20240229 | 20.3 | 83.2 | 19.6 | 2 | 329 | 3.9 |
| claude-3-sonnet-20240229 | 8.7 | 78.8 | 26.2 | 22 | 308 | 0.73 |
| GPT-4O-2024-08-06 | 4.6 | 76.6 | 27.9 | 26 | 310 | 0.0 |
| Codestral-2405 | 1.9 | 76.3 | 29.3 | 33 | 276 | 0.0 |
| GPT-4-TURBO-2024-04-09 | 10.8 | 75.3 | 29.6 | 38 | 290 | 1.38 |
| chatgpt-4o-latest | 4.8 | 75.0 | 27.9 | 25 | 263 | 0.0 |
| Claude-3-Haiku-20240307 | 4.0 | 74.9 | 27.2 | 9 | 261 | 0.05 |
| GPT-4-0125-PREVIEW | 30.3 | 74.4 | 30.3 | 39 | 284 | 1.29 |
| GPT-4-1106-PREVIEW | 22.4 | 74.4 | 29.9 | 19 | 142 | 1.21 |
| GPT-4O-MINI-2024-07-18 | 5.1 | 74.0 | 29.4 | 32 | 276 | 0.03 |
| ミストラル - ラージ-2407 | 11.3 | 73.6 | 29.5 | 15 | 137 | 0.49 |
| GPT-4O-2024-05-13 | 4.3 | 72.9 | 29.1 | 29 | 257 | 0.0 |
| deepseek-coder | 13.0 | 71.6 | 32.6 | 39 | 115 | 0.01 |
| ミストラル - ラージ-2402 | 8.5 | 71.6 | 27.2 | 13 | 223 | 0.0 |
| deepseek-chat | 17.9 | 71.3 | 32.9 | 30 | 140 | 0.01 |
| クロード-2.1 | 10.1 | 67.9 | 30.8 | 47 | 229 | 0.8 |
| GPT-3.5-Turbo-0125 | 1.2 | 61.7 | 36.6 | 125 | 192 | 0.03 |
| ミストラルメディアム | 18.1 | 60.8 | 33.2 | 22 | 90 | 0.41 |
| ミストラルスモール | 5.9 | 60.1 | 30.2 | 27 | 76 | 0.09 |
| Mistral-Small-2402 | 5.3 | 59.9 | 29.4 | 31 | 169 | 0.0 |
| GPT-3.5-TURBO-106 | 2.1 | 58.4 | 39.2 | 82 | 97 | 0.04 |
| ミストラルタイニー | 4.6 | 46.9 | 32.0 | 75 | 42 | 0.02 |
| GPT-3.5-ターボ | 3.6 | 42.3 | 38.2 | 132 | 54 | 0.04 |
| gemini-1.0-pro-latest | 4.2 | 34.8 | 27.4 | 181 | 25 | 0.0 |
注:2024年2月中旬から、「GPT-3.5-Turbo」は最新リリース「GPT-3.5-Turbo-0125」(6月のリリースを非難)を指します。
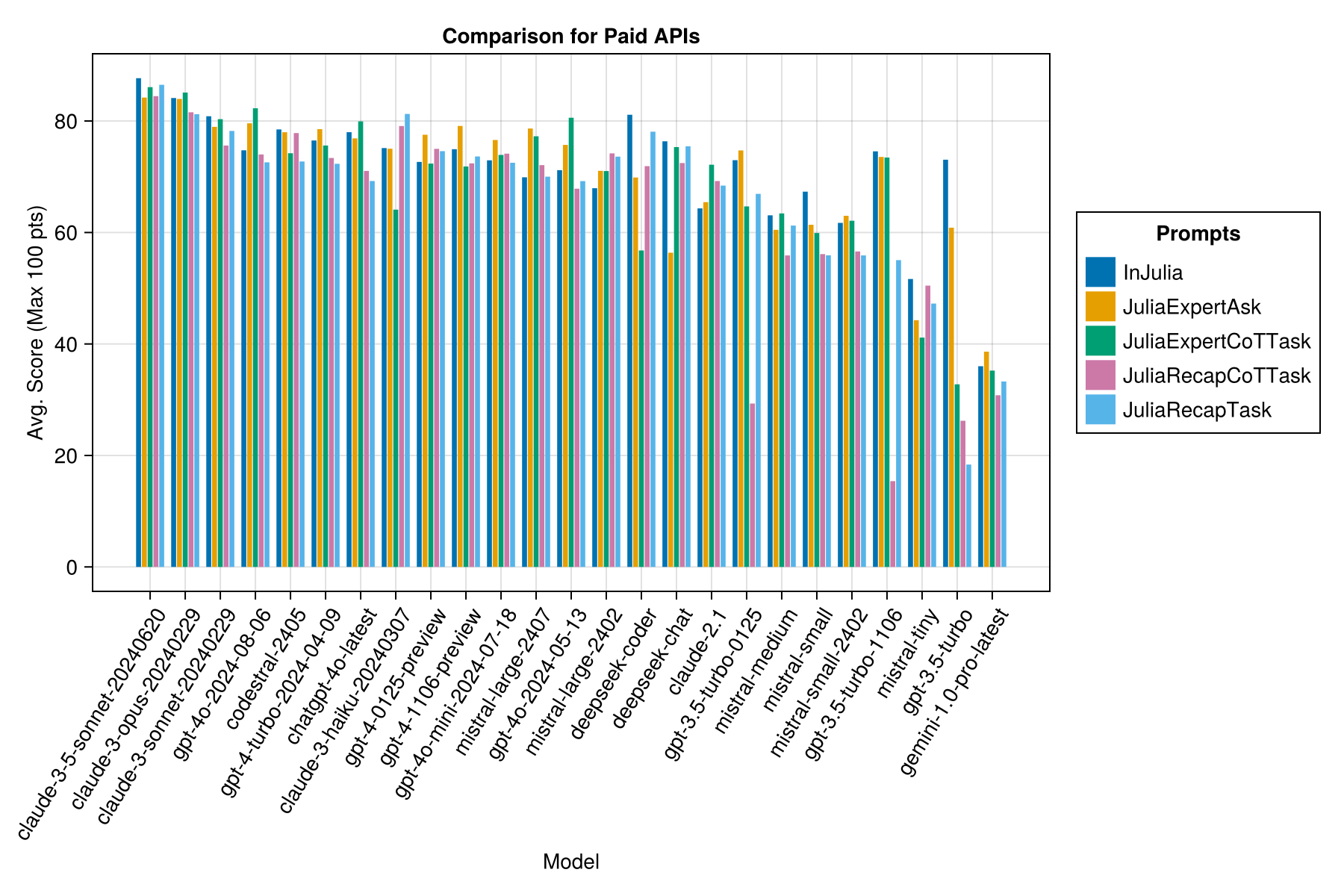
同じ情報ですが、バーチャートとして:
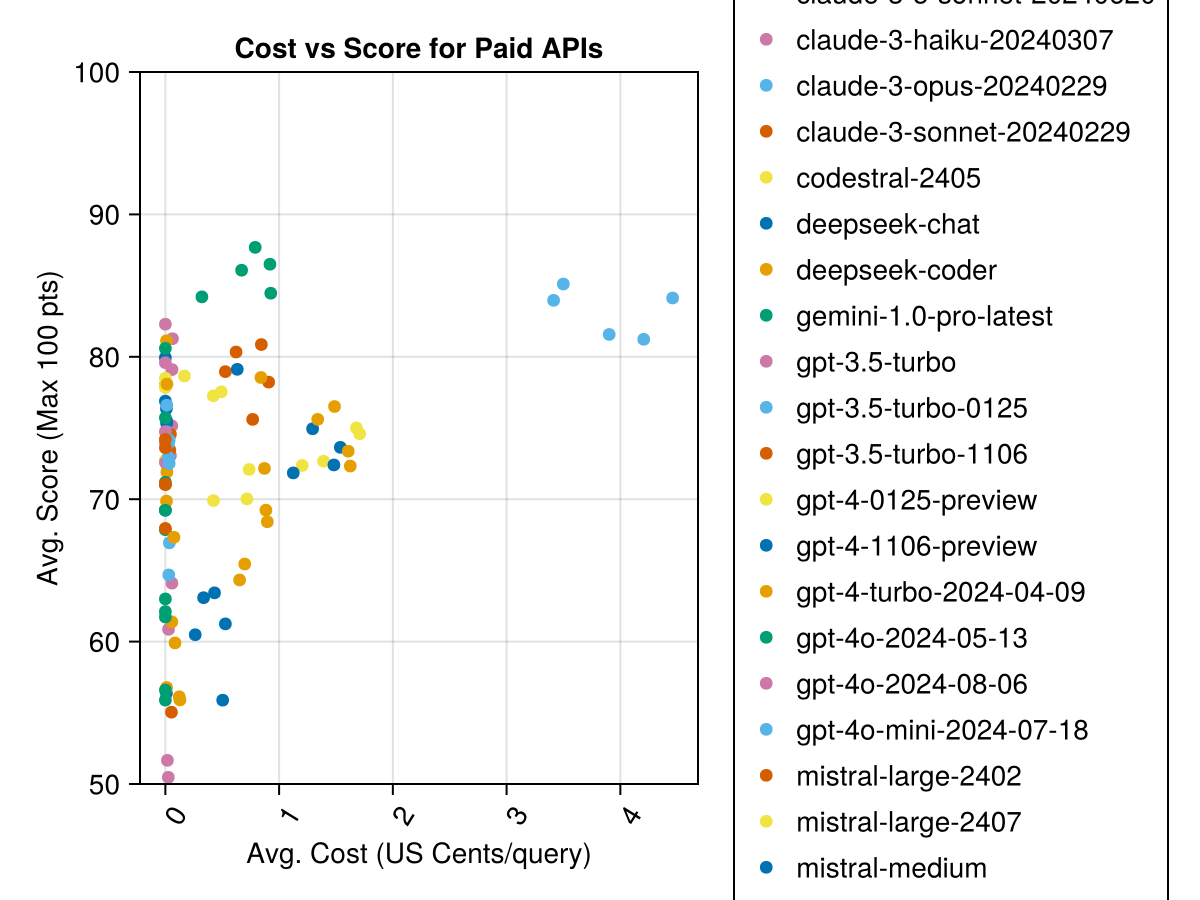
さらに、パフォーマンス(スコア)とコスト(米国セントで測定)を考慮することができます。
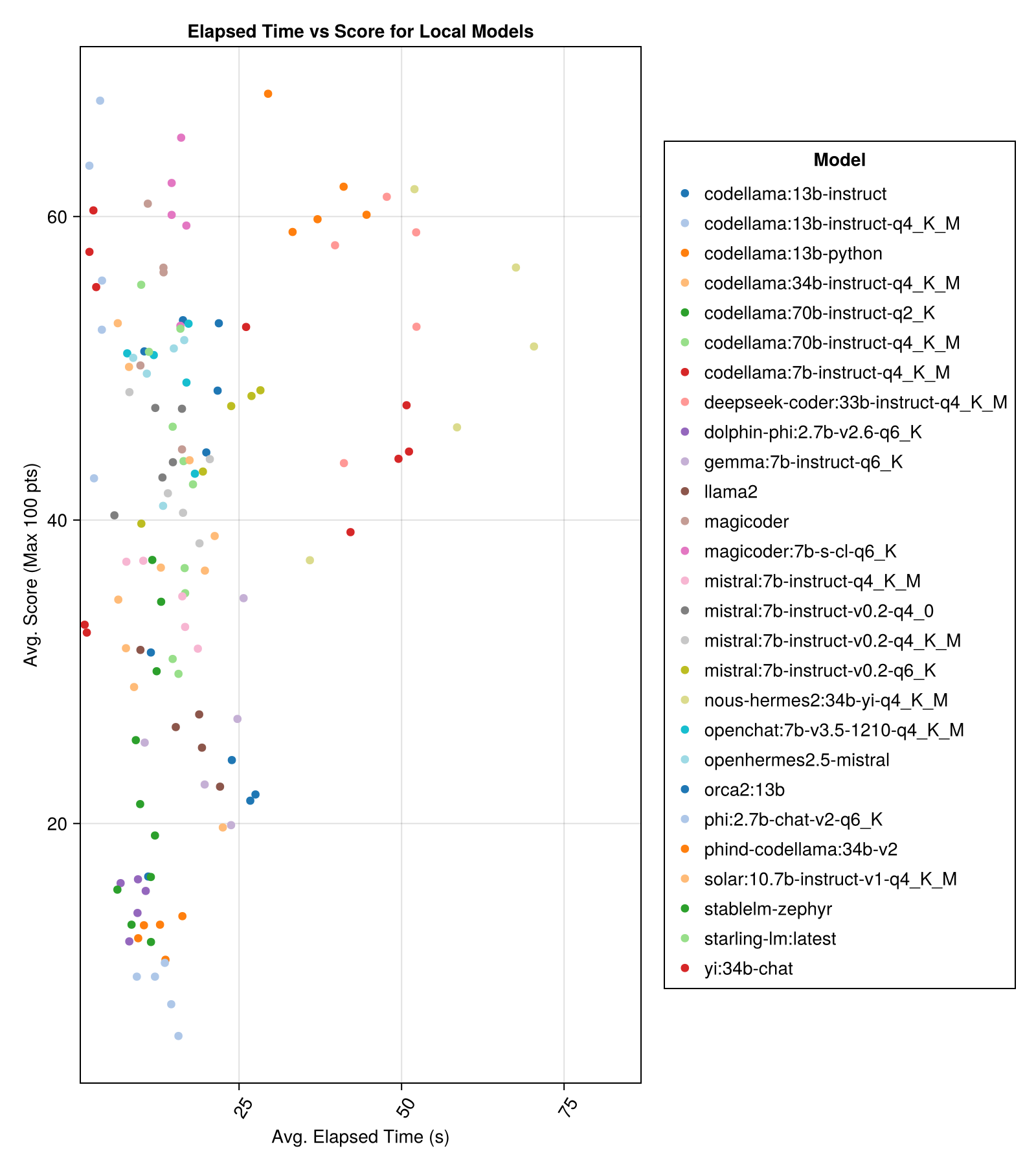
ローカルにホストされたモデルは、一般的に最高の有料APIほど良くありませんが、近づいています! 「ミストラルスマル」はすでにローカルで実行できることに注意してください。
注記
このベンチマークのいくつかの部分に計算を提供してくれた01.aiとJun Tianに感謝します!
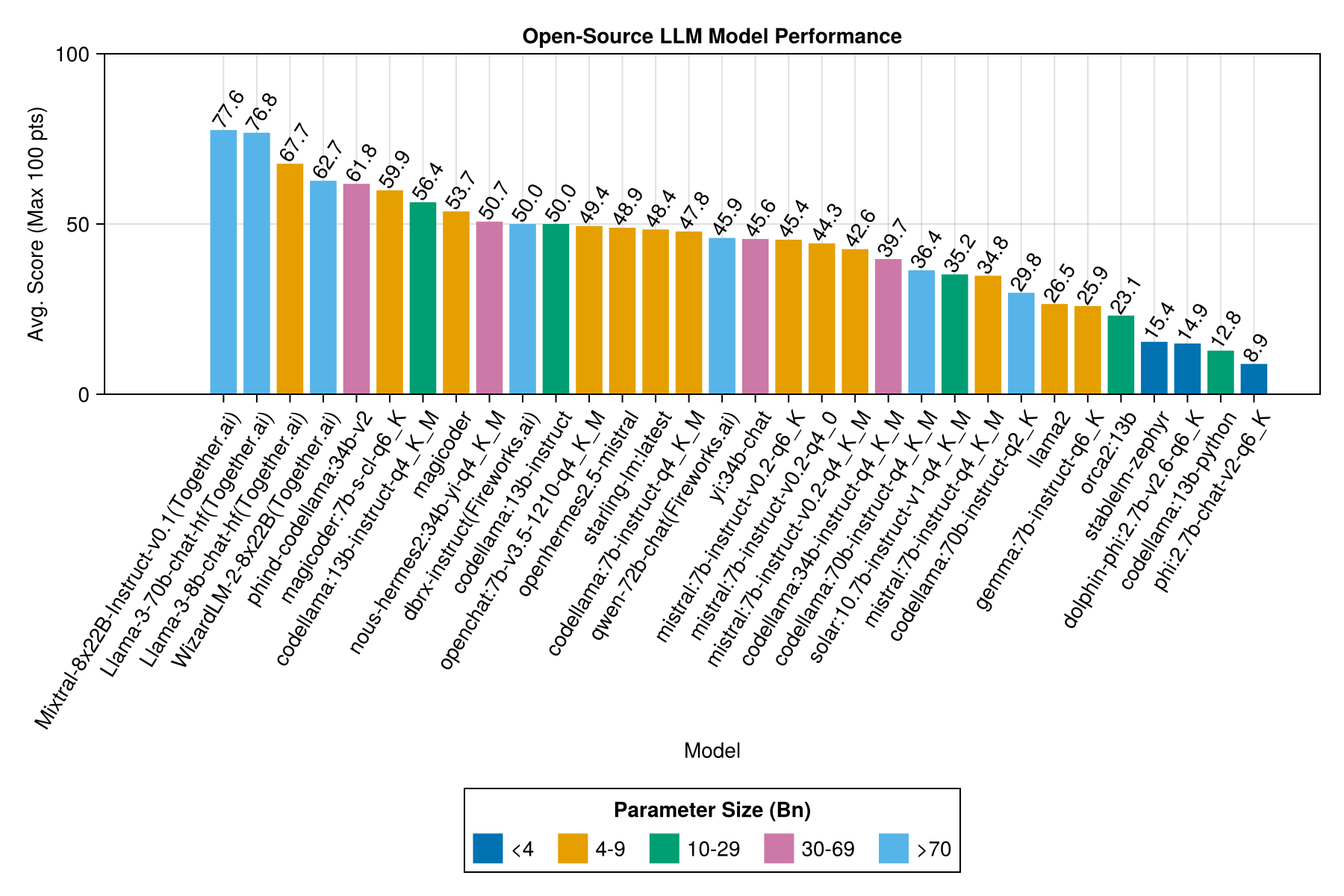
最高のトレードオフパフォーマンスとサイズは、最新のメタラマ38bnです。それ以外の場合、主要なモデルはMixtral-8x22bnです。
| モデル | 経過 | 中央値の経過 | スコア | 中央値のスコア | スコアSTD偏差 | ゼロスコアをカウントします | フルスコアをカウントします |
|---|---|---|---|---|---|---|---|
| mixtral-8x222b-instruct-v0.1(goiting.ai) | 14.1 | 11.0 | 77.6 | 90.0 | 25.8 | 5.0 | 151.0 |
| llama-3-70b-chat-hf(一緒に) | 4.3 | 4.1 | 76.8 | 88.3 | 25.2 | 0.0 | 160.0 |
| llama-3-8b-chat-hf(一緒に) | 1.5 | 1.4 | 67.7 | 66.7 | 26.4 | 5.0 | 70.0 |
| wizardlm-2-8x22b(一緒に) | 34.7 | 31.0 | 62.7 | 60.0 | 33.8 | 33.0 | 118.0 |
| Phind-Codellama:34B-V2 | 37.1 | 36.4 | 61.8 | 62.5 | 33.5 | 36.0 | 58.0 |
| マジックダー:7b-s-cl-q6_k | 15.6 | 15.8 | 59.9 | 60.0 | 29.9 | 18.0 | 35.0 |
| Codellama:13b-instruct-q4_k_m | 3.2 | 3.0 | 56.4 | 54.6 | 33.0 | 56.0 | 61.0 |
| DeepSeek-Coder:33B-Instruct-Q4_K_M | 46.7 | 44.6 | 55.0 | 50.0 | 36.8 | 62.0 | 68.0 |
| マジックダー | 12.8 | 10.7 | 53.7 | 50.0 | 33.2 | 49.0 | 52.0 |
| nous-hermes2:34b-yi-q4_k_m | 56.8 | 52.8 | 50.7 | 50.0 | 34.7 | 78.0 | 56.0 |
| dbrx-instruct(fireworks.ai) | 3.7 | 3.6 | 50.0 | 50.0 | 41.2 | 121.0 | 75.0 |
| Codellama:13b-instruct | 18.1 | 16.7 | 50.0 | 50.0 | 34.4 | 65.0 | 44.0 |
| OpenChat:7B-V3.5-1210-Q4_K_M | 14.4 | 13.7 | 49.4 | 50.0 | 30.3 | 48.0 | 23.0 |
| openhermes2.5 mistral | 12.9 | 12.2 | 48.9 | 50.0 | 31.3 | 55.0 | 27.0 |
| Starling-LM:最新 | 13.7 | 12.5 | 48.4 | 50.0 | 30.2 | 58.0 | 26.0 |
| Codellama:7b-instruct-q4_k_m | 2.1 | 2.0 | 47.8 | 50.0 | 35.3 | 95.0 | 38.0 |
| Qwen-72b-chat(fireworks.ai) | 3.2 | 3.8 | 45.9 | 50.0 | 38.8 | 117.0 | 63.0 |
| yi:34b-chat | 43.9 | 41.3 | 45.6 | 50.0 | 30.5 | 45.0 | 34.0 |
| ミストラル:7B-Instruct-V0.2-Q6_K | 21.7 | 20.9 | 45.4 | 50.0 | 31.3 | 44.0 | 23.0 |
| ミストラル:7B-Instruct-V0.2-Q4_0 | 12.4 | 12.3 | 44.3 | 50.0 | 30.6 | 75.0 | 32.0 |
| ミストラル:7b-instruct-v0.2-q4_k_m | 15.6 | 15.1 | 42.6 | 50.0 | 28.6 | 71.0 | 23.0 |
| Codellama:34b-instruct-q4_k_m | 7.5 | 6.8 | 39.7 | 50.0 | 36.1 | 127.0 | 35.0 |
| Codellama:70b-instruct-q4_k_m | 16.3 | 13.8 | 36.4 | 0.0 | 41.2 | 179.0 | 58.0 |
| ソーラー:10.7B-Instruct-V1-Q4_K_M | 18.8 | 17.7 | 35.2 | 50.0 | 31.1 | 107.0 | 10.0 |
| ミストラル:7b-instruct-q4_k_m | 13.9 | 13.0 | 34.8 | 50.0 | 26.5 | 80.0 | 0.0 |
| Codellama:70B-Instruct-Q2_K | 11.2 | 9.4 | 29.8 | 0.0 | 37.7 | 198.0 | 29.0 |
| llama2 | 17.1 | 16.3 | 26.5 | 25.0 | 26.5 | 131.0 | 0.0 |
| ジェマ:7b-instruct-q6_k | 20.9 | 22.1 | 25.9 | 25.0 | 25.2 | 147.0 | 2.0 |
| orca2:13b | 20.1 | 18.3 | 23.1 | 0.0 | 30.6 | 166.0 | 11.0 |
| Stablelm-Zephyr | 9.9 | 7.7 | 15.4 | 0.0 | 23.5 | 192.0 | 1.0 |
| イルカ-PHI:2.7B-V2.6-Q6_K | 8.9 | 8.4 | 14.9 | 0.0 | 22.9 | 188.0 | 0.0 |
| Codellama:13b-python | 12.5 | 10.7 | 12.8 | 0.0 | 22.1 | 155.0 | 0.0 |
| PHI:2.7b-chat-v2-q6_k | 13.0 | 11.6 | 8.9 | 0.0 | 19.4 | 222.0 | 0.0 |
同じ情報ですが、バーチャートとして:
プロンプトテンプレートごとに別のバーがあります。 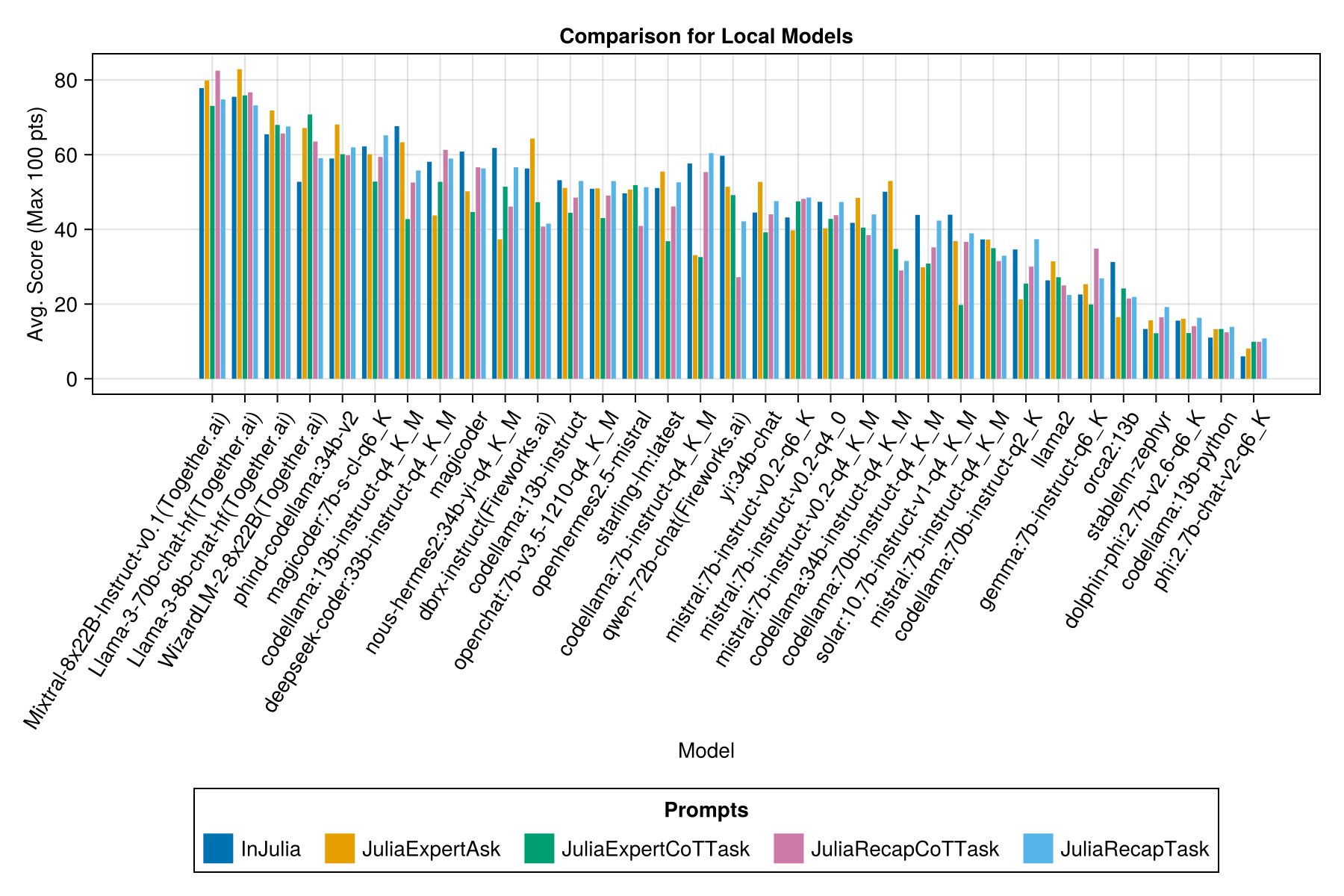
注記
Ollamaリポジトリ(およびHF)の基礎モデルが正しくなく、パフォーマンスが非常に低いため、QWEN-1.5モデルは概要から削除されました。
注記
Ollama/llama.cppでのいくつかの回避は、現在12月23日よりもわずかに高いスコアを獲得していることに気付いたので、上記の回転を再実行するロードマップにあります。
明らかに、有料のAPIが勝ちます(最新リリース:GPT-3.5-Turbo-1066)ですが、それは全体の話ではありません。
促進戦略に関するガイダンスを提供できることを願っています。たとえば、「Juliaexpert*」というプロンプトテンプレートvs vs an "をJulia、Answer Xyz" Promptを使用する方が良い場合があります。
これまでの学習:
| プロンプトテンプレート | 経過(S、平均) | Elapsed(S、中央値) | 平均。スコア(最大100ポイント) | 中央スコア(最大100ポイント) |
|---|---|---|---|---|
| Indulia | 14.0 | 9.6 | 55.2 | 50.0 |
| juliaexpertask | 9.9 | 6.4 | 53.8 | 50.0 |
| Juliarecaptask | 16.7 | 11.5 | 52.0 | 50.0 |
| juliaexpertcottask | 15.4 | 10.4 | 49.5 | 50.0 |
| Juliarecapcottask | 16.1 | 11.3 | 48.6 | 50.0 |
注:XMLベースのテンプレートは、Claude 3モデル(Haiku and Sonnet)に対してのみテストされているため、比較から削除しました。
examples/summarize_results.jlで独自の分析を作成してください!
scripts/code_gen_benchmark.jl確認してください。いくつかの実験を実行して結果を保存したいですか? examples/experiment_hyperparameter_scan.jlをご覧ください!
過去のベンチマークの実行のいくつかを確認したいですか?全体的な統計とexamples/debugging_results.jl examples/summarize_results.jlをご覧ください。
テストケースを提供するには:
code_generation/category/test_case_name/definition.tomlに従ってネストされたフォルダーを作成します。code_generation/category/test case/model/evaluation__PROMPT__STRATEGY__TIMESTAMP.jsonおよびcode_generation/category/test case/model/conversation__PROMPT__STRATEGY__TIMESTAMP.jsondefinition.tomlの解剖学。TOML definition.tomlの必要なフィールド。tomlは以下を含みます。
my_function(1, 2) )を使用した実行可能なステートメントのベクトルとして提供されるテストの例のシナリオ。@test X = Zステートメントのベクトルとして提供されるコードを検証するテスト。いくつかのオプションのフィールドがあります:
上記のフィールドは、例/単位テスト全体でコードの再利用を改善できます。
examples/create_definition.jlの例を参照してください。 validate_definition()を使用して、テストケースの定義を検証できます。
フォルダーjulia_conversations/でJuliaを使用して/in/inについて、関連する、ほぼ正しい会話をprと追加してください。
目標は、小規模なモデルでジュリアの知識を微調整するのに役立つ会話のコレクションを持つことです。
コミュニティの入力を高く評価しています。改善のための提案やアイデアがある場合は、問題を開いてください。すべての貢献は大歓迎です!


