hallucination leaderboard
1.0.0
Public LLM Leader Soble, вычисляется с использованием модели оценки Hughes Hughes Hughes Hallucination. Это оценивает, как часто LLM вводит галлюцинации при суммировании документа. Мы планируем регулярно обновлять это по мере того, как наша модель и LLMS обновляются с течением времени.
Кроме того, не стесняйтесь проверить нашу таблицу лидеров галлюцинации, обнимая лицо.
Рейтинги в этом таблице лидеров вычисляются с использованием модели оценки галлюцинации HHEM-2.1. Если вы заинтересованы в предыдущем таблице лидеров, которая была основана на HHEM-1.0, он доступен здесь
 | В любящей памяти Саймона Марка Хьюза ... |
Последнее обновление 6 ноября 2024 года
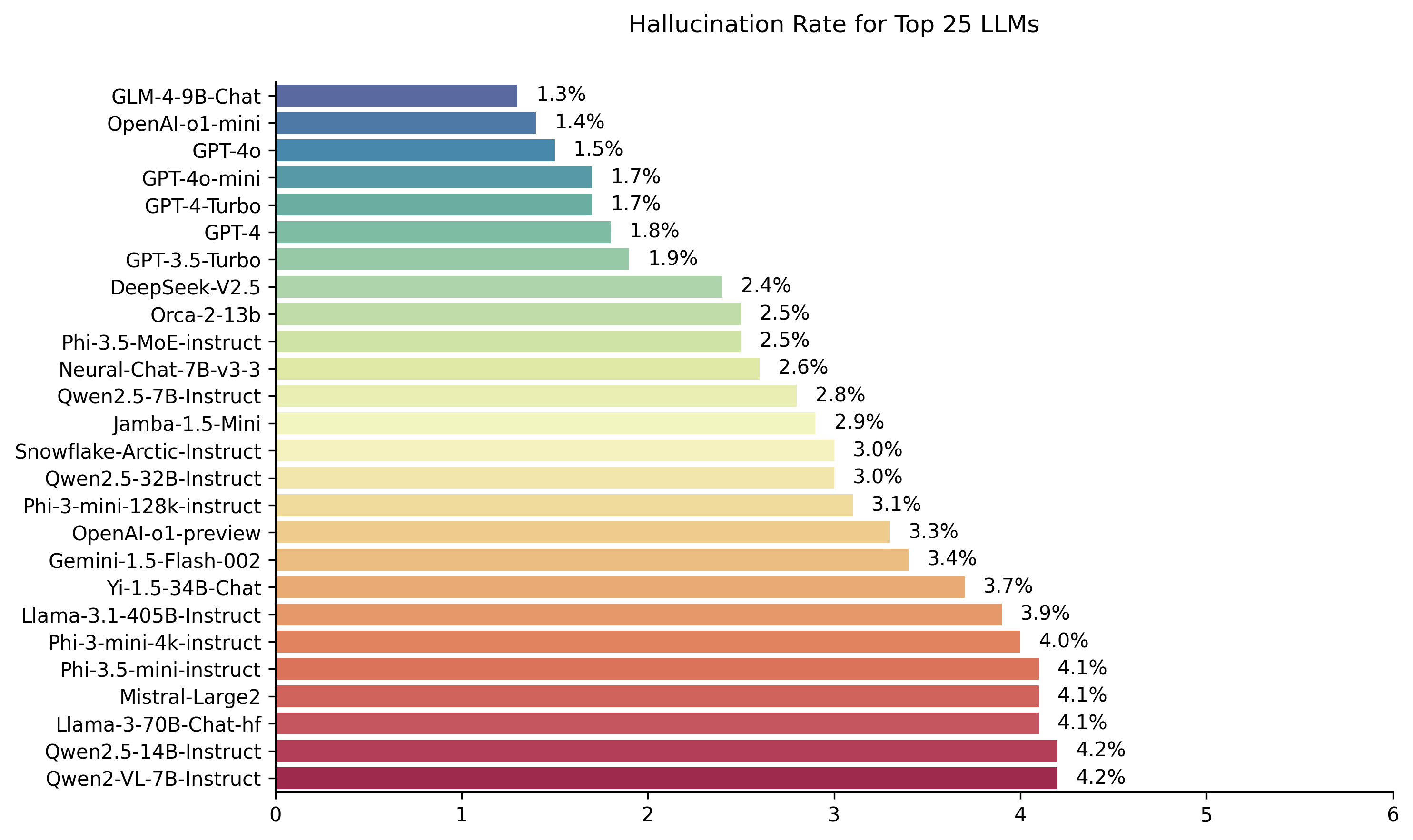
| Модель | Уровень галлюцинации | Фактический уровень согласованности | Скорость ответов | Средняя сводная длина (слова) |
|---|---|---|---|---|
| ZHIPU AI GLM-4-9B-чат | 1,3 % | 98,7 % | 100,0 % | 58.1 |
| Openai-O1-Mini | 1,4 % | 98,6 % | 100,0 % | 78.3 |
| GPT-4O | 1,5 % | 98,5 % | 100,0 % | 77.8 |
| GPT-4O-Mini | 1,7 % | 98,3 % | 100,0 % | 76.3 |
| GPT-4-Turbo | 1,7 % | 98,3 % | 100,0 % | 86.2 |
| GPT-4 | 1,8 % | 98,2 % | 100,0 % | 81.1 |
| GPT-3.5-Turbo | 1,9 % | 98,1 % | 99,6 % | 84.1 |
| DeepSeek-V2.5 | 2,4 % | 97,6 % | 100,0 % | 83,2 |
| Microsoft Orca-2-13b | 2,5 % | 97,5 % | 100,0 % | 66.2 |
| Microsoft PHI-3,5-ME-инструкт | 2,5 % | 97,5 % | 96,3 % | 69,7 |
| Intel Neural-Chat-7b-V3-3 | 2,6 % | 97,4 % | 100,0 % | 60.7 |
| Qwen2.5-7b-instruct | 2,8 % | 97,2 % | 100,0 % | 71.0 |
| AI21 Джамба-1,5-мино | 2,9 % | 97,1 % | 95,6 % | 74,5 |
| Снежинка-Арктика-Инструкция | 3,0 % | 97,0 % | 100,0 % | 68.7 |
| Qwen2.5-32b-instruct | 3,0 % | 97,0 % | 100,0 % | 67.9 |
| Microsoft Phi-3-Mini-128K-Instruct | 3,1 % | 96,9 % | 100,0 % | 60.1 |
| Openai-O1-Preview | 3,3 % | 96,7 % | 100,0 % | 119.3 |
| Google Gemini-1.5-Flash-002 | 3,4 % | 96,6 % | 99,9 % | 59,4 |
| 01-AI YI-1.5-34B-чат | 3,7 % | 96,3 % | 100,0 % | 83,7 |
| Llama-3.1-405b-instruct | 3,9 % | 96,1 % | 99,6 % | 85,7 |
| Microsoft Phi-3-Mini-4K-Instruct | 4,0 % | 96,0 % | 100,0 % | 86.8 |
| Microsoft PHI-3,5-минутная инстакция | 4,1 % | 95,9 % | 100,0 % | 75.0 |
| MISTRAL-LARGE2 | 4,1 % | 95,9 % | 100,0 % | 77.4 |
| Llama-3-70B-Chat-HF | 4,1 % | 95,9 % | 99,2 % | 68.5 |
| QWEN2-VL-7B-НАБЛЮДЕНИЕ | 4,2 % | 95,8 % | 100,0 % | 73,9 |
| QWEN2.5-14B-Instruct | 4,2 % | 95,8 % | 100,0 % | 74,8 |
| Qwen2.5-72b-instruct | 4,3 % | 95,7 % | 100,0 % | 80.0 |
| Лама-3,2-90B-визионер-инструкт | 4,3 % | 95,7 % | 100,0 % | 79,8 |
| Xai Grok | 4,6 % | 95,4 % | 100,0 % | 91.0 |
| Антропический Клод-3-5-Sonnet | 4,6 % | 95,4 % | 100,0 % | 95,9 |
| Qwen2-72b-instruct | 4,7 % | 95,3 % | 100,0 % | 100.1 |
| Mixtral-8x22b-Instruct-V0.1 | 4,7 % | 95,3 % | 99,9 % | 92.0 |
| Антропический Клод-3-5-Хайку | 4,9 % | 95,1 % | 100,0 % | 92,9 |
| 01-AI YI-1.5-9B-чат | 4,9 % | 95,1 % | 100,0 % | 85,7 |
| Команда-r | 4,9 % | 95,1 % | 100,0 % | 68.7 |
| Llama-3.1-70b-Instruct | 5,0 % | 95,0 % | 100,0 % | 79,6 |
| Лама-3.1-8B-Инструкция | 5,4 % | 94,6 % | 100,0 % | 71.0 |
| COMEHE COMAND-R-PLUS | 5,4 % | 94,6 % | 100,0 % | 68.4 |
| Лама-3,2-11B-визионер-инструкт | 5,5 % | 94,5 % | 100,0 % | 67.3 |
| Лама-2-70B-чат-Х.Ф. | 5,9 % | 94,1 % | 99,9 % | 84,9 |
| IBM Granite-3.0-8B-Instruct | 6,5 % | 93,5 % | 100,0 % | 74.2 |
| Google Gemini-1.5-Pro-002 | 6,6 % | 93,7 % | 99,9 % | 62,0 |
| Google Gemini-1.5-Flash | 6,6 % | 93,4 % | 99,9 % | 63,3 |
| Microsoft Phi-2 | 6,7 % | 93,3 % | 91,5 % | 80.8 |
| Google Gemma-2-2b-It | 7,0 % | 93,0 % | 100,0 % | 62,2 |
| Qwen2.5-3b-instruct | 7,0 % | 93,0 % | 100,0 % | 70.4 |
| Llama-3-8B-Chat-HF | 7,4 % | 92,6 % | 99,8 % | 79,7 |
| Google Gemini-Pro | 7,7 % | 92,3 % | 98,4 % | 89,5 |
| 01-AI YI-1.5-6B-Chat | 7,9 % | 92,1 % | 100,0 % | 98.9 |
| Лама-3.2-3B-Инструкция | 7,9 % | 92,1 % | 100,0 % | 72,2 |
| DataBricks dbrx-instruct | 8,3 % | 91,7 % | 100,0 % | 85,9 |
| QWEN2-VL-2B-Instruct | 8,3 % | 91,7 % | 100,0 % | 81.8 |
| COUCE AYA ARSANSE 32B | 8,5 % | 91,5 % | 99,9 % | 81.9 |
| IBM Granite-3.0-2B-Instruct | 8,8 % | 91,2 % | 100,0 % | 81.6 |
| MISTRAL-7B-INSTRUCT-V0.3 | 9,5 % | 90,5 % | 100,0 % | 98.4 |
| Google Gemini-1.5-Pro | 9,1 % | 90,9 % | 99,8 % | 61.6 |
| Антропический Клод-3-Опус | 10,1 % | 89,9 % | 95,5 % | 92.1 |
| Google Gemma-2-9b-It | 10,1 % | 89,9 % | 100,0 % | 70.2 |
| Лама-2-13B-чат-Х.Ф. | 10,5 % | 89,5 % | 99,8 % | 82.1 |
| Mistral-Nemy-Instruct | 11,2 % | 88,8 % | 100,0 % | 69,9 |
| Llama-2-7b-Chat-HF | 11,3 % | 88,7 % | 99,6 % | 119,9 |
| Microsoft Wizardlm-2-8x22b | 11,7 % | 88,3 % | 99,9 % | 140.8 |
| Объединить Aya Arvanse 8b | 12,2 % | 87,8 % | 99,9 % | 83,9 |
| Amazon Titan-Express | 13,5 % | 86,5 % | 99,5 % | 98.4 |
| Google Palm-2 | 14,1 % | 85,9 % | 99,8 % | 86.6 |
| Google Gemma-7b-it | 14,8 % | 85,2 % | 100,0 % | 113.0 |
| Qwen2.5-1.5b-instruct | 15,8 % | 84,2 % | 100,0 % | 70.7 |
| Антропический Клод-3-Sonnet | 16,3 % | 83,7 % | 100,0 % | 108.5 |
| Google Gemma-1.1-7b-It | 17,0 % | 83,0 % | 100,0 % | 64.3 |
| Антропический Клод-2 | 17,4 % | 82,6 % | 99,3 % | 87.5 |
| Google Flan-T5-Large | 18,3 % | 81,7 % | 99,3 % | 20.9 |
| Mixtral-8x7b-Instruct-V0.1 | 20,1 % | 79,9 % | 99,9 % | 90.7 |
| Лама-3,2-1B-Инструкция | 20,7 % | 79,3 % | 100,0 % | 71.5 |
| Apple OpenELM-3B-Instruct | 24,8 % | 75,2 % | 99,3 % | 47.2 |
| Qwen2.5-0.5b-instruct | 25,2 % | 74,8 % | 100,0 % | 72,6 |
| Google Gemma-1.1-2b-It | 27,8 % | 72,2 % | 100,0 % | 66.8 |
| TII Falcon-7B-Instruct | 29,9 % | 70,1 % | 90,0 % | 75,5 |
Эта таблица лидеров использует HHEM-2.1, модель коммерческой галлюцинации Vectara, для вычисления рейтинга LLM. Вы можете найти вариант с открытым исходным кодом этой модели, HHEM-2.1-OPEN на обнимающем лицо и Kaggle.
Смотрите этот набор данных для сгенерированных резюме, которые мы использовали для оценки моделей.
Большая предыдущая работа в этой области была сделана. Для некоторых из лучших работ в этой области (фактическая последовательность при суммировании), см. Здесь:
Очень полный список, см. Здесь-https://github.com/edinburghnlp/awesome-hallucination-detection. Методы, описанные в следующем разделе, используют протоколы, установленные в этих статьях, среди многих других.
Для получения подробного объяснения работы, которая вошла в эту модель, обратитесь к нашему сообщению в блоге о выпуске: вырезать быка…. Обнаружение галлюцинаций в моделях крупных языков.
Чтобы определить эту таблицу лидеров, мы обучили модель для обнаружения галлюцинаций в выходах LLM, используя различные наборы данных с открытым исходным кодом из фактических исследований согласованности в модели суммирования. Используя модель, которая конкурентоспособна с лучшим состоянием современных моделей, мы затем подали 1000 коротких документов в каждый из вышеуказанных LLM с помощью их публичных API и попросили их обобщить каждый короткий документ, используя только факты, представленные в документе. Из этих 1000 документов только 831 документ был обобщен по каждой модели, оставшиеся документы были отклонены по крайней мере одной моделью из -за ограничений на содержание. Используя эти 831 документы, мы затем вычислили общий уровень фактической согласованности (без галлюцинаций) и частоту галлюцинации (100 - точность) для каждой модели. Скорость, с которой каждая модель отказывается отвечать на подсказку, подробно описана в столбце «Скорость ответа». Ни один из контента, отправленных моделям, не содержал незаконного или «небезопасного для работы», но настоящего спусковых слов было достаточно, чтобы запустить некоторые из фильтров контента. Документы были взяты в основном из CNN / Daily Mail Corpus. Мы использовали температуру 0 при вызове LLMS.
Мы оцениваем суммирование фактической согласованности, а не общей фактической точностью, потому что она позволяет нам сравнивать ответ модели с предоставленной информацией. Другими словами, является резюме, предоставляемой «фактически согласованным» с исходным документом. Определение галлюцинаций невозможно сделать для любого специального вопроса, так как не известно, на что обучается каждый LLM. Кроме того, наличие модели, которая может определить, был ли какой -либо ответ галлюцинирован без эталонного источника, требует решения проблемы галлюцинации и, по -видимому, обучать модель как большую или больше, чем эти LLMS оценивают. Таким образом, мы решили посмотреть на частоту галлюцинации в задаче суммирования, так как это хороший аналог, чтобы определить, насколько правдивы модели в целом. Кроме того, LLMS все чаще используется в трубопроводах Rag (извлеченное изысканное образование), чтобы ответить на запросы пользователей, например, в Bing Chat и интеграции чата Google. В тряпичной системе модель развертывается в качестве суммификатора результатов поиска, поэтому эта таблица лидеров также является хорошим показателем точности моделей при использовании в RAG Systems.
Вы - чат -бот, отвечающий на вопросы, используя данные. Вы должны придерживаться ответов, предоставленных исключительно текстом в предоставленном отрывке. Вам задают вопрос: «Предоставьте краткую резюме следующего отрывка, охватывающего основные детали информации, описанные». <Проход> '
При вызове API токен <Stress> был затем заменен исходным документом (см. Столбец «Источник» в этом наборе данных).
Ниже приведен подробный обзор интегрированных моделей и их конкретных конечных точек:
gpt-3.5-turbo через клиентскую библиотеку Python OpenAI, в частности через конечную точку chat.completions.create .gpt-4 .gpt-4-turbo-2024-04-09 , в соответствии с документацией Openai.gpt-4o .gpt-4o-mini .o1-mini .o1-previewmeta-llama/Llama-2-xxb-chat-hf , где xxb может быть 7b , 13b и 70b , адаптированные к способности каждой модели.chat AI и используют модель meta-llama/Llama-3-xxB-chat-hf , где xxB может быть 8B и 70B .Meta-Llama-3.1-405B-Instruct доступна через API Replicate с использованием модели meta/meta-llama-3.1-405b-instruct .Meta-Llama-3.2-3B-Instruct доступна через конечную точку chat AI с использованием Model meta-llama/Llama-3.2-3B-Instruct-Turbo .Llama-3.2-11B-Vision-Instruct and Llama-3.2-90B-Vision-Instruct are accessed via Together AI chat endpoint using model meta-llama/Llama-3.2-11B-Vision-Instruct-Turbo and meta-llama/Llama-3.2-90B-Vision-Instruct-Turbo .command-r-08-2024 и конечной точки /chat .command-r-plus-08-2024 и конечной точки /chat .c4ai-aya-expanse-8b и c4ai-aya-expanse-32b . Для получения дополнительной информации о моделях Cohere обратитесь к их веб -сайту.claude-2.0 для вызова API.claude-3-opus-20240229 для вызова API.claude-3-sonnet-20240229 для вызова API.claude-3-5-sonnet-20241022 для вызова API.claude-3-5-haiku-20241022 для вызова API.mistralai/Mixtral-8x22B-Instruct-v0.1 и конечной точкой chat .mistral-large-latest .text-bison-001 , соответственно.gemini-pro 's Google включена для улучшенной языковой обработки, доступной для AI Vertex AI.gemini-1.5-pro-001 на вершине AI.gemini-1.5-flash-001 на вершине AI.gemini-1.5-pro-002 на вершине AI.gemini-1.5-flash-002 на вершине AI.Для глубокого понимания версии и жизненного цикла каждой модели, особенно тех, которые предлагаются Google, пожалуйста, обратитесь к модельным версиям и жизненным циклам на вершине AI.
amazon.titan-text-express-v1 .microsoft/WizardLM-2-8x22B и конечной точки chat .databricks/dbrx-instruct и конечной точки chat .snowflake/snowflake-arctic-instruct .chat Endpoint с именем модели Qwen/Qwen2-72B-Instruct .deepseek-chat и конечной точки chat .grok-beta и конечную точку chat/completions . QU. Почему вы используете модель для оценки модели?
Ответ Есть несколько причин, по которым мы решили сделать это по сравнению с человеческой оценкой. Несмотря на то, что мы могли бы провести краудсорсинговую оценку в масштабе человека, это одноразовая вещь, она не масштабируется таким образом, чтобы мы могли постоянно обновлять таблицу лидеров, когда новые API выходят в Интернет или модели обновляются. Мы работаем в быстро движущемся поле, поэтому любой такой процесс будет вне данных, как только он будет опубликован. Во -вторых, мы хотели повторяемый процесс, которым мы можем поделиться с другими, чтобы они могли использовать его самостоятельно как один из многих показателей качества LLM, которые они используют при оценке своих собственных моделей. Это было бы невозможно с процессом аннотации человека, где можно поделиться единственными вещами, это процесс и человеческие этикетки. Стоит также указать, что построение модели для обнаружения галлюцинаций намного проще, чем построить генеративную модель, которая никогда не производит галлюцинации. До тех пор, пока модель оценки галлюцинации сильно коррелирует с суждениями оценщиков человека, она может стать хорошим показателем для судей человека. Поскольку мы специально ориентируемся на суммирование, а не общий ответ «закрытая книга», отвечающий на вопрос LLM, который мы обучали, не нужно запоминать большую часть человеческих знаний, он просто должен иметь солидные понимания и понимания языков, которые он поддерживает (в настоящее время просто английский, но мы планируем расширить языковой охват с течением времени).
QU. Что, если LLM отказывается суммировать документ или предоставляет один или два ответа Word?
Ответ мы явно отфильтровали их. Смотрите наш пост в блоге для получения дополнительной информации. Вы можете увидеть столбец «Скорость ответа» в таблице лидеров, который указывает процент суммированных документов, а столбец «Средняя сводная длина» подробно описывает суммарные длины, показывая, что мы не получили очень короткие ответы для большинства документов.
QU. Какая версия модели XYZ вы использовали?
Ответьте , пожалуйста, см. Раздел «Подробная информация API», чтобы узнать подробности об используемых модельных версиях и о том, как они были вызваны, а также дату, когда таблица лидеров была обновлена в последний раз. Пожалуйста, свяжитесь с нами (создайте проблему в репо), если вам нужно больше ясности.
QU. Как насчет xai's grok llm?
Ответ в настоящее время (по состоянию на 14.11.2023) Grok не доступен публично, и у нас нет доступа. Те, у кого есть ранний доступ, я подозреваю, что, вероятно, юридически запрещены, проводя такую оценку на модели. После того, как модель будет доступна через публичный API, мы рассмотрим его, наряду с любыми другими LLM, которые достаточно популярны.
QU. Разве модель не может просто набрать 100%, не предоставляя ни ответов, ни очень коротких ответов?
Ответ Мы явно отфильтровали такие ответы из каждой модели, выполняя окончательную оценку только по документам, для которых все модели предоставили краткое изложение. Вы можете узнать больше технических деталей в нашем сообщении в блоге по теме. См. Также столбцы «Скорость ответа» и «Средняя сумма» в таблице выше.
QU. Разве не добывающая модель суммификатора, которая просто копирует и пасты из оригинальной суммы на 100% (0 галлуцинации) по этой задаче?
Ответьте абсолютно, как по определению, такая модель не будет иметь галлюцинаций и обеспечить верное резюме. Мы не утверждаем, что оцениваем качество суммирования, то есть отдельная и ортогональная задача, и должна быть оценена независимо. Мы не оцениваем качество резюме, только фактическую согласованность их, как мы указываем в сообщении в блоге.
QU. Это кажется очень взломанной метрикой, так как вы могли бы просто скопировать исходный текст в качестве резюме
Отвечать. Это правда, но мы не оцениваем произвольные модели по этому подходу, например, в конкуренции Kaggle. Любая модель, которая делает это, будет работать плохо при любой другой задаче, о которой вы заботитесь. Поэтому я бы считал это показателем качества, который вы проходите вместе с любыми другими оценками, которые вы имеете для вашей модели, например, качество суммирования, точность ответа на вопросы и т. Д. Но мы не рекомендуем использовать это в качестве автономной метрики. Ни одна из выбранных моделей не была обучена выходу нашей модели. Это может произойти в будущем, но когда мы планируем обновить модель, а также исходные документы, так что это живая таблица лидеров, это будет маловероятным явлением. Это также является проблемой с любым эталоном LLM. Мы также должны указать, что это основывается на большой работе над фактической последовательности, когда многие другие ученые изобрели и усовершенствовали этот протокол. Смотрите наши ссылки на Summac и True Papers в этом сообщении в блоге, а также об этом превосходном сборнике ресурсов-https://github.com/edinburghnlp/awesome-hallucination-detetion, чтобы прочитать больше.
QU. Это не окончательно измеряет все способы, которыми модель может галлюцинировать
Отвечать. Согласованный. Мы не утверждаем, что решили проблему обнаружения галлюцинации, и планируем расширить и расширять этот процесс дальше. Но мы считаем, что это движение в правильном направлении, и обеспечивает столь необходимую отправную точку, которую каждый может построить.
QU. Некоторые модели могут галлюцинаться только во время суммирования. Не могли бы вы просто предоставить ему список известных фактов и проверить, насколько хорошо это может их вспомнить?
Отвечать. По моему мнению, это было бы плохим тестом. Во -первых, если вы не обучили модель, вы не знаете данные, на которых она была обучена, поэтому вы не можете быть уверены, что модель заземляет свой ответ в реальных данных, на которых она видела, или он догадывается. Кроме того, нет четкого определения «хорошо известного», и эти типы данных, как правило, легко вспоминать большинство моделей. Большинство галлюцинаций, по моему признанию субъективного опыта, происходят из модели, которая извлекает информацию, которая очень редко известна или обсуждается, или факты, для которых модель видела противоречивая информация. Не зная исходных данных, на которые модель была обучена, опять же, невозможно проверить такие галлюцинации, поскольку вы не узнаете, какие данные соответствуют этому критерию. Я также думаю, что маловероятно, что модель будет только галлюцинирована при суммировании. Мы просим модель взять информацию и преобразовать ее таким образом, чтобы все еще верен источнику. Это аналогично множеству генеративных задач, помимо суммирования (например, напишите электронное письмо, охватывающее эти точки ...), и если модель отклоняется от подсказки, то это неспособность следовать инструкциям, указывая на то, что модель будет бороться с другими инструкциями, следующие за задачами.
QU. Это хорошее начало, но далеко не окончательное
Отвечать. Я полностью согласен. Есть гораздо больше, что нужно сделать, и проблема далеко не решена. Но «хороший старт» означает, что, надеюсь, прогресс начнет быть достигнут в этой области, и, открывая модель, мы надеемся привлечь сообщество к тому, чтобы поднять это на следующий уровень.


