hallucination leaderboard
1.0.0
VectaraのHughes Hallucination Evaluation Modelを使用して計算されたPublic LLMリーダーボード。これにより、LLMがドキュメントを要約するときに幻覚を導入する頻度を評価します。モデルとLLMが時間の経過とともに更新されるにつれて、これを定期的に更新する予定です。
また、顔を抱き締める幻覚リーダーボードを自由にチェックしてください。
このリーダーボードのランキングは、HHEM-2.1幻覚評価モデルを使用して計算されます。 HHEM-1.0に基づいた以前のリーダーボードに興味がある場合は、こちらから入手できます。
 | サイモン・マーク・ヒューズの愛情のこもった記憶に... |
2024年11月6日に最後に更新されました
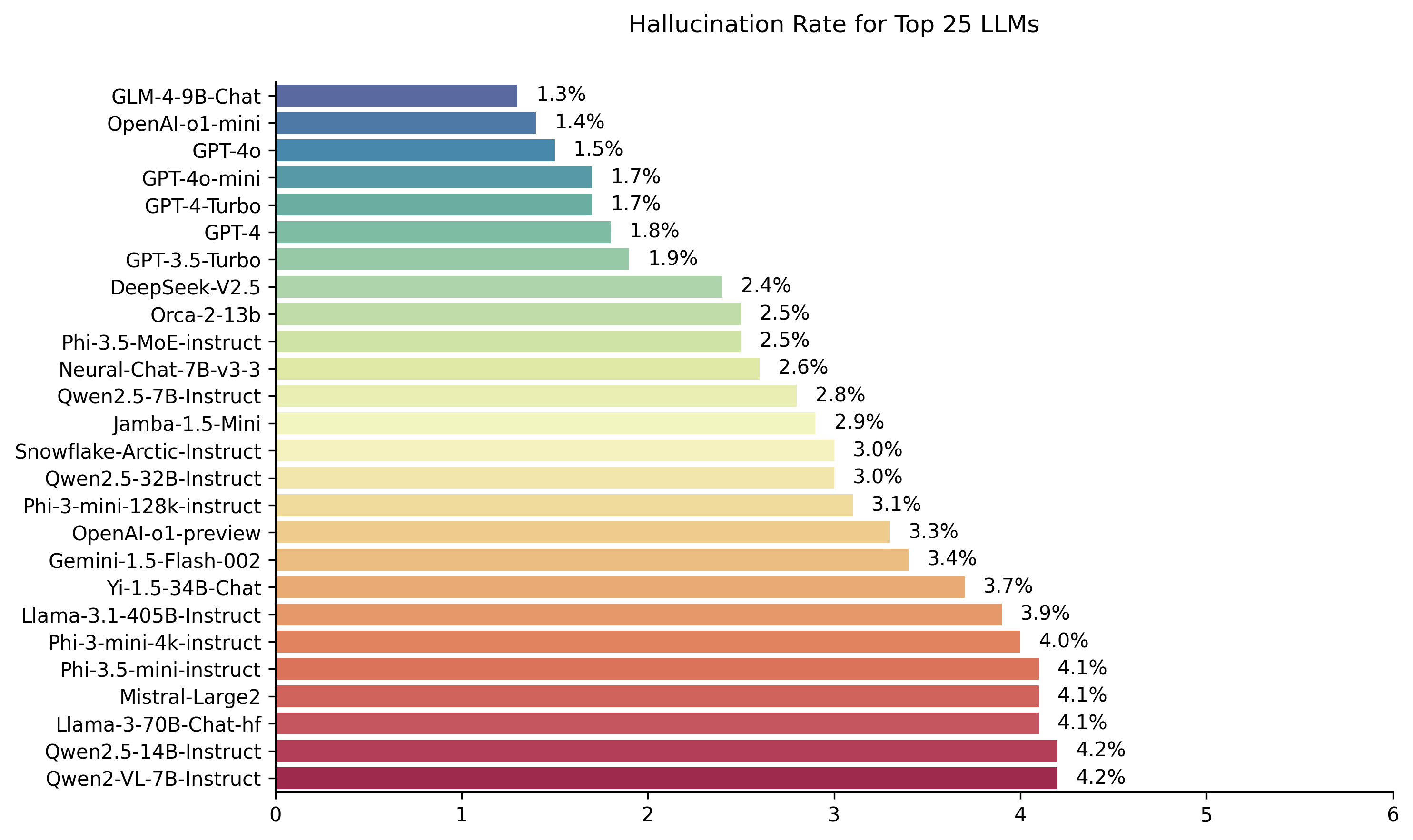
| モデル | 幻覚率 | 事実上の一貫性率 | 回答率 | 平均概要(単語) |
|---|---|---|---|---|
| Zhipu ai glm-4-9b-chat | 1.3% | 98.7% | 100.0% | 58.1 |
| Openai-o1-mini | 1.4% | 98.6% | 100.0% | 78.3 |
| GPT-4O | 1.5% | 98.5% | 100.0% | 77.8 |
| GPT-4O-MINI | 1.7% | 98.3% | 100.0% | 76.3 |
| GPT-4-Turbo | 1.7% | 98.3% | 100.0% | 86.2 |
| GPT-4 | 1.8% | 98.2% | 100.0% | 81.1 |
| GPT-3.5-ターボ | 1.9% | 98.1% | 99.6% | 84.1 |
| deepseek-v2.5 | 2.4% | 97.6% | 100.0% | 83.2 |
| Microsoft orca-2-13b | 2.5% | 97.5% | 100.0% | 66.2 |
| Microsoft PHI-3.5-MOE-Instruct | 2.5% | 97.5% | 96.3% | 69.7 |
| Intel Neural-Chat-7B-V3-3 | 2.6% | 97.4% | 100.0% | 60.7 |
| QWEN2.5-7B-Instruct | 2.8% | 97.2% | 100.0% | 71.0 |
| AI21 JAMBA-1.5-MINI | 2.9% | 97.1% | 95.6% | 74.5 |
| スノーフレークアークインストラクション | 3.0% | 97.0% | 100.0% | 68.7 |
| QWEN2.5-32B-Instruct | 3.0% | 97.0% | 100.0% | 67.9 |
| Microsoft Phi-3-Mini-128K-Instruct | 3.1% | 96.9% | 100.0% | 60.1 |
| Openai-O1-Preview | 3.3% | 96.7% | 100.0% | 119.3 |
| Google Gemini-1.5-Flash-002 | 3.4% | 96.6% | 99.9% | 59.4 |
| 01-AI YI-1.5-34B-chat | 3.7% | 96.3% | 100.0% | 83.7 |
| llama-3.1-405b-instruct | 3.9% | 96.1% | 99.6% | 85.7 |
| Microsoft Phi-3-mini-4k-instruct | 4.0% | 96.0% | 100.0% | 86.8 |
| Microsoft Phi-3.5-mini-Instruct | 4.1% | 95.9% | 100.0% | 75.0 |
| Mistral-Large2 | 4.1% | 95.9% | 100.0% | 77.4 |
| llama-3-70b-chat-hf | 4.1% | 95.9% | 99.2% | 68.5 |
| QWEN2-VL-7B-Instruct | 4.2% | 95.8% | 100.0% | 73.9 |
| QWEN2.5-14B-Instruct | 4.2% | 95.8% | 100.0% | 74.8 |
| QWEN2.5-72B-Instruct | 4.3% | 95.7% | 100.0% | 80.0 |
| llama-3.2-90b-vision-instruct | 4.3% | 95.7% | 100.0% | 79.8 |
| Xai Grok | 4.6% | 95.4% | 100.0% | 91.0 |
| 人類のクロード-3-5-ソネット | 4.6% | 95.4% | 100.0% | 95.9 |
| QWEN2-72B-Instruct | 4.7% | 95.3% | 100.0% | 100.1 |
| mixtral-8x22b-instruct-v0.1 | 4.7% | 95.3% | 99.9% | 92.0 |
| 人類のクロード-3-5-ハイク | 4.9% | 95.1% | 100.0% | 92.9 |
| 01-AI YI-1.5-9B-chat | 4.9% | 95.1% | 100.0% | 85.7 |
| Cohere command-r | 4.9% | 95.1% | 100.0% | 68.7 |
| llama-3.1-70b-instruct | 5.0% | 95.0% | 100.0% | 79.6 |
| llama-3.1-8b-instruct | 5.4% | 94.6% | 100.0% | 71.0 |
| Cohere Command-R-Plus | 5.4% | 94.6% | 100.0% | 68.4 |
| llama-3.2-11b-vision-instruct | 5.5% | 94.5% | 100.0% | 67.3 |
| llama-2-70b-chat-hf | 5.9% | 94.1% | 99.9% | 84.9 |
| IBM Granite-3.0-8B-Instruct | 6.5% | 93.5% | 100.0% | 74.2 |
| Google Gemini-1.5-Pro-002 | 6.6% | 93.7% | 99.9% | 62.0 |
| Google Gemini-1.5-Flash | 6.6% | 93.4% | 99.9% | 63.3 |
| Microsoft Phi-2 | 6.7% | 93.3% | 91.5% | 80.8 |
| Google Gemma-2-2B-It | 7.0% | 93.0% | 100.0% | 62.2 |
| QWEN2.5-3B-Instruct | 7.0% | 93.0% | 100.0% | 70.4 |
| llama-3-8b-chat-hf | 7.4% | 92.6% | 99.8% | 79.7 |
| Google Gemini-Pro | 7.7% | 92.3% | 98.4% | 89.5 |
| 01-AI YI-1.5-6B-chat | 7.9% | 92.1% | 100.0% | 98.9 |
| llama-3.2-3b-instruct | 7.9% | 92.1% | 100.0% | 72.2 |
| Databricks DBRX-Instruct | 8.3% | 91.7% | 100.0% | 85.9 |
| QWEN2-VL-2B-Instruct | 8.3% | 91.7% | 100.0% | 81.8 |
| Coherea aya expanse 32b | 8.5% | 91.5% | 99.9% | 81.9 |
| IBM Granite-3.0-2B-Instruct | 8.8% | 91.2% | 100.0% | 81.6 |
| Mistral-7B-Instruct-V0.3 | 9.5% | 90.5% | 100.0% | 98.4 |
| Google Gemini-1.5-Pro | 9.1% | 90.9% | 99.8% | 61.6 |
| 人類のクロード-3オプス | 10.1% | 89.9% | 95.5% | 92.1 |
| Google Gemma-2-9b-it | 10.1% | 89.9% | 100.0% | 70.2 |
| llama-2-13b-chat-hf | 10.5% | 89.5% | 99.8% | 82.1 |
| ミストラルネモインストラクション | 11.2% | 88.8% | 100.0% | 69.9 |
| llama-2-7b-chat-hf | 11.3% | 88.7% | 99.6% | 119.9 |
| Microsoft wizardlm-2-8x22b | 11.7% | 88.3% | 99.9% | 140.8 |
| Coherea aya Expanse 8b | 12.2% | 87.8% | 99.9% | 83.9 |
| Amazon Titan-Express | 13.5% | 86.5% | 99.5% | 98.4 |
| Google Palm-2 | 14.1% | 85.9% | 99.8% | 86.6 |
| Google Gemma-7b-it | 14.8% | 85.2% | 100.0% | 113.0 |
| QWEN2.5-1.5B-Instruct | 15.8% | 84.2% | 100.0% | 70.7 |
| 人類のクロード-3-sonnet | 16.3% | 83.7% | 100.0% | 108.5 |
| Google Gemma-1.1-7B-It | 17.0% | 83.0% | 100.0% | 64.3 |
| 人類のクロード-2 | 17.4% | 82.6% | 99.3% | 87.5 |
| Google Flan-T5-Large | 18.3% | 81.7% | 99.3% | 20.9 |
| mixtral-8x7b-instruct-v0.1 | 20.1% | 79.9% | 99.9% | 90.7 |
| llama-3.2-1b-instruct | 20.7% | 79.3% | 100.0% | 71.5 |
| Apple Openelm-3B-Instruct | 24.8% | 75.2% | 99.3% | 47.2 |
| QWEN2.5-0.5B-Instruct | 25.2% | 74.8% | 100.0% | 72.6 |
| Google Gemma-1.1-2B-It | 27.8% | 72.2% | 100.0% | 66.8 |
| TII FALCON-7B-Instruct | 29.9% | 70.1% | 90.0% | 75.5 |
このリーダーボードは、Vectaraの商用幻覚評価モデルであるHHEM-2.1を使用して、LLMランキングを計算します。そのモデルのオープンソースのバリアントを見つけることができます。HHEM-2.1-OPEN HUGGING FACEとKAGGLEです。
モデルの評価に使用した生成された要約については、このデータセットを参照してください。
この分野での多くの事前の作業が行われました。この分野のトップペーパーのいくつか(要約における事実の一貫性)については、こちらをご覧ください。
非常に包括的なリストについては、https://github.com/edinburghnlp/awesome-hallucination-セクションを参照してください。次のセクションで説明されている方法は、他の多くの中で、これらの論文で確立されたプロトコルを使用しています。
このモデルに入った作業の詳細な説明については、リリースに関するブログ投稿を参照してください:Cut the Bull…。大規模な言語モデルでの幻覚の検出。
このリーダーボードを決定するために、事実上の一貫性研究から要約モデルのさまざまなオープンソースデータセットを使用して、LLM出力の幻覚を検出するためのモデルをトレーニングしました。最良の最先端モデルと競合するモデルを使用して、上記の各LMSに1000の短いドキュメントを公開APIを介して供給し、ドキュメントに提示された事実のみを使用して、各短い文書を要約するように依頼しました。これらの1000のドキュメントのうち、すべてのモデルによって要約されたドキュメントは831文書のみであり、残りのドキュメントは、コンテンツの制限により、少なくとも1つのモデルによって拒否されました。これらの831のドキュメントを使用して、各モデルの全体的な事実上の一貫性率(幻覚なし)と幻覚率(100 -精度)を計算しました。各モデルがプロンプトへの応答を拒否するレートは、「回答率」列に詳述されています。モデルに送信されたコンテンツには、違法または「仕事に安全ではない」コンテンツが含まれていませんでしたが、トリガーワードのプレゼントでは、一部のコンテンツフィルターをトリガーするのに十分でした。文書は、主にCNN / Daily Mail Corpusから取得されました。 LLMSを呼び出すときに0の温度を使用しました。
モデルの応答を提供された情報と比較できるため、全体的な事実上の精度ではなく、要約の事実の一貫性率を評価します。言い換えれば、ソースドキュメントと「事実上一貫した」提供される要約です。幻覚を決定することは、すべてのLLMがトレーニングされているデータを正確に知られていないため、アドホックな質問に対して行うことは不可能です。さらに、参照ソースなしで応答が幻覚化されたかどうかを判断できるモデルを使用するには、幻覚の問題を解決し、おそらくこれらのLLMが評価されているよりも大きいまたは大きいモデルをトレーニングする必要があります。したがって、私たちは代わりに、要約タスク内の幻覚率を調べることを選択しました。これは、モデルが全体的に真実であることを決定するための良いアナログであるためです。さらに、LLMは、Bing ChatやGoogleのチャット統合など、ユーザークエリに答えるために、RAG(検索拡張生成)パイプラインでますます使用されています。 RAGシステムでは、モデルは検索結果の要約として展開されているため、このリーダーボードは、RAGシステムで使用した場合のモデルの精度の適切な指標でもあります。
あなたはデータを使用して質問に答えるチャットボットです。提供されているパッセージのテキストによってのみ提供される回答に固執する必要があります。 「説明されたコアの情報をカバーする、次の文章の簡潔な要約を提供する」という質問があります。 <assion> '
APIを呼び出すと、<pass>トークンをソースドキュメントに置き換えました(このデータセットの「ソース」列を参照)。
以下は、統合されたモデルとそれらの特定のエンドポイントの詳細な概要です。
gpt-3.5-turboを使用して、特にchat.completions.create Endpointを使用してアクセスします。gpt-4と統合。gpt-4-turbo-2024-04-09で使用されています。gpt-4oを使用してアクセスします。gpt-4o-miniを使用してアクセスします。o1-miniを使用してアクセスします。o1-previewを使用してアクセスしますxxbが7b 、 13b 、および70bであるモデルmeta-llama/Llama-2-xxb-chat-hfを使用して、あらゆるスケールのホストエンドポイントからアクセスされます。xxB AI chatエンドポイントを介してアクセスし、モデルmeta-llama/Llama-3-xxB-chat-hfを使用してアクセス70Bれ8B 。Meta-Llama-3.1-405B-Instructは、モデルmeta/meta-llama-3.1-405b-instructを使用して、ReplicateのAPIを介してアクセスできます。Meta-Llama-3.2-3B-Instructはmeta-llama/Llama-3.2-3B-Instruct-Turboを使用して、一緒にAI chatエンドポイントを介してアクセスされます。Llama-3.2-11B-Vision-Instruct and Llama-3.2-90B-Vision-Instruct are accessed via Together AI chat endpoint using model meta-llama/Llama-3.2-11B-Vision-Instruct-Turbo and meta-llama/Llama-3.2-90B-Vision-Instruct-Turbo .command-r-08-2024および/chat Endpointを使用して使用されます。command-r-plus-08-2024および/chat Endpointを使用して使用されます。c4ai-aya-expanse-8bおよびc4ai-aya-expanse-32bを使用してアクセス。 Cohereのモデルの詳細については、Webサイトを参照してください。claude-2.0を使用してモデルを呼び出しました。claude-3-opus-20240229を使用してモデルを呼び出しました。claude-3-sonnet-20240229を使用してモデルを呼び出しました。claude-3-5-sonnet-20241022を使用してモデルを呼び出しました。claude-3-5-haiku-20241022を使用してモデルを呼び出しました。mistralai/Mixtral-8x22B-Instruct-v0.1とchatエンドポイントを使用して、一緒にAIのAPIを介してアクセスします。mistral-large-latestを使用してMistral AIのAPIを介してアクセスします。text-bison-001モデルを使用して実装されています。gemini-proモデルは、Vertex AIでアクセス可能で、強化された言語処理のために組み込まれています。gemini-1.5-pro-001を使用してアクセス。gemini-1.5-flash-001を使用してアクセス。gemini-1.5-pro-002を使用してアクセス。gemini-1.5-flash-002を使用してアクセス。各モデルのバージョンとライフサイクル、特にGoogleが提供するライフサイクルを詳細に理解するには、頂点AIのモデルバージョンとライフサイクルを参照してください。
amazon.titan-text-express-v1のモデル識別子を備えたAmazon Bedrockでアクセスされます。microsoft/WizardLM-2-8x22Bとchat Endpointを使用して、AIのAPIを一緒にアクセスします。databricks/dbrx-instructとchat Endpointを使用して、AIのAPIを一緒にアクセスします。snowflake/snowflake-arctic-instructを使用して、ReplicateのAPIを介してアクセスします。Qwen/Qwen2-72B-Instructを使用してAI chatエンドポイントを介してAccessed。deepseek-chatモデルとchatエンドポイントを使用して、DeepSeekのAPI経由でアクセスします。grok-betaとchat/completions Endpointを使用して、XaiのAPI経由でアクセスします。 qu。モデルを評価するためにモデルを使用しているのはなぜですか?
回答人間の評価に関してこれを行うことを選んだ理由はいくつかあります。大規模な人間のスケール評価をクラウドソーシングすることはできましたが、それは一度のことですが、新しいAPIがオンラインまたはモデルが更新されるにつれて、リーダーボードを絶えず更新できるようにすることはできません。私たちは速い移動分野で作業しているので、そのようなプロセスは公開されるとすぐにデータがなくなります。第二に、自分のモデルを評価する際に使用する多くのLLM品質スコアの1つとして自分で使用できるように、他の人と共有できる繰り返し可能なプロセスを望んでいました。これは、人間の注釈プロセスでは不可能です。ここでは、共有できるのはプロセスと人間のラベルだけです。また、幻覚を検出するためのモデルを構築することは、幻覚を生成しない生成モデルを構築するよりもはるかに簡単であることを指摘する価値があります。幻覚評価モデルが人間の評価者の判断と非常に相関している限り、それは人間の裁判官にとって良い代理として立つことができます。一般的な「閉じた本」の質問回答ではなく要約を標的にしているため、トレーニングしたLLMは、人間の知識の大部分を記憶する必要はありません。
qu。 LLMがドキュメントの要約を拒否するか、1つまたは2つの単語の答えを提供した場合はどうなりますか?
回答私たちはこれらを明示的にフィルタリングします。詳細については、ブログ投稿をご覧ください。要約されたドキュメントの割合を示す「回答率」列と、概要の長さを詳述する「平均要約長」列を見ることができます。
qu。どのバージョンのモデルXYZを使用しましたか?
回答モデルバージョンの詳細については、使用されたモデルバージョンとその呼び出し方法、およびリーダーボードが最後に更新された日付については、APIの詳細セクションをご覧ください。もっと明確にする必要がある場合は、お問い合わせください(リポジトリで問題を作成してください)。
qu。 XaiのGrok LLMはどうですか?
現在(11/14/2023の時点で)Grokは公開されておらず、アクセスできません。私が早期にアクセスできる人は、おそらくこの種の評価をモデルで行うことを法的に禁じられていると思います。モデルがパブリックAPIを介して利用可能になったら、それを追加して、十分に人気のある他のLLMとともに追加します。
qu。回答や非常に短い回答を提供することで、モデルは100%を獲得するだけではありませんか?
回答すべてのモデルからそのような応答を明示的にフィルタリングし、すべてのモデルが要約を提供したドキュメントでのみ最終評価を行いました。このトピックに関するブログ投稿で、その他の技術的な詳細をご覧ください。上の表の「回答率」と「平均要約長」列も参照してください。
qu。このタスクには、元の要約スコア100%(0の幻覚)からコピーして貼り付けている抽出要約モデルではありませんか?
定義上、絶対に答えて、そのようなモデルには幻覚がなく、忠実な要約を提供します。私たちは、要約の品質を評価しているとは言いません。これは、個別の直交課題であり、独立して評価する必要があります。ブログ投稿で指摘しているように、私たちは要約の品質を評価しているのではなく、それらの事実上の一貫性のみを評価しています。
qu。これは、元のテキストを要約としてコピーできるため、非常にハッキング可能なメトリックのようです
答え。それは本当ですが、たとえば、Kaggle競争のように、このアプローチで任意のモデルを評価していません。それを行うモデルは、あなたが気にする他のどのタスクでもパフォーマンスが低くなります。したがって、これは、要約品質、質問の精度など、モデルに対して他の評価が何であれ、どのような評価を実行しても実行する品質メトリックと考えますが、これをスタンドアロンメトリックとして使用することはお勧めしません。選択したモデルはいずれも、モデルの出力で訓練されていません。それは将来起こるかもしれませんが、モデルとソースドキュメントを更新する予定であるため、これは生きているリーダーボードであり、それはありそうもないことになります。ただし、これはLLMベンチマークの問題でもあります。また、これは、他の多くの学者がこのプロトコルを発明し洗練した事実の一貫性に関する大規模な作業に基づいていることを指摘する必要があります。このブログ投稿のsummacと真の論文への参照と、リソースのこの優れた編集-https://github.com/edinburghnlp/awesome-hallucination-セクションをご覧ください。
qu。これは、モデルが幻覚できるすべての方法を明確に測定するものではありません
答え。同意した。幻覚検出の問題を解決したとは主張しておらず、このプロセスをさらに拡大および強化する予定です。しかし、私たちはそれが正しい方向への動きであると信じており、誰もが上に構築できる非常に必要な出発点を提供します。
qu。いくつかのモデルは、要約中にのみ幻覚を起こす可能性があります。よく知られている事実のリストを提供して、それらをどれだけよく思い出すことができるかを確認できませんか?
答え。私の意見では、それは不十分なテストになるでしょう。一つには、モデルをトレーニングしない限り、トレーニングされたデータがわからないため、モデルが見た実際のデータや推測での応答を接地しているかどうかはわかりません。さらに、「よく知られている」の明確な定義はなく、これらのタイプのデータは通常、ほとんどのモデルが正確に想起するのが簡単です。私の明らかに主観的な経験では、ほとんどの幻覚は、非常にめったに知られていない、または議論されていない情報を取得するモデルから来ています。ソースデータを知らなくても、モデルはトレーニングされているため、この基準に適合するデータがわからないため、この種の幻覚を検証することは不可能です。また、モデルが要約中に幻覚のみをする可能性は低いと思います。私たちは、モデルに情報を取得し、ソースにまだ忠実な方法でそれを変換するように求めています。これは、要約以外の多くの生成タスクに類似しています(例:これらのポイントをカバーする電子メールを書く...)。モデルがプロンプトから逸脱している場合、それは指示に従うことができない場合、モデルがタスクに従って他の命令に苦労することを示します。
qu。これは良いスタートですが、決定的なものではありません
答え。私は完全に同意します。さらに多くのことを行う必要があり、問題は解決にはほど遠いものです。しかし、「良いスタート」とは、この分野で進歩が進むことを願っています。モデルを開くことで、コミュニティがこれを次のレベルに引き上げることを巻き込んでみたいと考えています。


