hallucination leaderboard
1.0.0
使用Vectara的Hughes幻覺評估模型計算的公共LLM排行榜。這評估了LLM總結文檔時引入幻覺的頻率。我們計劃隨著模型和LLM的更新,定期更新此信息。
另外,請隨時在擁抱臉上查看我們的幻覺排行榜。
該排行榜中的排名是使用HHEM-2.1幻覺評估模型計算的。如果您對基於HHEM-1.0的以前的排行榜感興趣,則可以在此處使用
 | 為了記憶西蒙·馬克·休斯(Simon Mark Hughes)... |
最後一次更新於2024年11月6日
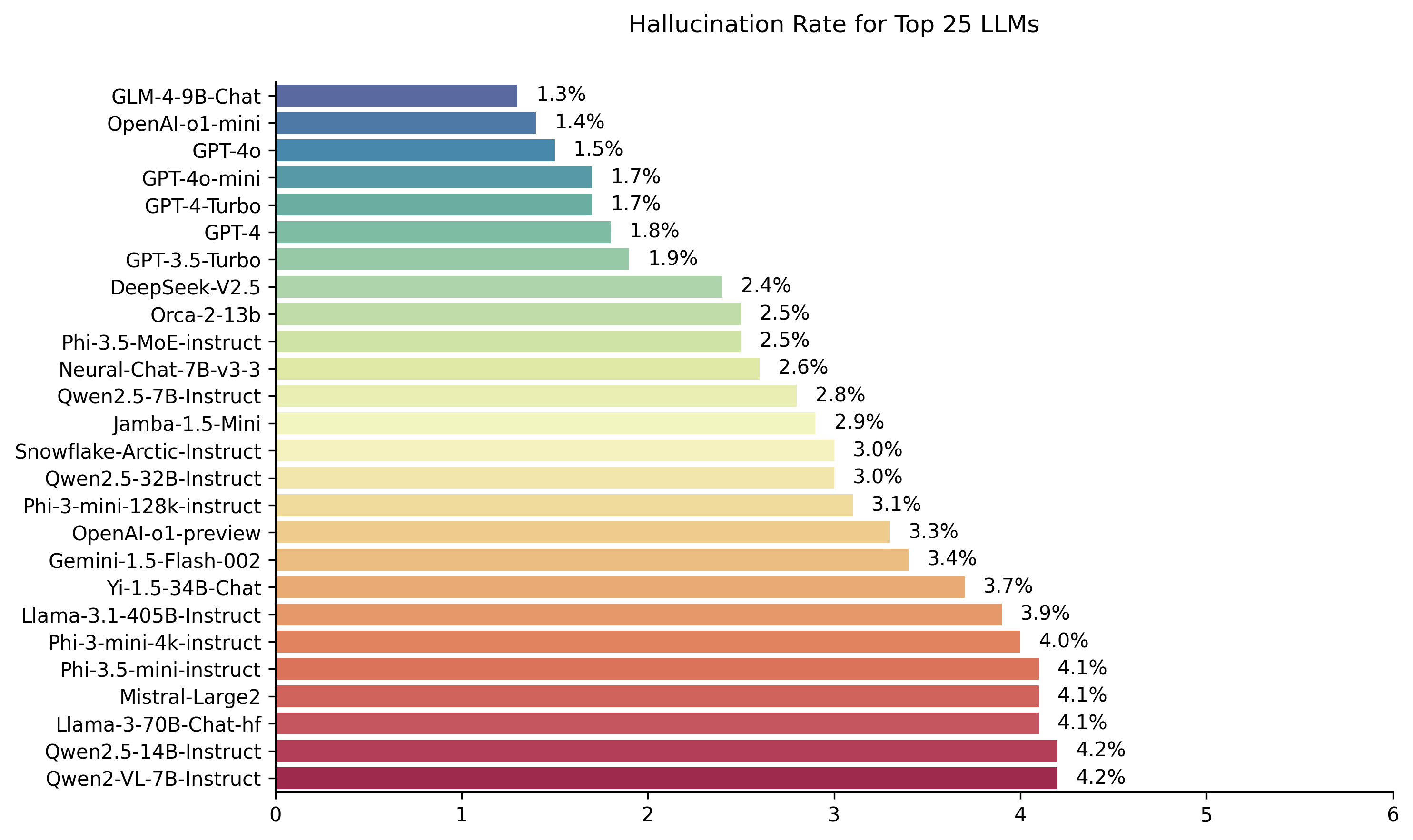
| 模型 | 幻覺率 | 事實一致性率 | 答案率 | 平均摘要長度(單詞) |
|---|---|---|---|---|
| Zhipu ai glm-4-9b-chat | 1.3% | 98.7% | 100.0% | 58.1 |
| Openai-O1-Mini | 1.4% | 98.6% | 100.0% | 78.3 |
| GPT-4O | 1.5% | 98.5% | 100.0% | 77.8 |
| GPT-4O-Mini | 1.7% | 98.3% | 100.0% | 76.3 |
| GPT-4-turbo | 1.7% | 98.3% | 100.0% | 86.2 |
| GPT-4 | 1.8% | 98.2% | 100.0% | 81.1 |
| GPT-3.5-Turbo | 1.9% | 98.1% | 99.6% | 84.1 |
| DeepSeek-V2.5 | 2.4% | 97.6% | 100.0% | 83.2 |
| Microsoft Orca-2-13b | 2.5% | 97.5% | 100.0% | 66.2 |
| Microsoft Phi-3.5-Moe-Instruct | 2.5% | 97.5% | 96.3% | 69.7 |
| 英特爾神經chat-7b-v3-3 | 2.6% | 97.4% | 100.0% | 60.7 |
| QWEN2.5-7B-INSTRUCT | 2.8% | 97.2% | 100.0% | 71.0 |
| AI21 jamba-1.5米尼 | 2.9% | 97.1% | 95.6% | 74.5 |
| 雪花北極教堂 | 3.0% | 97.0% | 100.0% | 68.7 |
| QWEN2.5-32B-INSTRUCT | 3.0% | 97.0% | 100.0% | 67.9 |
| Microsoft PHI-3-MINI-128K教學 | 3.1% | 96.9% | 100.0% | 60.1 |
| OpenAi-O1-preiview | 3.3% | 96.7% | 100.0% | 119.3 |
| Google Gemini-1.5-Flash-002 | 3.4% | 96.6% | 99.9% | 59.4 |
| 01-ai yi-1.5-34b-chat | 3.7% | 96.3% | 100.0% | 83.7 |
| Llama-3.1-405b-Instruct | 3.9% | 96.1% | 99.6% | 85.7 |
| Microsoft PHI-3-MINI-4K教學 | 4.0% | 96.0% | 100.0% | 86.8 |
| Microsoft Phi-3.5-Mini Instruct | 4.1% | 95.9% | 100.0% | 75.0 |
| Mistral-large2 | 4.1% | 95.9% | 100.0% | 77.4 |
| Llama-3-70B-Chat-HF | 4.1% | 95.9% | 99.2% | 68.5 |
| QWEN2-VL-7B-INSTRUCT | 4.2% | 95.8% | 100.0% | 73.9 |
| QWEN2.5-14B教學 | 4.2% | 95.8% | 100.0% | 74.8 |
| QWEN2.5-72B-INSTRUCT | 4.3% | 95.7% | 100.0% | 80.0 |
| Llama-3.2-90b-Vision-Instruct | 4.3% | 95.7% | 100.0% | 79.8 |
| Xai Grok | 4.6% | 95.4% | 100.0% | 91.0 |
| 人類Claude-3-5-Sonnet | 4.6% | 95.4% | 100.0% | 95.9 |
| QWEN2-72B-INSTRUCT | 4.7% | 95.3% | 100.0% | 100.1 |
| Mixtral-8x22b-instruct-v0.1 | 4.7% | 95.3% | 99.9% | 92.0 |
| 人類Claude-3-5-Haiku | 4.9% | 95.1% | 100.0% | 92.9 |
| 01-ai yi-1.5-9b-chat | 4.9% | 95.1% | 100.0% | 85.7 |
| cohere command-r | 4.9% | 95.1% | 100.0% | 68.7 |
| Llama-3.1-70B教學 | 5.0% | 95.0% | 100.0% | 79.6 |
| Llama-3.1-8B教學 | 5.4% | 94.6% | 100.0% | 71.0 |
| cohere Command-R-Plus | 5.4% | 94.6% | 100.0% | 68.4 |
| Llama-3.2-11b-Vision-Instruct | 5.5% | 94.5% | 100.0% | 67.3 |
| Llama-2-70B-Chat-HF | 5.9% | 94.1% | 99.9% | 84.9 |
| IBM Granite-3.0-8B教學 | 6.5% | 93.5% | 100.0% | 74.2 |
| Google Gemini-1.5-Pro-002 | 6.6% | 93.7% | 99.9% | 62.0 |
| Google Gemini-1.5-Flash | 6.6% | 93.4% | 99.9% | 63.3 |
| Microsoft PHI-2 | 6.7% | 93.3% | 91.5% | 80.8 |
| Google Gemma-2-2b-it | 7.0% | 93.0% | 100.0% | 62.2 |
| QWEN2.5-3B-INSTRUCT | 7.0% | 93.0% | 100.0% | 70.4 |
| Llama-3-8B-Chat-HF | 7.4% | 92.6% | 99.8% | 79.7 |
| Google Gemini-Pro | 7.7% | 92.3% | 98.4% | 89.5 |
| 01-ai yi-1.5-6b-chat | 7.9% | 92.1% | 100.0% | 98.9 |
| Llama-3.2-3b-Instruct | 7.9% | 92.1% | 100.0% | 72.2 |
| Databricks DBRX-Instruct | 8.3% | 91.7% | 100.0% | 85.9 |
| qwen2-vl-2b-instruct | 8.3% | 91.7% | 100.0% | 81.8 |
| cohere aya擴展32b | 8.5% | 91.5% | 99.9% | 81.9 |
| IBM Granite-3.0-2b-thiminct | 8.8% | 91.2% | 100.0% | 81.6 |
| MISTRAL-7B-INSTRUCT-V0.3 | 9.5% | 90.5% | 100.0% | 98.4 |
| Google Gemini-1.5-Pro | 9.1% | 90.9% | 99.8% | 61.6 |
| 人類Claude-3-opus | 10.1% | 89.9% | 95.5% | 92.1 |
| Google Gemma-2-9b-it | 10.1% | 89.9% | 100.0% | 70.2 |
| Llama-2-13b-chat-hf | 10.5% | 89.5% | 99.8% | 82.1 |
| Mistral-Nemo-Instruct | 11.2% | 88.8% | 100.0% | 69.9 |
| Llama-2-7b-chat-hf | 11.3% | 88.7% | 99.6% | 119.9 |
| Microsoft Wizardlm-2-8x22b | 11.7% | 88.3% | 99.9% | 140.8 |
| cohere aya擴展8b | 12.2% | 87.8% | 99.9% | 83.9 |
| 亞馬遜泰坦表達 | 13.5% | 86.5% | 99.5% | 98.4 |
| Google Palm-2 | 14.1% | 85.9% | 99.8% | 86.6 |
| Google Gemma-7b-it | 14.8% | 85.2% | 100.0% | 113.0 |
| QWEN2.5-1.5B-INSTRUCT | 15.8% | 84.2% | 100.0% | 70.7 |
| 人類Claude-3-sonnet | 16.3% | 83.7% | 100.0% | 108.5 |
| Google Gemma-1.1-7b-it | 17.0% | 83.0% | 100.0% | 64.3 |
| 擬人化的克勞德-2 | 17.4% | 82.6% | 99.3% | 87.5 |
| Google flan-t5大 | 18.3% | 81.7% | 99.3% | 20.9 |
| Mixtral-8x7b-instruct-v0.1 | 20.1% | 79.9% | 99.9% | 90.7 |
| Llama-3.2-1b-Instruct | 20.7% | 79.3% | 100.0% | 71.5 |
| Apple OpenElm-3B教學 | 24.8% | 75.2% | 99.3% | 47.2 |
| QWEN2.5-0.5B-INSTRUCT | 25.2% | 74.8% | 100.0% | 72.6 |
| Google Gemma-1.1-2b-it | 27.8% | 72.2% | 100.0% | 66.8 |
| TII Falcon-7b-Instruct | 29.9% | 70.1% | 90.0% | 75.5 |
該排行榜使用Vectara的商業幻覺評估模型HHEM-2.1來計算LLM排名。您可以在擁抱臉和Kaggle上找到該型號的開源變體HHEM-2.1-OPEN。
有關我們用於評估模型的生成摘要,請參見此數據集。
在這一領域已經做了許多先前的工作。有關該領域的一些高級論文(摘要中的事實一致性),請參見:
有關非常全面的列表,請參閱此處-https://github.com/edinburghnlp/awesome-hallacination-detection。下一節中描述的方法使用這些論文中建立的協議,以及其他許多論文。
有關此模型中的工作的詳細說明,請參閱我們有關發行版的博客文章:Cut the Bull…。在大語言模型中檢測幻覺。
為了確定此排行榜,我們使用了從事實一致性研究中的各種開源數據集中培訓了一個模型來檢測LLM輸出中的幻覺。然後,我們使用與最佳最佳模型競爭的模型,然後通過其公共API向上方的每個LLM餵了1000個簡短文檔,並要求他們總結每個簡短文檔,僅使用文檔中介紹的事實。在這1000個文檔中,每個模型只匯總了831個文件,其余文檔由於內容限製而被至少一個模型拒絕。然後,使用這些831個文檔,我們計算了每個模型的總體事實一致性率(無幻覺)和幻覺率(100-精度)。 “答案率”列中詳細介紹了每個模型拒絕響應提示的速率。發送給模型的內容都不包含非法或“不安全的工作”內容,但是觸發單詞的當下足以觸發某些內容過濾器。這些文件主要來自CNN / Daily Mail語料庫。調用LLM時,我們使用的溫度為0 。
我們評估匯總的事實一致性率,而不是總體事實準確性,因為它使我們可以比較模型對所提供信息的響應。換句話說,是與源文檔“事實一致”提供的摘要。對於任何臨時問題,確定幻覺是不可能做的,因為不確定每個LLM都經過了哪些數據。此外,擁有一個可以確定任何響應是否在沒有參考源的情況下幻覺的模型就需要解決幻覺問題,並且大概比評估這些LLM大的模型訓練模型。因此,我們選擇在摘要任務中查看幻覺速度,因為這是一個很好的模擬,以確定模型的整體方式。此外,LLM越來越多地用於抹布(檢索增強生成)管道中,以回答用戶查詢,例如Bing Chat和Google的聊天集成。在抹布系統中,該模型正在作為搜索結果的摘要部署,因此該排行榜也是在抹布系統中使用的模型準確性的良好指標。
您是一個使用數據回答問題的聊天機器人。您必須堅持僅由所提供的段落中的文本提供的答案。詢問您的問題“提供了以下段落的簡明摘要,涵蓋了所描述的核心信息。” <通道>'
調用API時,然後將<vassage>令牌替換為源文檔(請參閱此數據集中的“源”列)。
以下是集成模型及其特定端點的詳細概述:
gpt-3.5-turbo訪問,特別是通過chat.completions.create Endpoint訪問。gpt-4集成。gpt-4-turbo-2024-04-09使用,與OpenAI的文檔一致。gpt-4o訪問。gpt-4o-mini訪問。o1-mini訪問。o1-preview訪問meta-llama/Llama-2-xxb-chat-hf這些不同尺寸的這些型號,其中XXB可以為每種型號的容量量身定制xxb為7b , 13b和70b 。chat端點訪問,並使用型號meta-llama/Llama-3-xxB-chat-hf ,其中xxB可以為8B和70B 。Meta-Llama-3.1-405B-Instruct通過複製的API訪問模型meta/meta-llama-3.1-405b-instruct 。meta-llama/Llama-3.2-3B-Instruct-Turbo Meta-Llama-3.2-3B-Instruct -Instruct-turbo通過AI chat端點訪問Meta-Lalama-3.2-3b-Instruct。Llama-3.2-11B-Vision-Instruct和Llama-3.2-90B-Vision-Instruct使用AI chat端點訪問,使用meta-llama/Llama-3.2-11B-Vision-Instruct-Turbo和meta-llama/Llama-3.2-90B-Vision-Instruct-Turbo 。command-r-08-2024和/chat Endpoint使用。command-r-plus-08-2024和/chat Endpoint使用。c4ai-aya-expanse-8b和c4ai-aya-expanse-32b訪問。有關Cohere模型的更多信息,請參閱其網站。claude-2.0進行API調用調用模型。claude-3-opus-20240229用於API調用,調用了模型。claude-3-sonnet-20240229進行API調用,調用了該模型。claude-3-5-sonnet-20241022調用API調用的模型。claude-3-5-haiku-20241022調用模型,以進行API調用。mistralai/Mixtral-8x22B-Instruct-v0.1和chat端點的模型通過AI的API訪問。mistral-large-latest模型通過Mistral AI的API訪問。text-bison-001模型實施。gemini-pro模型已合併用於增強語言處理,可在Vertex AI上訪問。gemini-1.5-pro-001訪問。gemini-1.5-flash-001訪問。gemini-1.5-pro-002訪問。gemini-1.5-flash-002訪問。要深入了解每個模型的版本和生命週期,尤其是Google提供的版本,請參閱頂點AI上的模型版本和生命週期。
amazon.titan-text-express-v1的Amazon Bedrock上訪問。microsoft/WizardLM-2-8x22B和chat端點通過AI的API一起訪問。databricks/dbrx-instruct和chat Endpoint通過AI的API訪問。snowflake/snowflake-arctic-instruct通過Replicate的API訪問。chat端點與模型名稱Qwen/Qwen2-72B-Instruct一起使用。deepseek-chat模型和chat端點通過DeepSeek的API訪問。grok-beta和chat/completions端點通過XAI的API訪問。 qu。您為什麼使用模型來評估模型?
回答我們選擇通過人類評估來做到這一點的原因有很多。儘管我們可能會進行大量的人類規模評估,但這是一次性的事情,但它並不能以使我們能夠隨著新API的到線或更新模型的更新而不斷更新排行榜的方式進行擴展。我們在一個快速移動的字段中工作,因此任何此類過程都將在發布後立即脫離數據。其次,我們想要一個可重複的過程,我們可以與他人共享,以便他們可以將其用作評估自己的模型時使用的許多LLM質量分數之一。通過人類註釋過程,這是不可能的,在該過程中,唯一可以共享的東西是過程和人類標籤。還值得指出的是,建立用於檢測幻覺的模型要比建立從未產生幻覺的生成模型要容易得多。只要幻覺評估模型與人類評估者的判斷高度相關,它就可以成為人類法官的良好代理。由於我們專門針對摘要,而不是一般的“封閉式書籍”問題回答,因此我們訓練的LLM不需要記住大量的人類知識,因此它只需要對其支持的語言有牢固的掌握和理解(目前只是英語,但我們計劃隨著時間的推移擴展語言覆蓋範圍)即可。
qu。如果LLM拒絕總結文檔或提供一個或兩個單詞答案該怎麼辦?
回答我們明確過濾這些。有關更多信息,請參見我們的博客文章。您可以在排行榜上看到“答案率”列,以指示摘要的文檔百分比,以及詳細說明摘要長度的“平均摘要長度”列,表明我們對大多數文檔沒有很短的答案。
qu。您使用了哪種版本的XYZ?
答案請參見API詳細信息部分,以獲取有關所使用的型號版本及其所調用的詳細信息,以及排行榜最後更新的日期。如果您需要更多的清晰度,請與我們聯繫(在存儲庫中創建問題)。
qu。 Xai的Grok LLM呢?
當前的答案(截至2023年11月14日)無法公開使用,我們無法訪問。我懷疑那些有早期訪問的人可能是法律上禁止在模型上進行這種評估的。一旦通過公共API獲得該模型,我們將考慮添加它,以及其他足夠受歡迎的LLM。
qu。模型不能僅通過提供答案或很短的答案來得分100%嗎?
答案我們明確過濾了每個模型中的此類響應,僅對所有模型提供摘要的文檔進行最終評估。您可以在我們有關該主題的博客文章中找到更多技術細節。另請參見上表中的“答案率”和“平均摘要長度”列。
qu。在此任務上的原始摘要分數(0幻覺)中,是否會復制和粘貼的提取性摘要模型?
從定義上講,絕對回答這種模型不會具有幻覺,並提供忠實的摘要。我們沒有聲稱正在評估摘要質量,這是一項獨立且正交的任務,應獨立評估。正如我們在博客文章中指出的那樣,我們沒有評估摘要的質量,而是僅評估它們的事實一致性。
qu。這似乎是一個非常可黑的度量標準,因為您可以將原始文本複制為摘要
回答。確實如此,但我們沒有在這種方法上評估任意模型,例如在Kaggle競爭中。任何這樣做的模型都會在您關心的任何其他任務中表現不佳。因此,我認為這是質量指標,您將與您對模型的其他評估一起運行,例如摘要質量,答案的準確性等。但是我們不建議將其用作獨立公制。所選模型均未對我們的模型的輸出進行培訓。這可能會在將來發生,但是當我們計劃更新模型和源文檔時,這是一個活著的排行榜,這將是不太可能發生的。但是,這也是任何LLM基準測試的問題。我們還應該指出,這基於許多其他學者發明和完善該協議的事實一致性的大量工作。請參閱我們對本博客文章中的摘要和真實論文的引用,以及這種出色的資源彙編-https://github.com/edinburghnlp/awesome-hallacination-detection,以閱讀更多信息。
qu。這並不能明確地衡量模型幻覺的所有方式
回答。同意。我們沒有聲稱解決了幻覺檢測的問題,併計劃進一步擴展和增強這一過程。但是我們確實認為這是朝著正確方向朝著正確的方向發展的舉動,並提供了一個急需的起點,每個人都可以建立在上面。
qu。一些模型只能在總結時幻覺。您難道不能只是提供眾所周知的事實列表,並檢查它能回想起它們嗎?
回答。在我看來,這將是一個糟糕的考驗。一方面,除非您訓練了模型,否則您不知道經過培訓的數據,因此您不能確定該模型將其響應紮根於其所看到的真實數據或是否在猜測中。此外,“眾所周知”沒有明確的定義,並且這些類型的數據通常很容易使大多數模型準確回憶。在我公認的主觀經驗中,大多數幻覺都來自獲取很少已知或討論的信息的模型,或者該模型看到了相互矛盾的信息。在不知道該模型的源數據的情況下,再次無法驗證這些幻覺,因為您不知道哪個數據符合此標準。我還認為,該模型不太可能在總結時幻覺。我們要求模型以仍然忠於來源的方式獲取信息並轉換信息。除了摘要之外,這類似於許多生成任務(例如,寫一封涵蓋這些要點的電子郵件...),如果模型偏離了提示,那麼這是未能遵循說明,表明該模型也會在其他指令上掙扎以下任務。
qu。這是一個不錯的開端,但遠非確定的
回答。我完全同意。還有很多需要做的事情,問題尚未解決。但是,“良好的開始”意味著希望在這方面開始取得進展,並且通過開放採購模型,我們希望讓社區將其提升到一個新的水平。


