hallucination leaderboard
1.0.0
Papan peringkat LLM publik dihitung menggunakan model evaluasi halusinasi Hughes Vectara. Ini mengevaluasi seberapa sering LLM memperkenalkan halusinasi saat merangkum dokumen. Kami berencana untuk memperbarui ini secara teratur karena model kami dan LLMS diperbarui dari waktu ke waktu.
Juga, jangan ragu untuk memeriksa papan peringkat halusinasi kami di wajah memeluk.
Peringkat di papan peringkat ini dihitung menggunakan model evaluasi halusinasi HHEM-2.1. Jika Anda tertarik dengan papan peringkat sebelumnya, yang didasarkan pada HHEM-1.0, tersedia di sini
 | Dalam memori cinta Simon Mark Hughes ... |
Terakhir diperbarui pada 6 November 2024
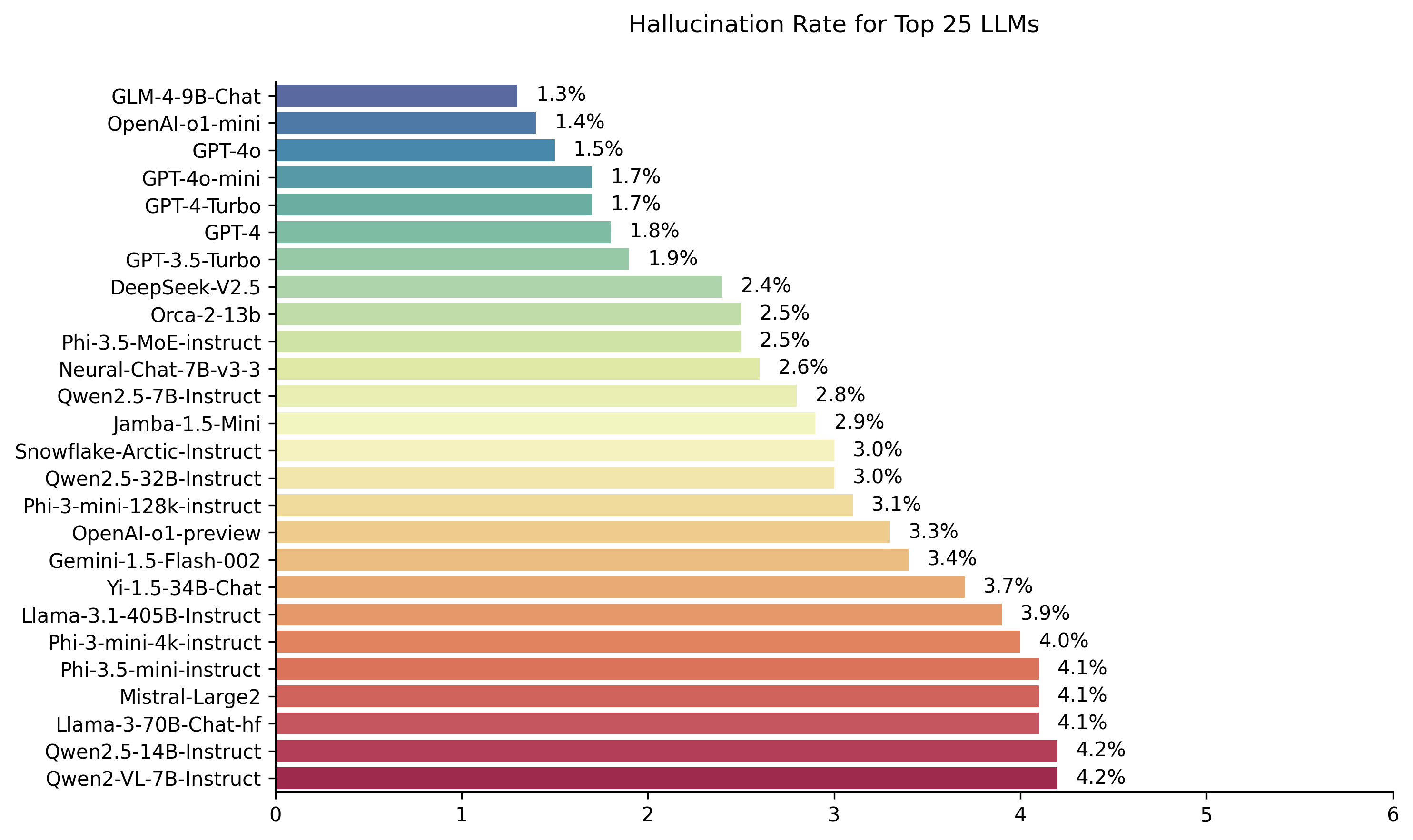
| Model | Tingkat halusinasi | Tingkat konsistensi faktual | Tingkat jawaban | Panjang ringkasan rata -rata (kata -kata) |
|---|---|---|---|---|
| Zhipu AI GLM-4-9B-CHAT | 1,3 % | 98,7 % | 100,0 % | 58.1 |
| OpenAI-O1-Mini | 1,4 % | 98,6 % | 100,0 % | 78.3 |
| GPT-4O | 1,5 % | 98,5 % | 100,0 % | 77.8 |
| GPT-4O-Mini | 1,7 % | 98,3 % | 100,0 % | 76.3 |
| GPT-4-turbo | 1,7 % | 98,3 % | 100,0 % | 86.2 |
| GPT-4 | 1,8 % | 98,2 % | 100,0 % | 81.1 |
| GPT-3.5-turbo | 1,9 % | 98,1 % | 99,6 % | 84.1 |
| Deepseek-V2.5 | 2,4 % | 97,6 % | 100,0 % | 83.2 |
| Microsoft orca-2-13b | 2,5 % | 97,5 % | 100,0 % | 66.2 |
| Microsoft phi-3.5-moe-instruct | 2,5 % | 97,5 % | 96,3 % | 69.7 |
| Intel Neural-CHAT-7B-V3-3 | 2,6 % | 97,4 % | 100,0 % | 60.7 |
| Qwen2.5-7b-instruct | 2,8 % | 97,2 % | 100,0 % | 71.0 |
| AI21 Jamba-1.5-mini | 2,9 % | 97,1 % | 95,6 % | 74.5 |
| Snowflake-Arktik-Instruksi | 3,0 % | 97,0 % | 100,0 % | 68.7 |
| Qwen2.5-32b-instruct | 3,0 % | 97,0 % | 100,0 % | 67.9 |
| Microsoft phi-3-mini-128k-instruct | 3,1 % | 96,9 % | 100,0 % | 60.1 |
| OpenAI-O1-Preview | 3,3 % | 96,7 % | 100,0 % | 119.3 |
| Google Gemini-1.5-Flash-002 | 3,4 % | 96,6 % | 99,9 % | 59.4 |
| 01-AI YI-1.5-34B-CHAT | 3,7 % | 96,3 % | 100,0 % | 83.7 |
| Llama-3.1-405b-instruct | 3,9 % | 96,1 % | 99,6 % | 85.7 |
| Microsoft phi-3-mini-4K-instruct | 4.0 % | 96,0 % | 100,0 % | 86.8 |
| Microsoft phi-3.5-mini-mini-instruct | 4.1 % | 95,9 % | 100,0 % | 75.0 |
| Mistral-Large2 | 4.1 % | 95,9 % | 100,0 % | 77.4 |
| Llama-3-70b-chat-hf | 4.1 % | 95,9 % | 99,2 % | 68.5 |
| QWEN2-VL-7B-INSTRUCT | 4,2 % | 95,8 % | 100,0 % | 73.9 |
| Qwen2.5-14b-instruct | 4,2 % | 95,8 % | 100,0 % | 74.8 |
| Qwen2.5-72b-instruct | 4,3 % | 95,7 % | 100,0 % | 80.0 |
| Llama-3.2-90b-vision-instruct | 4,3 % | 95,7 % | 100,0 % | 79.8 |
| Xai Grok | 4,6 % | 95,4 % | 100,0 % | 91.0 |
| Antropik Claude-3-5-Sonnet | 4,6 % | 95,4 % | 100,0 % | 95.9 |
| QWEN2-72B-INSTRUCT | 4,7 % | 95,3 % | 100,0 % | 100.1 |
| Mixtral-8x22b-instruct-V0.1 | 4,7 % | 95,3 % | 99,9 % | 92.0 |
| Antropik Claude-3-5-Haiku | 4,9 % | 95,1 % | 100,0 % | 92.9 |
| 01-AI YI-1.5-9B-CHAT | 4,9 % | 95,1 % | 100,0 % | 85.7 |
| Cohere command-r | 4,9 % | 95,1 % | 100,0 % | 68.7 |
| Llama-3.1-70b-instruct | 5,0 % | 95,0 % | 100,0 % | 79.6 |
| Llama-3.1-8b-instruct | 5,4 % | 94,6 % | 100,0 % | 71.0 |
| Cohere command-r-plus | 5,4 % | 94,6 % | 100,0 % | 68.4 |
| LLAMA-3.2-11B-Vision-instruct | 5,5 % | 94,5 % | 100,0 % | 67.3 |
| LLAMA-2-70B-CHAT-HF | 5,9 % | 94,1 % | 99,9 % | 84.9 |
| IBM Granite-3.0-8B-instruct | 6,5 % | 93,5 % | 100,0 % | 74.2 |
| Google Gemini-1.5-Pro-002 | 6,6 % | 93,7 % | 99,9 % | 62.0 |
| Google Gemini-1.5-Flash | 6,6 % | 93,4 % | 99,9 % | 63.3 |
| Microsoft Phi-2 | 6,7 % | 93,3 % | 91,5 % | 80.8 |
| Google Gemma-2-2b-it | 7,0 % | 93,0 % | 100,0 % | 62.2 |
| Qwen2.5-3b-instruct | 7,0 % | 93,0 % | 100,0 % | 70.4 |
| Llama-3-8b-chat-hf | 7,4 % | 92,6 % | 99,8 % | 79.7 |
| Google Gemini-Pro | 7,7 % | 92,3 % | 98,4 % | 89.5 |
| 01-AI YI-1.5-6B-CHAT | 7,9 % | 92,1 % | 100,0 % | 98.9 |
| Llama-3.2-3b-instruct | 7,9 % | 92,1 % | 100,0 % | 72.2 |
| Databricks DBRX-Instruksi | 8,3 % | 91,7 % | 100,0 % | 85.9 |
| QWEN2-VL-2B-INSTRUCT | 8,3 % | 91,7 % | 100,0 % | 81.8 |
| Cohere Aya Expanse 32b | 8,5 % | 91,5 % | 99,9 % | 81.9 |
| IBM Granite-3.0-2b-instruct | 8,8 % | 91,2 % | 100,0 % | 81.6 |
| Mistral-7b-instruct-V0.3 | 9,5 % | 90,5 % | 100,0 % | 98.4 |
| Google Gemini-1.5-Pro | 9,1 % | 90,9 % | 99,8 % | 61.6 |
| Antropik Claude-3-Opus | 10,1 % | 89,9 % | 95,5 % | 92.1 |
| Google Gemma-2-9b-it | 10,1 % | 89,9 % | 100,0 % | 70.2 |
| LLAMA-2-13B-CHAT-HF | 10,5 % | 89,5 % | 99,8 % | 82.1 |
| Mistral-Nemo-instruct | 11,2 % | 88,8 % | 100,0 % | 69.9 |
| LLAMA-2-7B-CHAT-HF | 11,3 % | 88,7 % | 99,6 % | 119.9 |
| Microsoft WizardLM-2-8X22B | 11,7 % | 88,3 % | 99,9 % | 140.8 |
| Cohere Aya Expanse 8b | 12,2 % | 87,8 % | 99,9 % | 83.9 |
| Amazon Titan-Express | 13,5 % | 86,5 % | 99,5 % | 98.4 |
| Google Palm-2 | 14,1 % | 85,9 % | 99,8 % | 86.6 |
| Google Gemma-7b-it | 14,8 % | 85,2 % | 100,0 % | 113.0 |
| Qwen2.5-1.5b-instruct | 15,8 % | 84,2 % | 100,0 % | 70.7 |
| Antropik Claude-3-Sonnet | 16,3 % | 83,7 % | 100,0 % | 108.5 |
| Google GEMMA-1.1-7B-IT | 17,0 % | 83,0 % | 100,0 % | 64.3 |
| Antropik Claude-2 | 17,4 % | 82,6 % | 99,3 % | 87.5 |
| Google Flan-T5-Large | 18,3 % | 81,7 % | 99,3 % | 20.9 |
| Mixtral-8x7b-instruct-V0.1 | 20,1 % | 79,9 % | 99,9 % | 90.7 |
| Llama-3.2-1b-instruct | 20,7 % | 79,3 % | 100,0 % | 71.5 |
| Apple OpenElm-3b-instruct | 24,8 % | 75,2 % | 99,3 % | 47.2 |
| Qwen2.5-0.5b-instruct | 25,2 % | 74,8 % | 100,0 % | 72.6 |
| Google GEMMA-1.1-2B-IT | 27,8 % | 72,2 % | 100,0 % | 66.8 |
| Tii falcon-7b-instruct | 29,9 % | 70,1 % | 90,0 % | 75.5 |
Papan peringkat ini menggunakan HHEM-2.1, model evaluasi halusinasi komersial Vectara, untuk menghitung peringkat LLM. Anda dapat menemukan varian open-source dari model itu, HHEM-2.1-Open pada memeluk wajah dan kaggle.
Lihat dataset ini untuk ringkasan yang dihasilkan yang kami gunakan untuk mengevaluasi model.
Banyak pekerjaan sebelumnya di bidang ini telah dilakukan. Untuk beberapa makalah teratas di bidang ini (konsistensi faktual dalam ringkasan) silakan lihat di sini:
Untuk daftar yang sangat komprehensif, silakan lihat di sini-https://github.com/edinburghnlp/awesome-hallucination-detection. Metode yang dijelaskan pada bagian berikut menggunakan protokol yang ditetapkan dalam makalah -makalah tersebut, di antara banyak lainnya.
Untuk penjelasan terperinci tentang karya yang masuk ke model ini, silakan merujuk ke posting blog kami pada rilis: Cut the Bull…. Mendeteksi halusinasi dalam model bahasa besar.
Untuk menentukan papan peringkat ini, kami melatih model untuk mendeteksi halusinasi dalam output LLM, menggunakan berbagai set data sumber terbuka dari penelitian konsistensi faktual ke dalam model peringkasan. Menggunakan model yang kompetitif dengan model seni canggih terbaik, kami kemudian memberi 1000 dokumen pendek untuk masing -masing LLM di atas melalui API publik mereka dan meminta mereka untuk merangkum setiap dokumen pendek, menggunakan hanya fakta yang disajikan dalam dokumen. Dari 1000 dokumen ini, hanya 831 dokumen yang dirangkum oleh setiap model, dokumen yang tersisa ditolak oleh setidaknya satu model karena pembatasan konten. Dengan menggunakan 831 dokumen ini, kami kemudian menghitung tingkat konsistensi faktual keseluruhan (tidak ada halusinasi) dan tingkat halusinasi (100 - akurasi) untuk setiap model. Tingkat di mana masing -masing model menolak untuk menanggapi prompt dirinci dalam kolom 'Tingkat Jawaban'. Tak satu pun dari konten yang dikirim ke model yang berisi konten ilegal atau 'tidak aman untuk pekerjaan' tetapi sekarang dari kata -kata pemicu sudah cukup untuk memicu beberapa filter konten. Dokumen -dokumen itu diambil terutama dari CNN / Daily Mail Corpus. Kami menggunakan suhu 0 saat memanggil LLMS.
Kami mengevaluasi ringkasan tingkat konsistensi faktual alih -alih akurasi faktual secara keseluruhan karena memungkinkan kami untuk membandingkan respons model terhadap informasi yang disediakan. Dengan kata lain, ringkasan disediakan 'secara faktual konsisten' dengan dokumen sumber. Menentukan halusinasi tidak mungkin dilakukan untuk pertanyaan ad hoc karena tidak diketahui dengan tepat data apa yang dilatih setiap LLM. Selain itu, memiliki model yang dapat menentukan apakah ada respons yang berhalusinasi tanpa sumber referensi memerlukan pemecahan masalah halusinasi dan mungkin melatih model yang besar atau lebih besar dari LLM ini dievaluasi. Jadi kami malah memilih untuk melihat tingkat halusinasi dalam tugas peringkasan karena ini adalah analog yang baik untuk menentukan seberapa jujur model secara keseluruhan. Selain itu, LLMS semakin banyak digunakan dalam RAG (Retrieval Augmented Generation) untuk menjawab pertanyaan pengguna, seperti di Bing Chat dan integrasi obrolan Google. Dalam sistem RAG, model ini digunakan sebagai ringkasan hasil pencarian, jadi papan peringkat ini juga merupakan indikator yang baik untuk keakuratan model ketika digunakan dalam sistem RAG.
Anda adalah bot obrolan menjawab pertanyaan menggunakan data. Anda harus tetap berpegang pada jawaban yang disediakan semata -mata oleh teks dalam bagian yang disediakan. Anda ditanya pertanyaan 'memberikan ringkasan ringkas dari bagian berikut, yang mencakup bagian -bagian inti dari informasi yang dijelaskan.' <setraft> '
Saat memanggil API, token <setra> kemudian diganti dengan dokumen sumber (lihat kolom 'Sumber' dalam dataset ini).
Di bawah ini adalah tinjauan terperinci dari model yang terintegrasi dan titik akhir spesifiknya:
gpt-3.5-turbo melalui Perpustakaan Klien Python OpenAI, khususnya melalui chat.completions.create Endpoint.gpt-4 .gpt-4-turbo-2024-04-09 , sejalan dengan dokumentasi Openai.gpt-4o .gpt-4o-mini .o1-mini .o1-previewmeta-llama/Llama-2-xxb-chat-hf , di mana xxb dapat menjadi 7b , 13b , dan 70b , disesuaikan dengan kapasitas masing-masing model.chat AI bersama dan menggunakan model meta-llama/Llama-3-xxB-chat-hf , di mana xxB dapat 8B dan 70B .Meta-Llama-3.1-405B-Instruct diakses melalui Replicate's API menggunakan model meta/meta-llama-3.1-405b-instruct .Meta-Llama-3.2-3B-Instruct diakses melalui titik akhir chat AI menggunakan model meta-llama/Llama-3.2-3B-Instruct-Turbo .Llama-3.2-11B-Vision-Instruct dan Llama-3.2-90B-Vision-Instruct diakses melalui titik akhir chat AI menggunakan model meta-llama/Llama-3.2-11B-Vision-Instruct-Turbo meta-llama/Llama-3.2-90B-Vision-Instruct-Turbo .command-r-08-2024 dan titik akhir /chat .command-r-plus-08-2024 dan titik akhir /chat .c4ai-aya-expanse-8b dan c4ai-aya-expanse-32b . Untuk informasi lebih lanjut tentang model Cohere, lihat situs web mereka.claude-2.0 untuk panggilan API.claude-3-opus-20240229 untuk panggilan API.claude-3-sonnet-20240229 untuk panggilan API.claude-3-5-sonnet-20241022 untuk panggilan API.claude-3-5-haiku-20241022 untuk panggilan API.mistralai/Mixtral-8x22B-Instruct-v0.1 dan titik akhir chat .mistral-large-latest .text-bison-001 , masing-masing.gemini-pro Google dimasukkan untuk pemrosesan bahasa yang ditingkatkan, dapat diakses pada Vertex AI.gemini-1.5-pro-001 pada Vertex AI.gemini-1.5-flash-001 pada vertex AI.gemini-1.5-pro-002 pada Vertex AI.gemini-1.5-flash-002 pada vertex AI.Untuk pemahaman mendalam tentang versi dan siklus hidup masing-masing model, terutama yang ditawarkan oleh Google, silakan merujuk ke versi model dan siklus hidup di vertex AI.
amazon.titan-text-express-v1 .microsoft/WizardLM-2-8x22B dan titik akhir chat .databricks/dbrx-instruct dan titik akhir chat .snowflake/snowflake-arctic-instruct .chat AI dengan nama model Qwen/Qwen2-72B-Instruct .deepseek-chat dan titik akhir chat .grok-beta dan titik akhir chat/completions . Qu. Mengapa Anda menggunakan model untuk mengevaluasi model?
Jawab Ada beberapa alasan kami memilih untuk melakukan ini melalui evaluasi manusia. Meskipun kami bisa melakukan crowdsourcing evaluasi skala manusia yang besar, itu adalah hal yang satu kali, itu tidak skala dengan cara yang memungkinkan kami untuk terus memperbarui papan peringkat saat API baru online atau model diperbarui. Kami bekerja di bidang yang bergerak cepat sehingga proses seperti itu akan keluar dari data segera setelah diterbitkan. Kedua, kami menginginkan proses berulang yang dapat kami bagikan dengan orang lain sehingga mereka dapat menggunakannya sendiri sebagai salah satu dari banyak skor kualitas LLM yang mereka gunakan ketika mengevaluasi model mereka sendiri. Ini tidak akan dimungkinkan dengan proses anotasi manusia, di mana satu -satunya hal yang dapat dibagikan adalah proses dan label manusia. Perlu juga menunjukkan bahwa membangun model untuk mendeteksi halusinasi jauh lebih mudah daripada membangun model generatif yang tidak pernah menghasilkan halusinasi. Selama model evaluasi halusinasi sangat berkorelasi dengan penilaian penilai manusia, ia dapat berdiri sebagai proksi yang baik bagi hakim manusia. Karena kami secara khusus menargetkan peringkasan dan bukan menjawab pertanyaan 'buku tertutup' umum, LLM yang kami latih tidak perlu menghafal sebagian besar pengetahuan manusia, ia hanya perlu memiliki pemahaman dan pemahaman yang kuat tentang bahasa yang didukungnya (saat ini hanya bahasa Inggris, tetapi kami berencana untuk memperluas liputan bahasa dari waktu ke waktu).
Qu. Bagaimana jika LLM menolak untuk meringkas dokumen atau memberikan jawaban satu atau dua kata?
Jawab Kami secara eksplisit memfilter ini. Lihat posting blog kami untuk informasi lebih lanjut. Anda dapat melihat kolom 'Tingkat Jawaban' di papan peringkat yang menunjukkan persentase dokumen yang dirangkum, dan kolom 'Ringkasan Panjang Ringkasan Rata -rata' yang merinci panjang ringkasan, menunjukkan bahwa kami tidak mendapatkan jawaban yang sangat singkat untuk sebagian besar dokumen.
Qu. Versi model XYZ apa yang Anda gunakan?
Jawaban Silakan lihat bagian Detail API untuk spesifik tentang versi model yang digunakan dan bagaimana mereka dipanggil, serta tanggal papan peringkat terakhir diperbarui. Silakan hubungi kami (buat masalah di repo) jika Anda membutuhkan lebih banyak kejelasan.
Qu. Bagaimana dengan Xai's Grok LLM?
Jawaban saat ini (pada 11/14/2023) Grok tidak tersedia untuk umum dan kami tidak memiliki akses. Mereka yang memiliki akses awal yang saya duga mungkin dilarang secara hukum melakukan evaluasi semacam ini pada model. Setelah model tersedia melalui API publik, kami akan mencari untuk menambahkannya, bersama dengan LLM lain yang cukup populer.
Qu. Tidak bisakah model hanya mencetak 100% dengan tidak memberikan jawaban atau jawaban yang sangat singkat?
Jawaban Kami secara eksplisit menyaring tanggapan tersebut dari setiap model, melakukan evaluasi akhir hanya pada dokumen yang semua model memberikan ringkasan. Anda dapat menemukan lebih banyak detail teknis di posting blog kami tentang topik tersebut. Lihat juga kolom 'Tingkat Jawaban' dan 'Panjang Ringkasan Rata -rata' dalam tabel di atas.
Qu. Bukankah model Summarizer ekstraktif yang hanya menyalin dan menempel dari skor ringkasan asli 100% (0 halusinasi) pada tugas ini?
Jawaban sepenuhnya sebagai definisi model seperti itu tidak akan memiliki halusinasi dan memberikan ringkasan yang setia. Kami tidak mengklaim mengevaluasi kualitas ringkasan, itu adalah tugas yang terpisah dan ortogonal , dan harus dievaluasi secara mandiri. Kami tidak mengevaluasi kualitas ringkasan, hanya konsistensi faktual dari mereka, seperti yang kami tunjukkan dalam posting blog.
Qu. Ini tampaknya metrik yang sangat dapat diretas, karena Anda bisa menyalin teks asli sebagai ringkasan
Menjawab. Itu benar tetapi kami tidak mengevaluasi model sewenang -wenang pada pendekatan ini, misalnya seperti dalam kompetisi kaggle. Model apa pun yang melakukannya akan berkinerja buruk pada tugas lain yang Anda pedulikan. Jadi saya akan menganggap ini sebagai metrik kualitas yang akan Anda jalankan bersama evaluasi lain apa pun yang Anda miliki untuk model Anda, seperti kualitas ringkasan, akurasi menjawab pertanyaan, dll. Tetapi kami tidak merekomendasikan menggunakan ini sebagai metrik mandiri. Tidak ada model yang dipilih yang dilatih pada output model kami. Itu mungkin terjadi di masa depan tetapi ketika kami berencana untuk memperbarui model dan juga dokumen sumber sehingga ini adalah papan peringkat yang hidup, itu akan menjadi kejadian yang tidak mungkin. Namun itu juga merupakan masalah dengan tolok ukur LLM apa pun. Kita juga harus menunjukkan hal ini dibangun di atas banyak pekerjaan pada konsistensi faktual di mana banyak akademisi lain menemukan dan menyempurnakan protokol ini. Lihat referensi kami ke Summac dan Makalah Sejati dalam posting blog ini, serta kompilasi sumber daya yang sangat baik ini-https://github.com/edinburghnlp/awesome-hallucination-detection untuk membaca lebih lanjut.
Qu. Ini tidak secara definitif mengukur semua cara model dapat berhalusinasi
Menjawab. Sepakat. Kami tidak mengklaim telah memecahkan masalah deteksi halusinasi, dan berencana untuk memperluas dan meningkatkan proses ini lebih lanjut. Tapi kami percaya ini adalah langkah ke arah yang benar, dan memberikan titik awal yang sangat dibutuhkan yang dapat dibangun oleh semua orang di atas.
Qu. Beberapa model hanya bisa berhalusinasi saat merangkum. Tidak bisakah Anda memberikannya daftar fakta -fakta terkenal dan memeriksa seberapa baik itu dapat mengingatnya?
Menjawab. Itu akan menjadi ujian yang buruk menurut saya. Untuk satu hal, kecuali Anda melatih model, Anda tidak tahu data yang dilatih, jadi Anda tidak dapat memastikan model tersebut mendasari responsnya dalam data nyata yang telah dilihatnya atau apakah itu menebak. Selain itu, tidak ada definisi yang jelas tentang 'terkenal', dan jenis data ini biasanya mudah untuk diingat secara akurat. Sebagian besar halusinasi, dalam pengalaman subyektif saya yang diakui, berasal dari model mengambil informasi yang sangat jarang diketahui atau dibahas, atau fakta yang modelnya telah melihat informasi yang bertentangan. Tanpa mengetahui data sumber model dilatih, sekali lagi tidak mungkin untuk memvalidasi halusinasi semacam ini karena Anda tidak akan tahu data mana yang sesuai dengan kriteria ini. Saya juga berpikir tidak mungkin model hanya akan berhalusinasi saat meringkas. Kami meminta model untuk mengambil informasi dan mengubahnya dengan cara yang masih setia pada sumbernya. Ini analog dengan banyak tugas generatif selain dari ringkasan (misalnya menulis email yang mencakup poin -poin ini ...), dan jika model menyimpang dari prompt maka itu adalah kegagalan untuk mengikuti instruksi, menunjukkan model akan berjuang pada instruksi lain yang mengikuti tugas juga.
Qu. Ini adalah awal yang baik tetapi jauh dari definitif
Menjawab. Saya sangat setuju. Ada banyak lagi yang perlu dilakukan, dan masalahnya masih jauh dari terpecahkan. Tetapi 'awal yang baik' berarti bahwa semoga kemajuan akan mulai dibuat di bidang ini, dan dengan sumber terbuka model, kami berharap dapat melibatkan masyarakat untuk membawa ini ke tingkat berikutnya.


