hallucination leaderboard
1.0.0
Public LLM Raeperboard calculado utilizando el modelo de evaluación de alucinación Hughes de Vectara. Esto evalúa con qué frecuencia un LLM presenta alucinaciones al resumir un documento. Planeamos actualizar esto regularmente como nuestro modelo y los LLM se actualizan con el tiempo.
Además, siéntase libre de ver nuestra clasificación de alucinaciones sobre la cara abrazada.
Las clasificaciones en esta tabla de clasificación se calculan utilizando el modelo de evaluación de alucinación HHEM-2.1. Si está interesado en la tabla de clasificación anterior, que se basó en HHEM-1.0, está disponible aquí
 | En memoria amorosa de Simon Mark Hughes ... |
Última actualización el 6 de noviembre de 2024
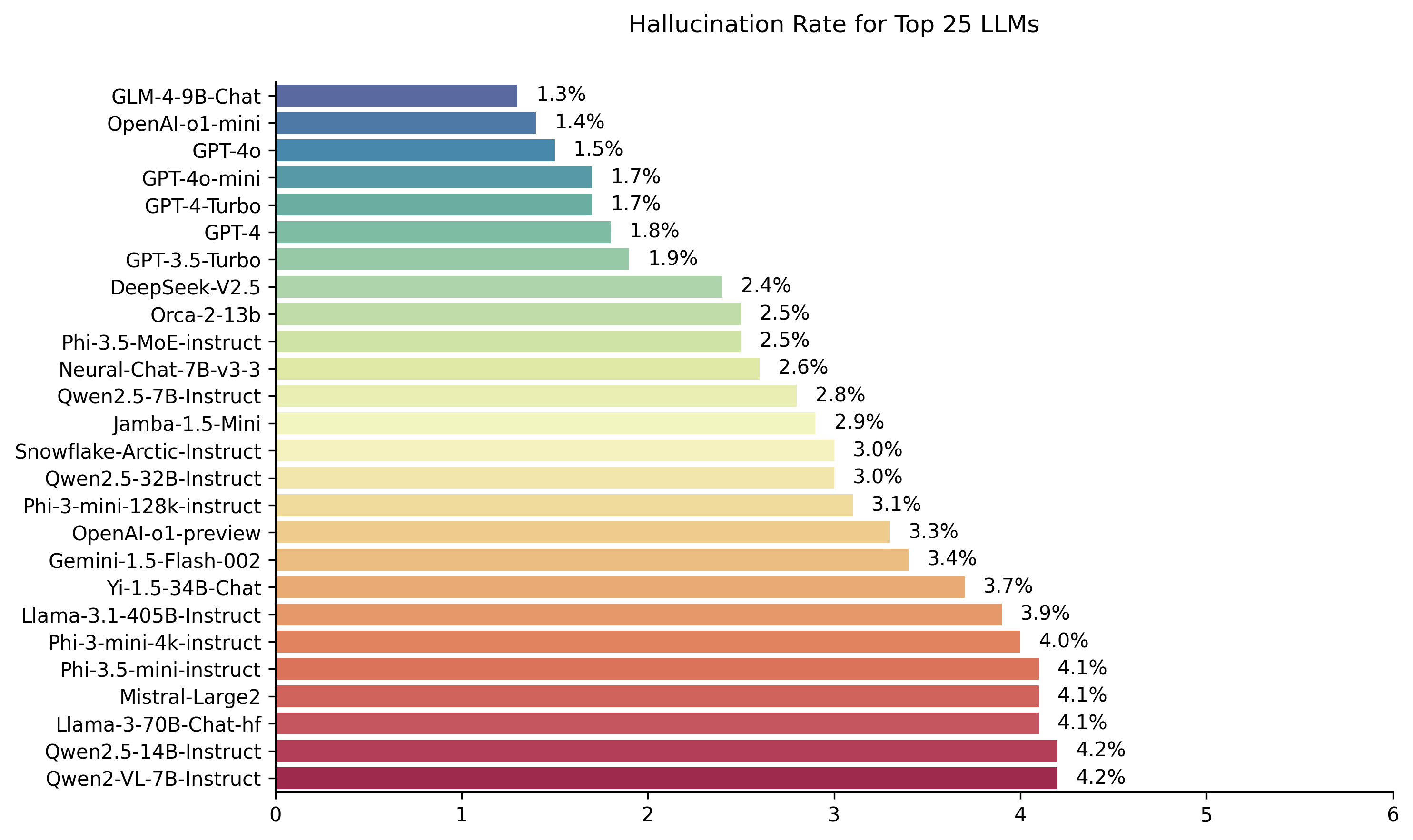
| Modelo | Tasa de alucinación | Tasa de consistencia objetiva | Tasa de respuesta | Longitud de resumen promedio (palabras) |
|---|---|---|---|---|
| Zhipu ai glm-4-9b-chat | 1.3 % | 98.7 % | 100.0 % | 58.1 |
| OpenAi-O1-Mini | 1.4 % | 98.6 % | 100.0 % | 78.3 |
| GPT-4O | 1.5 % | 98.5 % | 100.0 % | 77.8 |
| GPT-4O-Mini | 1.7 % | 98.3 % | 100.0 % | 76.3 |
| GPT-4-TURBO | 1.7 % | 98.3 % | 100.0 % | 86.2 |
| GPT-4 | 1.8 % | 98.2 % | 100.0 % | 81.1 |
| GPT-3.5-TURBO | 1.9 % | 98.1 % | 99.6 % | 84.1 |
| Deepseek-v2.5 | 2.4 % | 97.6 % | 100.0 % | 83.2 |
| Microsoft Orca-2-13b | 2.5 % | 97.5 % | 100.0 % | 66.2 |
| Microsoft Phi-3.5-Moe-Instructo | 2.5 % | 97.5 % | 96.3 % | 69.7 |
| Intel Neural-Chat-7B-V3-3 | 2.6 % | 97.4 % | 100.0 % | 60.7 |
| Qwen2.5-7b-instructo | 2.8 % | 97.2 % | 100.0 % | 71.0 |
| AI21 Jamba-1.5-Mini | 2.9 % | 97.1 % | 95.6 % | 74.5 |
| Insinución de copos de nieve | 3.0 % | 97.0 % | 100.0 % | 68.7 |
| QWEN2.5-32B-INSTRUST | 3.0 % | 97.0 % | 100.0 % | 67.9 |
| Microsoft Phi-3-Mini-128K-Instructo | 3.1 % | 96.9 % | 100.0 % | 60.1 |
| Pregai-o1 previa | 3.3 % | 96.7 % | 100.0 % | 119.3 |
| Google Géminis-1.5-Flash-002 | 3.4 % | 96.6 % | 99.9 % | 59.4 |
| 01-AI yi-1.5-34b-chat | 3.7 % | 96.3 % | 100.0 % | 83.7 |
| Llama-3.1-405b-Instructo | 3.9 % | 96.1 % | 99.6 % | 85.7 |
| Microsoft Phi-3-mini-4K-Instructo | 4.0 % | 96.0 % | 100.0 % | 86.8 |
| Microsoft Phi-3.5 mini-Instructo | 4.1 % | 95.9 % | 100.0 % | 75.0 |
| Mistral-Large2 | 4.1 % | 95.9 % | 100.0 % | 77.4 |
| Llama-3-70B-CHAT-HF | 4.1 % | 95.9 % | 99.2 % | 68.5 |
| QWEN2-VL-7B-INSTRUST | 4.2 % | 95.8 % | 100.0 % | 73.9 |
| Qwen2.5-14b-instructo | 4.2 % | 95.8 % | 100.0 % | 74.8 |
| QWEN2.5-72B-INSTRUST | 4.3 % | 95.7 % | 100.0 % | 80.0 |
| LLAMA-3.2-90B-VISION-INSTRUST | 4.3 % | 95.7 % | 100.0 % | 79.8 |
| Xai Grok | 4.6 % | 95.4 % | 100.0 % | 91.0 |
| Antrópico Claude-3-5-Sonnet | 4.6 % | 95.4 % | 100.0 % | 95.9 |
| QWEN2-72B-INSTRUST | 4.7 % | 95.3 % | 100.0 % | 100.1 |
| Mixtral-8x22b-insiRCUT-V0.1 | 4.7 % | 95.3 % | 99.9 % | 92.0 |
| Antrópico Claude-3-5-Haiku | 4.9 % | 95.1 % | 100.0 % | 92.9 |
| 01-AI yi-1.5-9b-chat | 4.9 % | 95.1 % | 100.0 % | 85.7 |
| Cohere Command-R | 4.9 % | 95.1 % | 100.0 % | 68.7 |
| Llama-3.1-70B-Instructo | 5.0 % | 95.0 % | 100.0 % | 79.6 |
| Llama-3.1-8b-Instructo | 5.4 % | 94.6 % | 100.0 % | 71.0 |
| Cohere Command-R-plus | 5.4 % | 94.6 % | 100.0 % | 68.4 |
| LLAMA-3.2-11B-Visión-Instructo | 5.5 % | 94.5 % | 100.0 % | 67.3 |
| LLAMA-2-70B-CHAT-HF | 5.9 % | 94.1 % | 99.9 % | 84.9 |
| IBM Granite-3.0-8b-Instructo | 6.5 % | 93.5 % | 100.0 % | 74.2 |
| Google Gemini-1.5-Pro-002 | 6.6 % | 93.7 % | 99.9 % | 62.0 |
| Google Géminis-1.5 Flash | 6.6 % | 93.4 % | 99.9 % | 63.3 |
| Microsoft Phi-2 | 6.7 % | 93.3 % | 91.5 % | 80.8 |
| Google GEMMA-2-2B-IT | 7.0 % | 93.0 % | 100.0 % | 62.2 |
| Qwen2.5-3b-instructo | 7.0 % | 93.0 % | 100.0 % | 70.4 |
| LLAMA-3-8B-CHAT-HF | 7.4 % | 92.6 % | 99.8 % | 79.7 |
| Google Gemini-Pro | 7.7 % | 92.3 % | 98.4 % | 89.5 |
| 01-AI yi-1.5-6b-chat | 7.9 % | 92.1 % | 100.0 % | 98.9 |
| Llama-3.2-3b-Instructo | 7.9 % | 92.1 % | 100.0 % | 72.2 |
| Databricks DBRX-Instructo | 8.3 % | 91.7 % | 100.0 % | 85.9 |
| QWEN2-VL-2B-Instructo | 8.3 % | 91.7 % | 100.0 % | 81.8 |
| Cohere Aya Expanse 32B | 8.5 % | 91.5 % | 99.9 % | 81.9 |
| IBM Granite-3.0-2B-Instructo | 8.8 % | 91.2 % | 100.0 % | 81.6 |
| Mistral-7B-Instructo-V0.3 | 9.5 % | 90.5 % | 100.0 % | 98.4 |
| Google Géminis-1.5-Pro | 9.1 % | 90.9 % | 99.8 % | 61.6 |
| Antrópico Claude-3-opus | 10.1 % | 89.9 % | 95.5 % | 92.1 |
| Google Gemma-2-9B-IT | 10.1 % | 89.9 % | 100.0 % | 70.2 |
| Llama-2-13B-CHAT-HF | 10.5 % | 89.5 % | 99.8 % | 82.1 |
| Mistral-Nemo-Instructo | 11.2 % | 88.8 % | 100.0 % | 69.9 |
| LLAMA-2-7B-CHAT-HF | 11.3 % | 88.7 % | 99.6 % | 119.9 |
| Microsoft Wizardlm-2-8x22b | 11.7 % | 88.3 % | 99.9 % | 140.8 |
| Cohere Aya Expanse 8B | 12.2 % | 87.8 % | 99.9 % | 83.9 |
| Amazon Titan-Express | 13.5 % | 86.5 % | 99.5 % | 98.4 |
| Google Palm-2 | 14.1 % | 85.9 % | 99.8 % | 86.6 |
| Google Gemma-7B-IT | 14.8 % | 85.2 % | 100.0 % | 113.0 |
| Qwen2.5-1.5b-instructo | 15.8 % | 84.2 % | 100.0 % | 70.7 |
| Antrópico Claude-3-Sonnet | 16.3 % | 83.7 % | 100.0 % | 108.5 |
| Google Gemma-1.1-7B-IT | 17.0 % | 83.0 % | 100.0 % | 64.3 |
| Antrópico Claude-2 | 17.4 % | 82.6 % | 99.3 % | 87.5 |
| Google Flan-T5-Large | 18.3 % | 81.7 % | 99.3 % | 20.9 |
| Mixtral-8x7b-instructo-v0.1 | 20.1 % | 79.9 % | 99.9 % | 90.7 |
| LLAMA-3.2-1B-INSTRUST | 20.7 % | 79.3 % | 100.0 % | 71.5 |
| Apple OpenELM-3B-Instructo | 24.8 % | 75.2 % | 99.3 % | 47.2 |
| QWEN2.5-0.5B-INSTRUST | 25.2 % | 74.8 % | 100.0 % | 72.6 |
| Google Gemma-1.1-2B-IT | 27.8 % | 72.2 % | 100.0 % | 66.8 |
| Tii Falcon-7b-Instructo | 29.9 % | 70.1 % | 90.0 % | 75.5 |
Esta tabla de clasificación utiliza HHEM-2.1, el modelo de evaluación de alucinación comercial de Vectara, para calcular las clasificaciones LLM. Puede encontrar una variante de código abierto de ese modelo, hhem-2.1-abre en la cara abrazada y kaggle.
Vea este conjunto de datos para los resúmenes generados que utilizamos para evaluar los modelos.
Se ha realizado mucho trabajo previo en esta área. Para algunos de los mejores documentos de esta área (consistencia objetiva en resumen), consulte aquí:
Para una lista muy completa, consulte aquí: https://github.com/edinburhnlp/awesome-hallucination Detection. Los métodos descritos en la siguiente sección usan protocolos establecidos en esos documentos, entre muchos otros.
Para obtener una explicación detallada del trabajo que entró en este modelo, consulte nuestra publicación de blog sobre el comunicado: Cortar el toro ... Detección de alucinaciones en modelos de idiomas grandes.
Para determinar esta tabla de clasificación, capacitamos un modelo para detectar alucinaciones en las salidas de LLM, utilizando varios conjuntos de datos de código abierto de la investigación de consistencia objetiva en los modelos de resumen. Utilizando un modelo que sea competitivo con los mejores modelos de última generación, luego alimentamos 1000 documentos cortos a cada uno de los LLM anteriores a través de sus API públicas y les pedimos que resumieran cada documento corto, utilizando solo los hechos presentados en el documento. De estos 1000 documentos, solo 831 documentos fueron resumidos por cada modelo, los documentos restantes fueron rechazados por al menos un modelo debido a restricciones de contenido. Usando estos 831 documentos, calculamos la tasa general de consistencia de hechos (sin alucinaciones) y la tasa de alucinación (100 precisión) para cada modelo. La tasa a la que cada modelo se niega a responder a la solicitud se detalla en la columna de 'tasa de respuesta'. Ninguno de los contenidos enviados a los modelos contenía contenido ilícito o "no seguro para el trabajo", pero el presente de las palabras de activación fue suficiente para activar algunos de los filtros de contenido. Los documentos se tomaron principalmente del CNN / Daily Mail Corpus. Usamos una temperatura de 0 cuando llamamos a los LLM.
Evaluamos la tasa de consistencia objetiva de resumen en lugar de la precisión objetiva general porque nos permite comparar la respuesta del modelo con la información proporcionada. En otras palabras, es el resumen proporcionado 'fácticamente consistente' con el documento fuente. Determinar alucinaciones es imposible de hacer para cualquier pregunta ad hoc, ya que no se sabe con precisión en qué datos se capacita cada LLM. Además, tener un modelo que pueda determinar si alguna respuesta fue alucinada sin una fuente de referencia requiere resolver el problema de alucinación y presumiblemente capacitar un modelo tan grande o más grande que estos LLM que se evalúan. Por lo tanto, elegimos observar la tasa de alucinación dentro de la tarea de resumen, ya que este es un buen análogo para determinar cuán veraz son los modelos en general. Además, los LLM se utilizan cada vez más en las tuberías de RAG (generación aumentada de recuperación) para responder consultas de los usuarios, como en el chat de Bing y la integración de chat de Google. En un sistema de RAG, el modelo se está implementando como un resumen de los resultados de búsqueda, por lo que esta tabla de clasificación también es un buen indicador para la precisión de los modelos cuando se usa en los sistemas RAG.
Usted es un bot de chat respondiendo preguntas utilizando datos. Debe cumplir con las respuestas proporcionadas únicamente por el texto en el pasaje proporcionado. Se le hace la pregunta "Proporcione un resumen conciso del siguiente pasaje, que cubre las piezas de información básicas descritas". <gase> '
Al llamar a la API, el token <gase> se reemplazó con el documento de origen (consulte la columna 'fuente' en este conjunto de datos).
A continuación se muestra una descripción detallada de los modelos integrados y sus puntos finales específicos:
gpt-3.5-turbo a través de la Biblioteca de clientes de Python de OpenAi, específicamente a través del punto final chat.completions.create .gpt-4 .gpt-4-turbo-2024-04-09 , en línea con la documentación de OpenAI.gpt-4o .gpt-4o-mini .o1-mini .o1-previewmeta-llama/Llama-2-xxb-chat-hf , donde xxb puede ser 7b , 13b y 70b , adaptado a la capacidad de cada modelo.chat AI juntos y utilizando el modelo meta-llama/Llama-3-xxB-chat-hf , donde xxB puede ser 8B y 70B .Meta-Llama-3.1-405B-Instruct a través de la API de Replicate utilizando el modelo meta/meta-llama-3.1-405b-instruct .Meta-Llama-3.2-3B-Instruct se accede a través del punto final chat AI juntos utilizando el modelo meta-llama/Llama-3.2-3B-Instruct-Turbo .Llama-3.2-11B-Vision-Instruct y Llama-3.2-90B-Vision-Instruct a través del punto final chat AI de AI utilizando el modelo meta-llama/Llama-3.2-11B-Vision-Instruct-Turbo y meta-llama/Llama-3.2-90B-Vision-Instruct-Turbo .command-r-08-2024 y el punto final /chat .command-r-plus-08-2024 y el punto final /chat .c4ai-aya-expanse-8b y c4ai-aya-expanse-32b . Para obtener más información sobre los modelos de Cohere, consulte su sitio web.claude-2.0 para la llamada API.claude-3-opus-20240229 para la llamada API.claude-3-sonnet-20240229 para la llamada API.claude-3-5-sonnet-20241022 para la llamada API.claude-3-5-haiku-20241022 para la llamada API.mistralai/Mixtral-8x22B-Instruct-v0.1 y el punto final chat .mistral-large-latest .text-bison-001 , respectivamente.gemini-pro de Google se incorpora para un mejor procesamiento del lenguaje, accesible en Vertex AI.gemini-1.5-pro-001 en Vertex AI.gemini-1.5-flash-001 en Vertex AI.gemini-1.5-pro-002 en Vertex AI.gemini-1.5-flash-002 en Vertex AI.Para una comprensión profunda de la versión y el ciclo de vida de cada modelo, especialmente los que ofrecen Google, consulte las versiones de modelos y los ciclos de vida en Vertex AI.
amazon.titan-text-express-v1 .microsoft/WizardLM-2-8x22B y el punto final chat .databricks/dbrx-instruct y el punto final chat .snowflake/snowflake-arctic-instruct .chat AI juntos con nombre del modelo Qwen/Qwen2-72B-Instruct .deepseek-chat y el punto final chat .grok-beta y el punto final chat/completions . Quemaría ¿Por qué está utilizando un modelo para evaluar un modelo?
Respuesta Hay varias razones por las que elegimos hacer esto a través de una evaluación humana. Si bien podríamos tener una evaluación de escala humana grande, eso es algo único, no se escala de una manera que nos permite actualizar constantemente la tabla de clasificación a medida que las nuevas API entran en línea o los modelos se actualizan. Trabajamos en un campo de movimiento rápido, por lo que cualquier proceso de este tipo estaría sin datos tan pronto como se publique. En segundo lugar, queríamos un proceso repetible que podamos compartir con otros para que puedan usarlo ellos mismos como uno de los muchos puntajes de calidad de LLM que usan al evaluar sus propios modelos. Esto no sería posible con un proceso de anotación humana, donde las únicas cosas que podrían compartirse son el proceso y las etiquetas humanas. También vale la pena señalar que construir un modelo para detectar alucinaciones es mucho más fácil que construir un modelo generativo que nunca produce alucinaciones. Mientras el modelo de evaluación de alucinación esté altamente correlacionado con los juicios de los evaluadores humanos, puede ser un buen proxy para los jueces humanos. Como estamos específicamente de resumen de alguacería y no una respuesta general de las preguntas del "libro cerrado", la LLM que capacitamos no necesita haber memorizado una gran proporción de conocimientos humanos, solo necesita tener una comprensión sólida y una comprensión de los idiomas que apoya (actualmente solo inglés, pero planeamos expandir la cobertura del idioma con el tiempo).
Quemaría ¿Qué pasa si el LLM se niega a resumir el documento o proporciona una respuesta de una o dos palabras?
Respuesta Los filtramos explícitamente. Vea nuestra publicación de blog para obtener más información. Puede ver la columna de 'tasa de respuestas' en la tabla de clasificación que indica el porcentaje de documentos resumidos, y la columna de 'longitud de resumen promedio' que detalla las longitudes de resumen, lo que demuestra que no obtuvimos respuestas muy cortas para la mayoría de los documentos.
Quemaría ¿Qué versión del modelo XYZ usaste?
Respuesta Por favor, consulte la sección Detalles de la API para obtener detalles sobre las versiones del modelo utilizadas y cómo se llamaron, así como la fecha en que se actualizó la tabla de clasificación. Póngase en contacto con nosotros (cree un problema en el repositorio) si necesita más claridad.
Quemaría ¿Qué hay de Xai's Grok LLM?
La respuesta actualmente (a partir del 14/11/2023) Grok no está disponible públicamente y no tenemos acceso. Aquellos con acceso temprano, sospecho que probablemente tengan prohibido legalmente hacer este tipo de evaluación en el modelo. Una vez que el modelo esté disponible a través de una API pública, buscaremos agregarlo, junto con cualquier otro LLM que sea lo suficientemente popular.
Quemaría ¿No puede un modelo solo anotar un 100% al proporcionar respuestas ni respuestas muy cortas?
Respuesta Filtramos explícitamente tales respuestas de cada modelo, realizando la evaluación final solo en documentos para los que todos los modelos proporcionaron un resumen. Puede encontrar más detalles técnicos en nuestra publicación de blog sobre el tema. Consulte también las columnas 'tasa de respuesta' y 'longitud de resumen promedio' en la tabla anterior.
Quemaría ¿No sería un modelo de resumen extractivo que solo copie y pasea del resumen original puntaje 100% (0 alucinación) en esta tarea?
Responda absolutamente, ya que por definición, tal modelo no tendría alucinaciones y proporcionaría un resumen fiel. No pretendemos evaluar la calidad de resumen, que es una tarea separada y ortogonal , y debemos evaluarse de forma independiente. No estamos evaluando la calidad de los resúmenes, solo la consistencia objetiva de ellos, como señalamos en la publicación del blog.
Quemaría Esta parece una métrica muy hackable, ya que podría copiar el texto original como resumen
Respuesta. Eso es cierto, pero no estamos evaluando modelos arbitrarios en este enfoque, por ejemplo, como en una competencia de Kaggle. Cualquier modelo que lo haga funcionaría mal en cualquier otra tarea que le importe. Por lo tanto, consideraría esto como una métrica de calidad que ejecutaría junto con cualquier otra evaluación que tenga para su modelo, como la calidad de resumen, la precisión de respuesta de preguntas, etc. Pero no recomendamos usar esto como una métrica independiente. Ninguno de los modelos elegidos fue entrenado en la salida de nuestro modelo. Eso puede suceder en el futuro, pero a medida que planeamos actualizar el modelo y también los documentos de origen, por lo que esta es una tabla de clasificación viva, será un hecho poco probable. Sin embargo, eso también es un problema con cualquier punto de referencia de LLM. También debemos señalar que esto se basa en una gran cantidad de trabajo sobre consistencia objetiva donde muchos otros académicos inventaron y refinaron este protocolo. Vea nuestras referencias a los documentos de la Cumbre y Verdadero en esta publicación de blog, así como esta excelente compilación de recursos: https://github.com/edinburhnlp/awesome-hallucination Detection para leer más.
Quemaría Esto no mide definitivamente todas las formas en que un modelo puede alucinar
Respuesta. Acordado. No afirmamos haber resuelto el problema de la detección de alucinación y planeamos expandir y mejorar este proceso aún más. Pero creemos que es un movimiento en la dirección correcta, y proporciona un punto de partida muy necesario que todos puedan construir sobre.
Quemaría Algunos modelos podrían alucinar solo mientras resumen. ¿No podría simplemente proporcionarle una lista de hechos bien conocidos y verificar qué tan bien puede recordarlos?
Respuesta. Esa sería una mala prueba en mi opinión. Por un lado, a menos que haya capacitado el modelo, no conoce los datos en los que fue entrenado, por lo que no puede estar seguro de que el modelo está basado en su respuesta en datos reales que ha visto o si está adivinando. Además, no existe una definición clara de 'bien conocido', y estos tipos de datos suelen ser fáciles de recordar con precisión para la mayoría de los modelos. La mayoría de las alucinaciones, en mi experiencia ciertamente subjetiva, provienen de la información que obtiene el modelo que rara vez se conoce o discuten, o hechos para los cuales el modelo ha visto información contradictoria. Sin conocer los datos de origen en los que se entrenó el modelo, nuevamente es imposible validar este tipo de alucinaciones, ya que no sabrá qué datos se ajustan a este criterio. También creo que es poco probable que el modelo solo se alucine mientras resume. Estamos pidiendo al modelo que tome información y la transforme de una manera que aún sea fiel a la fuente. Esto es análogo a muchas tareas generativas, además del resumen (por ejemplo, escriba un correo electrónico que cubra estos puntos ...), y si el modelo se desvía de la solicitud, entonces eso es un fracaso para seguir las instrucciones, lo que indica que el modelo lucharía en otras tareas de instrucciones también.
Quemaría Este es un buen comienzo pero lejos de ser definitivo
Respuesta. Estoy totalmente de acuerdo. Hay mucho más por hacer, y el problema está lejos de ser resuelto. Pero un "buen comienzo" significa que, con suerte, el progreso comenzará a hacerse en esta área, y al abre el modelo, esperamos involucrar a la comunidad para que lleve esto al siguiente nivel.


