Julia LLM Leaderboard
v0.2.0
Comparación de las capacidades de generación de idiomas de Julia de varios modelos de idiomas grandes
definition.toml¡Bienvenido al repositorio de referencia de la generación de código de Julia!
Este proyecto está diseñado para la comunidad de Julia para comparar las capacidades de generación de código de varios modelos de IA. A diferencia de los puntos de referencia académicos, nuestro enfoque es la practicidad y la simplicidad: "Generar código, ejecutarlo y ver si funciona (-ish)".
Este repositorio tiene como objetivo comprender cómo funcionan los diferentes modelos de IA y las estrategias de suministro para generar el código Julia sintácticamente correcto para guiar a los usuarios a elegir el mejor modelo para sus necesidades.
Picazón en los dedos? Salta a examples/ o simplemente ejecute tu propio punto de referencia con run_benchmark() (por ejemplo, examples/code_gen_benchmark.jl ).
Los casos de prueba se definen en un archivo definition.toml , proporcionando una estructura estándar para cada prueba. Si desea contribuir con un caso de prueba, siga las instrucciones en la sección Contribuir el caso de su prueba.
El desempeño de cada modelo y aviso se evalúa en función de varios criterios:
Por el momento, todos los criterios se pesan por igual y cada caso de prueba puede ganar un máximo de 100 puntos. Si un código pasa todos los criterios, obtiene 100/100 puntos. Si falla un criterio (por ejemplo, todas las pruebas unitarias), obtiene 75/100 puntos. Si falla dos criterios (por ejemplo, se ejecuta pero todos los ejemplos y pruebas unitarias están rotas), obtiene 50 puntos, y así sucesivamente.
Para proporcionar una visión de la funcionalidad del repositorio, hemos incluido resultados de ejemplo para los primeros 14 casos de prueba. Abra la documentación para obtener los resultados completos y una inmersión profunda en cada caso de prueba.
Advertencia
Estos puntajes pueden cambiar a medida que evolucionamos la funcionalidad de soporte y agregamos más modelos.
Recuerde que el punto de referencia es bastante desafiante para cualquier modelo: ¡un solo espacio adicional o paréntesis y la puntuación podría convertirse en 0 (= "incapaz de analizar")!
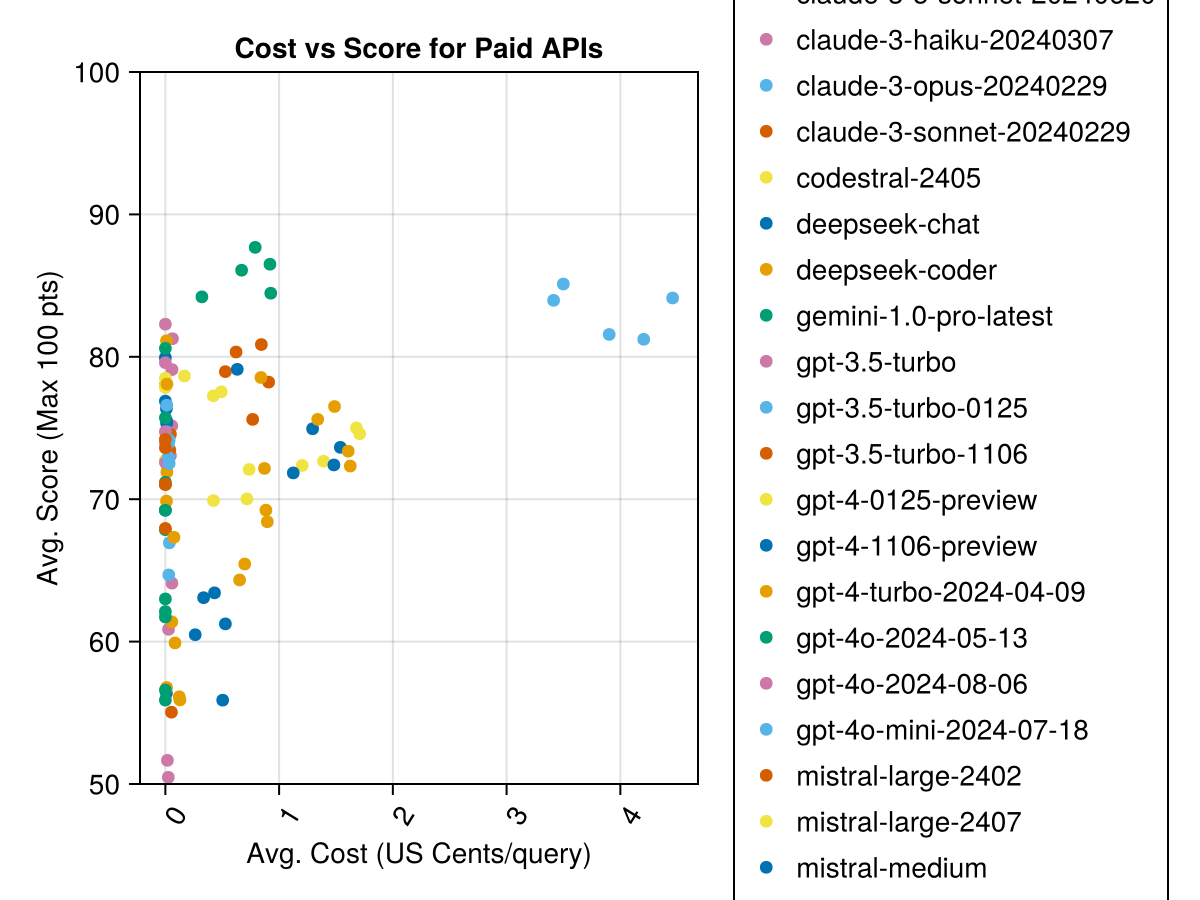
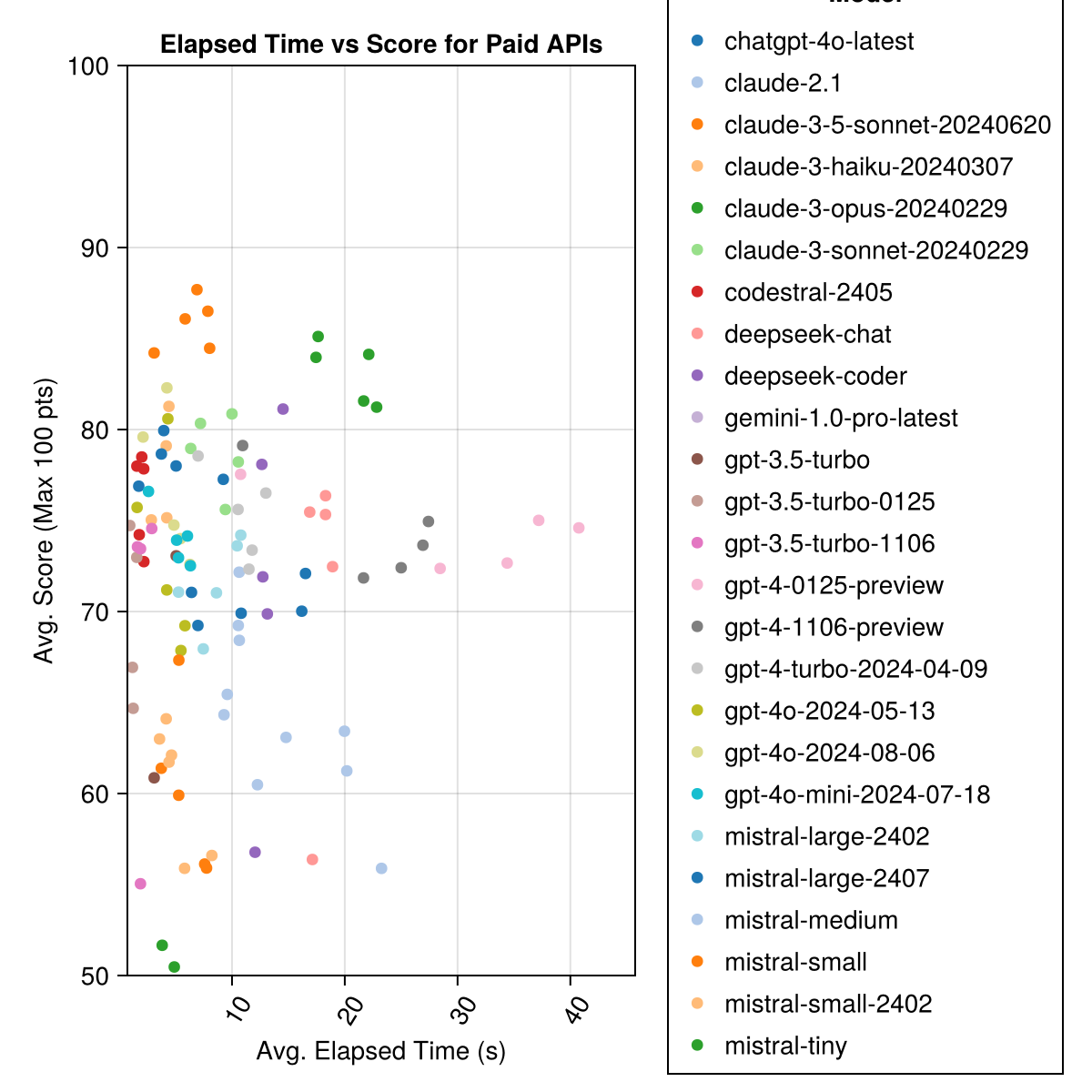
El soneto Claude 3.5 es el modelo de mayor rendimiento. Para obtener el mejor valor para el dinero, busque en Mistral Codestral, Claude 3 Haiku y, recientemente lanzado, GPT 4O Mini (60% más barato que GPT3.5!).
| Modelo | Transcurrido | Puntaje | Desviación de STD de puntuación | CUENTA DE CUENTA CERO | Contar puntaje completo | Costos centavos |
|---|---|---|---|---|---|---|
| Claude-3-5-Sonnet-20240620 | 6.3 | 85.8 | 21.1 | 13 | 355 | 0.73 |
| Claude-3-OPUS-20240229 | 20.3 | 83.2 | 19.6 | 2 | 329 | 3.9 |
| Claude-3-Sonnet-20240229 | 8.7 | 78.8 | 26.2 | 22 | 308 | 0.73 |
| GPT-4O-2024-08-06 | 4.6 | 76.6 | 27.9 | 26 | 310 | 0.0 |
| Codestral-2405 | 1.9 | 76.3 | 29.3 | 33 | 276 | 0.0 |
| GPT-4-TURBO-2024-04-09 | 10.8 | 75.3 | 29.6 | 38 | 290 | 1.38 |
| chatgpt-4o-latest | 4.8 | 75.0 | 27.9 | 25 | 263 | 0.0 |
| Claude-3-HAIKU-20240307 | 4.0 | 74.9 | 27.2 | 9 | 261 | 0.05 |
| GPT-4-0125 Preview | 30.3 | 74.4 | 30.3 | 39 | 284 | 1.29 |
| GPT-4-1106 previa | 22.4 | 74.4 | 29.9 | 19 | 142 | 1.21 |
| GPT-4O-MINI-2024-07-18 | 5.1 | 74.0 | 29.4 | 32 | 276 | 0.03 |
| Mistral-Large-2407 | 11.3 | 73.6 | 29.5 | 15 | 137 | 0.49 |
| GPT-4O-2024-05-13 | 4.3 | 72.9 | 29.1 | 29 | 257 | 0.0 |
| veloz de profundidad | 13.0 | 71.6 | 32.6 | 39 | 115 | 0.01 |
| Mistral-Large-2402 | 8.5 | 71.6 | 27.2 | 13 | 223 | 0.0 |
| profundo-chat | 17.9 | 71.3 | 32.9 | 30 | 140 | 0.01 |
| Claude-2.1 | 10.1 | 67.9 | 30.8 | 47 | 229 | 0.8 |
| GPT-3.5-TURBO-0125 | 1.2 | 61.7 | 36.6 | 125 | 192 | 0.03 |
| medio midal | 18.1 | 60.8 | 33.2 | 22 | 90 | 0.41 |
| malvado | 5.9 | 60.1 | 30.2 | 27 | 76 | 0.09 |
| Mistral-Small-2402 | 5.3 | 59.9 | 29.4 | 31 | 169 | 0.0 |
| GPT-3.5-TURBO-1106 | 2.1 | 58.4 | 39.2 | 82 | 97 | 0.04 |
| mistral | 4.6 | 46.9 | 32.0 | 75 | 42 | 0.02 |
| GPT-3.5-TURBO | 3.6 | 42.3 | 38.2 | 132 | 54 | 0.04 |
| Géminis-1.0-Pro-Latest | 4.2 | 34.8 | 27.4 | 181 | 25 | 0.0 |
Nota: Desde mediados de febrero de 2024, "GPT-3.5-Turbo" apuntará al último lanzamiento, "GPT-3.5-TURBO-0125" (desaprobando el lanzamiento de junio).
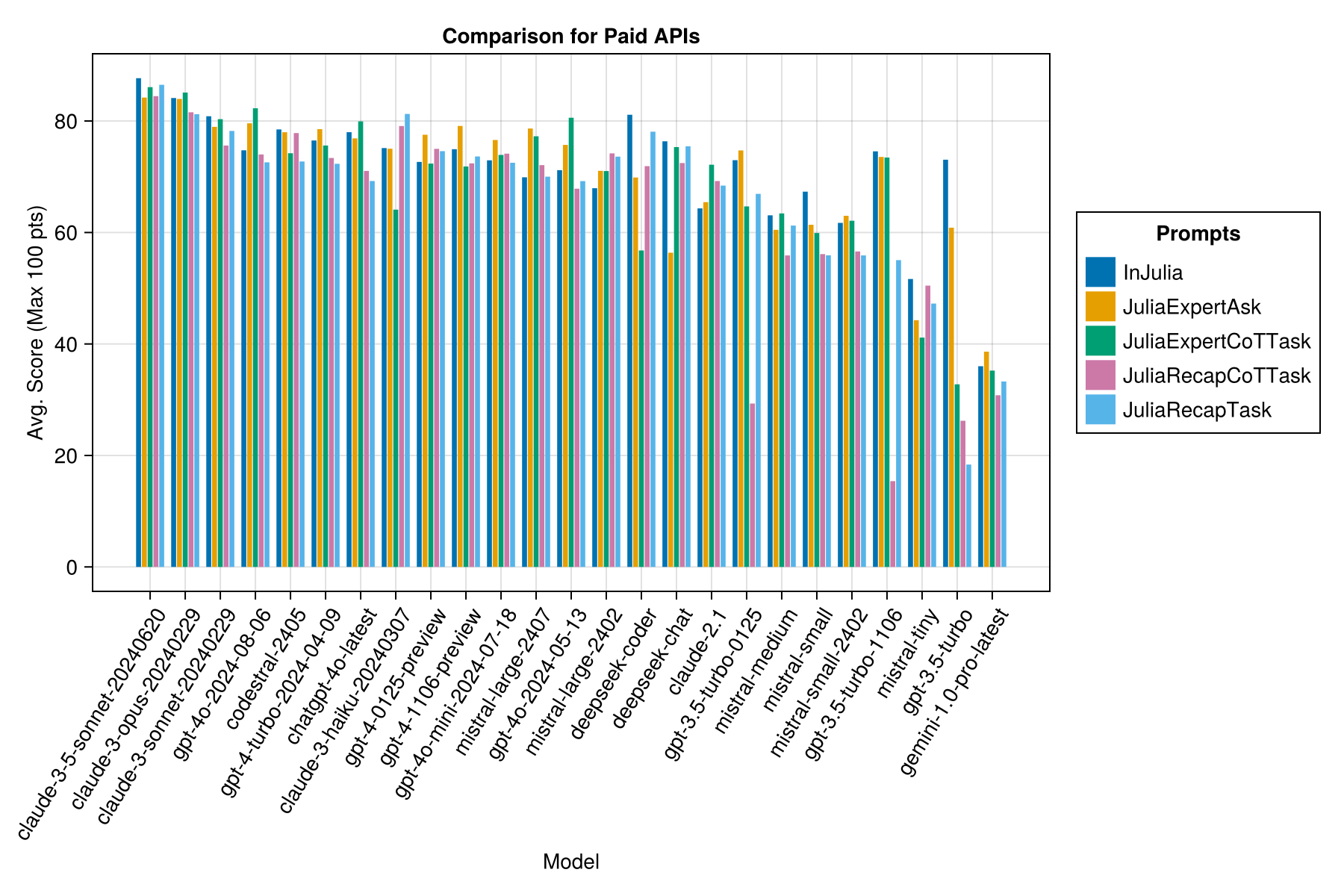
Misma información, pero como gráfico de barras:
Además, podemos considerar el rendimiento (puntaje) versus el costo (medido en centavos de EE. UU.):
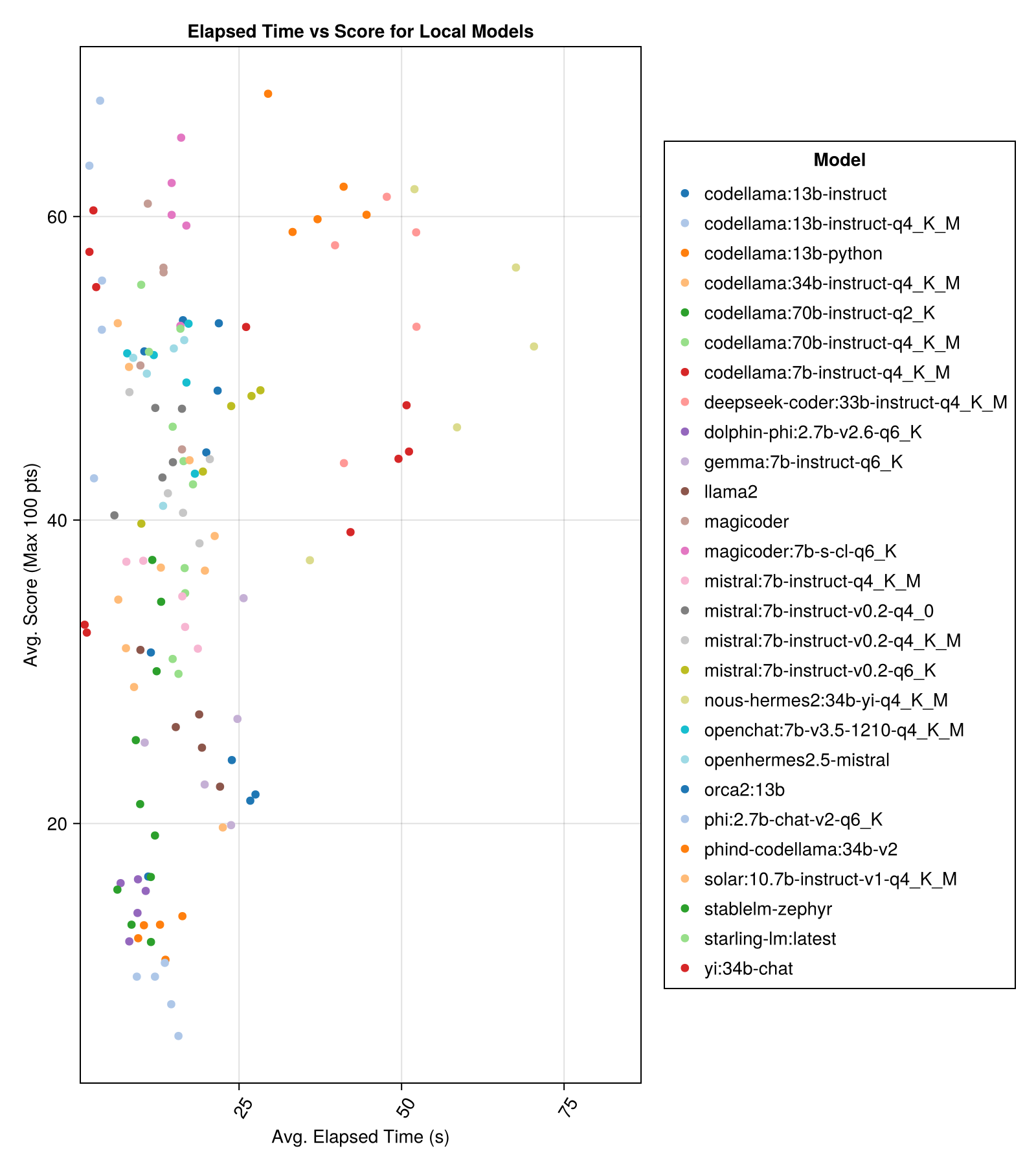
Los modelos alojados localmente generalmente no son tan buenos como las API mejor pagadas, ¡pero se están acercando! ¡Tenga en cuenta que el "Mistral-Small" ya está disponible para ejecutarse localmente y habrá muchas Futas Finetunes!
Nota
¡Muchas gracias a 01.ai y Jun Tian en particular por proporcionar el cómputo para varias partes de este punto de referencia!
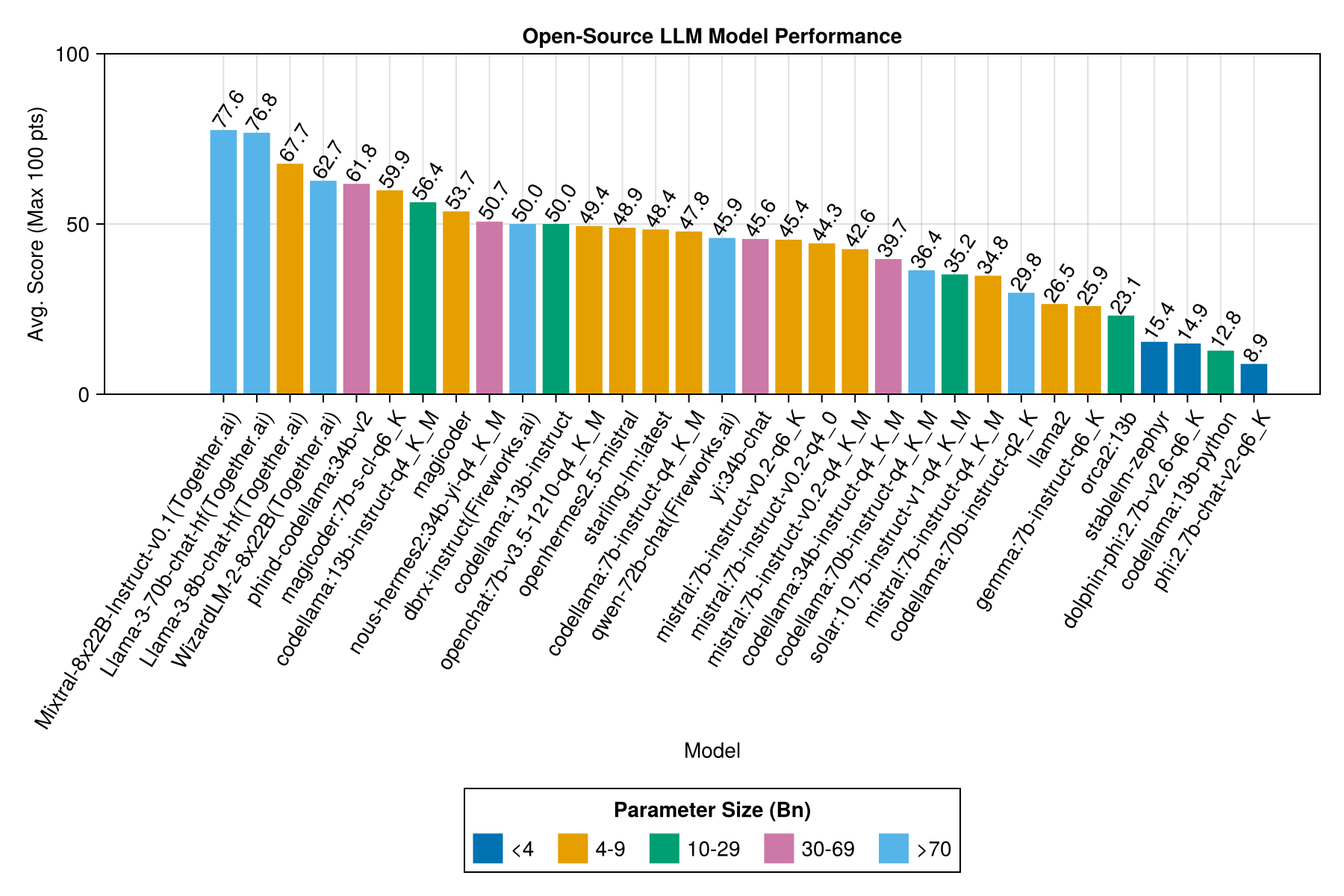
El mejor rendimiento de compensación vs tamaño es el último Meta Llama3 8bn. De lo contrario, el modelo principal es MixTral-8x22bn.
| Modelo | Transcurrido | Mediana transcurrida | Puntaje | Mediana de puntaje | Desviación de STD de puntuación | CUENTA DE CUENTA CERO | Contar puntaje completo |
|---|---|---|---|---|---|---|---|
| Mixtral-8x22b-instruct-v0.1 (juntos.ai) | 14.1 | 11.0 | 77.6 | 90.0 | 25.8 | 5.0 | 151.0 |
| LLAMA-3-70B-CHAT-HF (juntos.ai) | 4.3 | 4.1 | 76.8 | 88.3 | 25.2 | 0.0 | 160.0 |
| LLAMA-3-8B-CHAT-HF (juntos.ai) | 1.5 | 1.4 | 67.7 | 66.7 | 26.4 | 5.0 | 70.0 |
| Wizardlm-2-8x22b (juntos.ai) | 34.7 | 31.0 | 62.7 | 60.0 | 33.8 | 33.0 | 118.0 |
| Phind-Codellama: 34B-V2 | 37.1 | 36.4 | 61.8 | 62.5 | 33.5 | 36.0 | 58.0 |
| Magicoder: 7B-S-CL-Q6_K | 15.6 | 15.8 | 59.9 | 60.0 | 29.9 | 18.0 | 35.0 |
| Codellama: 13B-InNSTRUCT-Q4_K_M | 3.2 | 3.0 | 56.4 | 54.6 | 33.0 | 56.0 | 61.0 |
| Deepseek-coder: 33b-insiRT-Q4_K_M | 46.7 | 44.6 | 55.0 | 50.0 | 36.8 | 62.0 | 68.0 |
| mágico | 12.8 | 10.7 | 53.7 | 50.0 | 33.2 | 49.0 | 52.0 |
| nous-hermes2: 34b-yi-q4_k_m | 56.8 | 52.8 | 50.7 | 50.0 | 34.7 | 78.0 | 56.0 |
| DBRX-INSTRUST (fuegos artificiales.ai) | 3.7 | 3.6 | 50.0 | 50.0 | 41.2 | 121.0 | 75.0 |
| Codellama: 13B-Instructo | 18.1 | 16.7 | 50.0 | 50.0 | 34.4 | 65.0 | 44.0 |
| OpenChat: 7B-V3.5-1210-Q4_K_M | 14.4 | 13.7 | 49.4 | 50.0 | 30.3 | 48.0 | 23.0 |
| OpenHermes2.5-Mistral | 12.9 | 12.2 | 48.9 | 50.0 | 31.3 | 55.0 | 27.0 |
| Starling-LM: Último | 13.7 | 12.5 | 48.4 | 50.0 | 30.2 | 58.0 | 26.0 |
| Codellama: 7B-InNSTRUCT-Q4_K_M | 2.1 | 2.0 | 47.8 | 50.0 | 35.3 | 95.0 | 38.0 |
| QWEN-72B-CHAT (fuegos artificiales.ai) | 3.2 | 3.8 | 45.9 | 50.0 | 38.8 | 117.0 | 63.0 |
| Yi: 34b chat | 43.9 | 41.3 | 45.6 | 50.0 | 30.5 | 45.0 | 34.0 |
| Mistral: 7B-InNSTRUCT-V0.2-Q6_K | 21.7 | 20.9 | 45.4 | 50.0 | 31.3 | 44.0 | 23.0 |
| Mistral: 7B-InNSTRUCT-V0.2-Q4_0 | 12.4 | 12.3 | 44.3 | 50.0 | 30.6 | 75.0 | 32.0 |
| Mistral: 7B-InNSTRUCT-V0.2-Q4_K_M | 15.6 | 15.1 | 42.6 | 50.0 | 28.6 | 71.0 | 23.0 |
| Codellama: 34B-InNSTRUCT-Q4_K_M | 7.5 | 6.8 | 39.7 | 50.0 | 36.1 | 127.0 | 35.0 |
| Codellama: 70B-InNSTRUCT-Q4_K_M | 16.3 | 13.8 | 36.4 | 0.0 | 41.2 | 179.0 | 58.0 |
| Solar: 10.7b-Instuct-V1-Q4_K_M | 18.8 | 17.7 | 35.2 | 50.0 | 31.1 | 107.0 | 10.0 |
| Mistral: 7B-InNSTRUCT-Q4_K_M | 13.9 | 13.0 | 34.8 | 50.0 | 26.5 | 80.0 | 0.0 |
| Codellama: 70B-Instructo-Q2_K | 11.2 | 9.4 | 29.8 | 0.0 | 37.7 | 198.0 | 29.0 |
| Llama2 | 17.1 | 16.3 | 26.5 | 25.0 | 26.5 | 131.0 | 0.0 |
| GEMMA: 7B-INSTRUCT-Q6_K | 20.9 | 22.1 | 25.9 | 25.0 | 25.2 | 147.0 | 2.0 |
| ORCA2: 13B | 20.1 | 18.3 | 23.1 | 0.0 | 30.6 | 166.0 | 11.0 |
| stablelm-zephyr | 9.9 | 7.7 | 15.4 | 0.0 | 23.5 | 192.0 | 1.0 |
| Dolphin-Phi: 2.7B-V2.6-Q6_K | 8.9 | 8.4 | 14.9 | 0.0 | 22.9 | 188.0 | 0.0 |
| Codellama: 13b-Python | 12.5 | 10.7 | 12.8 | 0.0 | 22.1 | 155.0 | 0.0 |
| PHI: 2.7B-CHAT-V2-Q6_K | 13.0 | 11.6 | 8.9 | 0.0 | 19.4 | 222.0 | 0.0 |
Misma información, pero como gráfico de barras:
Y con una barra separada para cada plantilla de inmediato: 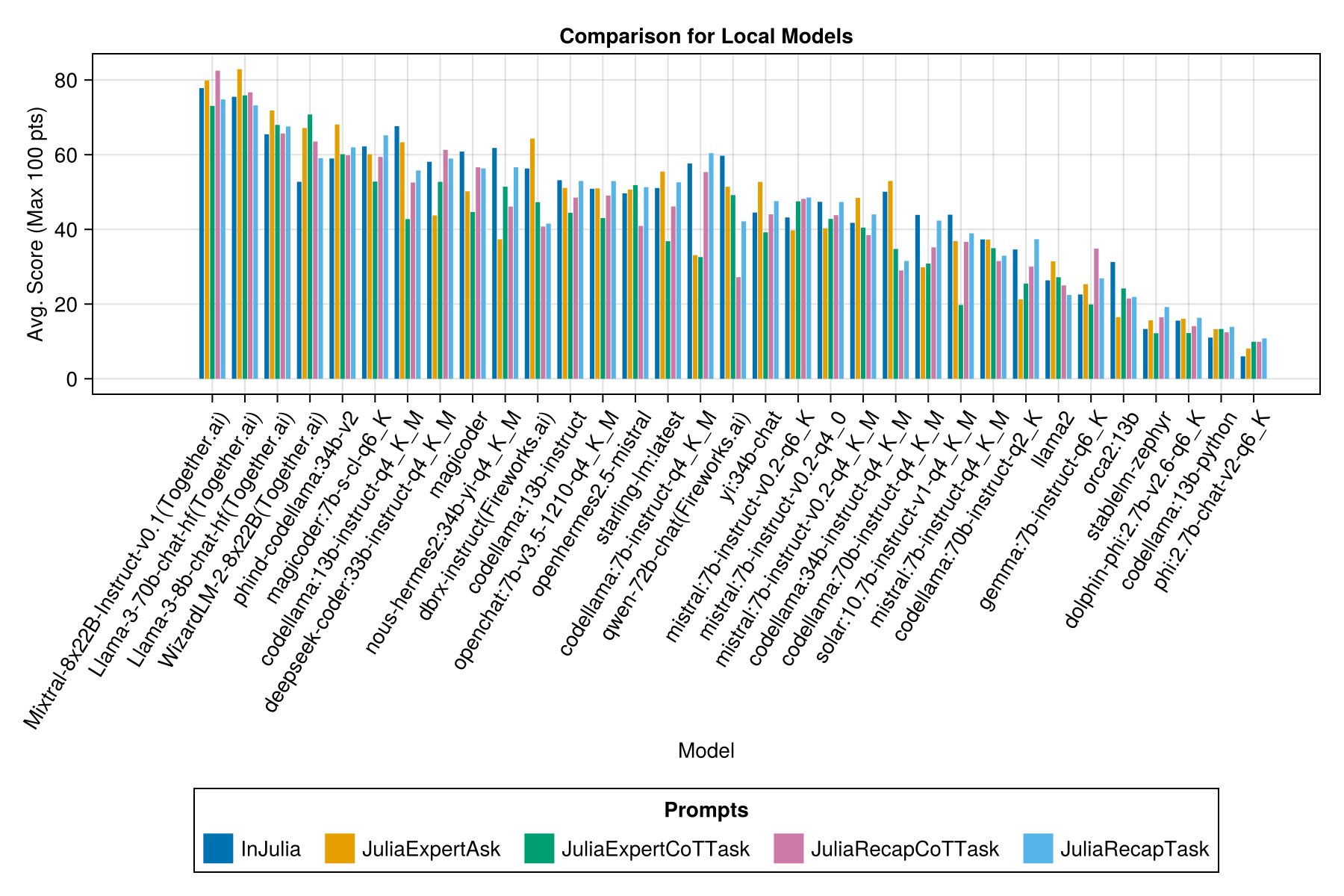
Nota
Los modelos QWEN-1.5 se han eliminado de las descripciones general, ya que el modelo subyacente en el repositorio de Ollama (y HF) no es correcto y tiene un rendimiento muy bajo.
Nota
He notado que algunas evals en Ollama/Llama.cpp ahora obtienen un puntaje ligeramente más alto ahora que en diciembre de 23, por lo que está en una hoja de ruta para volver a ejecutar las Evals anteriores.
Claramente, la victoria de las API pagadas (el último lanzamiento: GPT-3.5-TURBO-106), pero esa no es toda la historia.
Esperamos poder proporcionar una orientación sobre las estrategias de incorporación, por ejemplo, ¿cuándo es mejor usar una plantilla de inmediato "Juliaexpert*" frente a "en Julia, Respuesta XYZ".
Aprends hasta ahora:
| Plantilla de inmediato | Transcurrido (s, promedio) | Transcurrido (S, mediana) | Avg. Puntuación (máximo 100 pts) | Puntaje mediano (máximo 100 pts) |
|---|---|---|---|---|
| Injulia | 14.0 | 9.6 | 55.2 | 50.0 |
| Juliaexpertak | 9.9 | 6.4 | 53.8 | 50.0 |
| Juliarecaptask | 16.7 | 11.5 | 52.0 | 50.0 |
| Juliaexpertcottask | 15.4 | 10.4 | 49.5 | 50.0 |
| Juliarecapcottask | 16.1 | 11.3 | 48.6 | 50.0 |
Nota: Las plantillas basadas en XML se prueban solo para los modelos Claude 3 (Haiku y Sonnet), por eso las eliminamos de la comparación.
Haga su propio análisis con examples/summarize_results.jl !
scripts/code_gen_benchmark.jl para ver el ejemplo de evaluaciones anteriores. ¿Quieres ejecutar algunos experimentos y guardar los resultados? ¡Mira examples/experiment_hyperparameter_scan.jl !
¿Quieres revisar algunas de las corridas de referencia pasadas? Consulte examples/summarize_results.jl para ver las estadísticas y examples/debugging_results.jl para revisar las conversaciones individuales/respuestas del modelo.
Para contribuir con un caso de prueba:
code_generation/category/test_case_name/definition.toml .code_generation/category/test case/model/evaluation__PROMPT__STRATEGY__TIMESTAMP.json y code_generation/category/test case/model/conversation__PROMPT__STRATEGY__TIMESTAMP.jsondefinition.toml Campos requeridos en definition.toml incluye:
my_function(1, 2) ).@test X = Z .Hay varios campos opcionales:
Los campos anteriores pueden mejorar la reutilización del código en los ejemplos/pruebas unitarias.
Vea un ejemplo en examples/create_definition.jl . Puede validar las definiciones de su caso de prueba con validate_definition() .
Por favor, PR y agregue cualquier conversación relevante y en su mayoría correcta con/in/sobre Julia en la carpeta julia_conversations/ .
El objetivo es tener una colección de conversaciones que sean útiles para el conocimiento de Julia Fineting en modelos más pequeños.
Valoramos altamente aportes de la comunidad. Si tiene sugerencias o ideas para mejorar, abra un problema. ¡Todas las contribuciones son bienvenidas!


