hallucination leaderboard
1.0.0
Public LLM LaceRboard calculado usando o modelo de avaliação de Hughes Hunucination de Vetara. Isso avalia a frequência com que um LLM apresenta alucinações ao resumir um documento. Planejamos atualizá -lo regularmente à medida que nosso modelo e os LLMs são atualizados ao longo do tempo.
Além disso, sinta -se à vontade para conferir nossa tabela de líderes de alucinação em abraçar o rosto.
As classificações nesta tabela de classificação são calculadas usando o modelo de avaliação de alucinação HHEM-2.1. Se você estiver interessado na tabela de classificação anterior, que foi baseada no HHEM-1.0, ele está disponível aqui
 | Em memória amorosa de Simon Mark Hughes ... |
Última atualização em 6 de novembro de 2024
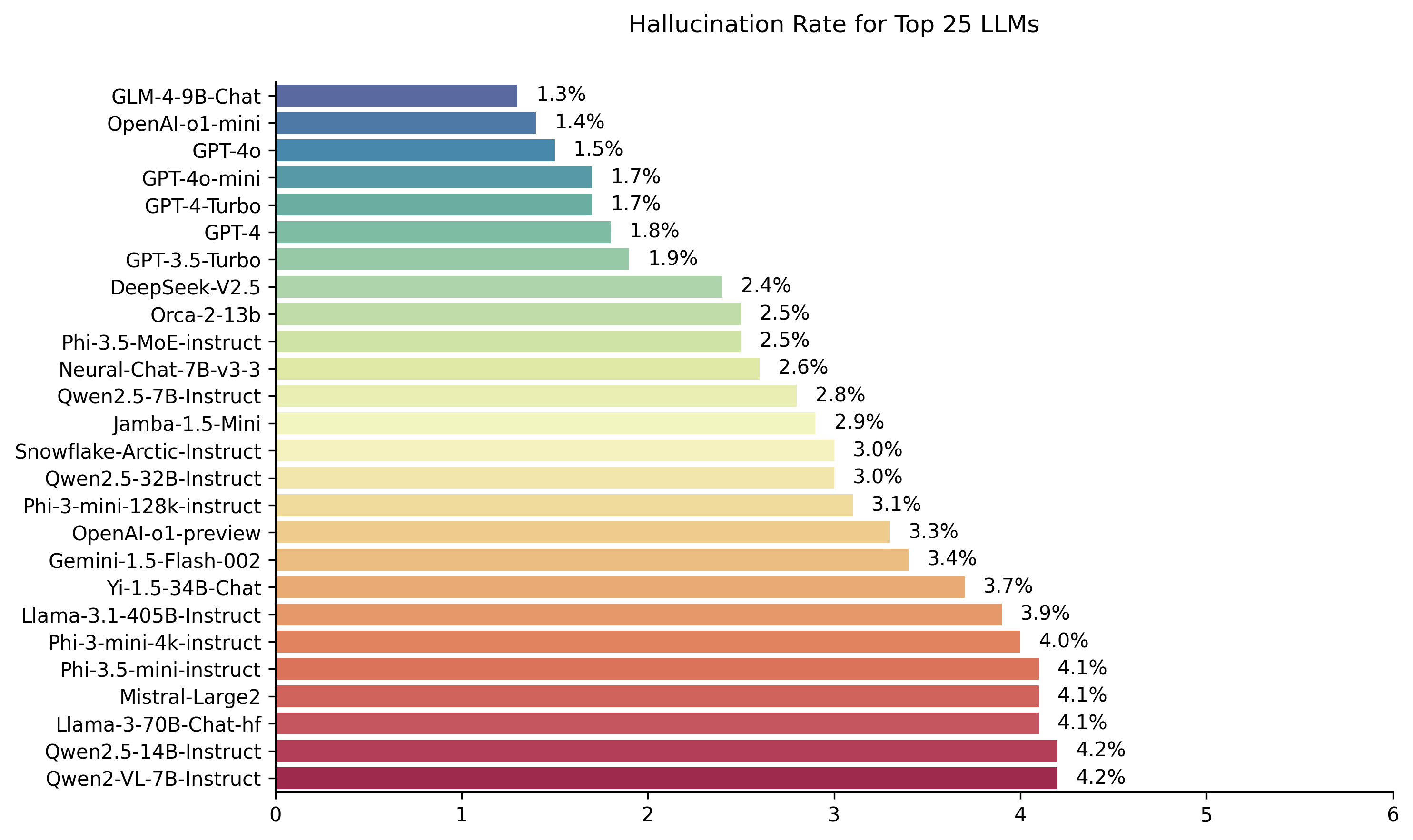
| Modelo | Taxa de alucinação | Taxa de consistência factual | Taxa de resposta | Comprimento médio de resumo (palavras) |
|---|---|---|---|---|
| Zhipu AI GLM-4-9B-CHAT | 1,3 % | 98,7 % | 100,0 % | 58.1 |
| OpenI-O1-mini | 1,4 % | 98,6 % | 100,0 % | 78.3 |
| GPT-4O | 1,5 % | 98,5 % | 100,0 % | 77.8 |
| GPT-4O-MINI | 1,7 % | 98,3 % | 100,0 % | 76.3 |
| GPT-4-Turbo | 1,7 % | 98,3 % | 100,0 % | 86.2 |
| GPT-4 | 1,8 % | 98,2 % | 100,0 % | 81.1 |
| GPT-3.5-Turbo | 1,9 % | 98,1 % | 99,6 % | 84.1 |
| Deepseek-V2.5 | 2,4 % | 97,6 % | 100,0 % | 83.2 |
| Microsoft ORCA-2-13B | 2,5 % | 97,5 % | 100,0 % | 66.2 |
| Microsoft Phi-3.5-MOE-Instruct | 2,5 % | 97,5 % | 96,3 % | 69.7 |
| Intel-Chat-7b-V3-3 | 2,6 % | 97,4 % | 100,0 % | 60.7 |
| QWEN2.5-7B-INSTRUTA | 2,8 % | 97,2 % | 100,0 % | 71.0 |
| AI21 Jamba-1,5-mini | 2,9 % | 97,1 % | 95,6 % | 74.5 |
| Instrução-Artic-Arco | 3,0 % | 97,0 % | 100,0 % | 68.7 |
| QWEN2.5-32B-INSTRUTA | 3,0 % | 97,0 % | 100,0 % | 67.9 |
| Microsoft Phi-3-Mini-128K-Instrut | 3,1 % | 96,9 % | 100,0 % | 60.1 |
| OpenAI-O1-Preview | 3,3 % | 96,7 % | 100,0 % | 119.3 |
| Google Gemini-1.5-Flash-002 | 3,4 % | 96,6 % | 99,9 % | 59.4 |
| 01-AI YI-1.5-34B-CHAT | 3,7 % | 96,3 % | 100,0 % | 83.7 |
| LLAMA-3.1-405B-INSTRUTA | 3,9 % | 96,1 % | 99,6 % | 85.7 |
| Microsoft Phi-3-Mini-4K-Instruct | 4,0 % | 96,0 % | 100,0 % | 86.8 |
| Microsoft Phi-3,5-Mini-Instruct | 4,1 % | 95,9 % | 100,0 % | 75.0 |
| Mistral-Large2 | 4,1 % | 95,9 % | 100,0 % | 77.4 |
| Llama-3-70b-chat-hf | 4,1 % | 95,9 % | 99,2 % | 68.5 |
| QWEN2-VL-7B-INSTRUTA | 4,2 % | 95,8 % | 100,0 % | 73.9 |
| QWEN2.5-14B-INSTRUTA | 4,2 % | 95,8 % | 100,0 % | 74.8 |
| QWEN2.5-72B-INSTRUTA | 4,3 % | 95,7 % | 100,0 % | 80.0 |
| LLAMA-3.2-90B-VISÃO-INSTRUTA | 4,3 % | 95,7 % | 100,0 % | 79.8 |
| Xai Grok | 4,6 % | 95,4 % | 100,0 % | 91.0 |
| Claude-3-5 antropia | 4,6 % | 95,4 % | 100,0 % | 95.9 |
| QWEN2-72B-INSTRUTA | 4,7 % | 95,3 % | 100,0 % | 100.1 |
| Mixtral-8x22b-Instruct-v0.1 | 4,7 % | 95,3 % | 99,9 % | 92.0 |
| Antrópico Claude-3-5-Haiku | 4,9 % | 95,1 % | 100,0 % | 92.9 |
| 01-AI YI-1.5-9B-CHAT | 4,9 % | 95,1 % | 100,0 % | 85.7 |
| Coere command-r | 4,9 % | 95,1 % | 100,0 % | 68.7 |
| LLAMA-3.1-70B-INSTRUTA | 5,0 % | 95,0 % | 100,0 % | 79.6 |
| LLAMA-3.1-8B-INSTRUTA | 5,4 % | 94,6 % | 100,0 % | 71.0 |
| Coere command-r-plus | 5,4 % | 94,6 % | 100,0 % | 68.4 |
| LLAMA-3.2-11B-VISION-INSTRUTA | 5,5 % | 94,5 % | 100,0 % | 67.3 |
| Llama-2-70b-chat-hf | 5,9 % | 94,1 % | 99,9 % | 84.9 |
| IBM Granite-3.0-8b-Instruct | 6,5 % | 93,5 % | 100,0 % | 74.2 |
| Google Gemini-1.5-Pro-002 | 6,6 % | 93,7 % | 99,9 % | 62.0 |
| Google Gemini-1.5-Flash | 6,6 % | 93,4 % | 99,9 % | 63.3 |
| Microsoft Phi-2 | 6,7 % | 93,3 % | 91,5 % | 80.8 |
| Google GEMMA-2-2B-IT | 7,0 % | 93,0 % | 100,0 % | 62.2 |
| QWEN2.5-3B-INSTRUTA | 7,0 % | 93,0 % | 100,0 % | 70.4 |
| Llama-3-8b-chat-hf | 7,4 % | 92,6 % | 99,8 % | 79.7 |
| Google Gemini-Pro | 7,7 % | 92,3 % | 98,4 % | 89.5 |
| 01-AI YI-1.5-6B-CHAT | 7,9 % | 92,1 % | 100,0 % | 98.9 |
| LLAMA-3.2-3B-INSTRUTA | 7,9 % | 92,1 % | 100,0 % | 72.2 |
| Databricks DBRX-Instruct | 8,3 % | 91,7 % | 100,0 % | 85.9 |
| QWEN2-VL-2B-INSTRUTA | 8,3 % | 91,7 % | 100,0 % | 81.8 |
| Coere aya Expanse 32b | 8,5 % | 91,5 % | 99,9 % | 81.9 |
| IBM Granite-3.0-2b-instrução | 8,8 % | 91,2 % | 100,0 % | 81.6 |
| Mistral-7b-Instruct-V0.3 | 9,5 % | 90,5 % | 100,0 % | 98.4 |
| Google Gemini-1.5-Pro | 9,1 % | 90,9 % | 99,8 % | 61.6 |
| Claude-3-opus antrópico | 10,1 % | 89,9 % | 95,5 % | 92.1 |
| Google GEMMA-2-9B-IT | 10,1 % | 89,9 % | 100,0 % | 70.2 |
| Lhama-2-13b-chat-hf | 10,5 % | 89,5 % | 99,8 % | 82.1 |
| Mistral-Nemo-Instruct | 11,2 % | 88,8 % | 100,0 % | 69.9 |
| LLAMA-2-7B-CHAT-HF | 11,3 % | 88,7 % | 99,6 % | 119.9 |
| Microsoft Wizardlm-2-8x22b | 11,7 % | 88,3 % | 99,9 % | 140.8 |
| Coere aya Expanse 8b | 12,2 % | 87,8 % | 99,9 % | 83.9 |
| Amazon Titan-Express | 13,5 % | 86,5 % | 99,5 % | 98.4 |
| Google Palm-2 | 14,1 % | 85,9 % | 99,8 % | 86.6 |
| Google Gemma-7b-it | 14,8 % | 85,2 % | 100,0 % | 113.0 |
| QWEN2.5-1.5B-INSTRUCT | 15,8 % | 84,2 % | 100,0 % | 70.7 |
| Claude-3 antrópico | 16,3 % | 83,7 % | 100,0 % | 108.5 |
| Google GEMMA-1.1-7B-IT | 17,0 % | 83,0 % | 100,0 % | 64.3 |
| Claude-2 antrópico | 17,4 % | 82,6 % | 99,3 % | 87.5 |
| Google Flan-T5-Large | 18,3 % | 81,7 % | 99,3 % | 20.9 |
| Mixtral-8x7b-Instruct-v0.1 | 20,1 % | 79,9 % | 99,9 % | 90.7 |
| LLAMA-3.2-1B-INSTRUTA | 20,7 % | 79,3 % | 100,0 % | 71.5 |
| Apple OpenELM-3B-Instrut | 24,8 % | 75,2 % | 99,3 % | 47.2 |
| QWEN2.5-0.5B-INSTRUTA | 25,2 % | 74,8 % | 100,0 % | 72.6 |
| Google Gemma-1.1-2b-it | 27,8 % | 72,2 % | 100,0 % | 66.8 |
| TII Falcon-7B-Instruct | 29,9 % | 70,1 % | 90,0 % | 75.5 |
Esta tabela de classificação usa o HHEM-2.1, modelo de avaliação de alucinação comercial da Vectara, para calcular os rankings LLM. Você pode encontrar uma variante de código aberto desse modelo, HHEM-2.1 -1-OPEN no rosto e kaggle abraçados.
Veja este conjunto de dados para os resumos gerados que usamos para avaliar os modelos.
Muito trabalho anterior nesta área foi feito. Para alguns dos principais documentos desta área (consistência factual em resumo), consulte aqui:
Para uma lista muito abrangente, consulte aqui-https://github.com/edinburghnlp/awesome-hallucination-detecção. Os métodos descritos na seção a seguir usam protocolos estabelecidos nesses trabalhos, entre muitos outros.
Para uma explicação detalhada do trabalho que entrou nesse modelo, consulte a nossa postagem no lançamento: Cut The Bull…. Detectar alucinações em grandes modelos de idiomas.
Para determinar essa tabela de classificação, treinamos um modelo para detectar alucinações nas saídas da LLM, usando vários conjuntos de dados de código aberto da pesquisa de consistência factual em modelos de resumo. Usando um modelo competitivo com os melhores modelos de última geração, alimentamos 1000 documentos curtos a cada um dos LLMs acima por meio de suas APIs públicas e pedimos que resumissem cada documento curto, usando apenas os fatos apresentados no documento. Desses 1000 documentos, apenas 831 documentos foram resumidos por todos os modelo, os documentos restantes foram rejeitados por pelo menos um modelo devido a restrições de conteúdo. Usando esses 831 documentos, calculamos a taxa geral de consistência factual (sem alucinações) e a taxa de alucinação (precisão de 100) para cada modelo. A taxa na qual cada modelo se recusa a responder ao prompt é detalhado na coluna 'taxa de resposta'. Nenhum dos conteúdos enviados aos modelos continha conteúdo ilícito ou "não seguro para o trabalho", mas o presente das palavras de gatilho foi suficiente para acionar alguns dos filtros de conteúdo. Os documentos foram retirados principalmente da CNN / Daily Mail Corpus. Usamos uma temperatura de 0 ao chamar o LLMS.
Avaliamos a taxa de consistência factual de resumo, em vez da precisão factual geral, porque ela nos permite comparar a resposta do modelo às informações fornecidas. Em outras palavras, o resumo é fornecido "factualmente consistente" com o documento de origem. Determinar alucinações é impossível de fazer para qualquer pergunta ad hoc, pois não se sabe com precisão em que dados todos os LLM são treinados. Além disso, ter um modelo que pode determinar se alguma resposta foi alucinada sem uma fonte de referência exige a solução do problema de alucinação e presumivelmente o treinamento de um modelo como grande ou maior do que esses LLMs que estão sendo avaliados. Por isso, optamos por olhar para a taxa de alucinação dentro da tarefa de resumo, pois esse é um bom análogo para determinar o quão verdadeiro os modelos são em geral. Além disso, os LLMs são cada vez mais utilizados em pipelines de RAG (Recuperação Geração Aumentada) para responder às consultas do usuário, como no Bing Chat e na integração de bate -papo do Google. Em um sistema de pano, o modelo está sendo implantado como um resumador dos resultados da pesquisa, portanto, esse tabela de classificação também é um bom indicador para a precisão dos modelos quando usado em sistemas de pano.
Você é um bot de bate -papo que responde perguntas usando dados. Você deve seguir as respostas fornecidas exclusivamente pelo texto na passagem fornecida. Você recebe a pergunta 'Forneça um resumo conciso da passagem a seguir, cobrindo as principais informações descritas'. <Damve> '
Ao ligar para a API, o token <Passage> foi substituído pelo documento de origem (consulte a coluna 'Origem' neste conjunto de dados).
Abaixo está uma visão geral detalhada dos modelos integrados e de seus pontos de extremidade específicos:
gpt-3.5-turbo através da biblioteca de clientes do Python da OpenAI, especificamente através do ponto final do chat.completions.create .gpt-4 .gpt-4-turbo-2024-04-09 , de acordo com a documentação do OpenAI.gpt-4o .gpt-4o-mini .o1-mini .o1-previewmeta-llama/Llama-2-xxb-chat-hf , onde xxb pode ser 7b , 13b e 70b , adaptado à capacidade de cada modelo.chat e usando o modelo meta-llama/Llama-3-xxB-chat-hf , onde xxB pode ser 8B e 70B .Meta-Llama-3.1-405B-Instruct é acessado através da API da REPLICACE usando o modelo meta/meta-llama-3.1-405b-instruct .Meta-Llama-3.2-3B-Instruct é acessado via terminal chat em conjunto usando o modelo meta-llama/Llama-3.2-3B-Instruct-Turbo .Llama-3.2-11B-Vision-Instruct E Llama-3.2-90B-Vision-Instruct são acessados via endpoint chat conjunto de AI usando o Model meta-llama/Llama-3.2-11B-Vision-Instruct-Turbo e meta-llama/Llama-3.2-90B-Vision-Instruct-Turbo /command-r-08-2024 e o Endpoint /chat .command-r-plus-08-2024 e o endpoint /chat .c4ai-aya-expanse-8b e c4ai-aya-expanse-32b . Para obter mais informações sobre os modelos da Coere, consulte o site deles.claude-2.0 para a chamada da API.claude-3-opus-20240229 para a chamada da API.claude-3-sonnet-20240229 para a chamada da API.claude-3-5-sonnet-20241022 para a chamada da API.claude-3-5-haiku-20241022 para a chamada da API.mistralai/Mixtral-8x22B-Instruct-v0.1 e o terminal chat .mistral-large-latest .text-bison-001 , respectivamente.gemini-pro do Google é incorporado para processamento de linguagem aprimorado, acessível no vértice AI.gemini-1.5-pro-001 no vértice ai.gemini-1.5-flash-001 no vértice AI.gemini-1.5-pro-002 no Vertex AI.gemini-1.5-flash-002 no vértice ai.Para uma compreensão aprofundada da versão e do ciclo de vida de cada modelo, especialmente os oferecidos pelo Google, consulte as versões e os ciclos de vida do vértice ai.
amazon.titan-text-express-v1 .microsoft/WizardLM-2-8x22B e o terminal chat .databricks/dbrx-instruct e o final chat .snowflake/snowflake-arctic-instruct .chat em conjunto com o nome do modelo Qwen/Qwen2-72B-Instruct .deepseek-chat e o terminal chat .grok-beta e o terminal chat/completions . Qu. Por que você está usando um modelo para avaliar um modelo?
Resposta Há várias razões pelas quais escolhemos fazer isso em vez de uma avaliação humana. Embora pudéssemos ter um crowdsourced uma grande avaliação em escala humana, isso é uma coisa única, ela não escala de uma maneira que nos permite atualizar constantemente a tabela de classificação à medida que novas APIs ficam on -line ou os modelos são atualizados. Trabalhamos em um campo em movimento rápido para que esse processo estivesse fora de dados assim que publicado. Em segundo lugar, queríamos um processo repetível que pudéssemos compartilhar com outras pessoas para que eles possam usá -lo como uma das muitas pontuações de qualidade do LLM que usam ao avaliar seus próprios modelos. Isso não seria possível com um processo de anotação humana, onde as únicas coisas que poderiam ser compartilhadas são o processo e os rótulos humanos. Também vale ressaltar que construir um modelo para detectar alucinações é muito mais fácil do que construir um modelo generativo que nunca produz alucinações. Enquanto o modelo de avaliação de alucinação estiver altamente correlacionado com os julgamentos dos avaliadores humanos, ele pode ser um bom proxy para os juízes humanos. Como estamos direcionando especificamente o resumo e não a resposta geral ao 'livro fechado', o LLM que treinamos não precisa memorizar uma grande proporção de conhecimento humano, ele só precisa ter uma sólida compreensão e compreensão dos idiomas que ele apoia (atualmente apenas inglês, mas planejamos expandir a cobertura do idioma ao longo do tempo).
Qu. E se o LLM se recusar a resumir o documento ou fornecer uma resposta de uma ou duas palavras?
Resposta Nós os filtramos explicitamente. Veja a nossa postagem no blog para obter mais informações. Você pode ver a coluna 'taxa de resposta' na tabela de classificação que indica a porcentagem de documentos resumidos e a coluna 'Comprimento médio de resumo' detalhando os comprimentos de resumo, mostrando que não obtivemos respostas muito curtas para a maioria dos documentos.
Qu. Qual versão do modelo XYZ você usou?
Resposta Consulte a seção Detalhes da API para obter detalhes sobre as versões do modelo usadas e como elas foram chamadas, bem como a data em que a tabela de classificação foi atualizada pela última vez. Entre em contato conosco (crie um problema no repositório) se precisar de mais clareza.
Qu. E quanto a Xai's Grok LLM?
Atualmente, a resposta (a partir de 14/11/2023) GROK não está disponível ao público e não temos acesso. Aqueles com acesso antecipado que eu suspeito provavelmente são legalmente proibidos de fazer esse tipo de avaliação no modelo. Depois que o modelo estiver disponível por meio de uma API pública, procuraremos adicioná -lo, juntamente com qualquer outro LLMS que seja popular o suficiente.
Qu. Um modelo não pode apenas pontuar 100% fornecendo respostas ou respostas muito curtas?
Resposta , filtramos explicitamente essas respostas de todos os modelo, fazendo a avaliação final apenas em documentos para os quais todos os modelos forneceram um resumo. Você pode descobrir mais detalhes técnicos em nossa postagem no blog sobre o assunto. Veja também as colunas 'taxa de resposta' e 'resumo médio' na tabela acima.
Qu. Um modelo de resumo extrativo não copia e pastas da pontuação de resumo original 100% (0 alucinação) nesta tarefa?
Responder absolutamente como, por definição, esse modelo não teria alucinações e proporcionaria um resumo fiel. Não afirmamos estar avaliando a qualidade do resumo, que é uma tarefa separada e ortogonal e deve ser avaliada de forma independente. Não estamos avaliando a qualidade dos resumos, apenas a consistência factual deles, como apontamos na postagem do blog.
Qu. Isso parece uma métrica muito hackeable, pois você pode simplesmente copiar o texto original como o resumo
Responder. Isso é verdade, mas não estamos avaliando modelos arbitrários nessa abordagem, por exemplo, como em uma competição de kaggle. Qualquer modelo que o faça tenha um desempenho ruim em qualquer outra tarefa de que você se importe. Então, eu consideraria isso como métrica de qualidade que você executaria ao lado de outras avaliações que tiver para o seu modelo, como qualidade de resumo, precisão de resposta a perguntas etc. Mas não recomendamos que isso seja uma métrica independente. Nenhum dos modelos escolhidos foi treinado na saída do nosso modelo. Isso pode acontecer no futuro, mas como planejamos atualizar o modelo e também os documentos de origem, portanto, este é um tabela de classificação viva, isso será uma ocorrência improvável. No entanto, isso também é um problema com qualquer referência da LLM. Também devemos apontar isso se baseia em um grande corpo de trabalho sobre consistência factual, onde muitos outros acadêmicos inventaram e refinaram esse protocolo. Consulte nossas referências ao Summac e a verdadeira documentos nesta postagem do blog, bem como esta excelente compilação de recursos-https://github.com/edinburghnlp/awesome-hallucination-detecção para ler mais.
Qu. Isso não mede definitivamente todas as maneiras pelas quais um modelo pode alucinar
Responder. Acordado. Não afirmamos ter resolvido o problema da detecção de alucinação e planejamos expandir e aprimorar esse processo. Mas acreditamos que é um movimento na direção certa e fornece um ponto de partida muito necessário que todos podem construir.
Qu. Alguns modelos só podem alucinar enquanto resumiam. Você não poderia apenas fornecer uma lista de fatos bem conhecidos e verificar como isso pode lembrá -los?
Responder. Isso seria um teste ruim na minha opinião. Por um lado, a menos que você tenha treinado o modelo em que não conhece os dados em que foi treinado, para que você não tenha certeza de que o modelo está fundamentando sua resposta em dados reais em que viu ou se está adivinhando. Além disso, não há uma definição clara de 'bem conhecido', e esses tipos de dados são normalmente fáceis para a maioria dos modelos recordarem com precisão. A maioria das alucinações, na minha experiência reconhecidamente subjetiva, vem da informação de busca de modelo que é muito raramente conhecida ou discutida, ou fatos pelos quais o modelo viu informações conflitantes. Sem conhecer os dados de origem em que o modelo foi treinado, novamente é impossível validar esse tipo de alucinações, pois você não saberá quais dados se encaixam nesse critério. Eu também acho que é improvável que o modelo apenas alucinasse ao resumir. Estamos pedindo ao modelo que tome informações e transformá -las de uma maneira que ainda seja fiel à fonte. Isso é análogo a muitas tarefas generativas, além do resumo (por exemplo, escreva um email que cobre esses pontos ...) e, se o modelo desviar do prompt, isso é uma falha em seguir as instruções, indicando que o modelo também lutará em outras instruções após as tarefas.
Qu. Este é um bom começo, mas longe de definitivo
Responder. Eu concordo totalmente. Há muito mais que precisa ser feito, e o problema está longe de ser resolvido. Mas um 'bom começo' significa que, esperançosamente, o progresso começará a ser feito nessa área e, ao fornecer o modelo, esperamos envolver a comunidade para levar isso ao próximo nível.


