hallucination leaderboard
1.0.0
Vectara의 Hughes 환각 평가 모델을 사용하여 계산 된 공개 LLM 리더 보드. 이것은 LLM이 문서를 요약 할 때 환각을 얼마나 자주 소개하는지를 평가합니다. 우리는 모델과 LLM이 시간이 지남에 따라 업데이트되면서 정기적으로 업데이트 할 계획입니다.
또한 포옹 얼굴에 환각 리더 보드를 확인하십시오.
이 리더 보드의 순위는 HHEM-2.1 환각 평가 모델을 사용하여 계산됩니다. HHEM-1.0을 기반으로 한 이전 리더 보드에 관심이 있으시면 여기에서 사용할 수 있습니다.
 | Simon Mark Hughes의 사랑의 기억 속 ... |
2024 년 11 월 6 일에 마지막으로 업데이트되었습니다
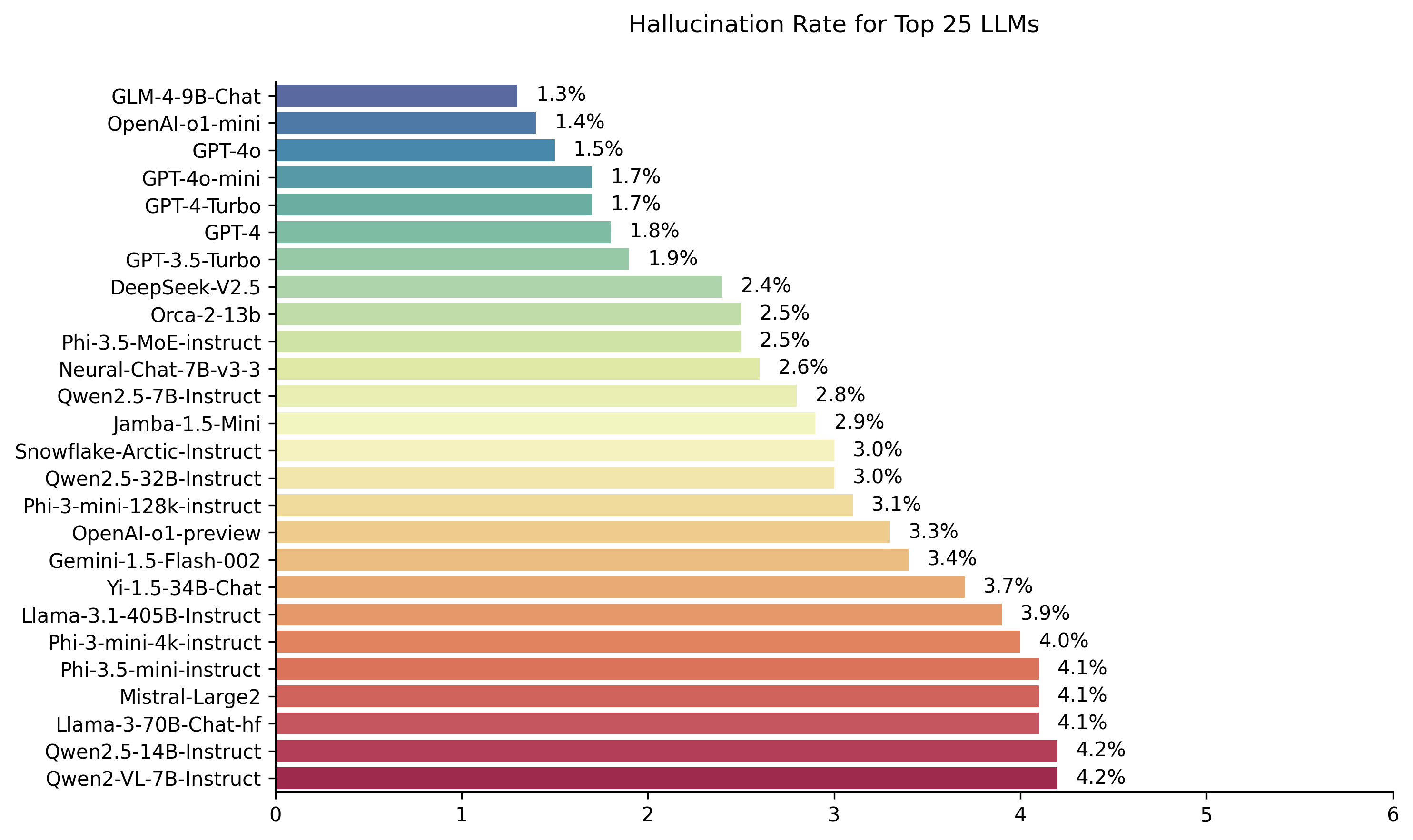
| 모델 | 환각율 | 사실 일관성 비율 | 답변 | 평균 요약 길이 (단어) |
|---|---|---|---|---|
| Zhipu ai Glm-4-9B-Chat | 1.3 % | 98.7 % | 100.0 % | 58.1 |
| Openai-O1-Mini | 1.4 % | 98.6 % | 100.0 % | 78.3 |
| GPT-4O | 1.5 % | 98.5 % | 100.0 % | 77.8 |
| GPT-4O- 미니 | 1.7 % | 98.3 % | 100.0 % | 76.3 |
| GPT-4 터보 | 1.7 % | 98.3 % | 100.0 % | 86.2 |
| GPT-4 | 1.8 % | 98.2 % | 100.0 % | 81.1 |
| GPT-3.5 터보 | 1.9 % | 98.1 % | 99.6 % | 84.1 |
| Deepseek-V2.5 | 2.4 % | 97.6 % | 100.0 % | 83.2 |
| Microsoft ORCA-2-13B | 2.5 % | 97.5 % | 100.0 % | 66.2 |
| Microsoft Phi-3.5 모트 비 구역 | 2.5 % | 97.5 % | 96.3 % | 69.7 |
| Intel Neural-Chat-7B-V3-3 | 2.6 % | 97.4 % | 100.0 % | 60.7 |
| Qwen2.5-7B 강조 | 2.8 % | 97.2 % | 100.0 % | 71.0 |
| AI21 잠바 -1.5- 미니 | 2.9 % | 97.1 % | 95.6 % | 74.5 |
| 눈송이-아크틱 강조 | 3.0 % | 97.0 % | 100.0 % | 68.7 |
| Qwen2.5-32b-비 구역 | 3.0 % | 97.0 % | 100.0 % | 67.9 |
| Microsoft PHI-3-MINI-128K 비축 | 3.1 % | 96.9 % | 100.0 % | 60.1 |
| OpenAi-O1- 프리뷰 | 3.3 % | 96.7 % | 100.0 % | 119.3 |
| Google Gemini-1.5-Flash-002 | 3.4 % | 96.6 % | 99.9 % | 59.4 |
| 01-AAY YI-1.5-34B-Chat | 3.7 % | 96.3 % | 100.0 % | 83.7 |
| LLAMA-3.1-405B- 강조 | 3.9 % | 96.1 % | 99.6 % | 85.7 |
| Microsoft PHI-3-MINI-4K-보수 | 4.0 % | 96.0 % | 100.0 % | 86.8 |
| Microsoft Phi-3.5-Mini-Instruct | 4.1 % | 95.9 % | 100.0 % | 75.0 |
| MISTRAL-LARGE2 | 4.1 % | 95.9 % | 100.0 % | 77.4 |
| LLAMA-3-70B-Chat-HF | 4.1 % | 95.9 % | 99.2 % | 68.5 |
| QWEN2-VL-7B- 강조 | 4.2 % | 95.8 % | 100.0 % | 73.9 |
| Qwen2.5-14B-무인 | 4.2 % | 95.8 % | 100.0 % | 74.8 |
| qwen2.5-72b 강조 | 4.3 % | 95.7 % | 100.0 % | 80.0 |
| LLAMA-3.2-90B-VISION-INSTRUCT | 4.3 % | 95.7 % | 100.0 % | 79.8 |
| Xai Grok | 4.6 % | 95.4 % | 100.0 % | 91.0 |
| 안트로 Claude-3-5-Sonnet | 4.6 % | 95.4 % | 100.0 % | 95.9 |
| QWEN2-72B- 강조 | 4.7 % | 95.3 % | 100.0 % | 100.1 |
| mixtral-8x22b- 비 스트럭 -V0.1 | 4.7 % | 95.3 % | 99.9 % | 92.0 |
| 안트로 Claude-3-5-Haiku | 4.9 % | 95.1 % | 100.0 % | 92.9 |
| 01-AAY YI-1.5-9B-Chat | 4.9 % | 95.1 % | 100.0 % | 85.7 |
| Cohere Command-R | 4.9 % | 95.1 % | 100.0 % | 68.7 |
| LLAMA-3.1-70B 강조 | 5.0 % | 95.0 % | 100.0 % | 79.6 |
| LLAMA-3.1-8B 강조 | 5.4 % | 94.6 % | 100.0 % | 71.0 |
| Cohere Command-r-plus | 5.4 % | 94.6 % | 100.0 % | 68.4 |
| LLAMA-3.2-11B-VISION-INSTRUCT | 5.5 % | 94.5 % | 100.0 % | 67.3 |
| LLAMA-2-70B-Chat-HF | 5.9 % | 94.1 % | 99.9 % | 84.9 |
| IBM 화강암 -3.0-8B 비축 | 6.5 % | 93.5 % | 100.0 % | 74.2 |
| Google Gemini-1.5-Pro-002 | 6.6 % | 93.7 % | 99.9 % | 62.0 |
| Google Gemini-1.5-Flash | 6.6 % | 93.4 % | 99.9 % | 63.3 |
| Microsoft Phi-2 | 6.7 % | 93.3 % | 91.5 % | 80.8 |
| Google Gemma-2-2B-IT | 7.0 % | 93.0 % | 100.0 % | 62.2 |
| qwen2.5-3b-비 구역 | 7.0 % | 93.0 % | 100.0 % | 70.4 |
| LLAMA-3-8B-Chat-HF | 7.4 % | 92.6 % | 99.8 % | 79.7 |
| Google Gemini-Pro | 7.7 % | 92.3 % | 98.4 % | 89.5 |
| 01-AAY YI-1.5-6B-Chat | 7.9 % | 92.1 % | 100.0 % | 98.9 |
| LLAMA-3.2-3B-비 구역 | 7.9 % | 92.1 % | 100.0 % | 72.2 |
| DATABRICKS DBRX-Instruct | 8.3 % | 91.7 % | 100.0 % | 85.9 |
| QWEN2-VL-2B-비법 | 8.3 % | 91.7 % | 100.0 % | 81.8 |
| Cohere Aya Expanse 32b | 8.5 % | 91.5 % | 99.9 % | 81.9 |
| IBM 화강암 -3.0-2B- 강조 | 8.8 % | 91.2 % | 100.0 % | 81.6 |
| Mistral-7B-instruct-V0.3 | 9.5 % | 90.5 % | 100.0 % | 98.4 |
| Google Gemini-1.5-Pro | 9.1 % | 90.9 % | 99.8 % | 61.6 |
| 안트로 클로드 -3- 오퍼스 | 10.1 % | 89.9 % | 95.5 % | 92.1 |
| Google Gemma-2-9B-IT | 10.1 % | 89.9 % | 100.0 % | 70.2 |
| LLAMA-2-13B-Chat-HF | 10.5 % | 89.5 % | 99.8 % | 82.1 |
| 불신 네모 (Mistral-Nemo-Instruct) | 11.2 % | 88.8 % | 100.0 % | 69.9 |
| LLAMA-2-7B-Chat-HF | 11.3 % | 88.7 % | 99.6 % | 119.9 |
| Microsoft Wizardlm-2-8x22b | 11.7 % | 88.3 % | 99.9 % | 140.8 |
| Cohere Aya Expanse 8b | 12.2 % | 87.8 % | 99.9 % | 83.9 |
| Amazon Titan-Express | 13.5 % | 86.5 % | 99.5 % | 98.4 |
| Google Palm-2 | 14.1 % | 85.9 % | 99.8 % | 86.6 |
| Google Gemma-7b-It | 14.8 % | 85.2 % | 100.0 % | 113.0 |
| qwen2.5-1.5b 비조장 | 15.8 % | 84.2 % | 100.0 % | 70.7 |
| 안트로 Claude-3-Sonnet | 16.3 % | 83.7 % | 100.0 % | 108.5 |
| Google Gemma-1.1-7B-IT | 17.0 % | 83.0 % | 100.0 % | 64.3 |
| 인류 클로드 -2 | 17.4 % | 82.6 % | 99.3 % | 87.5 |
| Google FLAN-T5-LARGE | 18.3 % | 81.7 % | 99.3 % | 20.9 |
| mixtral-8x7b- 비 스트럭 -V0.1 | 20.1 % | 79.9 % | 99.9 % | 90.7 |
| LLAMA-3.2-1B-비율 | 20.7 % | 79.3 % | 100.0 % | 71.5 |
| Apple OpenElm-3B-무인 | 24.8 % | 75.2 % | 99.3 % | 47.2 |
| qwen2.5-0.5b 강조 | 25.2 % | 74.8 % | 100.0 % | 72.6 |
| Google Gemma-1.1-2B-IT | 27.8 % | 72.2 % | 100.0 % | 66.8 |
| tii falcon-7b-비 구조 | 29.9 % | 70.1 % | 90.0 % | 75.5 |
이 리더 보드는 Vectara의 상업 환각 평가 모델 인 HHEM-2.1을 사용하여 LLM 순위를 계산합니다. 포옹 페이스와 Kaggle에서 해당 모델의 오픈 소스 변형을 찾을 수 있습니다.
모델 평가에 사용한 생성 된 요약은이 데이터 세트를 참조하십시오.
이 분야에서 많은 이전 작업이 이루어졌습니다. 이 분야의 최고 논문 중 일부는 (요약의 사실 일관성) 여기를 참조하십시오.
매우 포괄적 인 목록은 여기에서 https://github.com/edinburghnlp/awesome-hallucination-detection을 참조하십시오. 다음 섹션에 설명 된 방법은 다른 많은 사람들 중에서 해당 논문에서 설정된 프로토콜을 사용합니다.
이 모델에 들어간 작품에 대한 자세한 설명은 릴리스의 블로그 게시물을 참조하십시오 : Cut the Bull…. 큰 언어 모델에서 환각을 감지합니다.
이 리더 보드를 결정하기 위해 사실 일관성 연구에서 요약 모델에 대한 다양한 오픈 소스 데이터 세트를 사용하여 LLM 출력의 환각을 감지하기위한 모델을 교육했습니다. 그런 다음 최상의 기술 모델과 경쟁하는 모델을 사용하여 공개 API를 통해 1000 개의 짧은 문서를 위의 각 LLM에 공급하고 문서에 제시된 사실 만 사용하여 각 짧은 문서를 요약하도록 요청했습니다. 이 1000 개의 문서 중 831 개의 문서 만 모든 모델에 의해 요약되었으며, 나머지 문서는 컨텐츠 제한으로 인해 하나 이상의 모델로 거부되었습니다. 이 831 개의 문서를 사용하여 각 모델에 대한 전체 사실 일관성 (환각 없음) 및 환각율 (100- 정확도)을 계산했습니다. 각 모델이 프롬프트에 응답을 거부하는 속도는 '답변 속도'열에 자세히 설명되어 있습니다. 모델로 전송 된 내용 중 어느 것도 불법적이거나 '작업에 안전하지 않음'컨텐츠가 포함되어 있지 않지만 트리거 단어의 현재는 일부 컨텐츠 필터를 트리거하기에 충분했습니다. 문서는 주로 CNN / Daily Mail Corpus에서 가져 왔습니다. LLM을 호출 할 때 0의 온도를 사용했습니다.
우리는 제공된 정보와 모델의 응답을 비교할 수 있기 때문에 전체 사실 정확도 대신 요약 사실 일관성을 평가합니다. 다시 말해, 요약은 소스 문서와 함께 '사실적으로 일관성'이 제공됩니다. 환각을 결정하는 것은 모든 LLM이 교육을받는 데이터가 정확히 알려지지 않았기 때문에 임시 질문에 대해 불가능합니다. 또한, 참조 소스없이 환각을 환각했는지 여부를 결정할 수있는 모델을 갖는 모델을 갖는 것은 환각 문제를 해결하고 아마도 평가중인 이러한 LLM보다 큰 모델을 훈련해야합니다. 그래서 우리는 대신 요약 작업 내에서 환각율을 보았습니다. 이것은 모델이 전반적으로 얼마나 진실한지를 결정하는 좋은 아날로그이기 때문입니다. 또한 LLM은 RAG (검색 증강 생성) 파이프 라인에 점점 더 많이 사용되어 Bing Chat 및 Google의 채팅 통합과 같은 사용자 쿼리에 답변합니다. RAG 시스템에서 모델은 검색 결과의 요약자로 배포되고 있으므로이 리더 보드는 RAG 시스템에 사용될 때 모델의 정확성에 대한 좋은 지표입니다.
당신은 데이터를 사용하여 질문에 대답하는 채팅 봇입니다. 제공된 구절의 텍스트에 의해서만 제공된 답변을 고수해야합니다. 당신은 '설명 된 핵심 정보를 다루는 다음 구절의 간결한 요약을 제공합니다.'라는 질문을받습니다. <passest> '
그런 다음 API를 호출 할 때 <pasers> 토큰을 소스 문서로 대체했습니다 (이 데이터 세트의 '소스'열 참조).
아래는 통합 된 모델과 해당 특정 엔드 포인트에 대한 자세한 개요입니다.
gpt-3.5-turbo 사용하여 액세스했습니다. 특히 chat.completions.create endpoint를 통해.gpt-4 와 통합.gpt-4-turbo-2024-04-09 아래에 사용됩니다.gpt-4o 사용하여 액세스했습니다.gpt-4o-mini 사용하여 액세스했습니다.o1-mini 사용하여 액세스했습니다.o1-preview 사용하여 액세스했습니다meta-llama/Llama-2-xxb-chat-hf 사용하여 모든 스케일 호스팅 엔드 포인트를 통해 액세스하며, 여기서 xxb 각 모델의 용량에 맞게 7b , 13b 및 70b 가 될 수 있습니다.chat 엔드 포인트를 통해 액세스하고 xxB 8B 및 70B 일 수있는 모델 meta-llama/Llama-3-xxB-chat-hf 사용합니다.Meta-Llama-3.1-405B-Instruct 모델 meta/meta-llama-3.1-405b-instruct 사용하여 Replice의 API를 통해 액세스됩니다.Meta-Llama-3.2-3B-Instruct 모델 meta-llama/Llama-3.2-3B-Instruct-Turbo 사용하여 AI chat 종말점을 통해 액세스됩니다.Llama-3.2-11B-Vision-Instruct 및 Llama-3.2-90B-Vision-Instruct 는 모델 meta-llama/Llama-3.2-11B-Vision-Instruct-Turbo chat meta-llama/Llama-3.2-90B-Vision-Instruct-Turbo .command-r-08-2024 및 /chat 엔드 포인트를 사용하여 사용되었습니다.command-r-plus-08-2024 및 /chat 엔드 포인트를 사용하여 사용되었습니다.c4ai-aya-expanse-8b 및 c4ai-aya-expanse-32b 사용하여 액세스. Cohere의 모델에 대한 자세한 내용은 웹 사이트를 참조하십시오.claude-2.0 사용하여 모델을 호출했습니다.claude-3-opus-20240229 사용하여 모델을 호출했습니다.claude-3-sonnet-20240229 사용하여 모델을 호출했습니다.claude-3-5-sonnet-20241022 사용하여 모델을 호출했습니다.claude-3-5-haiku-20241022 사용하여 모델을 호출했습니다.mistralai/Mixtral-8x22B-Instruct-v0.1 및 chat 종말점을 사용하여 AI의 API를 통해 액세스.mistral-large-latest 사용하여 Mistral AI의 API를 통해 액세스했습니다.text-bison-001 모델을 사용하여 구현되었습니다.gemini-pro 모델은 Vertex AI에서 액세스 할 수있는 언어 처리 향상을 위해 통합되었습니다.gemini-1.5-pro-001 사용하여 액세스.gemini-1.5-flash-001 사용하여 액세스.gemini-1.5-pro-002 사용하여 액세스.gemini-1.5-flash-002 사용하여 액세스.각 모델의 버전 및 수명주기, 특히 Google에서 제공하는 것들에 대한 심층적 인 이해는 Vertex AI의 모델 버전 및 라이프 사이클을 참조하십시오.
amazon.titan-text-express-v1 의 모델 식별자와 함께 Amazon Bedrock에서 액세스합니다.microsoft/WizardLM-2-8x22B 및 chat 엔드 포인트를 사용하여 AI의 API를 통해 액세스했습니다.databricks/dbrx-instruct 및 chat 엔드 포인트를 사용하여 AI의 API를 통해 액세스합니다.snowflake/snowflake-arctic-instruct 사용하여 Replice의 API를 통해 액세스합니다.Qwen/Qwen2-72B-Instruct 와 함께 AI chat 엔드 포인트를 통해 ACCCEDED.deepseek-chat 모델과 chat 엔드 포인트를 사용하여 DeepSeek의 API를 통해 액세스했습니다.grok-beta 및 chat/completions Endpoint를 사용하여 Xai의 API를 통해 액세스합니다. Qu. 모델을 평가하기 위해 모델을 사용하는 이유는 무엇입니까?
답변 인간의 평가를 통해이를 선택한 몇 가지 이유가 있습니다. 우리는 대규모 인간 규모의 평가를받을 수 있었지만, 그것은 한 번의 일이지만, 새로운 API가 온라인으로 오거나 모델이 업데이트 될 때 리더 보드를 지속적으로 업데이트 할 수있는 방식으로 확장되지는 않습니다. 우리는 빠르게 움직이는 분야에서 일하면서 그러한 프로세스가 게시하자마자 데이터를 벗어날 수 있습니다. 둘째, 우리는 다른 사람들과 공유 할 수있는 반복 가능한 프로세스를 원했기 때문에 자체 모델을 평가할 때 사용하는 많은 LLM 품질 점수 중 하나로 스스로 사용할 수있었습니다. 이것은 인간 주석 과정에서는 불가능할 것입니다. 공유 할 수있는 유일한 것은 프로세스와 인간 라벨입니다. 환각을 감지하기위한 모델을 구축하는 것이 환각을 생성하지 않는 생성 모델을 구축하는 것보다 훨씬 쉽다는 것을 지적 할 가치가 있습니다. 환각 평가 모델이 인간 평가자의 판단과 밀접한 관련이있는 한, 그것은 인간 판사에게 좋은 대리자가 될 수 있습니다. 우리가 일반적인 '폐쇄 된 책'질문 대답이 아닌 요약을 구체적으로 목표로 삼고 있기 때문에, 우리가 훈련 한 LLM은 많은 비율의 인간 지식을 암기 할 필요가 없으며, 단지 지원 언어에 대한 견고한 이해와 이해가 필요하지만 (현재는 영어에 불과하지만, 우리는 시간이 지남에 따라 언어 적용 범위를 확대 할 계획입니다).
Qu. LLM이 문서를 요약하지 않거나 한두 가지 단어 답변을 제공하면 어떻게됩니까?
대답 우리는 이것들을 명시 적으로 필터링합니다. 자세한 내용은 블로그 게시물을 참조하십시오. 요약 된 문서의 백분율과 요약 길이를 자세히 설명하는 '평균 요약 길이'열을 나타내는 리더 보드의 '답변 속도'열을 볼 수 있으며 대부분의 문서에 대해 짧은 답변을 얻지 못했음을 보여줍니다.
Qu. 어떤 버전의 Model XYZ를 사용 했습니까?
답변 사용 된 모델 버전과 호출 방법에 대한 세부 사항 및 리더 보드가 마지막으로 업데이트 된 날짜에 대한 API 세부 정보 섹션을 참조하십시오. 더 명확 해야하는 경우 저희에게 연락하십시오 (Repo에서 문제를 만들어).
Qu. Xai의 Grok LLM은 어떻습니까?
현재 답변은 (2012/14/2023 년 기준) Grok은 공개적으로 제공되지 않으며 액세스 할 수 없습니다. 초기 접근성을 가진 사람들은 아마도 모델에 대해 이런 종류의 평가를 수행하는 것이 법적으로 금지되어있을 것입니다. 공개 API를 통해 모델을 사용할 수있게되면 충분히 인기있는 다른 LLM과 함께 추가 할 것입니다.
Qu. 모델이 답변이나 매우 짧은 답변을 제공함으로써 100% 점수를 얻을 수 없습니까?
답변 우리는 모든 모델에서 요약을 제공 한 문서에 대해서만 최종 평가를 수행하여 모든 모델에서 그러한 응답을 명시 적으로 필터링했습니다. 주제에 대한 블로그 게시물에서 더 많은 기술적 세부 사항을 찾을 수 있습니다. 위 표에서 '답변 속도'및 '평균 요약 길이'열도 참조하십시오.
Qu. 이 작업에서 원래 요약 점수 100% (0 환각)의 사본과 페이스트를 사본과 페이스트로하는 추출 요약 모델이 아닌가?
정의 에 따라 그러한 모델은 환각이없고 충실한 요약을 제공합니다. 우리는 요약 품질을 평가한다고 주장하지 않으며, 이는 별도의 직교 작업이며 독립적으로 평가되어야합니다. 우리는 블로그 게시물에서 지적한 것처럼 요약의 품질을 평가 하지 않고 사실적인 일관성 만 평가하지 않습니다.
Qu. 원본 텍스트를 요약으로 복사 할 수 있으므로 이것은 매우 해킹 가능한 메트릭으로 보입니다.
답변. 그것은 사실이지만 우리는이 접근법에 대한 임의의 모델을 평가하지 않습니다. 그렇게하는 모든 모델은 당신이 관심을 갖는 다른 작업에서 제대로 수행하지 못할 것입니다. 따라서 요약 품질, 질문 답변 정확도 등과 같이 모델에 대한 다른 평가와 함께 실행하는 품질 메트릭으로 간주하지만,이를 독립형 메트릭으로 사용하는 것은 권장하지 않습니다. 선택한 모델 중 어느 것도 모델의 출력에 대해 교육을받지 않았습니다. 미래에 일어날 수 있지만 모델과 소스 문서를 업데이트 할 계획이므로 살아있는 리더 보드이므로 발생하지 않을 것입니다. 그러나 LLM 벤치 마크의 문제도 있습니다. 우리는 또한 다른 많은 학자 들이이 프로토콜을 발명하고 개선 한 사실 일관성에 관한 많은 작업을 바탕으로 지적해야합니다. 이 블로그 게시물에서 Summac 및 True 논문에 대한 우리의 언급 과이 훌륭한 자원 편집 -https://github.com/edinburghnlp/awesome-hallucination-detection을 참조하십시오.
Qu. 이것은 모델이 환각 할 수있는 모든 방법을 결정적으로 측정하는 것은 아닙니다.
답변. 동의했다. 우리는 환각 탐지 문제를 해결했다고 주장하지 않으며이 과정을 더 확장하고 향상시킬 계획입니다. 그러나 우리는 그것이 올바른 방향으로의 움직임이라고 믿으며 모든 사람이 위에 올 수있는 필요한 출발점을 제공합니다.
Qu. 일부 모델은 요약 하면서만 환각 할 수 있습니다. 잘 알려진 사실의 목록을 제공하고 그것이 얼마나 잘 기억할 수 있는지 확인할 수 없습니까?
답변. 그것은 내 의견으로는 열악한 시험 일 것입니다. 우선, 모델을 훈련시키지 않으면 교육을받은 데이터를 알지 못하므로 모델이 본 실제 데이터 또는 추측 여부에 대한 응답을 접지하고 있는지 확인할 수 없습니다. 또한 '잘 알려진'에 대한 명확한 정의는 없으며, 이러한 유형의 데이터는 일반적으로 대부분의 모델이 정확하게 기억하기 쉽습니다. 주관적인 경험에서 대부분의 환각은 거의 알려지지 않았거나 논의 된 정보를 가져 오는 모델 또는 모델이 상충되는 정보를 보았던 사실을 가져옵니다. 소스 데이터를 알지 못하면 모델이 교육을 받았으며,이 기준에 맞는 데이터를 알지 못하므로 이러한 종류의 환각을 검증하는 것은 불가능합니다. 나는 또한 모델이 요약하면서 환각 만 할 가능성이 없다고 생각합니다. 우리는 모델에 정보를 가져 와서 여전히 소스에 충실한 방식으로 정보를 전환하도록 요청하고 있습니다. 이것은 요약 외에도 많은 생성 작업과 유사합니다 (예 : 이러한 점을 다루는 이메일을 작성합니다 ...). 모델이 프롬프트에서 벗어나면 지침을 따르지 않으면 모델이 다른 명령에 따라 어려움을 겪을 것임을 나타냅니다.
Qu. 이것은 좋은 출발이지만 결정과는 거리가 멀다
답변. 나는 완전히 동의합니다. 해야 할 일이 훨씬 많아서 문제는 해결되지 않았습니다. 그러나 '좋은 시작'은이 영역에서 진보가 이루어지기 시작하고 모델을 개방적으로 소싱함으로써 커뮤니티를 다음 단계로 끌어 올리기를 희망합니다.


