hallucination leaderboard
1.0.0
Public LLM Leadorboard محسوبة باستخدام نموذج تقييم الهلوسة Hughes Hughes. هذا يقيم عدد المرات التي تقدم فيها LLM الهلوسة عند تلخيص وثيقة. نخطط لتحديث هذا بانتظام مع تحديث طرازنا و LLMS مع مرور الوقت.
أيضا ، لا تتردد في التحقق من المتصدرين في هلوسة الهلوسة على وجه المعانقة.
يتم حساب التصنيفات في هذا المتصدرين باستخدام نموذج تقييم الهلوس HHEM-2.1. إذا كنت مهتمًا بالمتصدرين السابقون ، الذي كان يعتمد على HHEM-1.0 ، فهو متوفر هنا
 | في ذكرى محبة لسيمون مارك هيوز ... |
آخر تحديث في 6 نوفمبر 2024
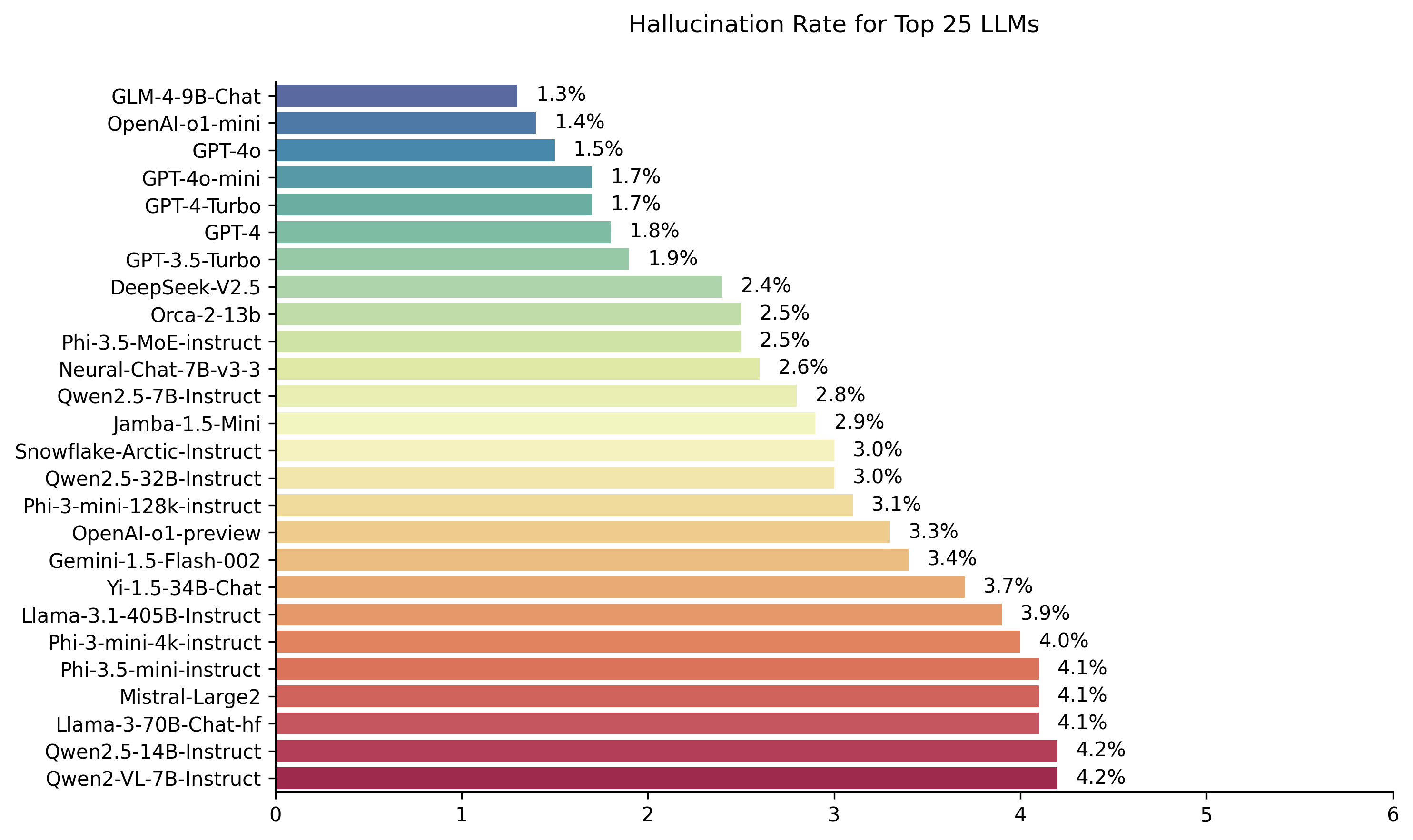
| نموذج | معدل الهلوسة | معدل الاتساق الواقعية | معدل الإجابة | متوسط طول الملخص (الكلمات) |
|---|---|---|---|---|
| ZHIPU AI GLM-4-9B-Chat | 1.3 ٪ | 98.7 ٪ | 100.0 ٪ | 58.1 |
| Openai-O1-Mini | 1.4 ٪ | 98.6 ٪ | 100.0 ٪ | 78.3 |
| GPT-4O | 1.5 ٪ | 98.5 ٪ | 100.0 ٪ | 77.8 |
| GPT-4O-MINI | 1.7 ٪ | 98.3 ٪ | 100.0 ٪ | 76.3 |
| GPT-4 توربو | 1.7 ٪ | 98.3 ٪ | 100.0 ٪ | 86.2 |
| GPT-4 | 1.8 ٪ | 98.2 ٪ | 100.0 ٪ | 81.1 |
| GPT-3.5 توربو | 1.9 ٪ | 98.1 ٪ | 99.6 ٪ | 84.1 |
| Deepseek-V2.5 | 2.4 ٪ | 97.6 ٪ | 100.0 ٪ | 83.2 |
| Microsoft ORCA-2-13B | 2.5 ٪ | 97.5 ٪ | 100.0 ٪ | 66.2 |
| Microsoft PHI-3.5-Moe-instruct | 2.5 ٪ | 97.5 ٪ | 96.3 ٪ | 69.7 |
| Intel Neural-Chat-7B-V3-3 | 2.6 ٪ | 97.4 ٪ | 100.0 ٪ | 60.7 |
| Qwen2.5-7b-instruct | 2.8 ٪ | 97.2 ٪ | 100.0 ٪ | 71.0 |
| AI21 Jamba-1.5-Mini | 2.9 ٪ | 97.1 ٪ | 95.6 ٪ | 74.5 |
| ثلج ندفة الثلج-القطب الأسلحة | 3.0 ٪ | 97.0 ٪ | 100.0 ٪ | 68.7 |
| Qwen2.5-32b-instruct | 3.0 ٪ | 97.0 ٪ | 100.0 ٪ | 67.9 |
| Microsoft PHI-3-MINI-128K-instruct | 3.1 ٪ | 96.9 ٪ | 100.0 ٪ | 60.1 |
| Openai-O1-Preview | 3.3 ٪ | 96.7 ٪ | 100.0 ٪ | 119.3 |
| Google Gemini-1.5-Flash-002 | 3.4 ٪ | 96.6 ٪ | 99.9 ٪ | 59.4 |
| 01-AI YI-1.5-34B-Chat | 3.7 ٪ | 96.3 ٪ | 100.0 ٪ | 83.7 |
| Llama-3.1-405b-instruct | 3.9 ٪ | 96.1 ٪ | 99.6 ٪ | 85.7 |
| Microsoft PHI-3-MINI-4K-instruct | 4.0 ٪ | 96.0 ٪ | 100.0 ٪ | 86.8 |
| Microsoft PHI-3.5-MINI-instruct | 4.1 ٪ | 95.9 ٪ | 100.0 ٪ | 75.0 |
| ميسترا لارجي 2 | 4.1 ٪ | 95.9 ٪ | 100.0 ٪ | 77.4 |
| Llama-3-70b-Chat-Hf | 4.1 ٪ | 95.9 ٪ | 99.2 ٪ | 68.5 |
| Qwen2-VL-7B-instruct | 4.2 ٪ | 95.8 ٪ | 100.0 ٪ | 73.9 |
| QWEN2.5-14B-instruct | 4.2 ٪ | 95.8 ٪ | 100.0 ٪ | 74.8 |
| Qwen2.5-72b-instruct | 4.3 ٪ | 95.7 ٪ | 100.0 ٪ | 80.0 |
| Llama-3.2-90b-vision-instruct | 4.3 ٪ | 95.7 ٪ | 100.0 ٪ | 79.8 |
| Xai Grok | 4.6 ٪ | 95.4 ٪ | 100.0 ٪ | 91.0 |
| أنثروبور كلود -3-5 سونيت | 4.6 ٪ | 95.4 ٪ | 100.0 ٪ | 95.9 |
| Qwen2-72b-instruct | 4.7 ٪ | 95.3 ٪ | 100.0 ٪ | 100.1 |
| mixtral-8x22b-instruct-v0.1 | 4.7 ٪ | 95.3 ٪ | 99.9 ٪ | 92.0 |
| أنثروبور كلود-3-5-هايكو | 4.9 ٪ | 95.1 ٪ | 100.0 ٪ | 92.9 |
| 01-AI YI-1.5-9B-Chat | 4.9 ٪ | 95.1 ٪ | 100.0 ٪ | 85.7 |
| CORELE Command-R | 4.9 ٪ | 95.1 ٪ | 100.0 ٪ | 68.7 |
| llama-3.1-70b-instruct | 5.0 ٪ | 95.0 ٪ | 100.0 ٪ | 79.6 |
| Llama-3.1-8b-instruct | 5.4 ٪ | 94.6 ٪ | 100.0 ٪ | 71.0 |
| COREME Command-R-Plus | 5.4 ٪ | 94.6 ٪ | 100.0 ٪ | 68.4 |
| llama-3.2-11b-vision-instruct | 5.5 ٪ | 94.5 ٪ | 100.0 ٪ | 67.3 |
| LLAMA-2-70B-Chat-HF | 5.9 ٪ | 94.1 ٪ | 99.9 ٪ | 84.9 |
| IBM Granite-3.0-8b-instruct | 6.5 ٪ | 93.5 ٪ | 100.0 ٪ | 74.2 |
| Google Gemini-1.5-Pro-002 | 6.6 ٪ | 93.7 ٪ | 99.9 ٪ | 62.0 |
| Google Gemini-1.5-Flash | 6.6 ٪ | 93.4 ٪ | 99.9 ٪ | 63.3 |
| Microsoft PHI-2 | 6.7 ٪ | 93.3 ٪ | 91.5 ٪ | 80.8 |
| Google GEMMA-2-2B-IT | 7.0 ٪ | 93.0 ٪ | 100.0 ٪ | 62.2 |
| Qwen2.5-3b-instruct | 7.0 ٪ | 93.0 ٪ | 100.0 ٪ | 70.4 |
| Llama-3-8b-Chat-Hf | 7.4 ٪ | 92.6 ٪ | 99.8 ٪ | 79.7 |
| Google Gemini-Pro | 7.7 ٪ | 92.3 ٪ | 98.4 ٪ | 89.5 |
| 01-AI YI-1.5-6B-Chat | 7.9 ٪ | 92.1 ٪ | 100.0 ٪ | 98.9 |
| Llama-3.2-3b-instruct | 7.9 ٪ | 92.1 ٪ | 100.0 ٪ | 72.2 |
| Databricks dbrx-instruct | 8.3 ٪ | 91.7 ٪ | 100.0 ٪ | 85.9 |
| Qwen2-VL-2B-instruct | 8.3 ٪ | 91.7 ٪ | 100.0 ٪ | 81.8 |
| Cohere Aya Expanse 32b | 8.5 ٪ | 91.5 ٪ | 99.9 ٪ | 81.9 |
| IBM Granite-3.0-2b-instruct | 8.8 ٪ | 91.2 ٪ | 100.0 ٪ | 81.6 |
| MISTRAL-7B-instruct-V0.3 | 9.5 ٪ | 90.5 ٪ | 100.0 ٪ | 98.4 |
| Google Gemini-1.5-Pro | 9.1 ٪ | 90.9 ٪ | 99.8 ٪ | 61.6 |
| الإنسان كلود 3-opus | 10.1 ٪ | 89.9 ٪ | 95.5 ٪ | 92.1 |
| Google Gemma-2-9b-it | 10.1 ٪ | 89.9 ٪ | 100.0 ٪ | 70.2 |
| Llama-2-13b-Chat-Hf | 10.5 ٪ | 89.5 ٪ | 99.8 ٪ | 82.1 |
| ميسترا نمو | 11.2 ٪ | 88.8 ٪ | 100.0 ٪ | 69.9 |
| Llama-2-7b-Chat-Hf | 11.3 ٪ | 88.7 ٪ | 99.6 ٪ | 119.9 |
| Microsoft Wizardlm-2-8x22b | 11.7 ٪ | 88.3 ٪ | 99.9 ٪ | 140.8 |
| Cohere Aya Expanse 8b | 12.2 ٪ | 87.8 ٪ | 99.9 ٪ | 83.9 |
| Amazon Titan-Express | 13.5 ٪ | 86.5 ٪ | 99.5 ٪ | 98.4 |
| Google Palm-2 | 14.1 ٪ | 85.9 ٪ | 99.8 ٪ | 86.6 |
| Google GEMMA-7B-IT | 14.8 ٪ | 85.2 ٪ | 100.0 ٪ | 113.0 |
| Qwen2.5-1.5b-instruct | 15.8 ٪ | 84.2 ٪ | 100.0 ٪ | 70.7 |
| أنثروبور كلود-3 سونيت | 16.3 ٪ | 83.7 ٪ | 100.0 ٪ | 108.5 |
| Google Gemma-1.1-7b-it | 17.0 ٪ | 83.0 ٪ | 100.0 ٪ | 64.3 |
| الإنسان كلود -2 | 17.4 ٪ | 82.6 ٪ | 99.3 ٪ | 87.5 |
| Google Flan-T5-Large | 18.3 ٪ | 81.7 ٪ | 99.3 ٪ | 20.9 |
| mixtral-8x7b-instruct-v0.1 | 20.1 ٪ | 79.9 ٪ | 99.9 ٪ | 90.7 |
| Llama-3.2-1b-instruct | 20.7 ٪ | 79.3 ٪ | 100.0 ٪ | 71.5 |
| Apple Openelm-3B-instruct | 24.8 ٪ | 75.2 ٪ | 99.3 ٪ | 47.2 |
| Qwen2.5-0.5b-instruct | 25.2 ٪ | 74.8 ٪ | 100.0 ٪ | 72.6 |
| Google Gemma-1.1-2b-it | 27.8 ٪ | 72.2 ٪ | 100.0 ٪ | 66.8 |
| Tii Falcon-7B-instruct | 29.9 ٪ | 70.1 ٪ | 90.0 ٪ | 75.5 |
يستخدم هذا اللوحة المتصدرين HHEM-2.1 ، نموذج تقييم الهلوسة التجاري لـ Vectara ، لحساب تصنيفات LLM. يمكنك العثور على متغير مفتوح المصدر من هذا النموذج ، HHEM-2.1 مفتوح على الوجه المعانقة و Kaggle.
راجع مجموعة البيانات هذه للملخصات التي استخدمناها لتقييم النماذج.
تم القيام بالكثير من العمل السابق في هذا المجال. لبعض من أفضل الأوراق في هذا المجال (الاتساق الواقعية في التلخيص) يرجى الاطلاع هنا:
للحصول على قائمة شاملة للغاية ، يرجى الاطلاع هنا-https://github.com/edinburghnlp/awesome-hallucination-nection. تستخدم الأساليب الموضحة في القسم التالي بروتوكولاتها المنشأة في تلك الأوراق ، من بين العديد من الآخرين.
للحصول على شرح مفصل للعمل الذي دخل في هذا النموذج ، يرجى الرجوع إلى منشور المدونة الخاص بنا على الإصدار: Cut the Bull…. اكتشاف الهلوسة في نماذج اللغة الكبيرة.
لتحديد هذه اللوحة المتصدرين ، قمنا بتدريب نموذج للكشف عن الهلوسة في مخرجات LLM ، باستخدام مجموعات بيانات مفتوحة المصدر المختلفة من أبحاث الاتساق الواقعية إلى نماذج تلخيص. باستخدام نموذج تنافسي مع أفضل النماذج الفنية ، قمنا بعد ذلك بتغذية 1000 وثيقة قصيرة لكل من LLMs أعلاه عبر واجهات برمجة التطبيقات العامة الخاصة بهم وطلب منهم تلخيص كل مستند قصير ، باستخدام الحقائق الواردة فقط في المستند. من بين هذه الوثائق 1000 ، تم تلخيص 831 مستندًا فقط بواسطة كل نموذج ، تم رفض المستندات المتبقية بواسطة نموذج واحد على الأقل بسبب قيود المحتوى. باستخدام هذه الوثائق 831 ، قمنا بعد ذلك بحساب معدل الاتساق الواقعي الكلي (بدون هلوسة) ومعدل الهلوسة (100 - دقة) لكل نموذج. يتم تفصيل المعدل الذي يرفض فيه كل نموذج للرد على المطالبة في عمود "معدل الإجابة". لم يحتوي أي من المحتوى المرسلة إلى النماذج على محتوى غير مشروع أو "غير آمن للعمل" ، لكن حاضر كلمات الزناد كان كافياً لإحداث بعض مرشحات المحتوى. تم أخذ الوثائق في المقام الأول من CNN / Daily Mail Corpus. استخدمنا درجة حرارة 0 عند استدعاء LLMS.
نقوم بتقييم معدل الاتساق الواقعية لتلخيص بدلاً من الدقة الواقعية الشاملة لأنه يسمح لنا بمقارنة استجابة النموذج للمعلومات المقدمة. بمعنى آخر ، هل الملخص المقدم "متسقًا في الواقع" مع المستند المصدر. من المستحيل تحديد الهلوسة لأي سؤال مخصص لأنه غير معروف على وجه التحديد البيانات التي يتم تدريبها على كل LLM. بالإضافة إلى ذلك ، يتطلب وجود نموذج يمكن أن يحدد ما إذا كان أي استجابة تم وهلوسًا بدون مصدر مرجعي يتطلب حل مشكلة الهلوسة ويفترض أن يتدرب على نموذج كبير أو أكبر من هذه LLMs التي يتم تقييمها. لذلك اخترنا بدلاً من ذلك أن ننظر إلى معدل الهلوسة ضمن مهمة التلخيص لأن هذا تناظرية جيدة لتحديد مدى صدق النماذج بشكل عام. بالإضافة إلى ذلك ، يتم استخدام LLMs بشكل متزايد في خطوط الأنابيب RAG (الجيل المعزز للاسترجاع) للإجابة على استعلامات المستخدم ، كما هو الحال في Bing Chat و Google Chat Integration. في نظام خرقة ، يتم نشر النموذج كملخص لنتائج البحث ، لذلك يعد هذا اللوحة المتصدرين أيضًا مؤشرًا جيدًا لدقة النماذج عند استخدامها في أنظمة RAG.
أنت روبوت الدردشة الإجابة على الأسئلة باستخدام البيانات. يجب أن تلتزم بالإجابات المقدمة فقط من خلال النص في المقطع المقدم. يتم طرح السؤال "تقديم ملخص موجز للمقطع التالي ، والذي يغطي الأجزاء الأساسية من المعلومات الموضحة." <visper> '
عند استدعاء واجهة برمجة التطبيقات ، تم استبدال الرمز المميز <Sugrs> بمستند المصدر (انظر عمود "المصدر" في مجموعة البيانات هذه).
فيما يلي نظرة عامة مفصلة على النماذج المدمجة ونقاط النهاية المحددة:
gpt-3.5-turbo من خلال مكتبة عميل Python Openai ، وتحديداً عبر chat.completions.create .gpt-4 .gpt-4-turbo-2024-04-09 ، تمشيا مع وثائق Openai.gpt-4o .gpt-4o-mini .o1-mini .o1-previewmeta-llama/Llama-2-xxb-chat-hf ، حيث يمكن أن يكون xxb 7b ، 13b ، و 70b ، مصممة على قدرة كل طراز.chat AI معًا واستخدام النموذج meta-llama/Llama-3-xxB-chat-hf ، حيث يمكن أن يكون xxB 8B و 70B .Meta-Llama-3.1-405B-Instruct عبر واجهة برمجة تطبيقات REPLICATE باستخدام نموذج meta/meta-llama-3.1-405b-instruct .Meta-Llama-3.2-3B-Instruct عبر نقطة نهاية chat AI معًا باستخدام نموذج meta-llama/Llama-3.2-3B-Instruct-Turbo .Llama-3.2-11B-Vision-Instruct و Llama-3.2-90B-Vision-Instruct عبر نقطة نهاية chat من AI باستخدام نموذج meta-llama/Llama-3.2-11B-Vision-Instruct-Turbo meta-llama/Llama-3.2-90B-Vision-Instruct-Turbocommand-r-08-2024 ونقطة نهاية /chat .command-r-plus-08-2024 ونقطة نهاية /chat .c4ai-aya-expanse-8b و c4ai-aya-expanse-32b . لمزيد من المعلومات حول نماذج Cohere ، راجع موقع الويب الخاص بهم.claude-2.0 لمكالمة API.claude-3-opus-20240229 لمكالمة API.claude-3-sonnet-20240229 لمكالمة API.claude-3-5-sonnet-20241022 لمكالمة API.claude-3-5-haiku-20241022 لمكالمة API.mistralai/Mixtral-8x22B-Instruct-v0.1 ونقطة نهاية chat .mistral-large-latest .text-bison-001 ، على التوالي.gemini-pro من Google لمعالجة اللغة المحسّنة ، ويمكن الوصول إليها على Vertex AI.gemini-1.5-pro-001 على Vertex AI.gemini-1.5-flash-001 على Vertex AI.gemini-1.5-pro-002 على Vertex AI.gemini-1.5-flash-002 على Vertex AI.من أجل فهم متعمق لإصدار كل طراز ودورة الحياة ، وخاصة تلك التي تقدمها Google ، يرجى الرجوع إلى إصدارات النماذج ودورات الحياة على Vertex AI.
amazon.titan-text-express-v1 .microsoft/WizardLM-2-8x22B ونقطة نهاية chat .databricks/dbrx-instruct ونقطة نهاية chat .snowflake/snowflake-arctic-instruct .chat معا مع اسم الطراز Qwen/Qwen2-72B-Instruct .deepseek-chat ونقطة نهاية chat .grok-beta ونقطة النهاية chat/completions . Qu. لماذا تستخدم نموذجًا لتقييم نموذج؟
الإجابة هناك عدة أسباب اخترنا القيام بذلك على تقييم إنساني. على الرغم من أننا يمكن أن نحصل على تقييم كبير لتقييم على نطاق بشري كبير ، إلا أنه شيء لمرة واحدة ، إلا أنه لا يتوسع بطريقة تتيح لنا تحديث المتصدرين باستمرار عندما تأتي واجهات برمجة التطبيقات الجديدة عبر الإنترنت أو تحديث النماذج. نحن نعمل في مجال الحركة السريع ، لذا فإن أي عملية من هذا القبيل ستكون خارج البيانات بمجرد نشرها. ثانياً ، أردنا عملية قابلة للتكرار يمكننا مشاركتها مع الآخرين حتى يتمكنوا من استخدامها بأنفسهم كواحد من العديد من درجات جودة LLM التي يستخدمونها عند تقييم النماذج الخاصة بهم. لن يكون هذا ممكنًا من خلال عملية شرح الإنسان ، حيث تكون الأشياء الوحيدة التي يمكن مشاركتها هي العملية والعلامات البشرية. تجدر الإشارة أيضًا إلى أن بناء نموذج للكشف عن الهلوسة أسهل بكثير من بناء نموذج توليدي لا ينتج عن الهلوسة. طالما أن نموذج تقييم الهلوسة يرتبط ارتباطًا وثيقًا بأحكام المقيمين البشريين ، يمكن أن يقف كبديل جيد للقضاة البشريين. نظرًا لأننا نستهدف على وجه التحديد ، لا نحتاج إلى أن يحفظ LLM الذي دربته ، LLM الذي قمنا بتدريبه ، لا يحتاج إلى حفظ نسبة كبيرة من المعرفة الإنسانية ، فهو يحتاج فقط إلى فهم وفهم قوي لللغات التي تدعمها (حاليًا فقط اللغة الإنجليزية ، ولكننا نخطط لتوسيع التغطية اللغوية مع مرور الوقت).
Qu. ماذا لو رفضت LLM تلخيص المستند أو توفر إجابة واحدة أو اثنين من كلمة؟
الإجابة نحن نرشح هذه بشكل صريح. انظر منشور المدونة لدينا لمزيد من المعلومات. يمكنك رؤية عمود "معدل الإجابة" على لوحة المتصدرين التي تشير إلى النسبة المئوية من المستندات الملخصة ، و "متوسط طول الملخص" الذي يوضح أطوال الملخص ، مما يدل على أننا لم نحصل على إجابات قصيرة للغاية لمعظم المستندات.
Qu. ما هو إصدار Model XYZ الذي استخدمته؟
الإجابة يرجى الاطلاع على قسم تفاصيل API للحصول على تفاصيل حول إصدارات النموذج المستخدمة وكيف تم استدعاؤها ، وكذلك تاريخ تحديث المتصدرين آخر مرة. يرجى الاتصال بنا (إنشاء مشكلة في الريبو) إذا كنت بحاجة إلى مزيد من الوضوح.
Qu. ماذا عن Xai's Grok LLM؟
الإجابة حاليًا (اعتبارًا من 11/14/2023) Grok غير متاح للجمهور وليس لدينا وصول. أولئك الذين لديهم وصول مبكر أظن أنهم ربما يحظرون قانونًا من القيام بهذا النوع من التقييم على النموذج. بمجرد توفر النموذج من خلال واجهة برمجة تطبيقات عامة ، سنبحث عن إضافته ، إلى جانب أي LLMs الأخرى التي تحظى بشعبية بدرجة كافية.
Qu. ألا يمكن أن يسجل الطراز 100 ٪ من خلال توفير أي إجابات أو إجابات قصيرة جدًا؟
الإجابة التي قمنا بتصفية هذه الردود بشكل صريح من كل نموذج ، ونقوم بالتقييم النهائي فقط على المستندات التي قدمت جميع النماذج ملخصًا لها. يمكنك معرفة المزيد من التفاصيل الفنية في منشور مدونتنا حول هذا الموضوع. انظر أيضًا "معدل الإجابة" و "متوسط طول الملخص" في الجدول أعلاه.
Qu. ألن لن ينسخ نموذج الملخص الاستخراجي الذي ينسخ فقط من النتيجة الملخص الأصلية بنسبة 100 ٪ (هلوسة 0) في هذه المهمة؟
أجب تمامًا كما هو الحال في التعريف ، لن يكون لهذا النموذج أي هلوسة ويوفر ملخصًا مخلصًا. نحن لا ندعي أنه نقيم جودة التلخيص ، وهي مهمة منفصلة ومتعامدة ، ويجب تقييمها بشكل مستقل. نحن لا نقوم بتقييم جودة الملخصات ، فقط الاتساق الواقعية لها ، كما نشير في منشور المدونة.
Qu. يبدو هذا مقياسًا يمكن اختراقه للغاية ، حيث يمكنك فقط نسخ النص الأصلي كملخص
إجابة. هذا صحيح لكننا لا نقيم النماذج التعسفية حول هذا النهج ، مثل في مسابقة Kaggle. أي نموذج يفعل ذلك سيؤدي أداءً سيئًا في أي مهمة أخرى تهتم بها. لذلك أود أن أعتبر هذا مقياسًا للجودة الذي تقوم بتشغيله جنبًا إلى جنب مع أي تقييمات أخرى لديك لنموذجك ، مثل جودة التلخيص ، ودقة الأسئلة ، وما إلى ذلك ، لكننا لا نوصي باستخدام هذا كمقياس مستقل. لم يتم تدريب أي من النماذج المختارة على ناتج نموذجنا. قد يحدث هذا في المستقبل ، ولكن مع التخطيط لتحديث النموذج وأيضًا المستندات المصدر ، فهذه عبارة عن لاعب رئيسي في المعيشة ، وسيكون هذا أمرًا غير محتمل. ومع ذلك ، فهذا يمثل أيضًا مشكلة مع أي معيار LLM. يجب أن نشير أيضًا إلى أن هذا يعتمد على مجموعة كبيرة من العمل على الاتساق الواقعية حيث اخترع العديد من الأكاديميين الآخرين وصقلهم هذا البروتوكول. راجع مراجعنا إلى Summac و True Papers في منشور المدونة هذا ، وكذلك هذا التجميع الممتاز للموارد-https://github.com/edinburghnlp/awesome-hallucination- الكشف لقراءة المزيد.
Qu. هذا لا يقيس بشكل قاطع جميع الطرق التي يمكن أن يهلوس النموذج
إجابة. متفق. لا ندعي أننا حلل مشكلة اكتشاف الهلوسة ، ونخطط لتوسيع هذه العملية وتعزيزها. لكننا نعتقد أنها خطوة في الاتجاه الصحيح ، وتوفر نقطة انطلاق تشتد الحاجة إليها يمكن للجميع بناءها فوقها.
Qu. يمكن لبعض النماذج الهلوسة فقط أثناء تلخيصها. ألا يمكنك فقط توفير قائمة بالحقائق المعروفة والتحقق من مدى استدعائها؟
إجابة. سيكون ذلك اختبارًا سيئًا في رأيي. لسبب واحد ، ما لم تدرب النموذج الذي لا تعرفه على البيانات التي تم تدريبها ، لذلك لا يمكنك التأكد من أن النموذج يتأثر باستجابته في البيانات الحقيقية التي شاهدتها أو ما إذا كان يخمن. بالإضافة إلى ذلك ، لا يوجد تعريف واضح لـ "معروف جيدًا" ، وعادةً ما تكون هذه الأنواع من البيانات سهلة عادةً على معظم النماذج لتذكرها بدقة. معظم الهلوسة ، في تجربتي الذاتية المعترف بها ، تأتي من معلومات جلب النموذج التي نادراً ما تكون معروفة أو تمت مناقشتها ، أو الحقائق التي شهد النموذج من أجلها معلومات متضاربة. دون معرفة بيانات المصدر التي تم تدريب النموذج عليها ، من المستحيل مرة أخرى التحقق من صحة هذا النوع من الهلوسة لأنك لن تعرف البيانات التي تناسب هذا المعيار. أعتقد أيضًا أنه من غير المحتمل أن يكون النموذج هلوسًا فقط أثناء تلخيصه. نطلب من النموذج أخذ المعلومات وتحويلها بطريقة لا تزال مخلصة للمصدر. هذا مماثل لكثير من المهام التوليدية بصرف النظر عن التلخيص (على سبيل المثال ، اكتب بريدًا إلكترونيًا يغطي هذه النقاط ...) ، وإذا كان النموذج ينحرف عن المطالبة ، فهذا فشل في اتباع التعليمات ، مما يشير إلى أن النموذج سيواجه على تعليمات أخرى بعد المهام أيضًا.
Qu. هذه بداية جيدة ولكنها بعيدة عن النهائي
إجابة. أنا أتفق تماما. هناك الكثير مما يجب القيام به ، والمشكلة بعيدة عن حلها. لكن "بداية جيدة" تعني أن التقدم نأمل أن يبدأ في هذا المجال ، ومن خلال تحديد المصادر النموذجية ، نأمل أن نشرط المجتمع في نقل هذا إلى المستوى التالي.


