Julia LLM Leaderboard
v0.2.0
Comparaison des capacités de génération de langue Julia de divers modèles de grande langue
definition.tomlBienvenue dans le référentiel de référence de génération de code Julia!
Ce projet est conçu pour la communauté de Julia afin de comparer les capacités de génération de code de divers modèles d'IA. Contrairement aux références académiques, notre objectif est l'aspect pratique et la simplicité: "Générez du code, exécutez-le et voyez si cela fonctionne (-ish)."
Ce référentiel vise à comprendre comment les différents modèles d'IA et les stratégies d'incitation fonctionnent pour générer un code Julia syntaxiquement correct pour guider les utilisateurs dans le choix du meilleur modèle pour leurs besoins.
Les doigts démangeaisons? Sautez aux examples/ ou exécutez simplement votre propre benchmark avec run_benchmark() (par exemple, examples/code_gen_benchmark.jl ).
Les cas de test sont définis dans un fichier definition.toml , fournissant une structure standard pour chaque test. Si vous souhaitez contribuer un cas de test, veuillez suivre les instructions dans la section Contribution de votre cas de test.
Les performances de chaque modèle et de l'invite sont évaluées en fonction de plusieurs critères:
À l'heure actuelle, tous les critères sont pesés de manière égale et chaque cas de test peut gagner un maximum de 100 points. Si un code passe tous les critères, il obtient 100/100 points. S'il échoue un critère (par exemple, tous les tests unitaires), il obtient 75/100 points. S'il échoue deux critères (par exemple, il fonctionne mais tous les exemples et tests unitaires sont cassés), il obtient 50 points, etc.
Pour donner un aperçu de la fonctionnalité du référentiel, nous avons inclus des exemples de résultats pour les 14 premiers cas de test. Ouvrez la documentation pour les résultats complets et une plongée profonde sur chaque cas de test.
Avertissement
Ces scores peuvent changer à mesure que nous évoluons les fonctionnalités de support et ajoutent plus de modèles.
N'oubliez pas que la référence est assez difficile pour tout modèle - un seul espace ou parenthèses supplémentaires et la partition pourrait devenir 0 (= "Impossible d'analyser")!
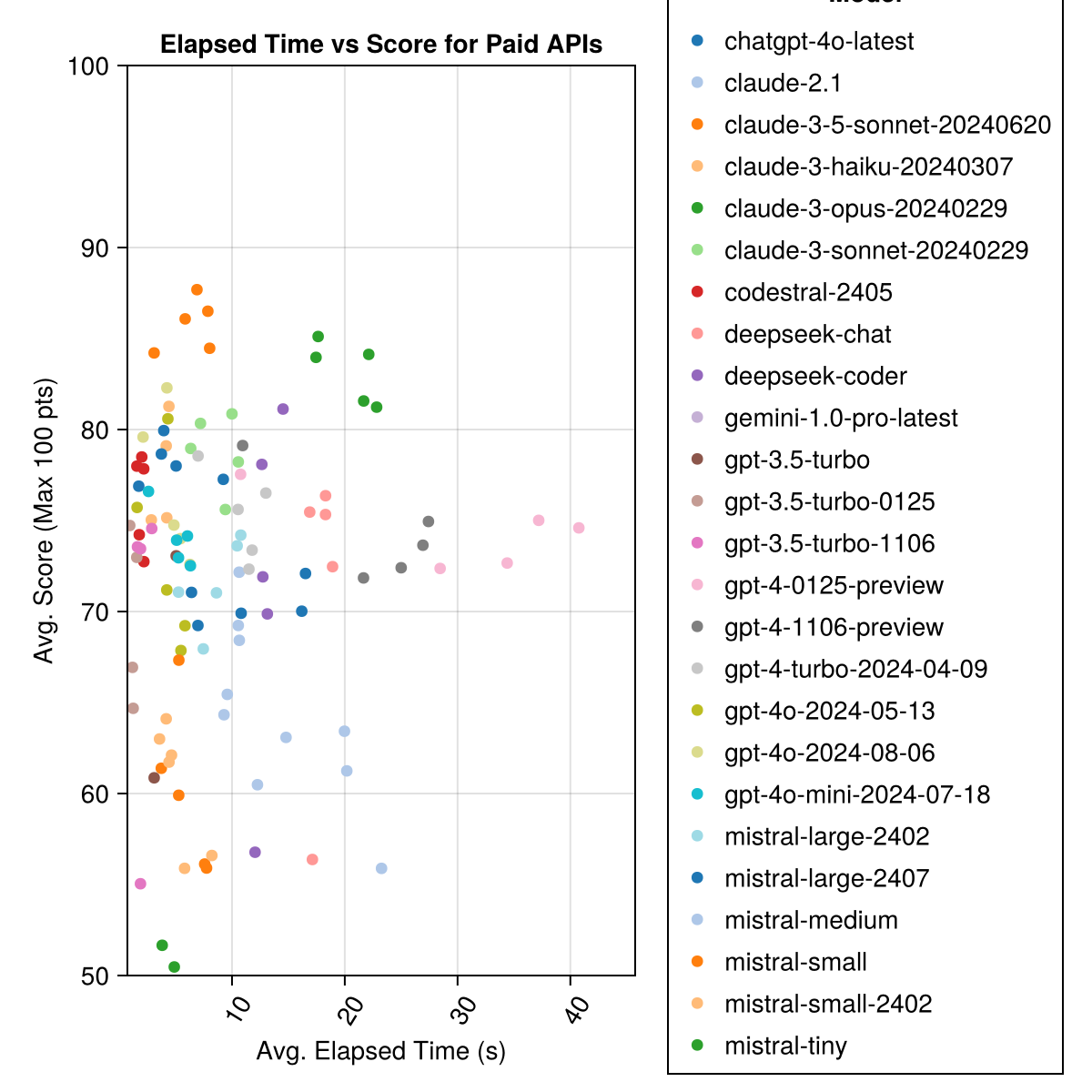
Claude 3.5 Sonnet est le modèle le plus performant. Pour la meilleure valeur pour mon argent, regardez le codestral Mistral, Claude 3 Haiku et, récemment publié, GPT 4O Mini (60% moins cher que GPT3.5 !!!).
| Modèle | Écoulé | Score | Score de l'écart MST | Count Zero Score | Compter le score complet | Cents de coûts |
|---|---|---|---|---|---|---|
| Claude-3-5-Sonnet-20240620 | 6.3 | 85.8 | 21.1 | 13 | 355 | 0,73 |
| Claude-3-Opus-20240229 | 20.3 | 83.2 | 19.6 | 2 | 329 | 3.9 |
| Claude-3-Sonnet-20240229 | 8.7 | 78.8 | 26.2 | 22 | 308 | 0,73 |
| GPT-4O-2024-08-06 | 4.6 | 76.6 | 27.9 | 26 | 310 | 0.0 |
| codestral-2405 | 1.9 | 76.3 | 29.3 | 33 | 276 | 0.0 |
| GPT-4-Turbo-2024-04-09 | 10.8 | 75.3 | 29.6 | 38 | 290 | 1.38 |
| chatppt-4o-latest | 4.8 | 75.0 | 27.9 | 25 | 263 | 0.0 |
| Claude-3-Haiku-20240307 | 4.0 | 74.9 | 27.2 | 9 | 261 | 0,05 |
| GPT-4-0125-Preview | 30.3 | 74.4 | 30.3 | 39 | 284 | 1.29 |
| GPT-4-1106-Preview | 22.4 | 74.4 | 29.9 | 19 | 142 | 1.21 |
| GPT-4O-MINI-2024-07-18 | 5.1 | 74.0 | 29.4 | 32 | 276 | 0,03 |
| Mistral-Garn-2407 | 11.3 | 73.6 | 29.5 | 15 | 137 | 0,49 |
| GPT-4O-2024-05-13 | 4.3 | 72.9 | 29.1 | 29 | 257 | 0.0 |
| coder en profondeur | 13.0 | 71.6 | 32.6 | 39 | 115 | 0,01 |
| Mistral-Garn-2402 | 8.5 | 71.6 | 27.2 | 13 | 223 | 0.0 |
| chat de profondeur | 17.9 | 71.3 | 32.9 | 30 | 140 | 0,01 |
| Claude-2.1 | 10.1 | 67.9 | 30.8 | 47 | 229 | 0.8 |
| GPT-3.5-turbo-0125 | 1.2 | 61.7 | 36.6 | 125 | 192 | 0,03 |
| mistral-médium | 18.1 | 60.8 | 33.2 | 22 | 90 | 0,41 |
| méconnaître | 5.9 | 60.1 | 30.2 | 27 | 76 | 0,09 |
| Mistral-Small-2402 | 5.3 | 59.9 | 29.4 | 31 | 169 | 0.0 |
| GPT-3.5-turbo-1106 | 2.1 | 58.4 | 39.2 | 82 | 97 | 0,04 |
| Mistral-Tiny | 4.6 | 46.9 | 32.0 | 75 | 42 | 0,02 |
| GPT-3,5-turbo | 3.6 | 42.3 | 38.2 | 132 | 54 | 0,04 |
| gemini-1.0-pro-latest | 4.2 | 34.8 | 27.4 | 181 | 25 | 0.0 |
Remarque: À partir de la mi-février 2024, "GPT-3.5-turbo" indiquera la dernière version, "GPT-3.5-Turbo-0125" (dépréciation de la version de juin).
Même information, mais en tant que graphique à barres:
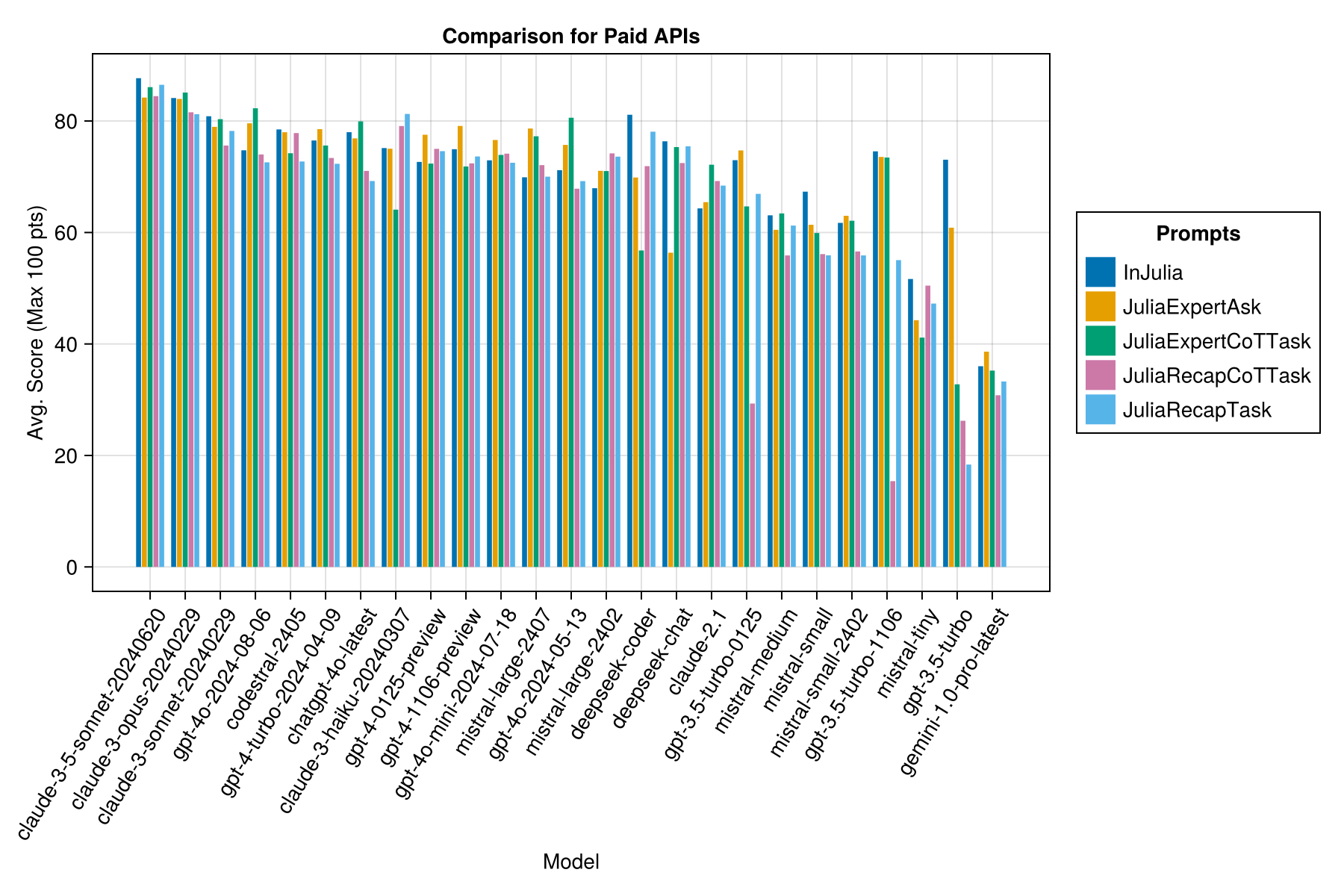
De plus, nous pouvons considérer les performances (score) par rapport au coût (mesuré en cents américains):
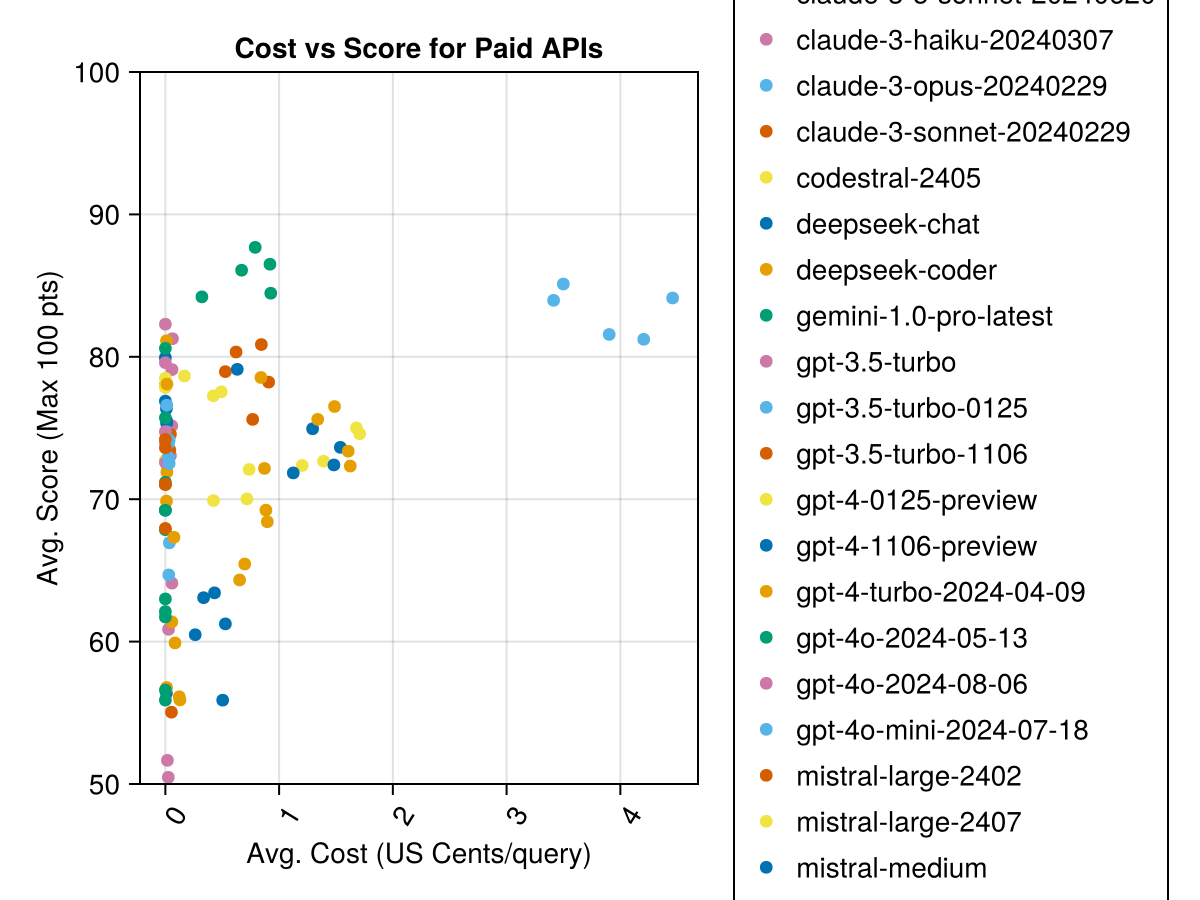
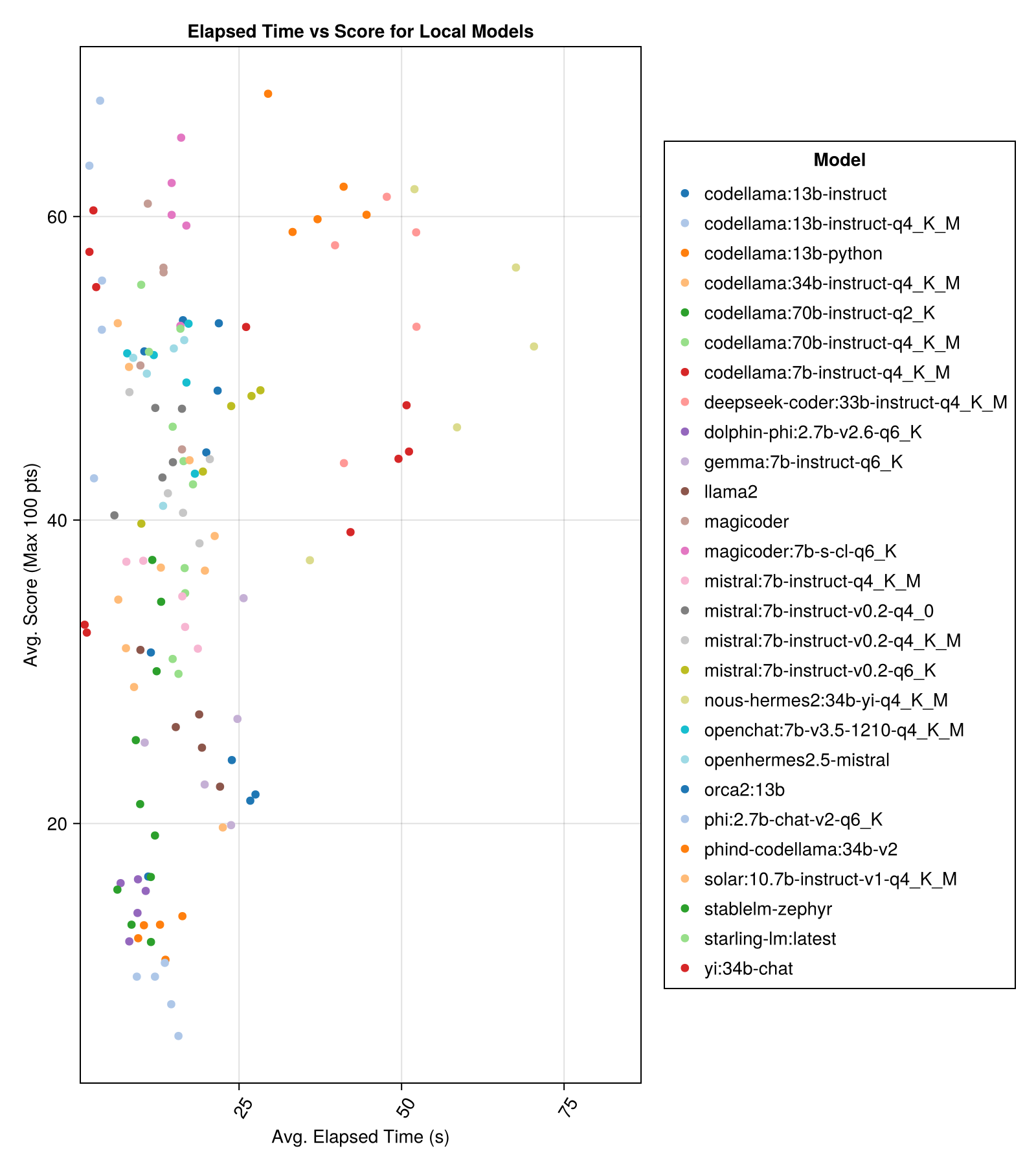
Les modèles hébergés localement ne sont généralement pas aussi bons que les API les mieux payés, mais ils se rapprochent! Notez que le "Mistral-Small" est déjà disponible pour être exécuté localement et qu'il y aura de nombreux futurs finetunes!
Note
Grand merci à 01.ai et Jun Tian en particulier d'avoir fourni le calcul pour plusieurs parties de cette référence!
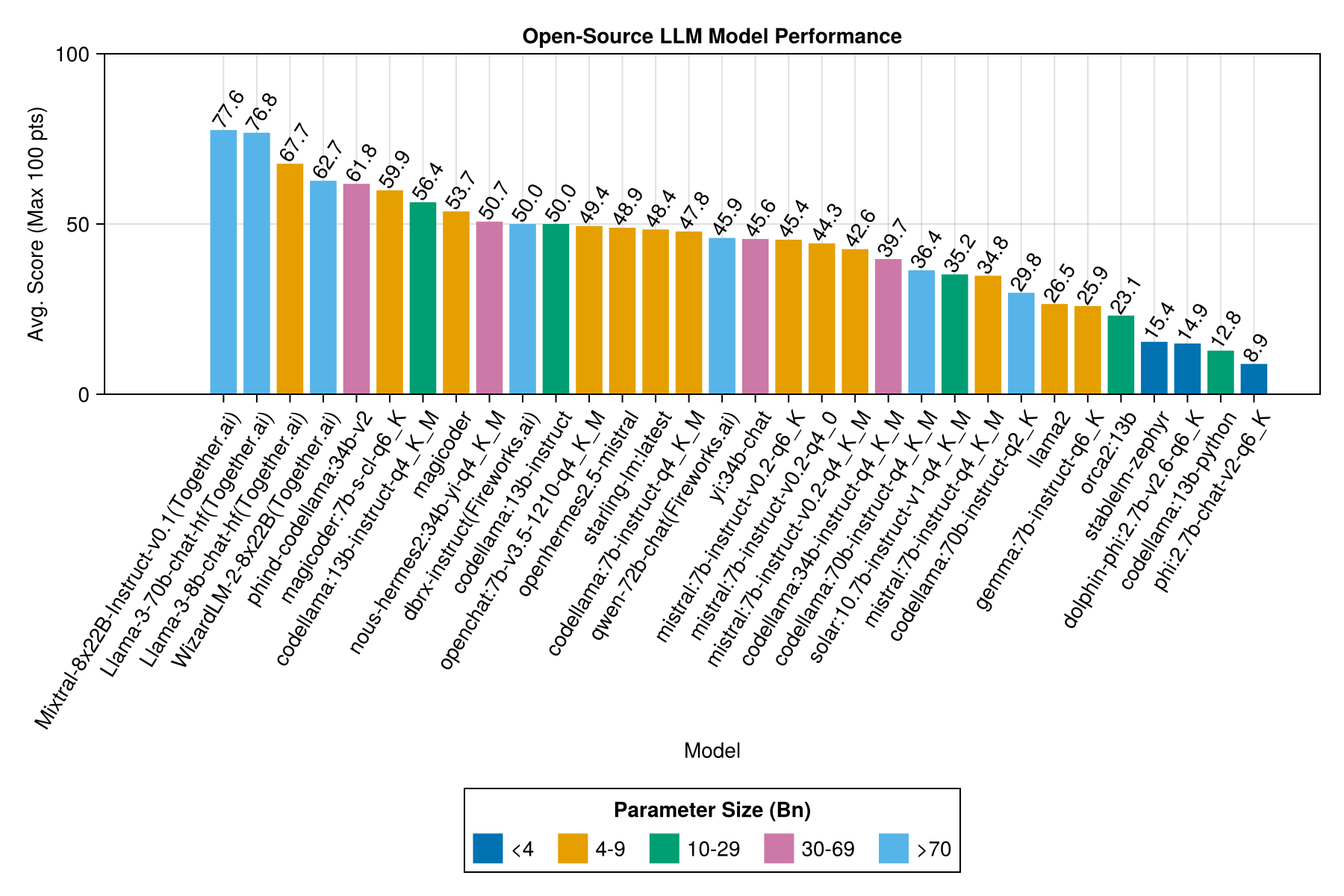
La meilleure performance de compromis vs taille est la dernière Meta Llama3 8BN. Sinon, le modèle principal est Mixtral-8x22BN.
| Modèle | Écoulé | Médian écoulé | Score | SCORE MÉDICE | Score de l'écart MST | Count Zero Score | Compter le score complet |
|---|---|---|---|---|---|---|---|
| Mixtral-8x22b-instruct-v0.1 (ensemble.ai) | 14.1 | 11.0 | 77.6 | 90.0 | 25.8 | 5.0 | 151.0 |
| Llama-3-70b-chat-hf (ensemble.ai) | 4.3 | 4.1 | 76.8 | 88.3 | 25.2 | 0.0 | 160.0 |
| Llama-3-8b-chat-hf (ensemble.ai) | 1.5 | 1.4 | 67.7 | 66.7 | 26.4 | 5.0 | 70.0 |
| Wizardlm-2-8x22b (ensemble.ai) | 34.7 | 31.0 | 62.7 | 60.0 | 33.8 | 33.0 | 118.0 |
| PHIND-CODELLAMA: 34B-V2 | 37.1 | 36.4 | 61.8 | 62.5 | 33.5 | 36.0 | 58.0 |
| MagicOder: 7b-s-CL-Q6_K | 15.6 | 15.8 | 59.9 | 60.0 | 29.9 | 18.0 | 35.0 |
| Codellama: 13B-Instruct-Q4_K_M | 3.2 | 3.0 | 56.4 | 54.6 | 33.0 | 56.0 | 61.0 |
| CODER DEEPSEEK: 33B-INSTRUCT-Q4_K_M | 46.7 | 44.6 | 55.0 | 50.0 | 36.8 | 62.0 | 68.0 |
| magicoder | 12.8 | 10.7 | 53.7 | 50.0 | 33.2 | 49.0 | 52.0 |
| nous-Hermes2: 34b-yi-q4_k_m | 56.8 | 52.8 | 50.7 | 50.0 | 34.7 | 78.0 | 56.0 |
| Dbrx-Istruct (Fireworks.ai) | 3.7 | 3.6 | 50.0 | 50.0 | 41.2 | 121.0 | 75.0 |
| Codellama: 13B-Istruct | 18.1 | 16.7 | 50.0 | 50.0 | 34.4 | 65.0 | 44.0 |
| OpenChat: 7B-V3.5-1210-Q4_K_M | 14.4 | 13.7 | 49.4 | 50.0 | 30.3 | 48.0 | 23.0 |
| OpenHermes2.5-missure | 12.9 | 12.2 | 48.9 | 50.0 | 31.3 | 55.0 | 27.0 |
| Starling-LM: Dernière | 13.7 | 12.5 | 48.4 | 50.0 | 30.2 | 58.0 | 26.0 |
| Codellama: 7B-Instruct-Q4_K_M | 2.1 | 2.0 | 47.8 | 50.0 | 35.3 | 95.0 | 38.0 |
| Qwen-72b-chat (Fireworks.ai) | 3.2 | 3.8 | 45.9 | 50.0 | 38.8 | 117.0 | 63.0 |
| Yi: 34B | 43.9 | 41.3 | 45.6 | 50.0 | 30.5 | 45.0 | 34.0 |
| Mistral: 7B-Instruct-V0.2-Q6_K | 21.7 | 20.9 | 45.4 | 50.0 | 31.3 | 44.0 | 23.0 |
| Mistral: 7B-Instruct-V0.2-Q4_0 | 12.4 | 12.3 | 44.3 | 50.0 | 30.6 | 75.0 | 32.0 |
| Mistral: 7B-Instruct-V0.2-Q4_K_M | 15.6 | 15.1 | 42.6 | 50.0 | 28.6 | 71.0 | 23.0 |
| Codellama: 34B-Instruct-Q4_K_M | 7.5 | 6.8 | 39.7 | 50.0 | 36.1 | 127.0 | 35.0 |
| Codellama: 70B-Instruct-Q4_K_M | 16.3 | 13.8 | 36.4 | 0.0 | 41.2 | 179.0 | 58.0 |
| solaire: 10.7b-instruct-v1-q4_k_m | 18.8 | 17.7 | 35.2 | 50.0 | 31.1 | 107.0 | 10.0 |
| Mistral: 7B-Instruct-Q4_K_M | 13.9 | 13.0 | 34.8 | 50.0 | 26.5 | 80.0 | 0.0 |
| Codellama: 70B-Instruct-Q2_K | 11.2 | 9.4 | 29.8 | 0.0 | 37.7 | 198.0 | 29.0 |
| lama2 | 17.1 | 16.3 | 26.5 | 25.0 | 26.5 | 131.0 | 0.0 |
| GEMMA: 7B-INSTRUCT-Q6_K | 20.9 | 22.1 | 25.9 | 25.0 | 25.2 | 147.0 | 2.0 |
| ORCA2: 13B | 20.1 | 18.3 | 23.1 | 0.0 | 30.6 | 166.0 | 11.0 |
| stablel-zéphyre | 9.9 | 7.7 | 15.4 | 0.0 | 23.5 | 192.0 | 1.0 |
| Dolphin-Phi: 2.7b-V2.6-Q6_K | 8.9 | 8.4 | 14.9 | 0.0 | 22.9 | 188.0 | 0.0 |
| Codellama: 13b-python | 12.5 | 10.7 | 12.8 | 0.0 | 22.1 | 155.0 | 0.0 |
| PHI: 2.7b-chat-v2-Q6_K | 13.0 | 11.6 | 8.9 | 0.0 | 19.4 | 222.0 | 0.0 |
Même information, mais en tant que graphique à barres:
Et avec une barre séparée pour chaque modèle d'invite: 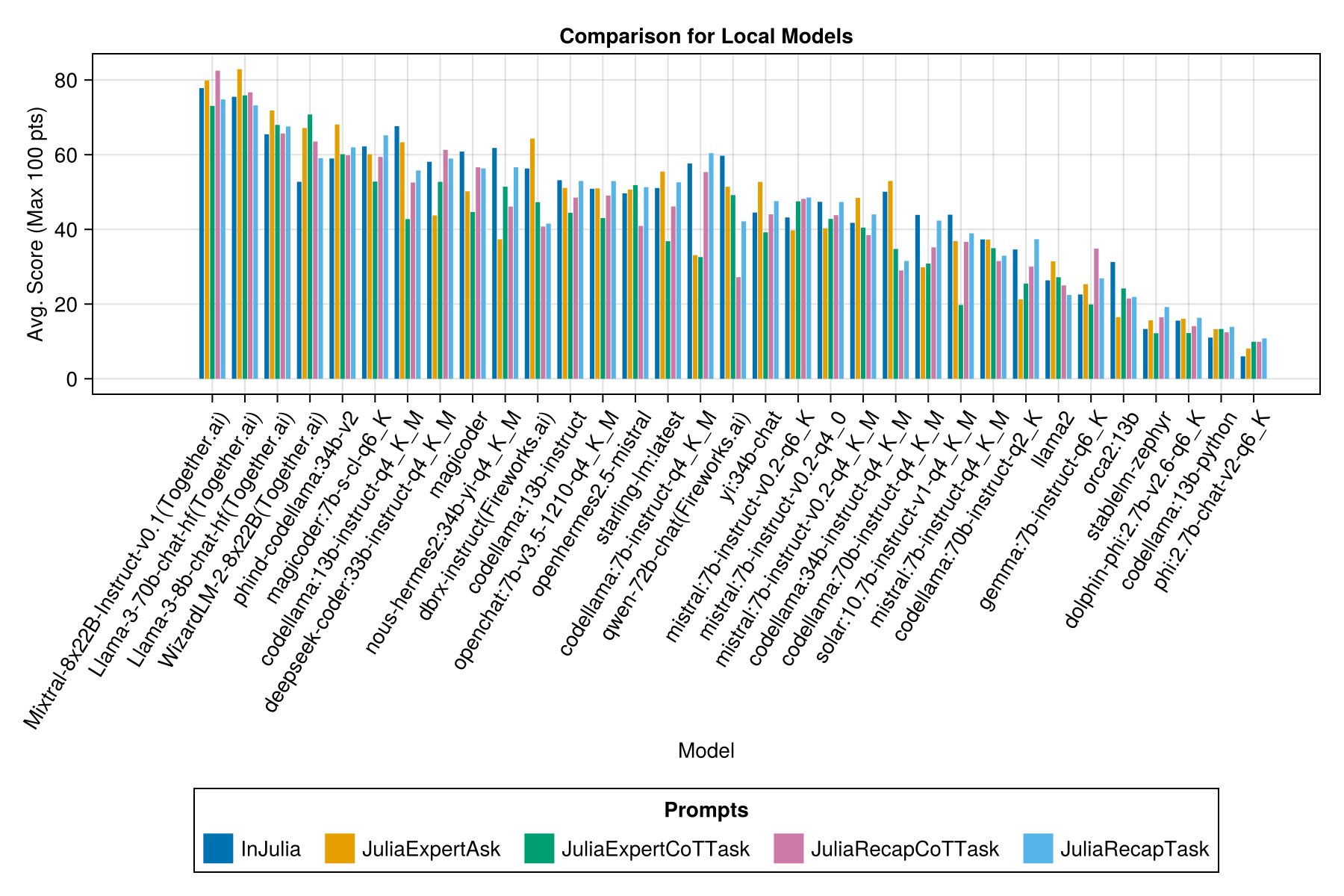
Note
Les modèles QWEN-1.5 ont été supprimés des aperçus car le modèle sous-jacent sur le référentiel Olllama (et HF) n'est pas correct et a des performances très faibles.
Note
J'ai remarqué que certains Evals dans Ollama / Llama.cpp obtiennent désormais un score légèrement plus élevé maintenant qu'en décembre-23, il est donc sur une feuille de route pour réintégrer les Evals ci-dessus.
De toute évidence, la victoire des API payantes (la dernière version: GPT-3.5-Turbo-1106), mais ce n'est pas toute l'histoire.
Nous espérons être en mesure de fournir des conseils sur les stratégies d'incitation, par exemple, quand vaut-il mieux utiliser un modèle d'invite "JuliaExpert *" par rapport à l'invite "in Julia, répondez xyz".
Apprentissage jusqu'à présent:
| Modèle invite | Écoulé (s, moyen) | Écoulé (s, médian) | Avg. Score (max 100 pts) | Score médian (max 100 pts) |
|---|---|---|---|---|
| Bêtise | 14.0 | 9.6 | 55.2 | 50.0 |
| JuliaExpertask | 9.9 | 6.4 | 53.8 | 50.0 |
| Juliatecaptask | 16.7 | 11.5 | 52.0 | 50.0 |
| JuliaExpertCottask | 15.4 | 10.4 | 49.5 | 50.0 |
| Juliatecapcottask | 16.1 | 11.3 | 48.6 | 50.0 |
Remarque: Les modèles basés sur XML sont testés uniquement pour les modèles Claude 3 (Haiku et Sonnet), c'est pourquoi nous les avons retirés de la comparaison.
Faites votre propre analyse avec examples/summarize_results.jl !
scripts/code_gen_benchmark.jl pour l'exemple des évaluations précédentes. Vous voulez exécuter quelques expériences et enregistrer les résultats? Découvrez examples/experiment_hyperparameter_scan.jl !
Vous voulez revoir certains des passes de référence passées? Consultez examples/summarize_results.jl pour les statistiques globales et examples/debugging_results.jl pour examiner les conversations individuelles / réponses du modèle.
Pour contribuer un cas de test:
code_generation/category/test_case_name/definition.toml .code_generation/category/test case/model/evaluation__PROMPT__STRATEGY__TIMESTAMP.json et code_generation/category/test case/model/conversation__PROMPT__STRATEGY__TIMESTAMP.jsondefinition.toml Champs requis dans definition.toml incluent:
my_function(1, 2) ).@test X = Z .Il existe plusieurs champs facultatifs:
Les champs ci-dessus peuvent améliorer la réutilisation du code à travers les exemples / tests unitaires.
Voir un exemple dans examples/create_definition.jl . Vous pouvez valider vos définitions de cas de test avec validate_definition() .
Veuillez PR et ajouter toutes les conversations pertinentes et principalement correctes avec / in / à propos de Julia dans le dossier julia_conversations/ .
L'objectif est d'avoir une collection de conversations qui sont utiles pour les connaissances de Julia Finetuning dans des modèles plus petits.
Nous apprécions fortement la contribution de la communauté. Si vous avez des suggestions ou des idées d'amélioration, veuillez ouvrir un problème. Toutes les contributions sont les bienvenues!


