Julia LLM Leaderboard
v0.2.0
مقارنة قدرات توليد اللغة جوليا لنماذج اللغة الكبيرة المختلفة
definition.tomlمرحبًا بكم في مستودع جوليا كود جيل المعيار!
تم تصميم هذا المشروع لمجتمع جوليا لمقارنة إمكانيات توليد الكود لنماذج الذكاء الاصطناعي المختلفة. على عكس المعايير الأكاديمية ، فإن تركيزنا هو التطبيق والبساطة: "إنشاء الكود ، وتشغيله ، ومعرفة ما إذا كان يعمل (-ish)."
يهدف هذا المستودع إلى فهم كيفية أداء نماذج الذكاء الاصطناعى المختلفة والاستراتيجيات التي تقدمها في توليد رمز جوليا الصحيح بشكل نحلي لتوجيه المستخدمين في اختيار أفضل نموذج لاحتياجاتهم.
أصابع حكة؟ اقفز إلى examples/ أو فقط قم بتشغيل معيارك الخاص مع run_benchmark() (على سبيل المثال ، examples/code_gen_benchmark.jl ).
يتم تعريف حالات الاختبار في ملف definition.toml ، مما يوفر بنية قياسية لكل اختبار. إذا كنت ترغب في المساهمة في حالة اختبار ، فيرجى اتباع الإرشادات في قسم حالة الاختبار المساهمة.
يتم تقييم أداء كل نموذج ومطالبة بناءً على عدة معايير:
في الوقت الحالي ، يتم وزن جميع المعايير على قدم المساواة ويمكن أن تكسب كل حالة اختبار 100 نقطة كحد أقصى. إذا نجح رمز في جميع المعايير ، فإنه يحصل على 100/100 نقطة. إذا فشلت معيار واحد (على سبيل المثال ، جميع اختبارات الوحدة) ، فإنه يحصل على 75/100 نقطة. إذا فشلت معايير (على سبيل المثال ، يتم تشغيلها ولكن جميع الأمثلة واختبارات الوحدة مكسورة) ، فإنها تحصل على 50 نقطة ، وهكذا.
لتوفير لمحة عن وظيفة المستودع ، قمنا بتضمين نتائج مثال لأول 14 حالة اختبار. افتح الوثائق للحصول على النتائج الكاملة والغوص العميق في كل حالة اختبار.
تحذير
قد تتغير هذه الدرجات مع تطور وظيفة الدعم وإضافة المزيد من النماذج.
تذكر أن المعيار يمثل تحديًا كبيرًا لأي نموذج - مساحة إضافية أو أقواس واحدة وقد تصبح النتيجة 0 (= "غير قادر على التحليل")!
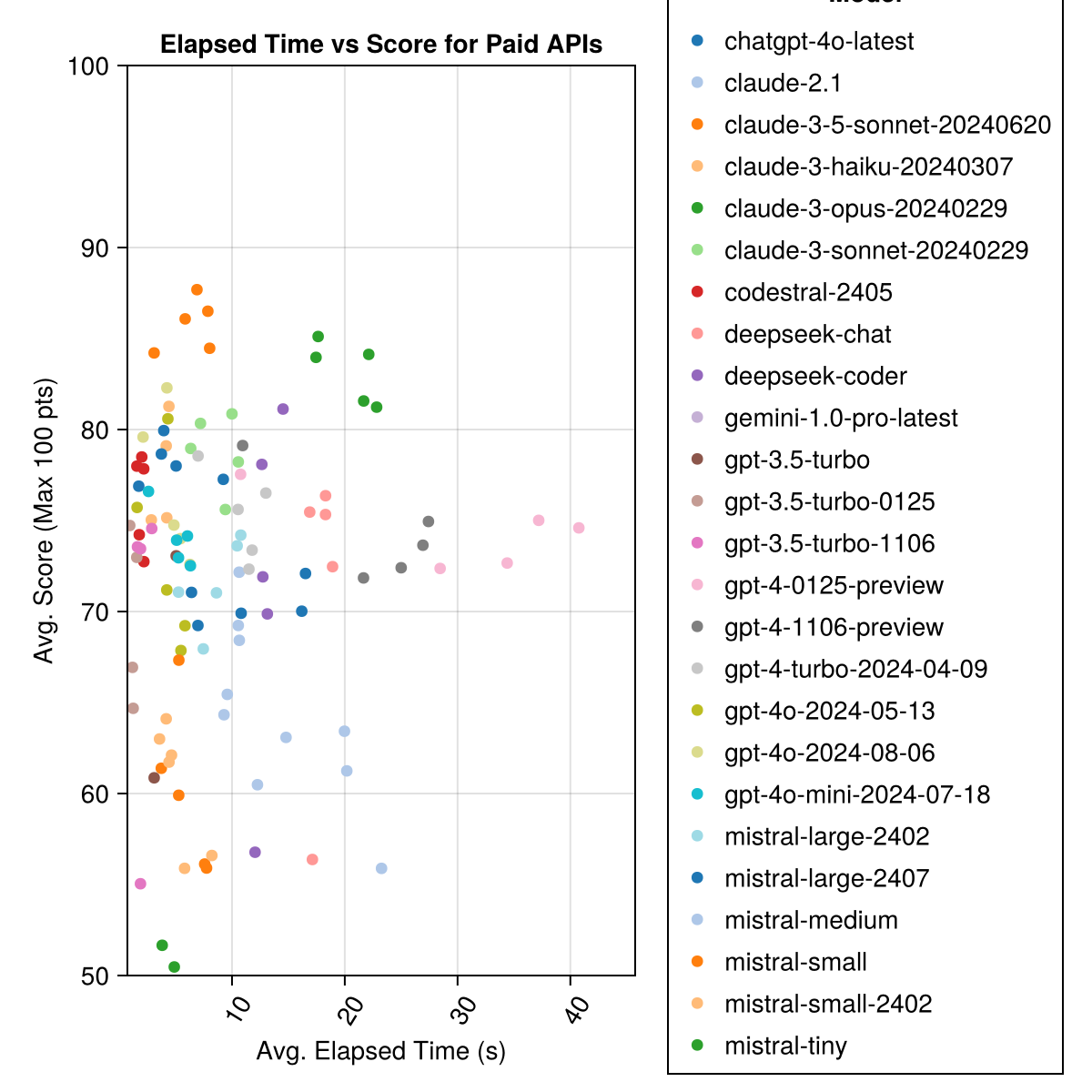
كلود 3.5 Sonnet هو النموذج الأعلى أداء. للحصول على أفضل قيمة مقابل المال ، انظر إلى Mistral CodeStral ، Claude 3 Haiku ، ، الذي تم إصداره مؤخرًا ، GPT 4O Mini (أرخص 60 ٪ من GPT3.5 !!!).
| نموذج | انقضت | نتيجة | نقاط الانحراف الأمراض المنقولة جنسيا | عد الصفر | عد النتيجة الكاملة | تكلفة سنتات |
|---|---|---|---|---|---|---|
| Claude-3-5-Sonnet-20240620 | 6.3 | 85.8 | 21.1 | 13 | 355 | 0.73 |
| Claude-3-Opus-20240229 | 20.3 | 83.2 | 19.6 | 2 | 329 | 3.9 |
| Claude-3-Sonnet-20240229 | 8.7 | 78.8 | 26.2 | 22 | 308 | 0.73 |
| GPT-4O-2024-08-06 | 4.6 | 76.6 | 27.9 | 26 | 310 | 0.0 |
| CodeStral-2405 | 1.9 | 76.3 | 29.3 | 33 | 276 | 0.0 |
| GPT-4-TURBO-2024-04-09 | 10.8 | 75.3 | 29.6 | 38 | 290 | 1.38 |
| chatgpt-4o-latest | 4.8 | 75.0 | 27.9 | 25 | 263 | 0.0 |
| كلود-3-هايكو -20240307 | 4.0 | 74.9 | 27.2 | 9 | 261 | 0.05 |
| GPT-4-0125-PREVIEW | 30.3 | 74.4 | 30.3 | 39 | 284 | 1.29 |
| GPT-4-1106-PREVIEW | 22.4 | 74.4 | 29.9 | 19 | 142 | 1.21 |
| GPT-4O-MINI-2024-07-18 | 5.1 | 74.0 | 29.4 | 32 | 276 | 0.03 |
| Mistral-Large-2407 | 11.3 | 73.6 | 29.5 | 15 | 137 | 0.49 |
| GPT-4O-2024-05-13 | 4.3 | 72.9 | 29.1 | 29 | 257 | 0.0 |
| Deepseek-CoDer | 13.0 | 71.6 | 32.6 | 39 | 115 | 0.01 |
| Mistral-Large-2402 | 8.5 | 71.6 | 27.2 | 13 | 223 | 0.0 |
| Deepseek-Chat | 17.9 | 71.3 | 32.9 | 30 | 140 | 0.01 |
| كلود -2.1 | 10.1 | 67.9 | 30.8 | 47 | 229 | 0.8 |
| GPT-3.5-TURBO-0125 | 1.2 | 61.7 | 36.6 | 125 | 192 | 0.03 |
| Mistral-Medium | 18.1 | 60.8 | 33.2 | 22 | 90 | 0.41 |
| ميسترا رمي | 5.9 | 60.1 | 30.2 | 27 | 76 | 0.09 |
| Mistral-Small-2402 | 5.3 | 59.9 | 29.4 | 31 | 169 | 0.0 |
| GPT-3.5-TURBO-1106 | 2.1 | 58.4 | 39.2 | 82 | 97 | 0.04 |
| ميستريني | 4.6 | 46.9 | 32.0 | 75 | 42 | 0.02 |
| GPT-3.5 توربو | 3.6 | 42.3 | 38.2 | 132 | 54 | 0.04 |
| Gemini-1.0-Pro-Latest | 4.2 | 34.8 | 27.4 | 181 | 25 | 0.0 |
ملاحظة: من منتصف فبراير 2024 ، ستشير "GPT-3.5-TURBO" إلى الإصدار الأخير ، "GPT-3.5-TURBO-0125" (إهمال إصدار يونيو).
نفس المعلومات ، ولكن كمخطط شريط:
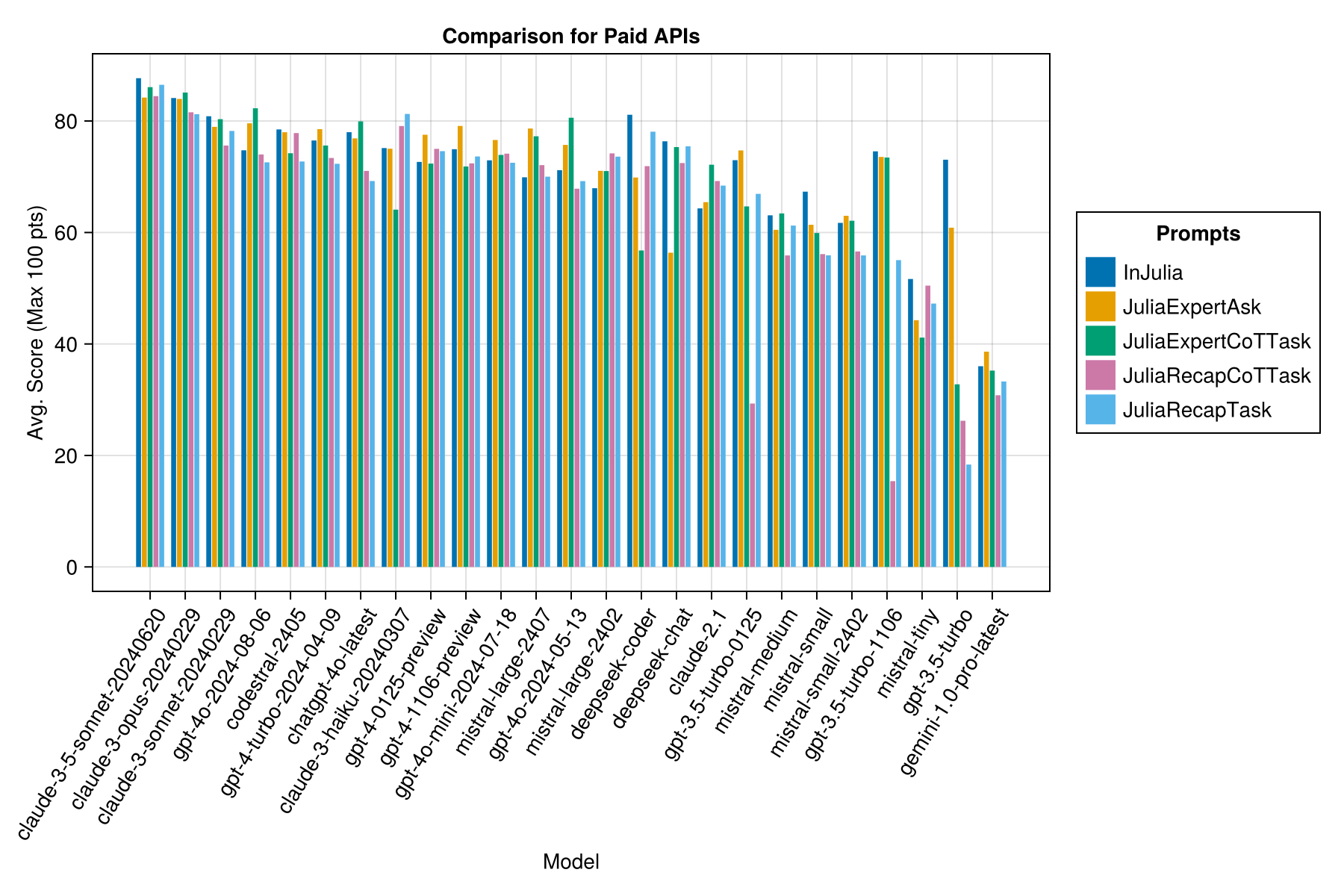
بالإضافة إلى ذلك ، يمكننا النظر في الأداء (النتيجة) مقابل التكلفة (تقاس في سنتات الولايات المتحدة):
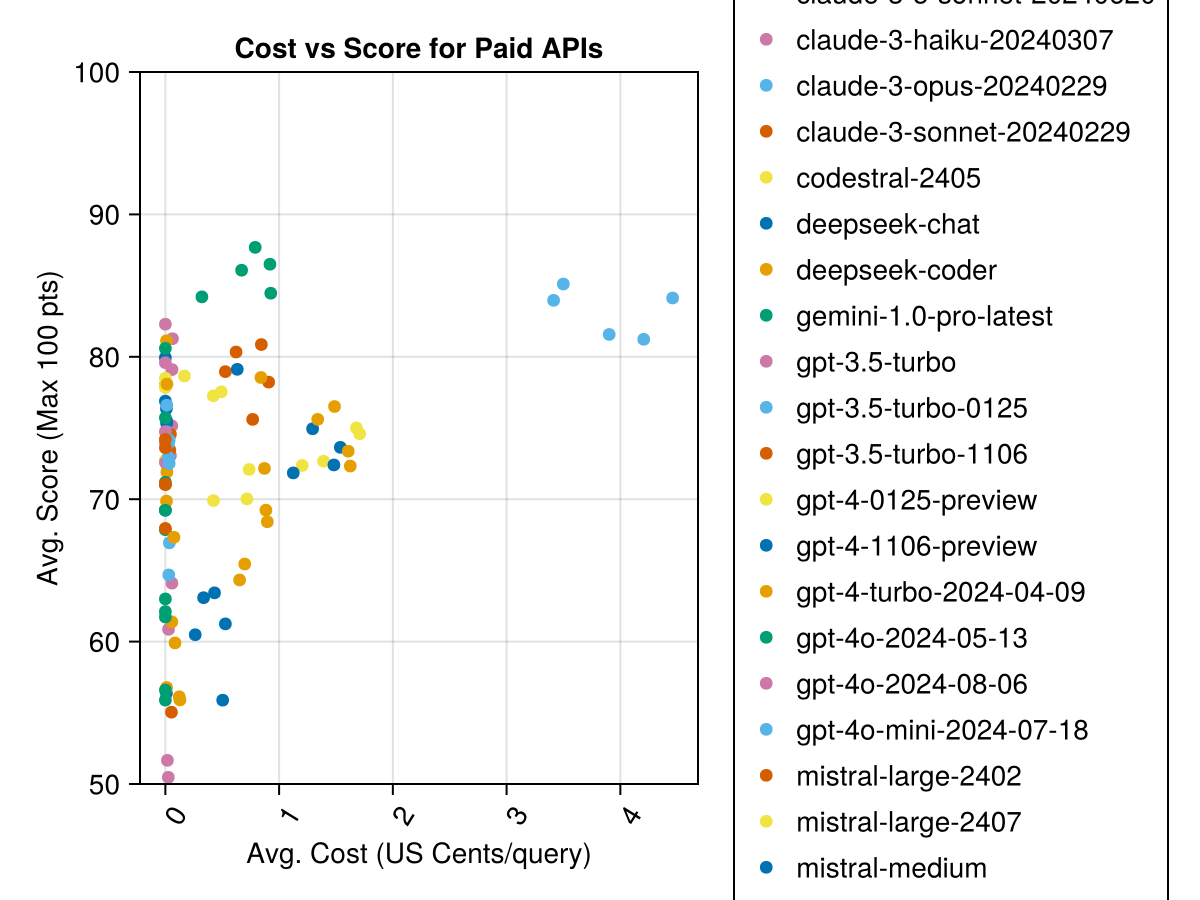
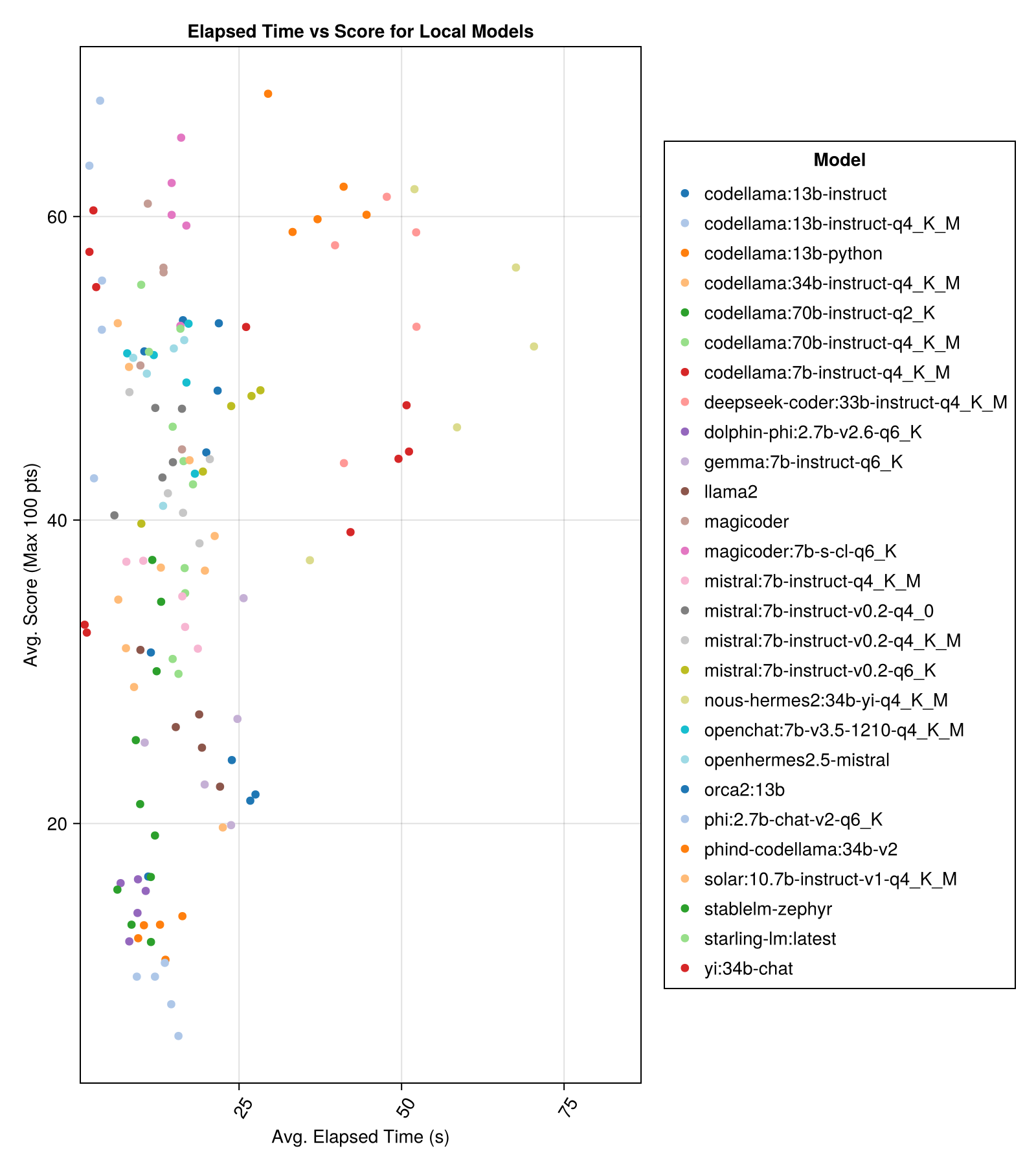
عادة ما تكون النماذج المستضافة محليًا جيدة مثل أفضل واجهات برمجة التطبيقات المدفوعة ، لكنها تقترب! لاحظ أن "small small" متاح بالفعل ليتم تشغيله محليًا وسيكون هناك العديد من Finetunes المستقبلية!
ملحوظة
شكراً جزيلاً لـ 01.ai و Jun Tian على وجه الخصوص لتوفير الحساب لعدة أجزاء من هذا المعيار!
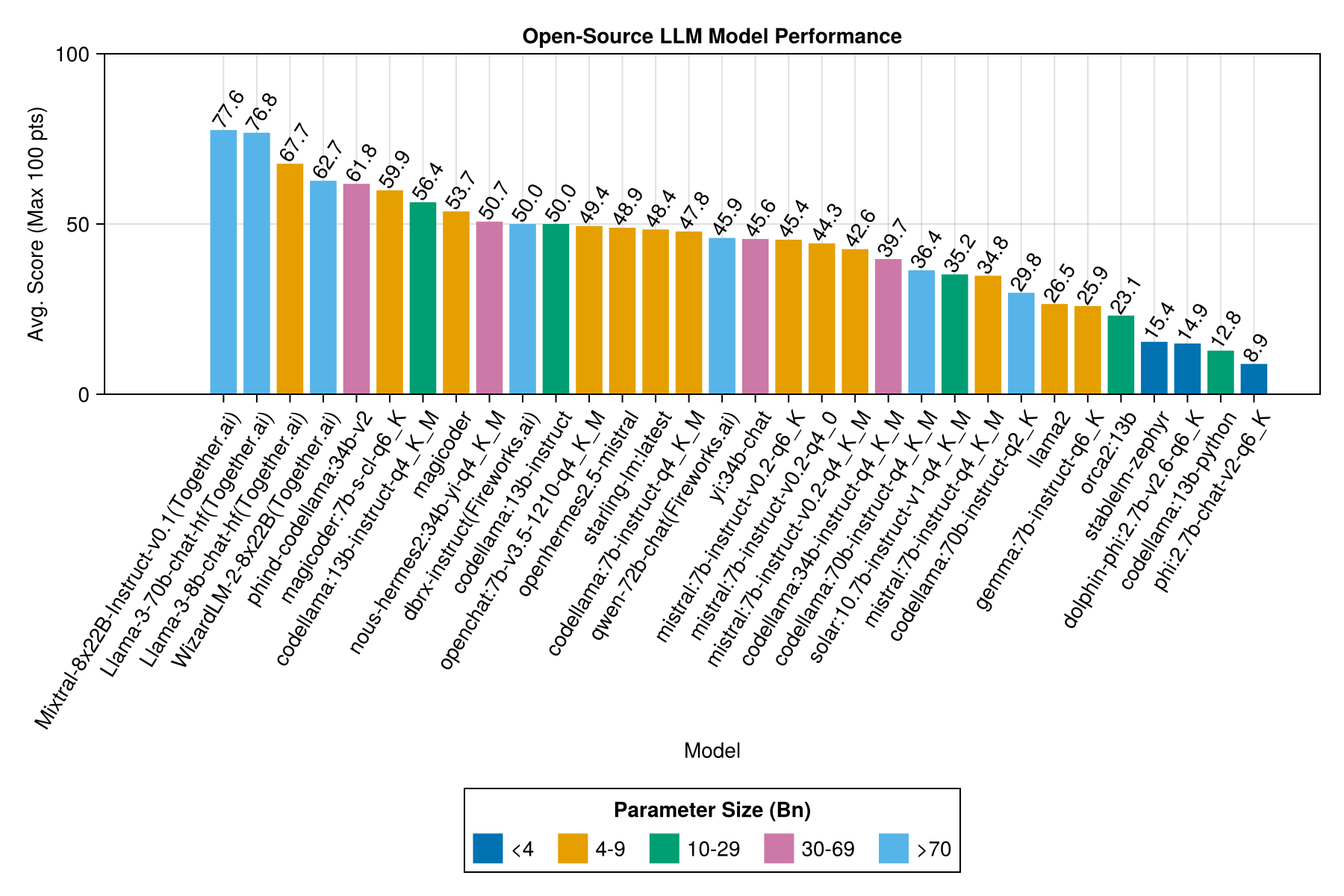
أفضل أداء مقايضة مقابل الحجم هو أحدث meta llama3 8bn. خلاف ذلك ، فإن النموذج الرائد هو Mixtral-8x22bn.
| نموذج | انقضت | المتوسط المنقضي | نتيجة | متوسط النتيجة | نقاط الانحراف الأمراض المنقولة جنسيا | عد الصفر | عد النتيجة الكاملة |
|---|---|---|---|---|---|---|---|
| mixtral-8x22b-instruct-v0.1 (معا .ai) | 14.1 | 11.0 | 77.6 | 90.0 | 25.8 | 5.0 | 151.0 |
| llama-3-70b-chat-hf (معا .ai) | 4.3 | 4.1 | 76.8 | 88.3 | 25.2 | 0.0 | 160.0 |
| Llama-3-8b-Chat-HF (معا .ai) | 1.5 | 1.4 | 67.7 | 66.7 | 26.4 | 5.0 | 70.0 |
| Wizardlm-2-8x22b (معا .ai) | 34.7 | 31.0 | 62.7 | 60.0 | 33.8 | 33.0 | 118.0 |
| Phind-Codellama: 34B-V2 | 37.1 | 36.4 | 61.8 | 62.5 | 33.5 | 36.0 | 58.0 |
| Magicoder: 7B-S-Cl-Q6_K | 15.6 | 15.8 | 59.9 | 60.0 | 29.9 | 18.0 | 35.0 |
| Codellama: 13b-instruct-q4_k_m | 3.2 | 3.0 | 56.4 | 54.6 | 33.0 | 56.0 | 61.0 |
| Deepseek-CoDer: 33b-instruct-q4_k_m | 46.7 | 44.6 | 55.0 | 50.0 | 36.8 | 62.0 | 68.0 |
| Magicoder | 12.8 | 10.7 | 53.7 | 50.0 | 33.2 | 49.0 | 52.0 |
| nous-hermes2: 34b-yi-q4_k_m | 56.8 | 52.8 | 50.7 | 50.0 | 34.7 | 78.0 | 56.0 |
| DBRX-instruct (الألعاب النارية. | 3.7 | 3.6 | 50.0 | 50.0 | 41.2 | 121.0 | 75.0 |
| Codellama: 13b-instruct | 18.1 | 16.7 | 50.0 | 50.0 | 34.4 | 65.0 | 44.0 |
| OpenChat: 7B-V3.5-1210-Q4_K_M | 14.4 | 13.7 | 49.4 | 50.0 | 30.3 | 48.0 | 23.0 |
| OpenHermes2.5-Mistral | 12.9 | 12.2 | 48.9 | 50.0 | 31.3 | 55.0 | 27.0 |
| Starling-LM: الأحدث | 13.7 | 12.5 | 48.4 | 50.0 | 30.2 | 58.0 | 26.0 |
| Codellama: 7b-instruct-q4_k_m | 2.1 | 2.0 | 47.8 | 50.0 | 35.3 | 95.0 | 38.0 |
| Qwen-72b-Chat (Fireworks.ai) | 3.2 | 3.8 | 45.9 | 50.0 | 38.8 | 117.0 | 63.0 |
| يي: 34 ب- الدردشة | 43.9 | 41.3 | 45.6 | 50.0 | 30.5 | 45.0 | 34.0 |
| Mistral: 7b-instruct-v0.2-q6_k | 21.7 | 20.9 | 45.4 | 50.0 | 31.3 | 44.0 | 23.0 |
| Mistral: 7b-instruct-v0.2-q4_0 | 12.4 | 12.3 | 44.3 | 50.0 | 30.6 | 75.0 | 32.0 |
| MISTRAL: 7B-instruct-V0.2-Q4_K_M | 15.6 | 15.1 | 42.6 | 50.0 | 28.6 | 71.0 | 23.0 |
| Codellama: 34b-instruct-q4_k_m | 7.5 | 6.8 | 39.7 | 50.0 | 36.1 | 127.0 | 35.0 |
| Codellama: 70b-instruct-q4_k_m | 16.3 | 13.8 | 36.4 | 0.0 | 41.2 | 179.0 | 58.0 |
| الطاقة الشمسية: 10.7b-instruct-v1-q4_k_m | 18.8 | 17.7 | 35.2 | 50.0 | 31.1 | 107.0 | 10.0 |
| Mistral: 7b-instruct-q4_k_m | 13.9 | 13.0 | 34.8 | 50.0 | 26.5 | 80.0 | 0.0 |
| Codellama: 70b-instruct-q2_k | 11.2 | 9.4 | 29.8 | 0.0 | 37.7 | 198.0 | 29.0 |
| Llama2 | 17.1 | 16.3 | 26.5 | 25.0 | 26.5 | 131.0 | 0.0 |
| Gemma: 7b-instruct-q6_k | 20.9 | 22.1 | 25.9 | 25.0 | 25.2 | 147.0 | 2.0 |
| ORCA2: 13B | 20.1 | 18.3 | 23.1 | 0.0 | 30.6 | 166.0 | 11.0 |
| Stablelm-zephyr | 9.9 | 7.7 | 15.4 | 0.0 | 23.5 | 192.0 | 1.0 |
| Dolphin-Phi: 2.7b-V2.6-Q6_K | 8.9 | 8.4 | 14.9 | 0.0 | 22.9 | 188.0 | 0.0 |
| Codellama: 13b-Python | 12.5 | 10.7 | 12.8 | 0.0 | 22.1 | 155.0 | 0.0 |
| PHI: 2.7B-Chat-V2-Q6_K | 13.0 | 11.6 | 8.9 | 0.0 | 19.4 | 222.0 | 0.0 |
نفس المعلومات ، ولكن كمخطط شريط:
ومع شريط منفصل لكل قالب موجه: 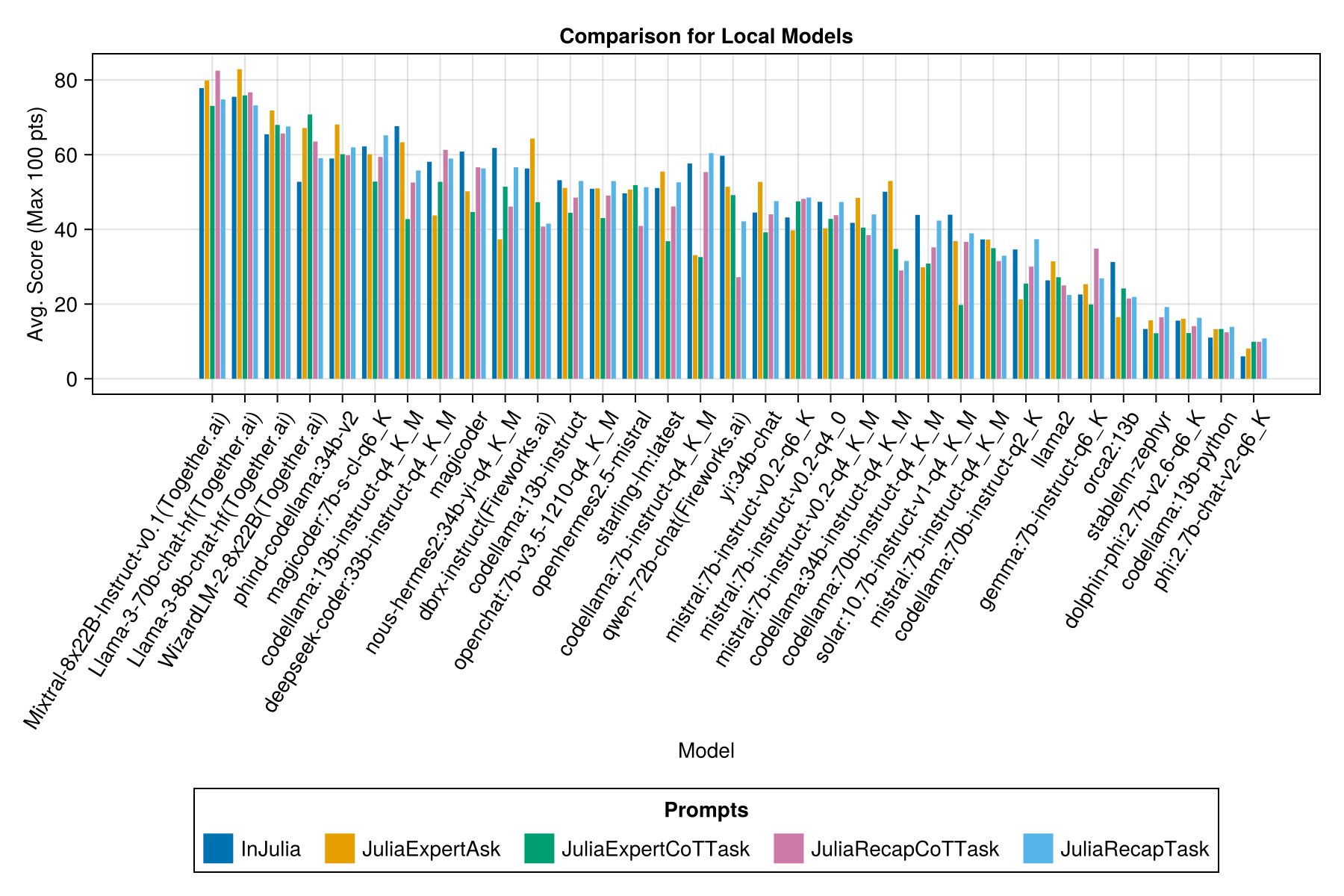
ملحوظة
تمت إزالة نماذج QWEN-1.5 من النظارات العامة لأن النموذج الأساسي على مستودع Ollama (و HF) غير صحيح وله أداء منخفض للغاية.
ملحوظة
لقد لاحظت أن بعض evals في Ollama/llama.cpp الآن يسجل الآن أعلى قليلاً من ديسمبر 23 ، لذلك يكون على خريطة طريق لإعادة تشغيل EVALs أعلاه.
من الواضح أن واجهات برمجة التطبيقات المدفوعة (أحدث إصدار: GPT-3.5-TURBO-1106) ، ولكن هذه ليست القصة بأكملها.
نأمل أن نكون قادرين على تقديم بعض الإرشادات حول استراتيجيات الدعوة ، على سبيل المثال ، متى من الأفضل استخدام قالب موجه "Juliaexpert*" مقابل "في جوليا ، الإجابة XYZ".
التعلم حتى الآن:
| قالب موجه | انقضت (S ، المتوسط) | انقضت (S ، متوسط) | متوسط. النتيجة (كحد أقصى 100 نقطة) | النتيجة المتوسطة (الحد الأقصى 100 نقطة) |
|---|---|---|---|---|
| إنقنسية | 14.0 | 9.6 | 55.2 | 50.0 |
| JuliaexperTask | 9.9 | 6.4 | 53.8 | 50.0 |
| Julearecaptask | 16.7 | 11.5 | 52.0 | 50.0 |
| Juliaexpertcottask | 15.4 | 10.4 | 49.5 | 50.0 |
| julearecapcottask | 16.1 | 11.3 | 48.6 | 50.0 |
ملاحظة: يتم اختبار القوالب المستندة إلى XML فقط لنماذج Claude 3 (Haiku و Sonnet) ، ولهذا السبب قمنا بإزالتها من المقارنة.
اجعل التحليل الخاص بك مع examples/summarize_results.jl !
scripts/code_gen_benchmark.jl لمثال التقييمات السابقة. هل تريد إجراء بعض التجارب وحفظ النتائج؟ تحقق من examples/experiment_hyperparameter_scan.jl !
هل تريد مراجعة بعض أشواط القياس السابقة؟ تحقق من examples/summarize_results.jl للحصول على الإحصاءات الشاملة examples/debugging_results.jl لمراجعة المحادثات الفردية/الاستجابات النموذجية.
للمساهمة في حالة اختبار:
code_generation/category/test_case_name/definition.toml .code_generation/category/test case/model/evaluation__PROMPT__STRATEGY__TIMESTAMP.json و code_generation/category/test case/model/conversation__PROMPT__STRATEGY__TIMESTAMP.jsondefinition.toml الحقول المطلوبة في definition.toml .
my_function(1, 2) ).@test X = Z .هناك العديد من الحقول الاختيارية:
يمكن للحقول المذكورة أعلاه تحسين إعادة استخدام التعليمات البرمجية عبر أمثلة/اختبارات الوحدة.
انظر مثال في examples/create_definition.jl . يمكنك التحقق من صحة تعريفات حالة الاختبار الخاصة بك باستخدام validate_definition() .
يرجى PR وإضافة أي محادثات ذات صلة وصحيحة في الغالب مع/في/حول جوليا في مجلد julia_conversations/ .
الهدف من ذلك هو الحصول على مجموعة من المحادثات المفيدة للمعرفة في جوليا في نماذج أصغر.
نحن نقدر بشدة مدخلات المجتمع. إذا كان لديك اقتراحات أو أفكار للتحسين ، فيرجى فتح مشكلة. جميع المساهمات موضع ترحيب!


