hallucination leaderboard
1.0.0
使用Vectara的Hughes幻觉评估模型计算的公共LLM排行榜。这评估了LLM总结文档时引入幻觉的频率。我们计划随着模型和LLM的更新,定期更新此信息。
另外,请随时在拥抱脸上查看我们的幻觉排行榜。
该排行榜中的排名是使用HHEM-2.1幻觉评估模型计算的。如果您对基于HHEM-1.0的以前的排行榜感兴趣,则可以在此处使用
 | 为了记忆西蒙·马克·休斯(Simon Mark Hughes)... |
最后一次更新于2024年11月6日
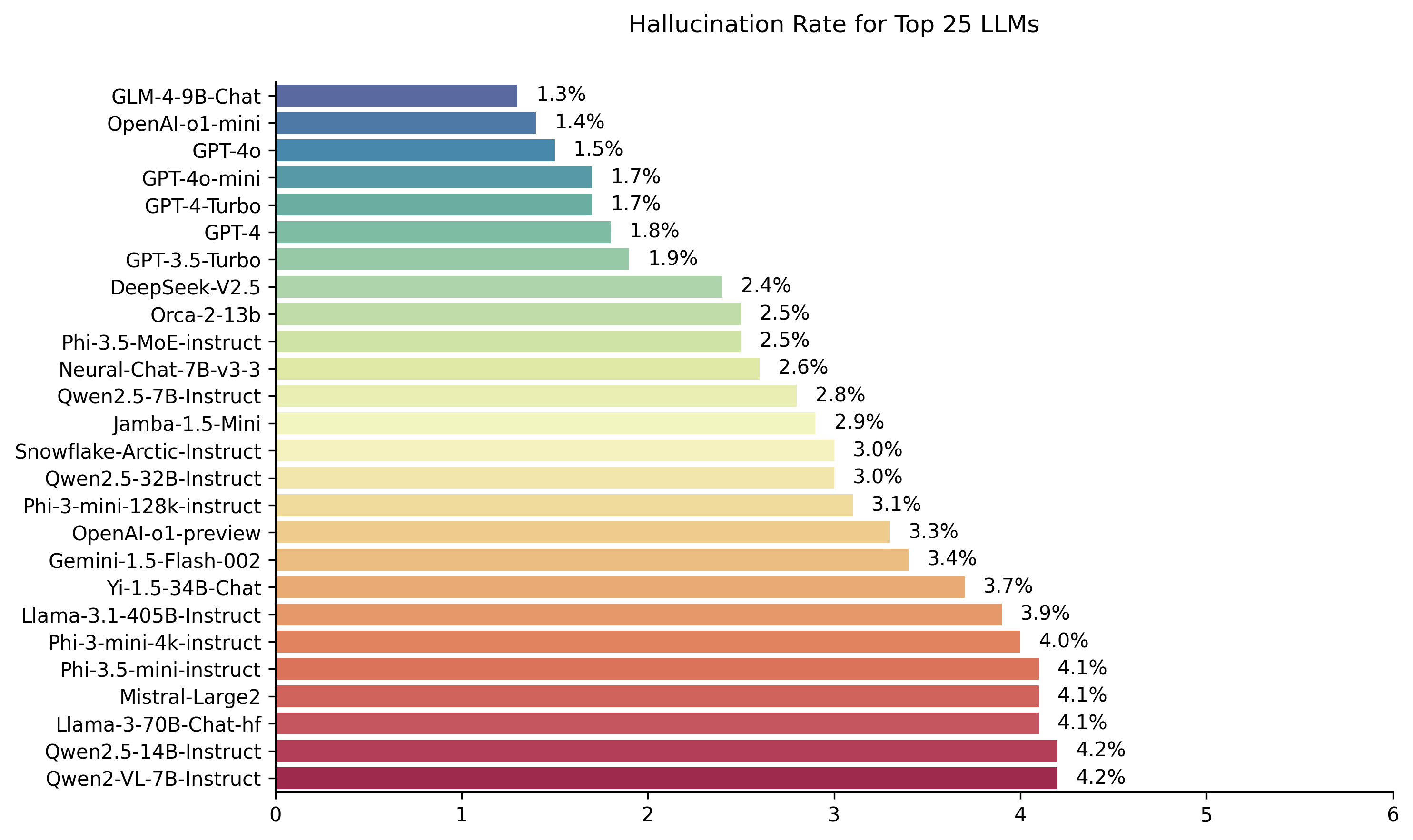
| 模型 | 幻觉率 | 事实一致性率 | 答案率 | 平均摘要长度(单词) |
|---|---|---|---|---|
| Zhipu ai glm-4-9b-chat | 1.3% | 98.7% | 100.0% | 58.1 |
| Openai-O1-Mini | 1.4% | 98.6% | 100.0% | 78.3 |
| GPT-4O | 1.5% | 98.5% | 100.0% | 77.8 |
| GPT-4O-Mini | 1.7% | 98.3% | 100.0% | 76.3 |
| GPT-4-turbo | 1.7% | 98.3% | 100.0% | 86.2 |
| GPT-4 | 1.8% | 98.2% | 100.0% | 81.1 |
| GPT-3.5-Turbo | 1.9% | 98.1% | 99.6% | 84.1 |
| DeepSeek-V2.5 | 2.4% | 97.6% | 100.0% | 83.2 |
| Microsoft Orca-2-13b | 2.5% | 97.5% | 100.0% | 66.2 |
| Microsoft Phi-3.5-Moe-Instruct | 2.5% | 97.5% | 96.3% | 69.7 |
| 英特尔神经chat-7b-v3-3 | 2.6% | 97.4% | 100.0% | 60.7 |
| QWEN2.5-7B-INSTRUCT | 2.8% | 97.2% | 100.0% | 71.0 |
| AI21 jamba-1.5米尼 | 2.9% | 97.1% | 95.6% | 74.5 |
| 雪花北极教堂 | 3.0% | 97.0% | 100.0% | 68.7 |
| QWEN2.5-32B-INSTRUCT | 3.0% | 97.0% | 100.0% | 67.9 |
| Microsoft PHI-3-MINI-128K教学 | 3.1% | 96.9% | 100.0% | 60.1 |
| OpenAi-O1-preiview | 3.3% | 96.7% | 100.0% | 119.3 |
| Google Gemini-1.5-Flash-002 | 3.4% | 96.6% | 99.9% | 59.4 |
| 01-ai yi-1.5-34b-chat | 3.7% | 96.3% | 100.0% | 83.7 |
| Llama-3.1-405b-Instruct | 3.9% | 96.1% | 99.6% | 85.7 |
| Microsoft PHI-3-MINI-4K教学 | 4.0% | 96.0% | 100.0% | 86.8 |
| Microsoft Phi-3.5-Mini Instruct | 4.1% | 95.9% | 100.0% | 75.0 |
| Mistral-large2 | 4.1% | 95.9% | 100.0% | 77.4 |
| Llama-3-70B-Chat-HF | 4.1% | 95.9% | 99.2% | 68.5 |
| QWEN2-VL-7B-INSTRUCT | 4.2% | 95.8% | 100.0% | 73.9 |
| QWEN2.5-14B教学 | 4.2% | 95.8% | 100.0% | 74.8 |
| QWEN2.5-72B-INSTRUCT | 4.3% | 95.7% | 100.0% | 80.0 |
| Llama-3.2-90b-Vision-Instruct | 4.3% | 95.7% | 100.0% | 79.8 |
| Xai Grok | 4.6% | 95.4% | 100.0% | 91.0 |
| 人类Claude-3-5-Sonnet | 4.6% | 95.4% | 100.0% | 95.9 |
| QWEN2-72B-INSTRUCT | 4.7% | 95.3% | 100.0% | 100.1 |
| Mixtral-8x22b-instruct-v0.1 | 4.7% | 95.3% | 99.9% | 92.0 |
| 人类Claude-3-5-Haiku | 4.9% | 95.1% | 100.0% | 92.9 |
| 01-ai yi-1.5-9b-chat | 4.9% | 95.1% | 100.0% | 85.7 |
| cohere command-r | 4.9% | 95.1% | 100.0% | 68.7 |
| Llama-3.1-70B教学 | 5.0% | 95.0% | 100.0% | 79.6 |
| Llama-3.1-8B教学 | 5.4% | 94.6% | 100.0% | 71.0 |
| cohere Command-R-Plus | 5.4% | 94.6% | 100.0% | 68.4 |
| Llama-3.2-11b-Vision-Instruct | 5.5% | 94.5% | 100.0% | 67.3 |
| Llama-2-70B-Chat-HF | 5.9% | 94.1% | 99.9% | 84.9 |
| IBM Granite-3.0-8B教学 | 6.5% | 93.5% | 100.0% | 74.2 |
| Google Gemini-1.5-Pro-002 | 6.6% | 93.7% | 99.9% | 62.0 |
| Google Gemini-1.5-Flash | 6.6% | 93.4% | 99.9% | 63.3 |
| Microsoft PHI-2 | 6.7% | 93.3% | 91.5% | 80.8 |
| Google Gemma-2-2b-it | 7.0% | 93.0% | 100.0% | 62.2 |
| QWEN2.5-3B-INSTRUCT | 7.0% | 93.0% | 100.0% | 70.4 |
| Llama-3-8B-Chat-HF | 7.4% | 92.6% | 99.8% | 79.7 |
| Google Gemini-Pro | 7.7% | 92.3% | 98.4% | 89.5 |
| 01-ai yi-1.5-6b-chat | 7.9% | 92.1% | 100.0% | 98.9 |
| Llama-3.2-3b-Instruct | 7.9% | 92.1% | 100.0% | 72.2 |
| Databricks DBRX-Instruct | 8.3% | 91.7% | 100.0% | 85.9 |
| qwen2-vl-2b-instruct | 8.3% | 91.7% | 100.0% | 81.8 |
| cohere aya扩展32b | 8.5% | 91.5% | 99.9% | 81.9 |
| IBM Granite-3.0-2b-thiminct | 8.8% | 91.2% | 100.0% | 81.6 |
| MISTRAL-7B-INSTRUCT-V0.3 | 9.5% | 90.5% | 100.0% | 98.4 |
| Google Gemini-1.5-Pro | 9.1% | 90.9% | 99.8% | 61.6 |
| 人类Claude-3-opus | 10.1% | 89.9% | 95.5% | 92.1 |
| Google Gemma-2-9b-it | 10.1% | 89.9% | 100.0% | 70.2 |
| Llama-2-13b-chat-hf | 10.5% | 89.5% | 99.8% | 82.1 |
| Mistral-Nemo-Instruct | 11.2% | 88.8% | 100.0% | 69.9 |
| Llama-2-7b-chat-hf | 11.3% | 88.7% | 99.6% | 119.9 |
| Microsoft Wizardlm-2-8x22b | 11.7% | 88.3% | 99.9% | 140.8 |
| cohere aya扩展8b | 12.2% | 87.8% | 99.9% | 83.9 |
| 亚马逊泰坦表达 | 13.5% | 86.5% | 99.5% | 98.4 |
| Google Palm-2 | 14.1% | 85.9% | 99.8% | 86.6 |
| Google Gemma-7b-it | 14.8% | 85.2% | 100.0% | 113.0 |
| QWEN2.5-1.5B-INSTRUCT | 15.8% | 84.2% | 100.0% | 70.7 |
| 人类Claude-3-sonnet | 16.3% | 83.7% | 100.0% | 108.5 |
| Google Gemma-1.1-7b-it | 17.0% | 83.0% | 100.0% | 64.3 |
| 拟人化的克劳德-2 | 17.4% | 82.6% | 99.3% | 87.5 |
| Google flan-t5大 | 18.3% | 81.7% | 99.3% | 20.9 |
| Mixtral-8x7b-instruct-v0.1 | 20.1% | 79.9% | 99.9% | 90.7 |
| Llama-3.2-1b-trustinct | 20.7% | 79.3% | 100.0% | 71.5 |
| Apple OpenElm-3B教学 | 24.8% | 75.2% | 99.3% | 47.2 |
| QWEN2.5-0.5B-INSTRUCT | 25.2% | 74.8% | 100.0% | 72.6 |
| Google Gemma-1.1-2b-it | 27.8% | 72.2% | 100.0% | 66.8 |
| TII Falcon-7b-Instruct | 29.9% | 70.1% | 90.0% | 75.5 |
该排行榜使用Vectara的商业幻觉评估模型HHEM-2.1来计算LLM排名。您可以在拥抱脸和Kaggle上找到该型号的开源变体HHEM-2.1-OPEN。
有关我们用于评估模型的生成摘要,请参见此数据集。
在这一领域已经做了许多先前的工作。有关该领域的一些高级论文(摘要中的事实一致性),请参见:
有关非常全面的列表,请参阅此处-https://github.com/edinburghnlp/awesome-hallacination-detection。下一节中描述的方法使用这些论文中建立的协议,以及其他许多论文。
有关此模型中的工作的详细说明,请参阅我们有关发行版的博客文章:Cut the Bull…。在大语言模型中检测幻觉。
为了确定此排行榜,我们使用了从事实一致性研究中的各种开源数据集中培训了一个模型来检测LLM输出中的幻觉。然后,我们使用与最佳最佳模型竞争的模型,然后通过其公共API向上方的每个LLM喂了1000个简短文档,并要求他们总结每个简短文档,仅使用文档中介绍的事实。在这1000个文档中,每个模型只汇总了831个文件,其余文档由于内容限制而被至少一个模型拒绝。然后,使用这些831个文档,我们计算了每个模型的总体事实一致性率(无幻觉)和幻觉率(100-精度)。 “答案率”列中详细介绍了每个模型拒绝响应提示的速率。发送给模型的内容都不包含非法或“不安全的工作”内容,但是触发单词的当下足以触发某些内容过滤器。这些文件主要来自CNN / Daily Mail语料库。调用LLM时,我们使用的温度为0 。
我们评估汇总的事实一致性率,而不是总体事实准确性,因为它使我们可以比较模型对所提供信息的响应。换句话说,是与源文档“事实一致”提供的摘要。对于任何临时问题,确定幻觉是不可能做的,因为不确定每个LLM都经过了哪些数据。此外,拥有一个可以确定任何响应是否在没有参考源的情况下幻觉的模型就需要解决幻觉问题,并且大概比评估这些LLM大的模型训练模型。因此,我们选择在摘要任务中查看幻觉速度,因为这是一个很好的模拟,以确定模型的整体方式。此外,LLM越来越多地用于抹布(检索增强生成)管道中,以回答用户查询,例如Bing Chat和Google的聊天集成。在抹布系统中,该模型正在作为搜索结果的摘要部署,因此该排行榜也是在抹布系统中使用的模型准确性的良好指标。
您是一个使用数据回答问题的聊天机器人。您必须坚持仅由所提供的段落中的文本提供的答案。询问您的问题“提供了以下段落的简明摘要,涵盖了所描述的核心信息。” <通道>'
调用API时,然后将<vassage>令牌替换为源文档(请参阅此数据集中的“源”列)。
以下是集成模型及其特定端点的详细概述:
gpt-3.5-turbo访问,特别是通过chat.completions.create Endpoint访问。gpt-4集成。gpt-4-turbo-2024-04-09使用,与OpenAI的文档一致。gpt-4o访问。gpt-4o-mini访问。o1-mini访问。o1-preview访问meta-llama/Llama-2-xxb-chat-hf这些不同尺寸的这些型号,其中XXB可以为每种型号的容量量身定制xxb为7b , 13b和70b 。chat端点访问,并使用型号meta-llama/Llama-3-xxB-chat-hf ,其中xxB可以为8B和70B 。Meta-Llama-3.1-405B-Instruct通过复制的API访问模型meta/meta-llama-3.1-405b-instruct 。meta-llama/Llama-3.2-3B-Instruct-Turbo Meta-Llama-3.2-3B-Instruct -Instruct-turbo通过AI chat端点访问Meta-Lalama-3.2-3b-Instruct。Llama-3.2-11B-Vision-Instruct和Llama-3.2-90B-Vision-Instruct使用AI chat端点访问,使用meta-llama/Llama-3.2-11B-Vision-Instruct-Turbo和meta-llama/Llama-3.2-90B-Vision-Instruct-Turbo 。command-r-08-2024和/chat Endpoint使用。command-r-plus-08-2024和/chat Endpoint使用。c4ai-aya-expanse-8b和c4ai-aya-expanse-32b访问。有关Cohere模型的更多信息,请参阅其网站。claude-2.0进行API调用调用模型。claude-3-opus-20240229用于API调用,调用了模型。claude-3-sonnet-20240229进行API调用,调用了该模型。claude-3-5-sonnet-20241022调用API调用的模型。claude-3-5-haiku-20241022调用模型,以进行API调用。mistralai/Mixtral-8x22B-Instruct-v0.1和chat端点的模型通过AI的API访问。mistral-large-latest模型通过Mistral AI的API访问。text-bison-001模型实施。gemini-pro模型已合并用于增强语言处理,可在Vertex AI上访问。gemini-1.5-pro-001访问。gemini-1.5-flash-001访问。gemini-1.5-pro-002访问。gemini-1.5-flash-002访问。要深入了解每个模型的版本和生命周期,尤其是Google提供的版本,请参阅顶点AI上的模型版本和生命周期。
amazon.titan-text-express-v1的Amazon Bedrock上访问。microsoft/WizardLM-2-8x22B和chat端点通过AI的API一起访问。databricks/dbrx-instruct和chat Endpoint通过AI的API访问。snowflake/snowflake-arctic-instruct通过Replicate的API访问。chat端点与模型名称Qwen/Qwen2-72B-Instruct一起使用。deepseek-chat模型和chat端点通过DeepSeek的API访问。grok-beta和chat/completions端点通过XAI的API访问。 qu。您为什么使用模型来评估模型?
回答我们选择通过人类评估来做到这一点的原因有很多。尽管我们可能会进行大量的人类规模评估,但这是一次性的事情,但它并不能以使我们能够随着新API的到线或更新模型的更新而不断更新排行榜的方式进行扩展。我们在一个快速移动的字段中工作,因此任何此类过程都将在发布后立即脱离数据。其次,我们想要一个可重复的过程,我们可以与他人共享,以便他们可以将其用作评估自己的模型时使用的许多LLM质量分数之一。通过人类注释过程,这是不可能的,在该过程中,唯一可以共享的东西是过程和人类标签。还值得指出的是,建立用于检测幻觉的模型要比建立从未产生幻觉的生成模型要容易得多。只要幻觉评估模型与人类评估者的判断高度相关,它就可以成为人类法官的良好代理。由于我们专门针对摘要,而不是一般的“封闭式书籍”问题回答,因此我们训练的LLM不需要记住大量的人类知识,因此它只需要对其支持的语言有牢固的掌握和理解(目前只是英语,但我们计划随着时间的推移扩展语言覆盖范围)即可。
qu。如果LLM拒绝总结文档或提供一个或两个单词答案该怎么办?
回答我们明确过滤这些。有关更多信息,请参见我们的博客文章。您可以在排行榜上看到“答案率”列,以指示摘要的文档百分比,以及详细说明摘要长度的“平均摘要长度”列,表明我们对大多数文档没有很短的答案。
qu。您使用了哪种版本的XYZ?
答案请参见API详细信息部分,以获取有关所使用的型号版本及其所调用的详细信息,以及排行榜最后更新的日期。如果您需要更多的清晰度,请与我们联系(在存储库中创建问题)。
qu。 Xai的Grok LLM呢?
当前的答案(截至2023年11月14日)无法公开使用,我们无法访问。我怀疑那些有早期访问的人可能是法律上禁止在模型上进行这种评估的。一旦通过公共API获得该模型,我们将考虑添加它,以及其他足够受欢迎的LLM。
qu。模型不能仅通过提供答案或很短的答案来得分100%吗?
答案我们明确过滤了每个模型中的此类响应,仅对所有模型提供摘要的文档进行最终评估。您可以在我们有关该主题的博客文章中找到更多技术细节。另请参见上表中的“答案率”和“平均摘要长度”列。
qu。在此任务上的原始摘要分数(0幻觉)中,是否会复制和粘贴的提取性摘要模型?
从定义上讲,绝对回答这种模型不会具有幻觉,并提供忠实的摘要。我们没有声称正在评估摘要质量,这是一项独立且正交的任务,应独立评估。正如我们在博客文章中指出的那样,我们没有评估摘要的质量,而是仅评估它们的事实一致性。
qu。这似乎是一个非常可黑的度量标准,因为您可以将原始文本复制为摘要
回答。确实如此,但我们没有在这种方法上评估任意模型,例如在Kaggle竞争中。任何这样做的模型都会在您关心的任何其他任务中表现不佳。因此,我认为这是质量指标,您将与您对模型的其他评估一起运行,例如摘要质量,答案的准确性等。但是我们不建议将其用作独立公制。所选模型均未对我们的模型的输出进行培训。这可能会在将来发生,但是当我们计划更新模型和源文档时,这是一个活着的排行榜,这将是不太可能发生的。但是,这也是任何LLM基准测试的问题。我们还应该指出,这基于许多其他学者发明和完善该协议的事实一致性的大量工作。请参阅我们对本博客文章中的摘要和真实论文的引用,以及这种出色的资源汇编-https://github.com/edinburghnlp/awesome-hallacination-detection,以阅读更多信息。
qu。这并不能明确地衡量模型幻觉的所有方式
回答。同意。我们没有声称解决了幻觉检测的问题,并计划进一步扩展和增强这一过程。但是我们确实认为这是朝着正确方向朝着正确的方向发展的举动,并提供了一个急需的起点,每个人都可以建立在上面。
qu。一些模型只能在总结时幻觉。您难道不能只是提供众所周知的事实列表,并检查它能回想起它们吗?
回答。在我看来,这将是一个糟糕的考验。一方面,除非您训练了模型,否则您不知道经过培训的数据,因此您不能确定该模型将其响应扎根于其所看到的真实数据或是否在猜测中。此外,“众所周知”没有明确的定义,并且这些类型的数据通常很容易使大多数模型准确回忆。在我公认的主观经验中,大多数幻觉都来自获取很少已知或讨论的信息的模型,或者该模型看到了相互矛盾的信息。在不知道该模型的源数据的情况下,再次无法验证这些幻觉,因为您不知道哪个数据符合此标准。我还认为,该模型不太可能在总结时幻觉。我们要求模型以仍然忠于来源的方式获取信息并转换信息。除了摘要之外,这类似于许多生成任务(例如,写一封涵盖这些要点的电子邮件...),如果模型偏离了提示,那么这是未能遵循说明,表明该模型也会在其他指令上挣扎以下任务。
qu。这是一个不错的开端,但远非确定的
回答。我完全同意。还有很多需要做的事情,问题尚未解决。但是,“良好的开始”意味着希望在这方面开始取得进展,并且通过开放采购模型,我们希望让社区将其提升到一个新的水平。


