Julia LLM Leaderboard
v0.2.0
Comparação dos recursos de geração de idiomas Julia de vários modelos de linguagem grande
definition.tomlBem -vindo ao Repositório de Benchmark de Geração de Código Julia!
Este projeto foi projetado para a comunidade Julia comparar os recursos de geração de código de vários modelos de IA. Ao contrário dos benchmarks acadêmicos, nosso foco é praticidade e simplicidade: "Gere código, execute-o e veja se funciona (-ish)".
Esse repositório visa entender como diferentes modelos de IA e estratégias de impulsionamento funcionam na geração de código Julia de maneira sintaticamente para orientar os usuários na escolha do melhor modelo para suas necessidades.
Destacados com coceira? Salte para examples/ ou apenas execute sua própria referência com run_benchmark() (por exemplo, examples/code_gen_benchmark.jl ).
Os casos de teste são definidos em um arquivo definition.toml , fornecendo uma estrutura padrão para cada teste. Se você deseja contribuir com um caso de teste, siga as instruções na seção contribuindo com o seu caso de teste.
O desempenho de cada modelo e prompt é avaliado com base em vários critérios:
No momento, todos os critérios são pesados igualmente e cada caso de teste pode ganhar no máximo 100 pontos. Se um código passar por todos os critérios, ele receberá 100/100 pontos. Se falhar um critério (por exemplo, todos os testes de unidade), ele recebe 75/100 pontos. Se falhar em dois critérios (por exemplo, é executado, mas todos os exemplos e testes de unidade estão quebrados), ele recebe 50 pontos e assim por diante.
Para fornecer um vislumbre da funcionalidade do repositório, incluímos resultados de exemplo para os 14 primeiros casos de teste. Abra a documentação para obter os resultados completos e um mergulho profundo em cada caso de teste.
Aviso
Essas pontuações podem mudar à medida que desenvolvemos a funcionalidade de suporte e adicionamos mais modelos.
Lembre -se de que a referência é bastante desafiadora para qualquer modelo - um único espaço ou parênteses extras e a pontuação pode se tornar 0 (= "incapaz de analisar")!
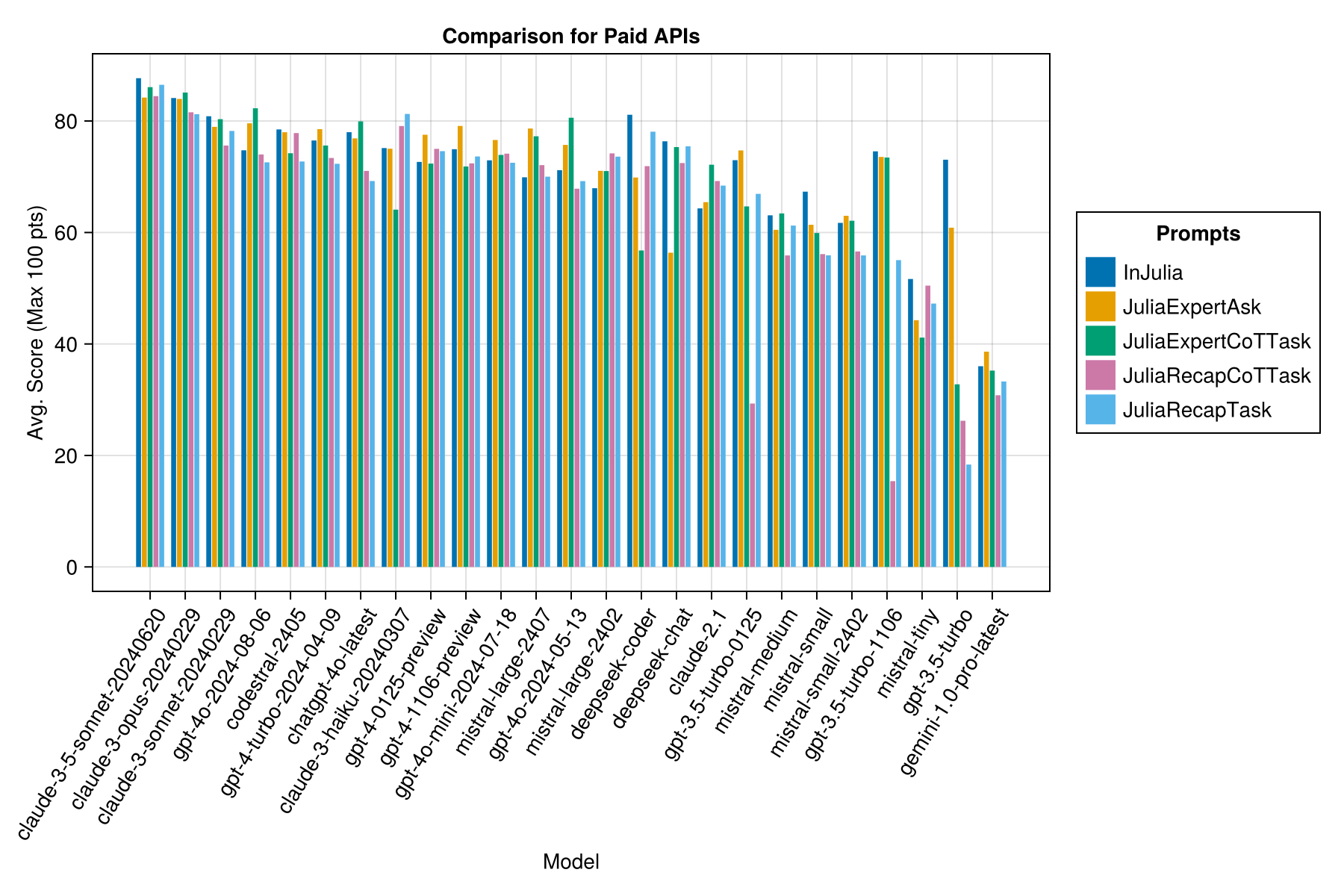
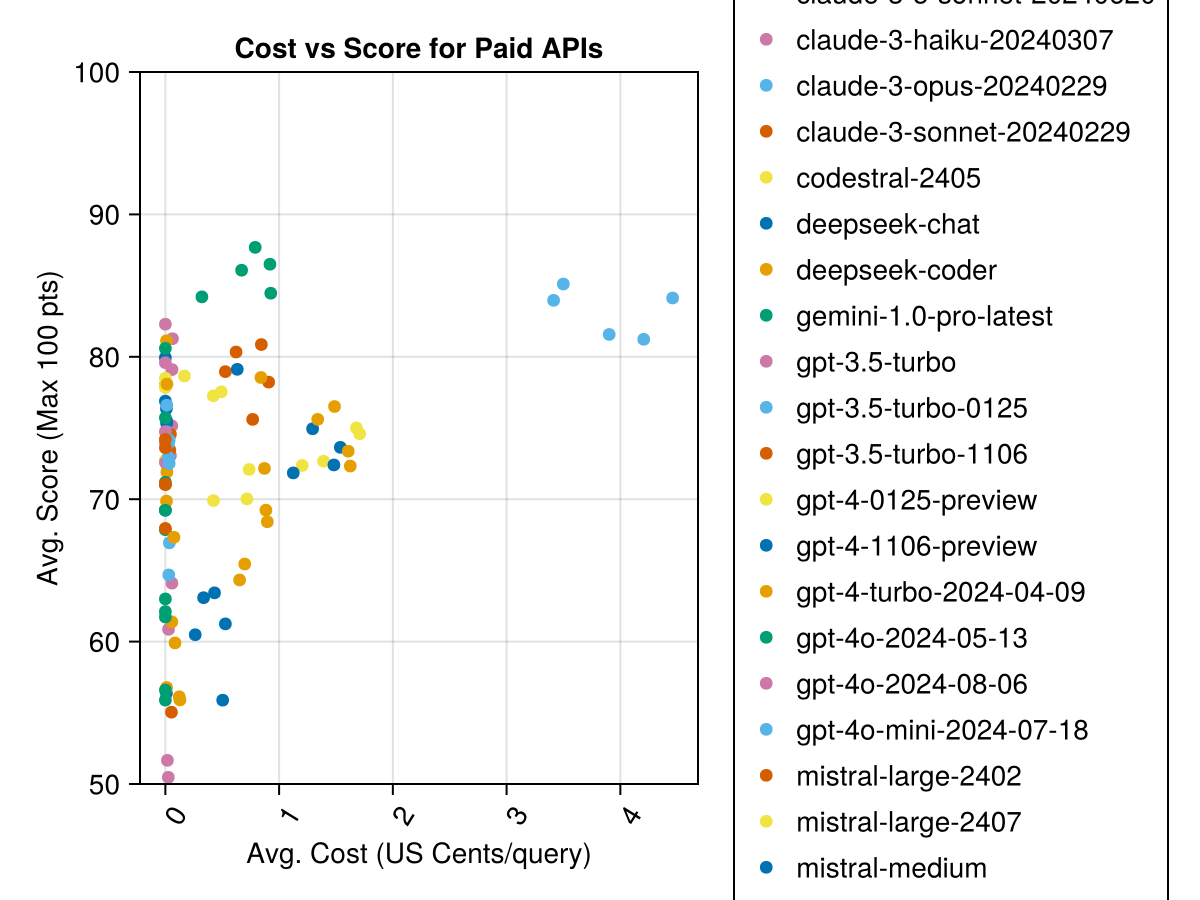
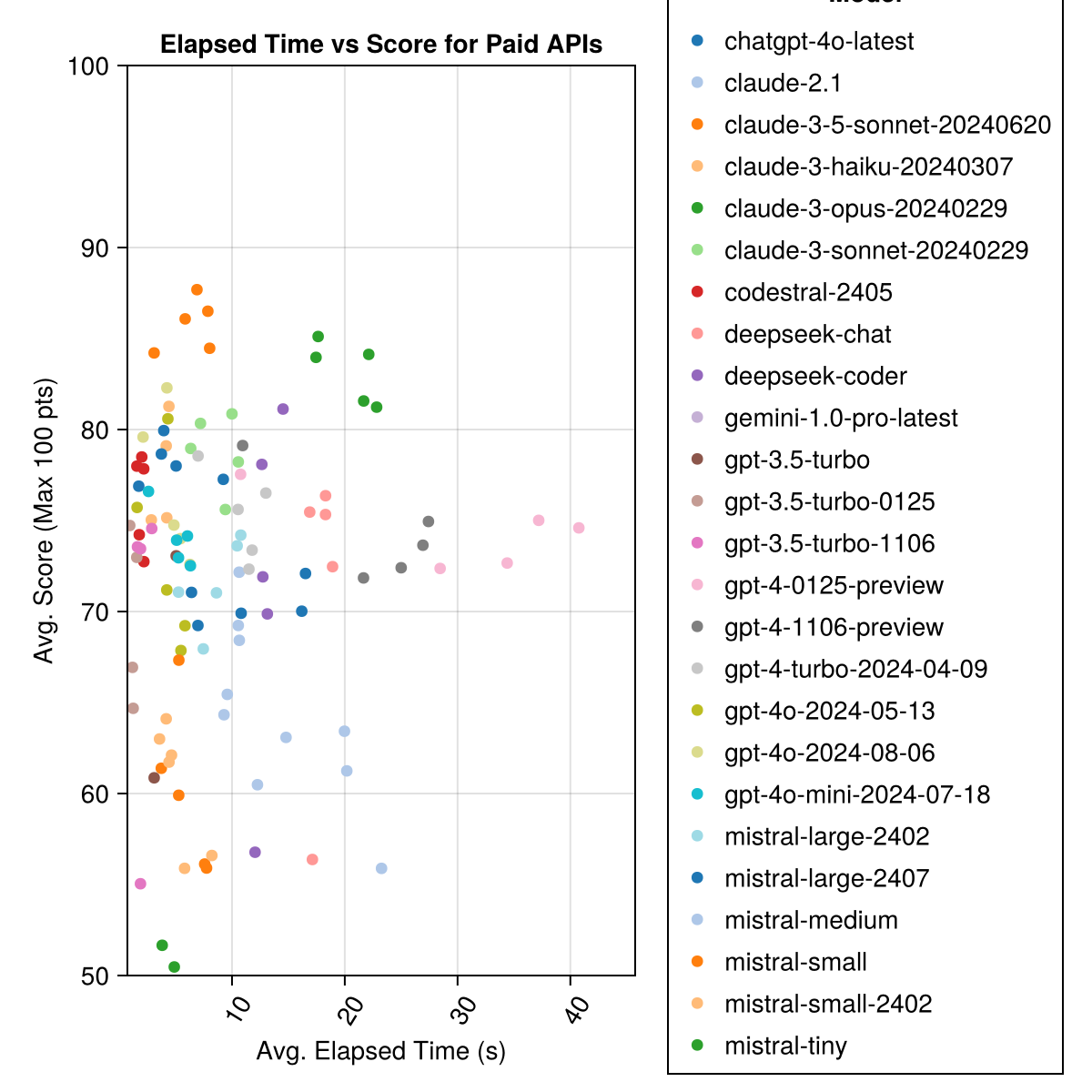
Claude 3,5 soneto é o modelo de maior desempenho. Para o melhor valor para dinheiro, procure codestral Mistral, Claude 3 haiku e, lançado recentemente, GPT 4o Mini (60% mais barato que Gpt3.5 !!!).
| Modelo | Decorrido | Pontuação | Pontuação de desvio padrão | Contagem zero pontuação | Conte a pontuação completa | Centavos de custo |
|---|---|---|---|---|---|---|
| CLAUDE-3-5-SONNET-20240620 | 6.3 | 85.8 | 21.1 | 13 | 355 | 0,73 |
| Claude-3-Opus-20240229 | 20.3 | 83.2 | 19.6 | 2 | 329 | 3.9 |
| CLAUDE-3-SONNET-20240229 | 8.7 | 78.8 | 26.2 | 22 | 308 | 0,73 |
| GPT-4O-2024-08-06 | 4.6 | 76.6 | 27.9 | 26 | 310 | 0,0 |
| Codestral-2405 | 1.9 | 76.3 | 29.3 | 33 | 276 | 0,0 |
| GPT-4-Turbo-2024-04-09 | 10.8 | 75.3 | 29.6 | 38 | 290 | 1.38 |
| Chatgpt-4o-Latest | 4.8 | 75.0 | 27.9 | 25 | 263 | 0,0 |
| Claude-3-Haiku-20240307 | 4.0 | 74.9 | 27.2 | 9 | 261 | 0,05 |
| GPT-4-0125-PREVISÃO | 30.3 | 74.4 | 30.3 | 39 | 284 | 1.29 |
| GPT-4-1106-PREVISÃO | 22.4 | 74.4 | 29.9 | 19 | 142 | 1.21 |
| GPT-4O-MINI-2024-07-18 | 5.1 | 74.0 | 29.4 | 32 | 276 | 0,03 |
| Mistral-Large-2407 | 11.3 | 73.6 | 29.5 | 15 | 137 | 0,49 |
| GPT-4O-2024-05-13 | 4.3 | 72.9 | 29.1 | 29 | 257 | 0,0 |
| Deepseek-Coder | 13.0 | 71.6 | 32.6 | 39 | 115 | 0,01 |
| Mistral-Large-2402 | 8.5 | 71.6 | 27.2 | 13 | 223 | 0,0 |
| Deepseek-Chat | 17.9 | 71.3 | 32.9 | 30 | 140 | 0,01 |
| Claude-2.1 | 10.1 | 67.9 | 30.8 | 47 | 229 | 0,8 |
| GPT-3.5-Turbo-0125 | 1.2 | 61.7 | 36.6 | 125 | 192 | 0,03 |
| Mistral-medium | 18.1 | 60.8 | 33.2 | 22 | 90 | 0,41 |
| Mistral-small | 5.9 | 60.1 | 30.2 | 27 | 76 | 0,09 |
| Mistral-small-2402 | 5.3 | 59.9 | 29.4 | 31 | 169 | 0,0 |
| GPT-3.5-Turbo-1106 | 2.1 | 58.4 | 39.2 | 82 | 97 | 0,04 |
| Mistral Tiny | 4.6 | 46.9 | 32.0 | 75 | 42 | 0,02 |
| GPT-3.5-Turbo | 3.6 | 42.3 | 38.2 | 132 | 54 | 0,04 |
| Gemini-1.0-Pro-Latest | 4.2 | 34.8 | 27.4 | 181 | 25 | 0,0 |
Nota: De meados de fevereiro de 2024, "GPT-3.5-turbo" apontará o último lançamento, "GPT-3.5-Turbo-0125" (depreciando o lançamento em junho).
Mesma informação, mas como um gráfico de barras:
Além disso, podemos considerar o desempenho (pontuação) versus o custo (medido em centavos dos EUA):
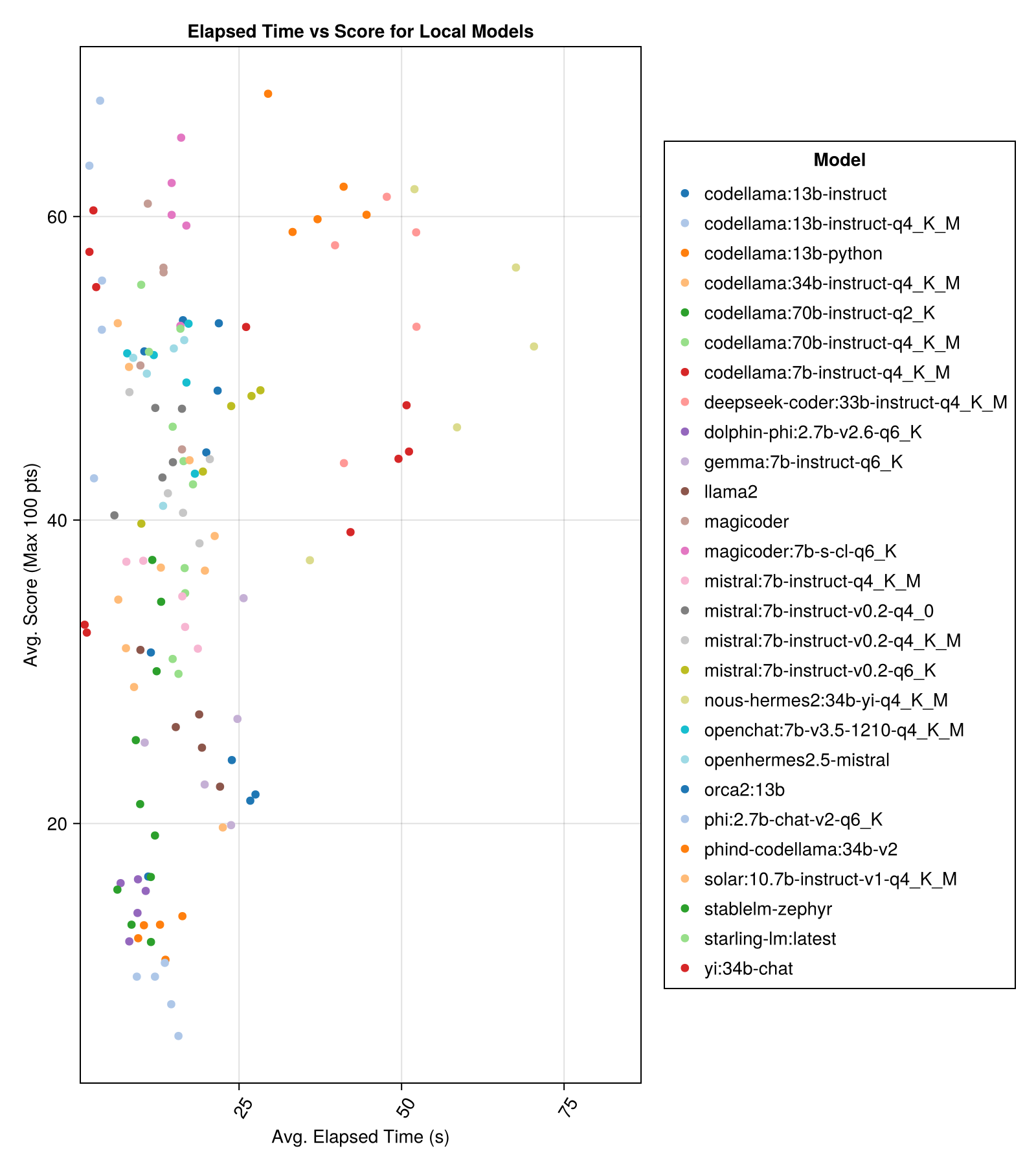
Os modelos hospedados localmente geralmente não são tão bons quanto as APIs mais bem pagas, mas estão chegando perto! Observe que o "Mistral-Small" já está disponível para ser executado localmente e haverá muitos futuros Finetunes!
Observação
Muito obrigado a 01.Ai e Jun Tian, em particular, por fornecer a computação para várias partes deste benchmark!
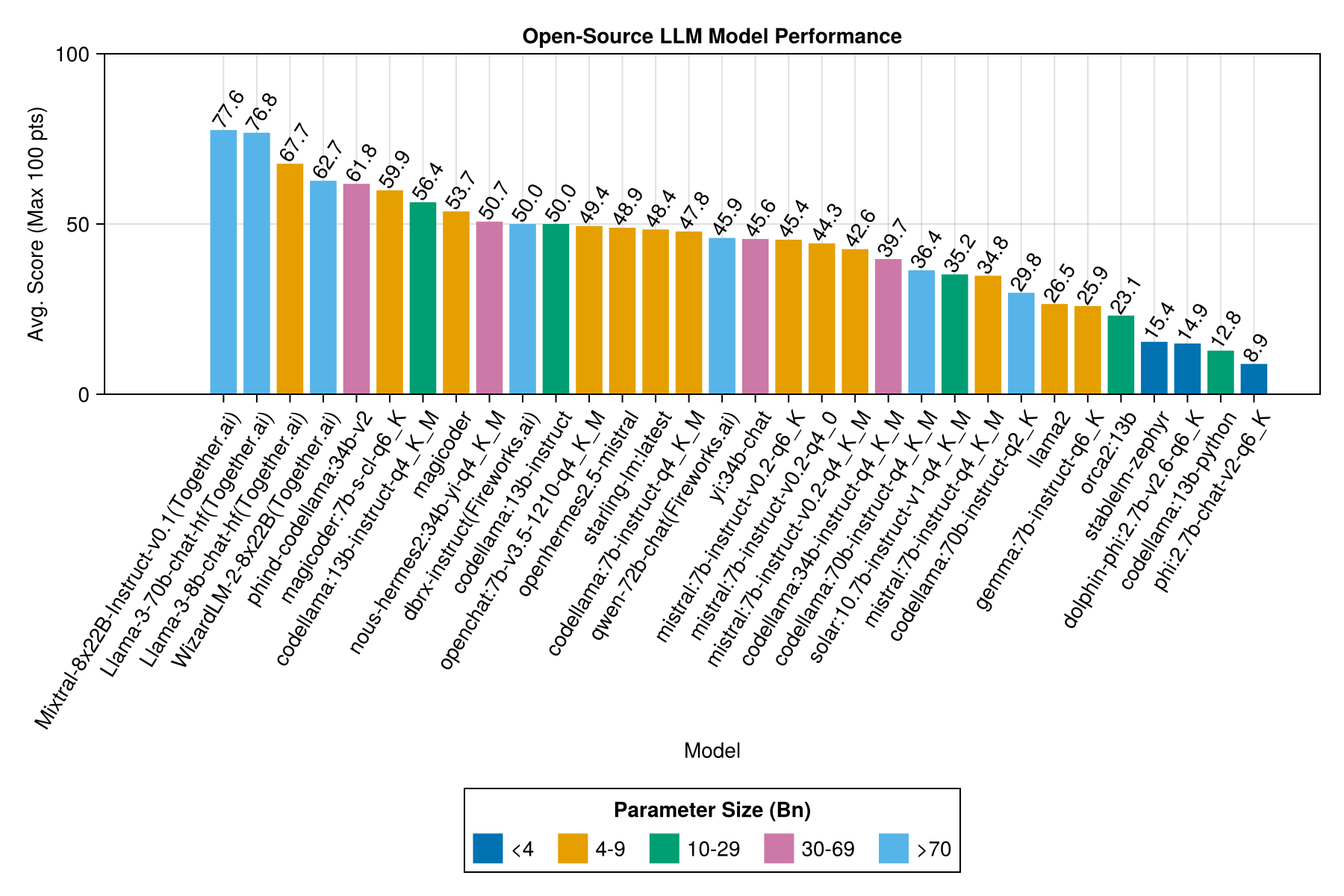
O melhor desempenho de trade-off vs tamanho é o mais recente meta llama3 8bn. Caso contrário, o modelo principal é o Mixtral-8x22bn.
| Modelo | Decorrido | Mediana decorrida | Pontuação | Pontuação mediana | Pontuação de desvio padrão | Contagem zero pontuação | Conte a pontuação completa |
|---|---|---|---|---|---|---|---|
| Mixtral-8x22b-Instruct-v0.1 (juntos.ai) | 14.1 | 11.0 | 77.6 | 90.0 | 25.8 | 5.0 | 151.0 |
| Llama-3-70b-chat-hf (juntos.ai) | 4.3 | 4.1 | 76.8 | 88.3 | 25.2 | 0,0 | 160.0 |
| Llama-3-8b-chat-hf (juntos.ai) | 1.5 | 1.4 | 67.7 | 66.7 | 26.4 | 5.0 | 70.0 |
| Wizardlm-2-8x22b (juntos.ai) | 34.7 | 31.0 | 62.7 | 60.0 | 33.8 | 33.0 | 118.0 |
| Phind-Codellama: 34B-V2 | 37.1 | 36.4 | 61.8 | 62.5 | 33.5 | 36.0 | 58.0 |
| Magicoder: 7B-S-CL-Q6_K | 15.6 | 15.8 | 59.9 | 60.0 | 29.9 | 18.0 | 35.0 |
| Codellama: 13B-Instruct-Q4_K_M | 3.2 | 3.0 | 56.4 | 54.6 | 33.0 | 56.0 | 61.0 |
| Deepseek-Coder: 33B-Instruct-Q4_K_M | 46.7 | 44.6 | 55.0 | 50.0 | 36.8 | 62.0 | 68.0 |
| Magicoder | 12.8 | 10.7 | 53.7 | 50.0 | 33.2 | 49.0 | 52.0 |
| nous-hermes2: 34b-yi-Q4_K_M | 56.8 | 52.8 | 50.7 | 50.0 | 34.7 | 78.0 | 56.0 |
| DBRX-Instruct (fogos de artifício) | 3.7 | 3.6 | 50.0 | 50.0 | 41.2 | 121.0 | 75.0 |
| Codellama: 13b-instrução | 18.1 | 16.7 | 50.0 | 50.0 | 34.4 | 65.0 | 44.0 |
| OpenChat: 7B-V3.5-1210-Q4_K_M | 14.4 | 13.7 | 49.4 | 50.0 | 30.3 | 48.0 | 23.0 |
| OpenHermes2.5-Mistral | 12.9 | 12.2 | 48.9 | 50.0 | 31.3 | 55.0 | 27.0 |
| Starling-LM: mais recente | 13.7 | 12.5 | 48.4 | 50.0 | 30.2 | 58.0 | 26.0 |
| Codellama: 7B-Instruct-Q4_K_M | 2.1 | 2.0 | 47.8 | 50.0 | 35.3 | 95.0 | 38.0 |
| Qwen-72b-chat (fogos de artifício) | 3.2 | 3.8 | 45.9 | 50.0 | 38.8 | 117.0 | 63.0 |
| Yi: 34b-chat | 43.9 | 41.3 | 45.6 | 50.0 | 30.5 | 45.0 | 34.0 |
| Mistral: 7B-Instruct-V0.2-Q6_K | 21.7 | 20.9 | 45.4 | 50.0 | 31.3 | 44.0 | 23.0 |
| Mistral: 7B-Instruct-V0.2-Q4_0 | 12.4 | 12.3 | 44.3 | 50.0 | 30.6 | 75.0 | 32.0 |
| Mistral: 7B-Instruct-V0.2-Q4_K_M | 15.6 | 15.1 | 42.6 | 50.0 | 28.6 | 71.0 | 23.0 |
| Codellama: 34B-Instruct-Q4_K_M | 7.5 | 6.8 | 39.7 | 50.0 | 36.1 | 127.0 | 35.0 |
| Codellama: 70B-Instruct-Q4_K_M | 16.3 | 13.8 | 36.4 | 0,0 | 41.2 | 179.0 | 58.0 |
| Solar: 10.7b-Instruct-V1-Q4_K_M | 18.8 | 17.7 | 35.2 | 50.0 | 31.1 | 107.0 | 10.0 |
| Mistral: 7B-Instruct-Q4_K_M | 13.9 | 13.0 | 34.8 | 50.0 | 26.5 | 80.0 | 0,0 |
| Codellama: 70B-Instruct-Q2_K | 11.2 | 9.4 | 29.8 | 0,0 | 37.7 | 198.0 | 29.0 |
| llama2 | 17.1 | 16.3 | 26.5 | 25.0 | 26.5 | 131.0 | 0,0 |
| Gemma: 7B-Instruct-Q6_K | 20.9 | 22.1 | 25.9 | 25.0 | 25.2 | 147.0 | 2.0 |
| Orca2: 13b | 20.1 | 18.3 | 23.1 | 0,0 | 30.6 | 166.0 | 11.0 |
| Stablelm-Zephyr | 9.9 | 7.7 | 15.4 | 0,0 | 23.5 | 192.0 | 1.0 |
| golfinho-phi: 2.7b-v2.6-q6_k | 8.9 | 8.4 | 14.9 | 0,0 | 22.9 | 188.0 | 0,0 |
| Codellama: 13b-python | 12.5 | 10.7 | 12.8 | 0,0 | 22.1 | 155.0 | 0,0 |
| Phi: 2,7b-chat-v2-q6_k | 13.0 | 11.6 | 8.9 | 0,0 | 19.4 | 222.0 | 0,0 |
Mesma informação, mas como um gráfico de barras:
E com uma barra separada para cada modelo de prompt: 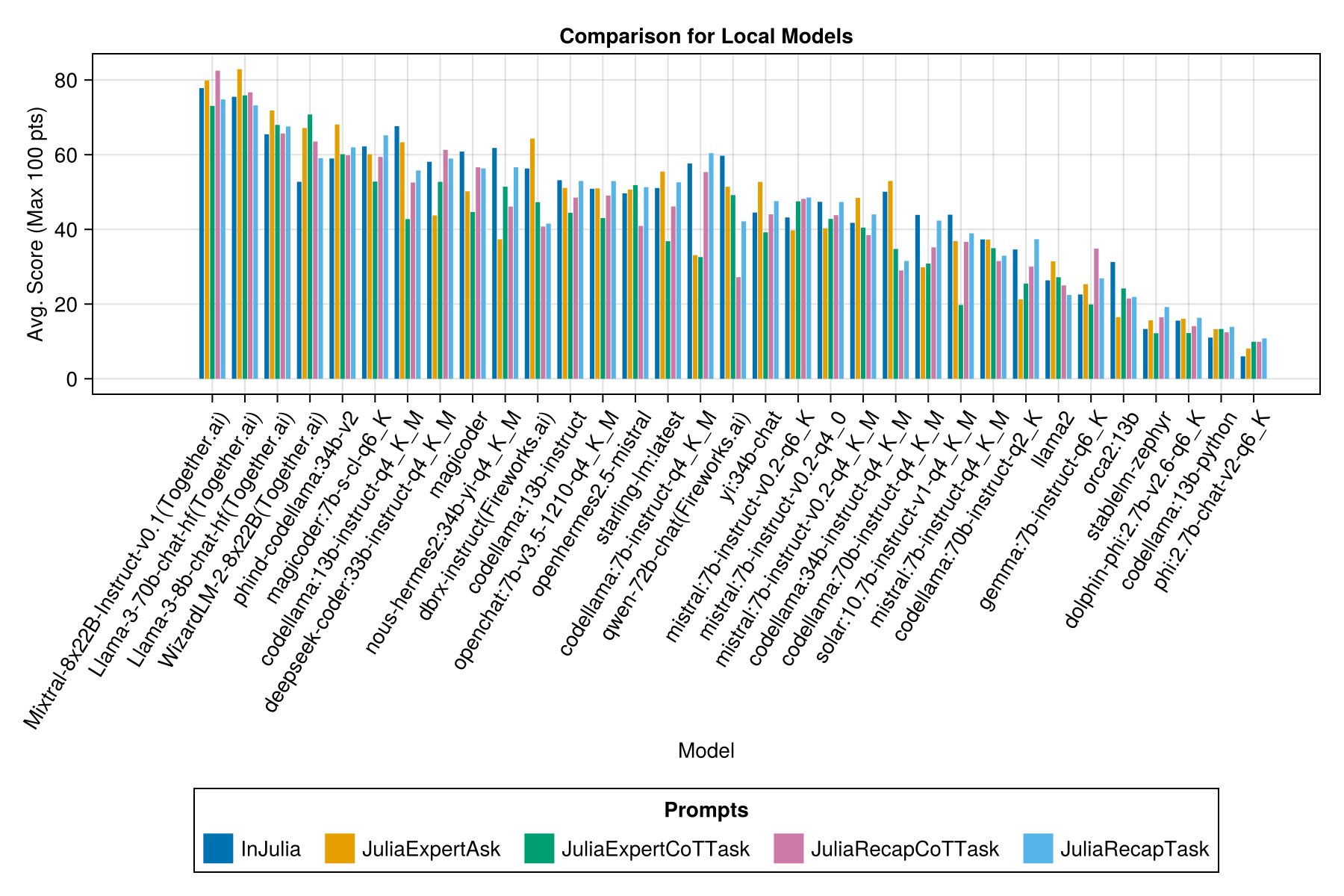
Observação
Os modelos QWEN-1.5 foram removidos da visão geral como o modelo subjacente no repositório Ollama (e HF) não está correto e tem desempenho muito baixo.
Observação
Percebi que alguns eves no ollama/llama.cpp agora pontuam um pouco mais altos agora do que em dezembro de 23, por isso está em um roteiro para re-executar os Evals acima.
Claramente, a vitória paga do APIs (o último lançamento: GPT-3.5-Turbo-1106), mas essa não é a história toda.
Esperamos poder fornecer algumas orientações sobre estratégias de solicitação, por exemplo, quando é melhor usar um modelo de prompt "JuliaExpert*" vs e "em Julia, Responder XYZ Prompt.
Aprendizados até agora:
| Modelo rápido | Decorrido (s, média) | Decorrido (S, mediana) | Avg. Pontuação (máximo 100 pts) | Pontuação mediana (máximo de 100 pts) |
|---|---|---|---|---|
| Injússico | 14.0 | 9.6 | 55.2 | 50.0 |
| JuliaExperTask | 9.9 | 6.4 | 53.8 | 50.0 |
| Juliarecaptask | 16.7 | 11.5 | 52.0 | 50.0 |
| JuliaExpertcottask | 15.4 | 10.4 | 49.5 | 50.0 |
| JuliarecapCottask | 16.1 | 11.3 | 48.6 | 50.0 |
Nota: Os modelos baseados em XML são testados apenas para os modelos Claude 3 (Haiku e Sonnet), é por isso que os removemos da comparação.
Faça sua própria análise com examples/summarize_results.jl !
scripts/code_gen_benchmark.jl para o exemplo de avaliações anteriores. Deseja executar algumas experiências e salvar os resultados? Confira examples/experiment_hyperparameter_scan.jl !
Deseja revisar algumas das corridas anteriores de referência? Confira examples/summarize_results.jl para obter estatísticas e examples/debugging_results.jl para revisar as respostas individuais de conversas/modelos.
Para contribuir com um caso de teste:
code_generation/category/test_case_name/definition.toml .code_generation/category/test case/model/evaluation__PROMPT__STRATEGY__TIMESTAMP.json e code_generation/category/test case/model/conversation__PROMPT__STRATEGY__TIMESTAMP.jsondefinition.toml Campos necessários em definition.toml Inclua:
my_function(1, 2) ).@test X = Z .Existem vários campos opcionais:
Os campos acima podem melhorar a reutilização do código nos exemplos/testes de unidade.
Veja um exemplo em examples/create_definition.jl . Você pode validar suas definições de caso de teste com validate_definition() .
PR e adicione quaisquer conversas relevantes e principalmente corretas com/in/sobre Julia na pasta julia_conversations/ .
O objetivo é ter uma coleção de conversas úteis para o Finetuning Julia Knowledge em modelos menores.
Valorizamos muito a entrada da comunidade. Se você tiver sugestões ou idéias de melhoria, abra um problema. Todas as contribuições são bem -vindas!


