hallucination leaderboard
1.0.0
ลีดเดอร์บอร์ด LLM สาธารณะคำนวณโดยใช้รูปแบบการประเมินภาพหลอน Hughes ของ Vectara สิ่งนี้จะประเมินว่า LLM แนะนำภาพหลอนบ่อยแค่ไหนเมื่อสรุปเอกสาร เราวางแผนที่จะอัปเดตสิ่งนี้เป็นประจำเป็นรุ่นของเราและ LLM ได้รับการอัปเดตเมื่อเวลาผ่านไป
นอกจากนี้อย่าลังเลที่จะตรวจสอบลีดเดอร์บอร์ดภาพหลอนของเราที่กอดหน้า
การจัดอันดับในลีดเดอร์บอร์ดนี้คำนวณโดยใช้รูปแบบการประเมินภาพหลอน HHEM-2.1 หากคุณสนใจในลีดเดอร์บอร์ดก่อนหน้านี้ซึ่งมีพื้นฐานมาจาก HHEM-1.0 ก็มีอยู่ที่นี่
 | ในความรักความทรงจำของ Simon Mark Hughes ... |
อัปเดตล่าสุดเมื่อวันที่ 6 พฤศจิกายน 2567
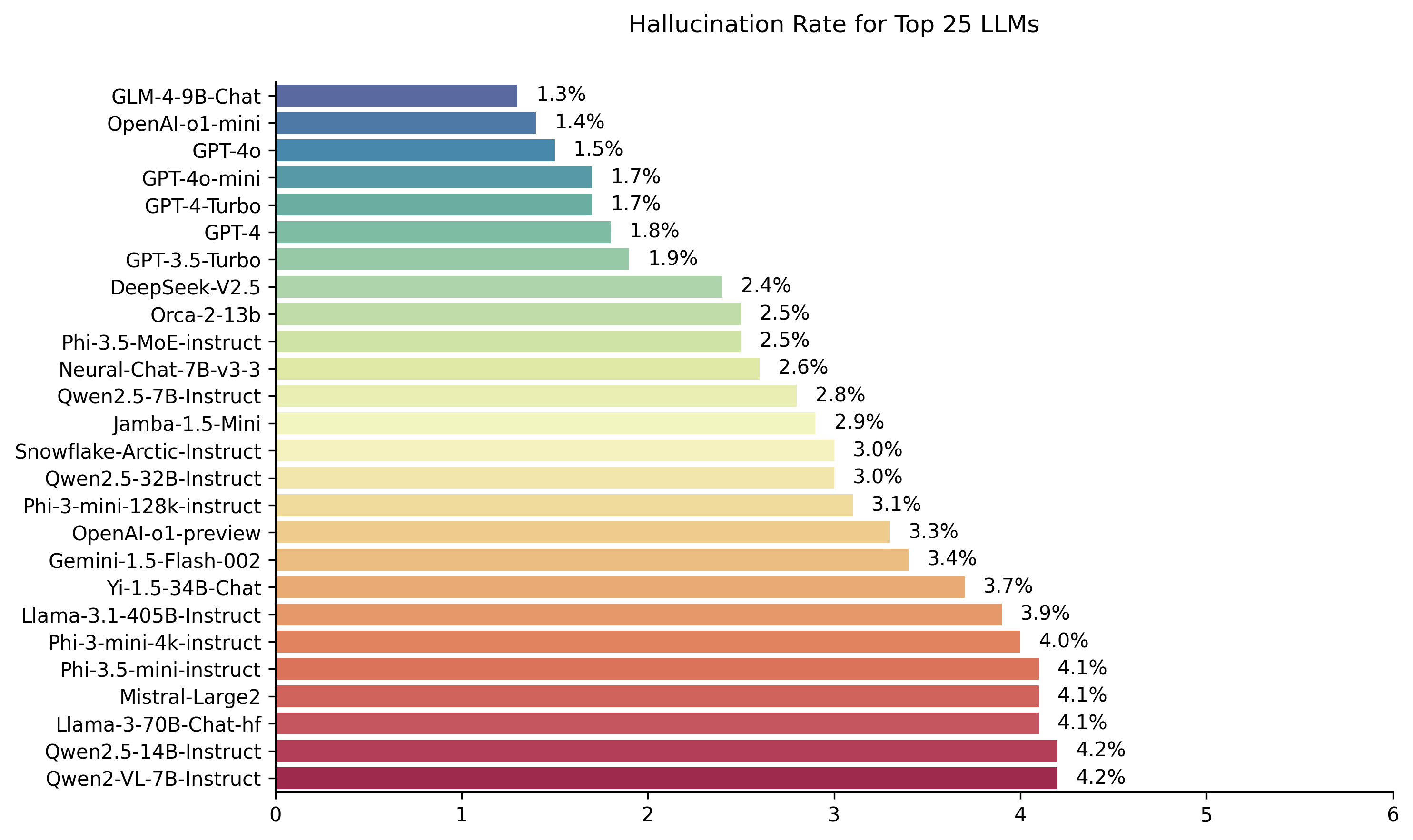
| แบบอย่าง | อัตราการหลอนหลอน | อัตราความสม่ำเสมอ | อัตราการตอบ | ความยาวสรุปเฉลี่ย (คำ) |
|---|---|---|---|---|
| zhipu ai glm-4-9b-chat | 1.3 % | 98.7 % | 100.0 % | 58.1 |
| Openai-O1-Mini | 1.4 % | 98.6 % | 100.0 % | 78.3 |
| GPT-4O | 1.5 % | 98.5 % | 100.0 % | 77.8 |
| GPT-4O-MINI | 1.7 % | 98.3 % | 100.0 % | 76.3 |
| GPT-4-turbo | 1.7 % | 98.3 % | 100.0 % | 86.2 |
| GPT-4 | 1.8 % | 98.2 % | 100.0 % | 81.1 |
| GPT-3.5-turbo | 1.9 % | 98.1 % | 99.6 % | 84.1 |
| DEEPSEEK-V2.5 | 2.4 % | 97.6 % | 100.0 % | 83.2 |
| Microsoft Orca-2-13b | 2.5 % | 97.5 % | 100.0 % | 66.2 |
| Microsoft Phi-3.5-Moe-Instruct | 2.5 % | 97.5 % | 96.3 % | 69.7 |
| Intel Neural-Chat-7b-V3-3 | 2.6 % | 97.4 % | 100.0 % | 60.7 |
| QWEN2.5-7B-Instruct | 2.8 % | 97.2 % | 100.0 % | 71.0 |
| AI21 JAMBA-1.5-MINI | 2.9 % | 97.1 % | 95.6 % | 74.5 |
| เกล็ดหิมะ | 3.0 % | 97.0 % | 100.0 % | 68.7 |
| QWEN2.5-32B-Instruct | 3.0 % | 97.0 % | 100.0 % | 67.9 |
| Microsoft Phi-3-Mini-128K-Instruct | 3.1 % | 96.9 % | 100.0 % | 60.1 |
| openai-o1-preview | 3.3 % | 96.7 % | 100.0 % | 119.3 |
| Google Gemini-1.5-Flash-002 | 3.4 % | 96.6 % | 99.9 % | 59.4 |
| 01-ai yi-1.5-34b-chat | 3.7 % | 96.3 % | 100.0 % | 83.7 |
| LLAMA-3.1-405B-Instruct | 3.9 % | 96.1 % | 99.6 % | 85.7 |
| Microsoft Phi-3-Mini-4K-Instruct | 4.0 % | 96.0 % | 100.0 % | 86.8 |
| Microsoft Phi-3.5-mini-Instruct | 4.1 % | 95.9 % | 100.0 % | 75.0 |
| mistral-large2 | 4.1 % | 95.9 % | 100.0 % | 77.4 |
| LLAMA-3-70B-Chat-HF | 4.1 % | 95.9 % | 99.2 % | 68.5 |
| QWEN2-VL-7B-Instruct | 4.2 % | 95.8 % | 100.0 % | 73.9 |
| QWEN2.5-14B-Instruct | 4.2 % | 95.8 % | 100.0 % | 74.8 |
| QWEN2.5-72B-Instruct | 4.3 % | 95.7 % | 100.0 % | 80.0 |
| LLAMA-3.2-90B-Vision-Instruct | 4.3 % | 95.7 % | 100.0 % | 79.8 |
| Xai Grok | 4.6 % | 95.4 % | 100.0 % | 91.0 |
| มานุษยวิทยา Claude-3-5-sonnet | 4.6 % | 95.4 % | 100.0 % | 95.9 |
| QWEN2-72B-Instruct | 4.7 % | 95.3 % | 100.0 % | 100.1 |
| MixTRAL-8X22B-Instruct-V0.1 | 4.7 % | 95.3 % | 99.9 % | 92.0 |
| มานุษยวิทยา Claude-3-5-Haiku | 4.9 % | 95.1 % | 100.0 % | 92.9 |
| 01-ai yi-1.5-9b-chat | 4.9 % | 95.1 % | 100.0 % | 85.7 |
| cohere command-r | 4.9 % | 95.1 % | 100.0 % | 68.7 |
| LLAMA-3.1-70B-Instruct | 5.0 % | 95.0 % | 100.0 % | 79.6 |
| LLAMA-3.1-8B-Instruct | 5.4 % | 94.6 % | 100.0 % | 71.0 |
| cohere command-r-plus | 5.4 % | 94.6 % | 100.0 % | 68.4 |
| Llama-3.2-11b-Vision-Instruct | 5.5 % | 94.5 % | 100.0 % | 67.3 |
| LLAMA-2-70B-Chat-HF | 5.9 % | 94.1 % | 99.9 % | 84.9 |
| IBM Granite-3.0-8B-Instruct | 6.5 % | 93.5 % | 100.0 % | 74.2 |
| Google Gemini-1.5-Pro-002 | 6.6 % | 93.7 % | 99.9 % | 62.0 |
| Google Gemini-1.5-Flash | 6.6 % | 93.4 % | 99.9 % | 63.3 |
| Microsoft Phi-2 | 6.7 % | 93.3 % | 91.5 % | 80.8 |
| Google Gemma-2-2b-it | 7.0 % | 93.0 % | 100.0 % | 62.2 |
| QWEN2.5-3B-Instruct | 7.0 % | 93.0 % | 100.0 % | 70.4 |
| LLAMA-3-8B-Chat-HF | 7.4 % | 92.6 % | 99.8 % | 79.7 |
| Google Gemini-Pro | 7.7 % | 92.3 % | 98.4 % | 89.5 |
| 01-ai yi-1.5-6b-chat | 7.9 % | 92.1 % | 100.0 % | 98.9 |
| LLAMA-3.2-3B-Instruct | 7.9 % | 92.1 % | 100.0 % | 72.2 |
| Databricks DBRX-Instruct | 8.3 % | 91.7 % | 100.0 % | 85.9 |
| QWEN2-VL-2B-Instruct | 8.3 % | 91.7 % | 100.0 % | 81.8 |
| Coeler Aya Expanse 32b | 8.5 % | 91.5 % | 99.9 % | 81.9 |
| IBM Granite-3.0-2B-Instruct | 8.8 % | 91.2 % | 100.0 % | 81.6 |
| MISTRAL-7B-Instruct-V0.3 | 9.5 % | 90.5 % | 100.0 % | 98.4 |
| Google Gemini-1.5-pro | 9.1 % | 90.9 % | 99.8 % | 61.6 |
| มานุษยวิทยา Claude-3-Opus | 10.1 % | 89.9 % | 95.5 % | 92.1 |
| Google Gemma-2-9b-it | 10.1 % | 89.9 % | 100.0 % | 70.2 |
| llama-2-13b-chat-hf | 10.5 % | 89.5 % | 99.8 % | 82.1 |
| Mistral-Nemo-Instruct | 11.2 % | 88.8 % | 100.0 % | 69.9 |
| llama-2-7b-chat-hf | 11.3 % | 88.7 % | 99.6 % | 119.9 |
| Microsoft Wizardlm-2-8x22b | 11.7 % | 88.3 % | 99.9 % | 140.8 |
| Coeler Aya Expanse 8b | 12.2 % | 87.8 % | 99.9 % | 83.9 |
| Amazon Titan-Express | 13.5 % | 86.5 % | 99.5 % | 98.4 |
| Google Palm-2 | 14.1 % | 85.9 % | 99.8 % | 86.6 |
| Google Gemma-7b-it | 14.8 % | 85.2 % | 100.0 % | 113.0 |
| QWEN2.5-1.5B-Instruct | 15.8 % | 84.2 % | 100.0 % | 70.7 |
| มานุษยวิทยา Claude-3-sonnet | 16.3 % | 83.7 % | 100.0 % | 108.5 |
| Google Gemma-1.1-7b-it | 17.0 % | 83.0 % | 100.0 % | 64.3 |
| มานุษยวิทยา Claude-2 | 17.4 % | 82.6 % | 99.3 % | 87.5 |
| Google Flan-T5 ขนาดใหญ่ | 18.3 % | 81.7 % | 99.3 % | 20.9 |
| MixTRAL-8X7B-Instruct-V0.1 | 20.1 % | 79.9 % | 99.9 % | 90.7 |
| LLAMA-3.2-1B-Instruct | 20.7 % | 79.3 % | 100.0 % | 71.5 |
| Apple OpenElm-3B-Instruct | 24.8 % | 75.2 % | 99.3 % | 47.2 |
| QWEN2.5-0.5B-Instruct | 25.2 % | 74.8 % | 100.0 % | 72.6 |
| Google Gemma-1.1-2b-it | 27.8 % | 72.2 % | 100.0 % | 66.8 |
| TII Falcon-7b-Instruct | 29.9 % | 70.1 % | 90.0 % | 75.5 |
กระดานผู้นำนี้ใช้ HHEM-2.1 รูปแบบการประเมินภาพหลอนเชิงพาณิชย์ของ Vectara เพื่อคำนวณการจัดอันดับ LLM คุณสามารถค้นหาตัวแปรโอเพนซอร์ซของรุ่นนั้นได้ Hhem-2.1-Open ในการกอดใบหน้าและ Kaggle
ดูชุดข้อมูลนี้สำหรับบทสรุปที่สร้างขึ้นที่เราใช้สำหรับการประเมินแบบจำลอง
งานก่อนหน้านี้มากในพื้นที่นี้ได้ทำไปแล้ว สำหรับเอกสารยอดนิยมในพื้นที่นี้ (ความสอดคล้องตามข้อเท็จจริงในการสรุป) โปรดดูที่นี่:
สำหรับรายการที่ครอบคลุมมากโปรดดูที่นี่-https://github.com/edinburghnlp/awesome-hallucination-etection วิธีการที่อธิบายไว้ในส่วนต่อไปนี้ใช้โปรโตคอลที่จัดตั้งขึ้นในเอกสารเหล่านั้นในหมู่คนอื่น ๆ อีกมากมาย
สำหรับคำอธิบายโดยละเอียดของงานที่เข้าสู่รุ่นนี้โปรดดูโพสต์บล็อกของเราในการเปิดตัว: ตัดวัว…. การตรวจจับภาพหลอนในรูปแบบภาษาขนาดใหญ่
ในการพิจารณาลีดเดอร์บอร์ดนี้เราได้ฝึกอบรมแบบจำลองเพื่อตรวจจับภาพหลอนในเอาต์พุต LLM โดยใช้ชุดข้อมูลโอเพนซอร์สต่างๆจากการวิจัยความสอดคล้องที่เป็นจริงในรูปแบบการสรุป การใช้โมเดลที่แข่งขันกับแบบจำลองที่ทันสมัยที่สุดเราป้อนเอกสารสั้น ๆ 1,000 เอกสารให้กับ LLMs แต่ละตัวผ่าน API สาธารณะของพวกเขาและขอให้พวกเขาสรุปเอกสารสั้น ๆ แต่ละฉบับโดยใช้ข้อเท็จจริงที่นำเสนอในเอกสารเท่านั้น จากเอกสาร 1,000 ฉบับเหล่านี้มีเพียง 831 เอกสารที่สรุปโดยทุกรุ่นเอกสารที่เหลือถูกปฏิเสธอย่างน้อยหนึ่งรุ่นเนื่องจากข้อ จำกัด ของเนื้อหา จากการใช้เอกสาร 831 เหล่านี้เราจึงคำนวณอัตราความสอดคล้องโดยรวม (ไม่มีภาพหลอน) และอัตราการเกิดภาพหลอน (100 - ความแม่นยำ) สำหรับแต่ละรุ่น อัตราที่แต่ละรุ่นปฏิเสธที่จะตอบสนองต่อพรอมต์มีรายละเอียดในคอลัมน์ 'อัตราคำตอบ' ไม่มีเนื้อหาใดที่ส่งไปยังโมเดลที่มีเนื้อหาผิดกฎหมายหรือ 'ไม่ปลอดภัยสำหรับการทำงาน' แต่ปัจจุบันของคำเรียกทริกเกอร์ก็เพียงพอที่จะกระตุ้นตัวกรองเนื้อหาบางส่วน เอกสารถูกนำมาจาก CNN / Daily Mail Corpus เป็นหลัก เราใช้ อุณหภูมิ 0 เมื่อโทร LLMS
เราประเมินอัตราการสรุปความสอดคล้องจริงแทนความถูกต้องตามข้อเท็จจริงโดยรวมเพราะช่วยให้เราสามารถเปรียบเทียบการตอบสนองของโมเดลกับข้อมูลที่ให้ไว้ กล่าวอีกนัยหนึ่งคือบทสรุปที่ให้ไว้ 'สอดคล้องกับจริง' กับเอกสารต้นฉบับ การพิจารณาภาพหลอนเป็นไปไม่ได้ที่จะทำเพื่อคำถามเฉพาะกิจใด ๆ เนื่องจากไม่ทราบว่าข้อมูลทุกอย่างที่ LLM ได้รับการฝึกฝน นอกจากนี้การมีแบบจำลองที่สามารถตรวจสอบได้ว่าการตอบสนองใด ๆ นั้นเป็นภาพหลอนโดยไม่ต้องใช้แหล่งอ้างอิงจำเป็นต้องแก้ปัญหาภาพหลอนและการฝึกอบรมแบบจำลองที่มีขนาดใหญ่หรือใหญ่กว่า LLMs เหล่านี้ที่ได้รับการประเมิน ดังนั้นเราจึงเลือกที่จะดูอัตราการเกิดภาพหลอนภายในงานสรุปเนื่องจากนี่เป็นอะนาล็อกที่ดีในการพิจารณาว่าแบบจำลองโดยรวมนั้นเป็นความจริงอย่างไร นอกจากนี้ LLM ยังถูกนำมาใช้มากขึ้นในท่อ RAG (Generation Augmented Retrieval) เพื่อตอบคำถามของผู้ใช้เช่นใน Bing Chat และการรวมแชทของ Google ในระบบ RAG โมเดลกำลังถูกปรับใช้เป็นผู้สรุปผลการค้นหาดังนั้นกระดานผู้นำนี้ยังเป็นตัวบ่งชี้ที่ดีสำหรับความแม่นยำของโมเดลเมื่อใช้ในระบบ RAG
คุณคือแชทบอทตอบคำถามโดยใช้ข้อมูล คุณต้องยึดติดกับคำตอบที่ให้ไว้โดยข้อความในข้อความที่ให้ไว้เท่านั้น คุณถูกถามคำถามว่า 'ให้บทสรุปโดยย่อของข้อความต่อไปนี้ซึ่งครอบคลุมข้อมูลหลักของข้อมูลที่อธิบายไว้' <Passage> '
เมื่อเรียก API โทเค็น <passage> จะถูกแทนที่ด้วยเอกสารต้นฉบับ (ดูคอลัมน์ 'แหล่งที่มา' ในชุดข้อมูลนี้)
ด้านล่างนี้เป็นภาพรวมโดยละเอียดของโมเดลที่รวมเข้ากับจุดสิ้นสุดเฉพาะของพวกเขา:
gpt-3.5-turbo ผ่านห้องสมุดไคลเอนต์ Python ของ OpenAI โดยเฉพาะผ่านทาง chat.completions.create Endpointgpt-4gpt-4-turbo-2024-04-09 ตามชื่อของ OpenAIgpt-4ogpt-4o-minio1-minio1-previewmeta-llama/Llama-2-xxb-chat-hf ซึ่ง xxb สามารถเป็น 7b , 13b และ 70b ซึ่งเหมาะกับความสามารถของแต่ละรุ่นchat AI ร่วมกันและใช้ meta-llama/Llama-3-xxB-chat-hf รุ่นที่ xxB สามารถเป็น 8B และ 70BMeta-Llama-3.1-405B-Instruct สามารถเข้าถึงได้ผ่าน API ของ Replicate โดยใช้ meta/meta-llama-3.1-405b-instructMeta-Llama-3.2-3B-Instruct สามารถเข้าถึงได้ผ่านจุดสิ้นสุด chat AI ร่วมกันโดยใช้ meta-llama/Llama-3.2-3B-Instruct-TurboLlama-3.2-11B-Vision-Instruct และ Llama-3.2-90B-Vision-Instruct สามารถเข้าถึงได้ผ่านจุดสิ้นสุด chat AI ร่วมกันโดยใช้ meta-llama/Llama-3.2-11B-Vision-Instruct-Turbo meta-llama/Llama-3.2-90B-Vision-Instruct-Turbocommand-r-08-2024 และจุดสิ้นสุด /chatcommand-r-plus-08-2024 และจุดสิ้นสุด /chatc4ai-aya-expanse-8b และ c4ai-aya-expanse-32b สำหรับข้อมูลเพิ่มเติมเกี่ยวกับโมเดลของ Cohere โปรดดูที่เว็บไซต์ของพวกเขาclaude-2.0 สำหรับการโทร APIclaude-3-opus-20240229 สำหรับการโทร APIclaude-3-sonnet-20240229 สำหรับการโทร APIclaude-3-5-sonnet-20241022 สำหรับการโทร APIclaude-3-5-haiku-20241022 สำหรับการโทร APImistralai/Mixtral-8x22B-Instruct-v0.1 และจุดสิ้นสุด chatmistral-large-latesttext-bison-001 ตามลำดับgemini-pro ของ Google นั้นถูกรวมเข้าด้วยกันเพื่อการประมวลผลภาษาที่ปรับปรุงแล้วสามารถเข้าถึงได้บน Vertex AIgemini-1.5-pro-001 บน Vertex AIgemini-1.5-flash-001 บน Vertex AIgemini-1.5-pro-002 บน Vertex AIgemini-1.5-flash-002 บน Vertex AIสำหรับความเข้าใจในเชิงลึกเกี่ยวกับรุ่นและวงจรชีวิตของแต่ละรุ่นโดยเฉพาะอย่างยิ่งที่ Google เสนอให้โปรดดูรุ่นรุ่นและ Lifecycles บน Vertex AI
amazon.titan-text-express-v1microsoft/WizardLM-2-8x22B และจุดสิ้นสุด chatdatabricks/dbrx-instruct และจุดสิ้นสุด chatsnowflake/snowflake-arctic-instructchat AI ร่วมกันด้วยชื่อรุ่น Qwen/Qwen2-72B-Instructdeepseek-chat และจุดสิ้นสุด chatgrok-beta และจุดสิ้นสุด chat/completions Qu. ทำไมคุณถึงใช้แบบจำลองเพื่อประเมินแบบจำลอง?
คำตอบ มีหลายเหตุผลที่เราเลือกที่จะทำสิ่งนี้ผ่านการประเมินของมนุษย์ ในขณะที่เราสามารถทำการประเมินระดับมนุษย์ขนาดใหญ่ได้ แต่นั่นเป็นสิ่งเดียว แต่ก็ไม่ได้ปรับขนาดในลักษณะที่ช่วยให้เราอัปเดตลีดเดอร์บอร์ดอย่างต่อเนื่องเมื่อ API ใหม่มาออนไลน์หรือได้รับการปรับปรุง เราทำงานในฟิลด์ที่เคลื่อนไหวอย่างรวดเร็วดังนั้นกระบวนการดังกล่าวจะออกจากข้อมูลทันทีที่เผยแพร่ ประการที่สองเราต้องการกระบวนการทำซ้ำที่เราสามารถแบ่งปันกับผู้อื่นเพื่อให้พวกเขาสามารถใช้มันเองเป็นหนึ่งในคะแนนคุณภาพ LLM ที่ใช้เมื่อประเมินโมเดลของตนเอง สิ่งนี้จะเป็นไปไม่ได้กับกระบวนการอธิบายประกอบของมนุษย์ซึ่งสิ่งเดียวที่สามารถแบ่งปันได้คือกระบวนการและฉลากมนุษย์ นอกจากนี้ยังคุ้มค่าที่จะชี้ให้เห็นว่าการสร้างแบบจำลองสำหรับการตรวจจับภาพหลอนนั้น ง่ายกว่า การสร้างแบบจำลองการกำเนิดที่ไม่เคยสร้างภาพหลอน ตราบใดที่รูปแบบการประเมินภาพหลอนมีความสัมพันธ์อย่างมากกับการตัดสินของผู้ประเมินของมนุษย์ก็สามารถยืนเป็นพร็อกซีที่ดีสำหรับผู้พิพากษามนุษย์ เนื่องจากเรากำลังกำหนดเป้าหมายการสรุปโดยเฉพาะและไม่ใช่การตอบคำถาม 'หนังสือปิด' ทั่วไป LLM ที่เราได้รับการฝึกฝนไม่จำเป็นต้องจดจำสัดส่วนของความรู้ของมนุษย์เป็นจำนวนมากมันเพียงแค่ต้องเข้าใจและเข้าใจภาษาที่สนับสนุน (ปัจจุบันเป็นภาษาอังกฤษ แต่เราวางแผนที่จะขยายการครอบคลุมภาษาเมื่อเวลาผ่านไป)
Qu. จะเกิดอะไรขึ้นถ้า LLM ปฏิเสธที่จะสรุปเอกสารหรือให้คำตอบหนึ่งหรือสองคำ?
คำตอบ เรากรองสิ่งเหล่านี้อย่างชัดเจน ดูโพสต์บล็อกของเราสำหรับข้อมูลเพิ่มเติม คุณสามารถดูคอลัมน์ 'อัตราคำตอบ' บนกระดานผู้นำที่ระบุเปอร์เซ็นต์ของเอกสารสรุปและคอลัมน์ 'ความยาวสรุปเฉลี่ย' ที่มีรายละเอียดความยาวสรุปแสดงว่าเราไม่ได้รับคำตอบสั้น ๆ สำหรับเอกสารส่วนใหญ่
Qu. คุณใช้ XYZ รุ่นใด
คำตอบ โปรดดูส่วนรายละเอียด API สำหรับข้อมูลเฉพาะเกี่ยวกับรุ่นรุ่นที่ใช้และวิธีการที่พวกเขาถูกเรียกเช่นเดียวกับวันที่ลีดเดอร์บอร์ดได้รับการอัปเดตล่าสุด โปรดติดต่อเรา (สร้างปัญหาใน repo) หากคุณต้องการความชัดเจนมากขึ้น
Qu. แล้ว Grok LLM ของ Xai ล่ะ?
คำตอบ ปัจจุบัน (ณ วันที่ 11/14/2023) Grok ไม่เปิดเผยต่อสาธารณะและเราไม่สามารถเข้าถึงได้ ผู้ที่มีการเข้าถึง แต่เนิ่นๆฉันสงสัยว่าอาจถูกห้ามไม่ให้ทำการประเมินแบบนี้ในแบบจำลอง เมื่อโมเดลพร้อมใช้งานผ่าน API สาธารณะเราจะเพิ่มมันพร้อมกับ LLM อื่น ๆ ที่ได้รับความนิยมเพียงพอ
Qu. แบบจำลองไม่สามารถทำคะแนนได้ 100% โดยการให้คำตอบหรือคำตอบสั้น ๆ หรือไม่?
คำตอบ เรากรองคำตอบดังกล่าวอย่างชัดเจนจากทุกรุ่นทำการประเมินขั้นสุดท้ายเฉพาะในเอกสารที่ทุกรุ่นให้สรุป คุณสามารถค้นหารายละเอียดทางเทคนิคเพิ่มเติมในโพสต์บล็อกของเราในหัวข้อ ดูเพิ่มเติมที่คอลัมน์ 'อัตราคำตอบ' และ 'ความยาวสรุปเฉลี่ย' ในตารางด้านบน
Qu. จะไม่ใช่โมเดลสรุปสกัดที่เพียงแค่คัดลอกและวางจากคะแนนสรุปต้นฉบับ 100% (0 ภาพหลอน) ในงานนี้หรือไม่?
คำตอบ อย่างแน่นอนตามคำจำกัดความรูปแบบดังกล่าวจะไม่มีภาพหลอนและให้บทสรุปที่ซื่อสัตย์ เราไม่ได้อ้างว่าเป็นการประเมินคุณภาพการสรุปซึ่งเป็นงานที่แยกจากกันและ ตั้งฉาก และควรได้รับการประเมินอย่างอิสระ เรา ไม่ ได้ประเมินคุณภาพของบทสรุปเฉพาะ ความสอดคล้องที่เป็นจริง ของพวกเขาในขณะที่เราชี้ให้เห็นในโพสต์บล็อก
Qu. ดูเหมือนว่าเป็นตัวชี้วัดที่แฮ็กได้มากเพราะคุณสามารถคัดลอกข้อความต้นฉบับเป็นบทสรุปได้
คำตอบ. นั่นเป็นเรื่องจริง แต่เราไม่ได้ประเมินแบบจำลองโดยพลการในวิธีการนี้เช่นในการแข่งขัน Kaggle รูปแบบใด ๆ ที่ทำเช่นนั้นจะทำงานได้ไม่ดีในงานอื่น ๆ ที่คุณสนใจ ดังนั้นฉันจะพิจารณาสิ่งนี้เป็นตัวชี้วัดคุณภาพที่คุณจะทำงานควบคู่ไปกับการประเมินอื่น ๆ ที่คุณมีสำหรับแบบจำลองของคุณเช่นคุณภาพการสรุปความถูกต้องตอบคำถาม ฯลฯ แต่เราไม่แนะนำให้ใช้สิ่งนี้เป็นตัวชี้วัดแบบสแตนด์อโลน ไม่มีรุ่นใดที่เลือกได้รับการฝึกฝนเกี่ยวกับผลลัพธ์ของโมเดลของเรา สิ่งนี้อาจเกิดขึ้นในอนาคต แต่เมื่อเราวางแผนที่จะอัปเดตโมเดลและเอกสารต้นฉบับดังนั้นนี่คือกระดานผู้นำที่มีชีวิตซึ่งจะเกิดขึ้นไม่น่าเป็นไปได้ อย่างไรก็ตามนั่นก็เป็นปัญหากับเกณฑ์มาตรฐาน LLM ใด ๆ เราควรชี้ให้เห็นว่าสิ่งนี้สร้างขึ้นจากงานขนาดใหญ่เกี่ยวกับความสอดคล้องที่เป็นจริงซึ่งนักวิชาการอื่น ๆ อีกหลายคนคิดค้นและปรับปรุงโปรโตคอลนี้ ดูการอ้างอิงของเราเกี่ยวกับ Summac และ TRUE Papers ในโพสต์บล็อกนี้รวมถึงการรวบรวมทรัพยากรที่ยอดเยี่ยมนี้-https://github.com/edinburghnlp/awesome-hallucination-etection เพื่ออ่านเพิ่มเติม
Qu. สิ่งนี้ไม่ได้วัดวิธีการทั้งหมดที่โมเดลสามารถเห็นภาพหลอนได้อย่างแน่นอน
คำตอบ. ตกลง เราไม่อ้างว่าได้แก้ไขปัญหาการตรวจจับภาพหลอนและวางแผนที่จะขยายและปรับปรุงกระบวนการนี้ต่อไป แต่เราเชื่อว่ามันเป็นการเคลื่อนไหวในทิศทางที่ถูกต้องและเป็นจุดเริ่มต้นที่จำเป็นมากที่ทุกคนสามารถสร้างได้
Qu. บางรุ่นสามารถเห็นภาพหลอนได้ในขณะที่สรุปเท่านั้น คุณไม่สามารถให้รายการข้อเท็จจริงที่รู้จักกันดีและตรวจสอบว่ามันสามารถจำได้ดีแค่ไหน?
คำตอบ. นั่นจะเป็นการทดสอบที่ไม่ดีในความคิดของฉัน สำหรับสิ่งหนึ่งเว้นแต่คุณจะได้รับการฝึกฝนแบบจำลองที่คุณไม่ทราบข้อมูลที่ได้รับการฝึกฝนดังนั้นคุณจึงไม่สามารถแน่ใจได้ว่าแบบจำลองกำลังตอบสนองการตอบสนองในข้อมูลจริงที่ได้เห็นหรือไม่ว่าจะเป็นการคาดเดา นอกจากนี้ยังไม่มีคำจำกัดความที่ชัดเจนของ 'ที่รู้จักกันดี' และข้อมูลประเภทนี้มักจะง่ายสำหรับรุ่นส่วนใหญ่ที่จะจำได้อย่างแม่นยำ ภาพหลอนส่วนใหญ่ในประสบการณ์ส่วนตัวที่เป็นที่ยอมรับของฉันมาจากข้อมูลการดึงข้อมูลที่ไม่ค่อยเป็นที่รู้จักหรือพูดคุยกันมากหรือข้อเท็จจริงที่โมเดลได้เห็นข้อมูลที่ขัดแย้งกัน โดยไม่ทราบข้อมูลต้นฉบับรูปแบบได้รับการฝึกฝนอีกครั้งมันเป็นไปไม่ได้ที่จะตรวจสอบภาพหลอนประเภทนี้เนื่องจากคุณไม่รู้ว่าข้อมูลใดที่เหมาะกับเกณฑ์นี้ ฉันยังคิดว่ามันไม่น่าเป็นไปได้ที่นางแบบจะเห็นภาพหลอนในขณะที่สรุป เรากำลังขอให้แบบจำลองใช้ข้อมูลและเปลี่ยนแปลงในแบบที่ยังคงซื่อสัตย์ต่อแหล่งที่มา สิ่งนี้คล้ายคลึงกับงานที่เกิดขึ้นมากมายนอกเหนือจากการสรุป (เช่นการเขียนอีเมลที่ครอบคลุมประเด็นเหล่านี้ ... ) และหากแบบจำลองเบี่ยงเบนจากพรอมต์นั่นคือความล้มเหลวในการทำตามคำแนะนำ
Qu. นี่เป็นการเริ่มต้นที่ดี แต่ห่างไกลจากที่ชัดเจน
คำตอบ. ฉันเห็นด้วยโดยสิ้นเชิง มีอีกมากที่ต้องทำและปัญหายังห่างไกลจากการแก้ไข แต่ 'การเริ่มต้นที่ดี' หมายความว่าหวังว่าความคืบหน้าจะเริ่มต้นขึ้นในพื้นที่นี้และโดยการจัดหาแบบเปิดเราหวังว่าจะเกี่ยวข้องกับชุมชนในการทำสิ่งนี้ไปสู่ระดับต่อไป


