hallucination leaderboard
1.0.0
Public LLM Leadboard calculé à l'aide du modèle d'évaluation Hughes Hallucination de Vectara. Cela évalue la fréquence à laquelle un LLM introduit des hallucinations lors du résumé d'un document. Nous prévoyons de mettre à jour cela régulièrement en tant que modèle et les LLM sont mis à jour au fil du temps.
N'hésitez pas à consulter notre classement des hallucinations sur les câlins.
Les classements dans ce classement sont calculés à l'aide du modèle d'évaluation des hallucinations HHEM-2.1. Si vous êtes intéressé par le classement précédent, qui était basé sur HHEM-1.0, il est disponible ici
 | En mémoire aimante de Simon Mark Hughes ... |
Dernière mise à jour le 6 novembre 2024
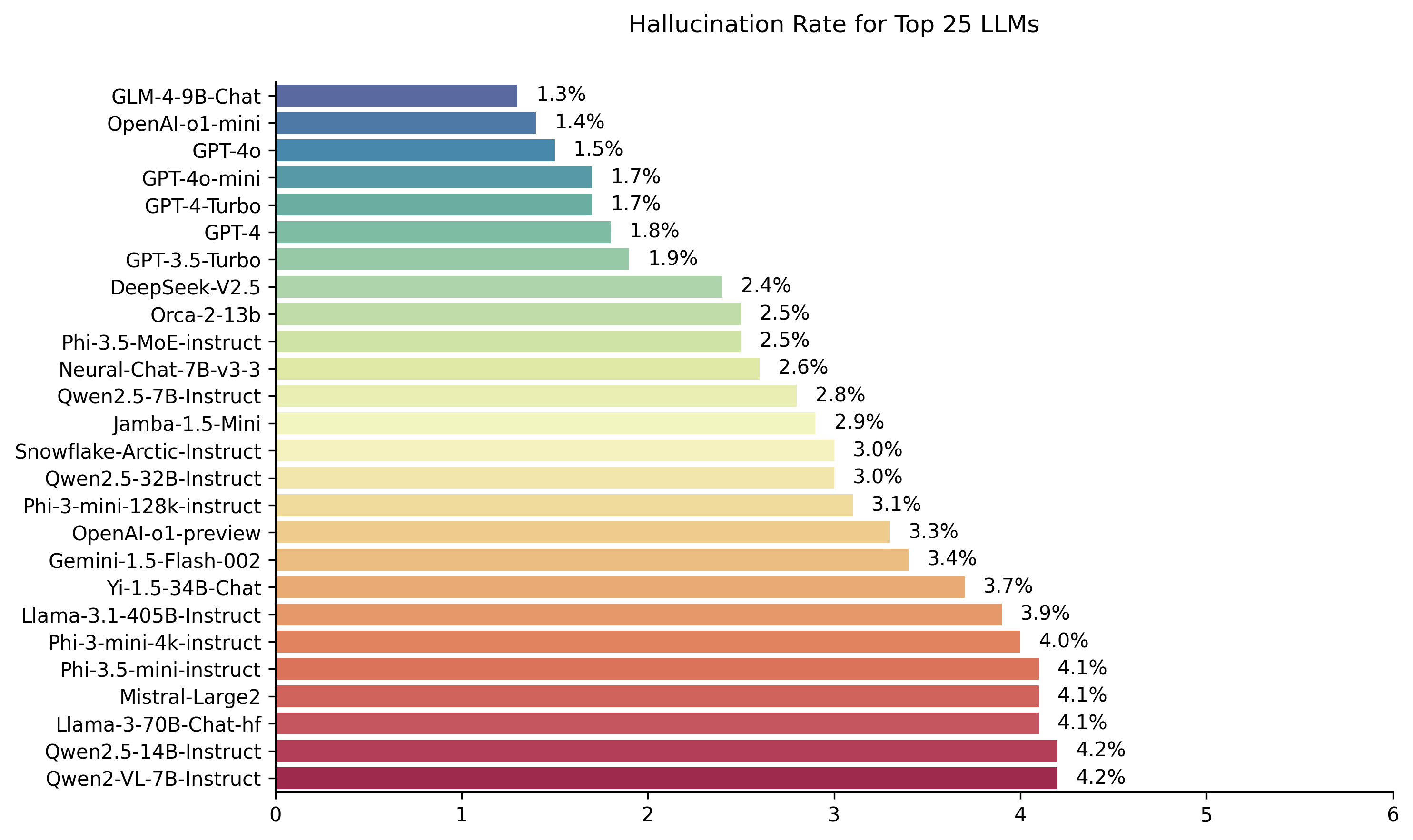
| Modèle | Taux d'hallucination | Taux de cohérence factuel | Taux de réponse | Durée de résumé moyenne (mots) |
|---|---|---|---|---|
| Zhipu AI GLM-4-9B-CHAT | 1,3% | 98,7% | 100,0% | 58.1 |
| Openai-o1-min | 1,4% | 98,6% | 100,0% | 78.3 |
| GPT-4O | 1,5% | 98,5% | 100,0% | 77.8 |
| GPT-4O-MINI | 1,7% | 98,3% | 100,0% | 76.3 |
| GPT-4-turbo | 1,7% | 98,3% | 100,0% | 86.2 |
| Gpt-4 | 1,8% | 98,2% | 100,0% | 81.1 |
| GPT-3,5-turbo | 1,9% | 98,1% | 99,6% | 84.1 |
| Deepseek-V2.5 | 2,4% | 97,6% | 100,0% | 83.2 |
| Microsoft Orca-2-13b | 2,5% | 97,5% | 100,0% | 66.2 |
| Microsoft PHI-3.5-MOE-INSTRUCT | 2,5% | 97,5% | 96,3% | 69.7 |
| Intel neural-chat-7b-v3-3 | 2,6% | 97,4% | 100,0% | 60.7 |
| QWEN2.5-7B-Istruct | 2,8% | 97,2% | 100,0% | 71.0 |
| AI21 JAMBA-1,5-MINI | 2,9% | 97,1% | 95,6% | 74.5 |
| Flocon de neige-instruct | 3,0% | 97,0% | 100,0% | 68.7 |
| QWEN2.5-32B-INSTRUCT | 3,0% | 97,0% | 100,0% | 67.9 |
| Microsoft PHI-3-MINI-128K-INSTRUCT | 3,1% | 96,9% | 100,0% | 60.1 |
| Openai-O1-Preview | 3,3% | 96,7% | 100,0% | 119.3 |
| Google Gemini-1.5-Flash-002 | 3,4% | 96,6% | 99,9% | 59.4 |
| 01-AI YI-1.5-34B-CHAT | 3,7% | 96,3% | 100,0% | 83.7 |
| LLAMA-3.1-405B-INSTRUCT | 3,9% | 96,1% | 99,6% | 85.7 |
| Microsoft PHI-3-MINI-4K-INSTRUCT | 4,0% | 96,0% | 100,0% | 86.8 |
| Microsoft PHI-3,5 minutes | 4,1% | 95,9% | 100,0% | 75.0 |
| Mistral-Large2 | 4,1% | 95,9% | 100,0% | 77.4 |
| LLAMA-3-70B-CHAT-HF | 4,1% | 95,9% | 99,2% | 68.5 |
| QWEN2-VL-7B-INSTRUCT | 4,2% | 95,8% | 100,0% | 73.9 |
| QWEN2.5-14B-INSTRUCT | 4,2% | 95,8% | 100,0% | 74.8 |
| QWEN2.5-72B-INSTRUCT | 4,3% | 95,7% | 100,0% | 80.0 |
| LLAMA-3.2-90B-VISION-INSTRUCT | 4,3% | 95,7% | 100,0% | 79.8 |
| Xai Grok | 4,6% | 95,4% | 100,0% | 91.0 |
| Claude-3-5 anthropique | 4,6% | 95,4% | 100,0% | 95.9 |
| QWEN2-72B-INSTRUCT | 4,7% | 95,3% | 100,0% | 100.1 |
| Mixtral-8x22b-instruct-v0.1 | 4,7% | 95,3% | 99,9% | 92.0 |
| Claude-3-5-Haiku anthropique | 4,9% | 95,1% | 100,0% | 92.9 |
| 01-AI YI-1.5-9B-CHAT | 4,9% | 95,1% | 100,0% | 85.7 |
| Cohere Command-R | 4,9% | 95,1% | 100,0% | 68.7 |
| LLAMA-3.1-70B-INSTRUCT | 5,0% | 95,0% | 100,0% | 79.6 |
| LLAMA-3.1-8B-INSTRUCT | 5,4% | 94,6% | 100,0% | 71.0 |
| Cohere Command-R-Plus | 5,4% | 94,6% | 100,0% | 68.4 |
| LLAMA-3.2-11B-VISION-INSTRUCT | 5,5% | 94,5% | 100,0% | 67.3 |
| Lama-2-70b-chat-hf | 5,9% | 94,1% | 99,9% | 84.9 |
| IBM Granite-3.0-8B-Istruct | 6,5% | 93,5% | 100,0% | 74.2 |
| Google Gemini-1.5-Pro-002 | 6,6% | 93,7% | 99,9% | 62.0 |
| Google Gemini-1.5-Flash | 6,6% | 93,4% | 99,9% | 63.3 |
| Microsoft PHI-2 | 6,7% | 93,3% | 91,5% | 80.8 |
| Google Gemma-2-2b-it | 7,0% | 93,0% | 100,0% | 62.2 |
| QWEN2.5-3B-Istruct | 7,0% | 93,0% | 100,0% | 70.4 |
| Llama-3-8b-chat-hf | 7,4% | 92,6% | 99,8% | 79.7 |
| Google Gemini-Pro | 7,7% | 92,3% | 98,4% | 89.5 |
| 01-AI YI-1.5-6B-CHAT | 7,9% | 92,1% | 100,0% | 98.9 |
| LLAMA-3.2-3B-INSTRUCT | 7,9% | 92,1% | 100,0% | 72.2 |
| DATABRICKS DBRX-INSTRUCT | 8,3% | 91,7% | 100,0% | 85.9 |
| QWEN2-VL-2B-INSTRUCT | 8,3% | 91,7% | 100,0% | 81.8 |
| Cohere Aya Expanse 32b | 8,5% | 91,5% | 99,9% | 81.9 |
| IBM Granite-3.0-2b-Instruct | 8,8% | 91,2% | 100,0% | 81.6 |
| Mistral-7B-Instruct-V0.3 | 9,5% | 90,5% | 100,0% | 98.4 |
| Google Gemini-1.5-Pro | 9,1% | 90,9% | 99,8% | 61.6 |
| Claude-3-opus anthropique | 10,1% | 89,9% | 95,5% | 92.1 |
| Google Gemma-2-9b-it | 10,1% | 89,9% | 100,0% | 70.2 |
| Lama-2-13b-chat-hf | 10,5% | 89,5% | 99,8% | 82.1 |
| Mistral-némo-instructeur | 11,2% | 88,8% | 100,0% | 69.9 |
| Lama-2-7b-chat-hf | 11,3% | 88,7% | 99,6% | 119.9 |
| Microsoft Wizardlm-2-8x22b | 11,7% | 88,3% | 99,9% | 140.8 |
| Cohere Aya Expanse 8b | 12,2% | 87,8% | 99,9% | 83.9 |
| Amazon Titan-Express | 13,5% | 86,5% | 99,5% | 98.4 |
| Google Palm-2 | 14,1% | 85,9% | 99,8% | 86.6 |
| Google Gemma-7b-it | 14,8% | 85,2% | 100,0% | 113.0 |
| QWEN2.5-1.5B-INSTRUCT | 15,8% | 84,2% | 100,0% | 70.7 |
| Anthropic Claude-3-Sonnet | 16,3% | 83,7% | 100,0% | 108.5 |
| Google Gemma-1.1-7b-it | 17,0% | 83,0% | 100,0% | 64.3 |
| Claude-2 anthropique | 17,4% | 82,6% | 99,3% | 87.5 |
| Google flan-t5-grand | 18,3% | 81,7% | 99,3% | 20.9 |
| Mixtral-8x7b-instruct-v0.1 | 20,1% | 79,9% | 99,9% | 90.7 |
| LLAMA-3.2-1B-INSTRUCT | 20,7% | 79,3% | 100,0% | 71.5 |
| Apple OpenELM-3B-INSTRUCT | 24,8% | 75,2% | 99,3% | 47.2 |
| QWEN2.5-0.5B-INSTRUCT | 25,2% | 74,8% | 100,0% | 72.6 |
| Google Gemma-1.1-2b-it | 27,8% | 72,2% | 100,0% | 66.8 |
| Tii falcon-7b-instruct | 29,9% | 70,1% | 90,0% | 75.5 |
Ce classement utilise HHEM-2.1, le modèle d'évaluation commerciale d'hallucination de Vectara, pour calculer le classement LLM. Vous pouvez trouver une variante open source de ce modèle, HHEM-2.1-Open sur la face étreinte et Kaggle.
Voir cet ensemble de données pour les résumés générés que nous avons utilisés pour évaluer les modèles.
Beaucoup de travaux antérieurs dans ce domaine ont été effectués. Pour certains des meilleurs articles de ce domaine (cohérence factuelle en résumé), veuillez consulter ici:
Pour une liste très complète, veuillez consulter ici - https://github.com/edinburghnlp/awesome-hallucination-dection. Les méthodes décrites dans la section suivante utilisent des protocoles établis dans ces articles, parmi beaucoup d'autres.
Pour une explication détaillée de l'œuvre qui a été consacrée à ce modèle, veuillez vous référer à notre article de blog sur la version: Cut the Bull…. Détection des hallucinations dans des modèles de grande langue.
Pour déterminer ce classement, nous avons formé un modèle pour détecter les hallucinations dans les sorties LLM, en utilisant divers ensembles de données open source à partir de la recherche de cohérence factuelle sur les modèles de résumé. En utilisant un modèle compétitif avec les meilleurs modèles de pointe, nous avons ensuite nourri 1000 courts documents à chacun des LLM ci-dessus via leurs API publiques et leur avons demandé de résumer chaque court document, en utilisant uniquement les faits présentés dans le document. Sur ces 1000 documents, seuls 831 documents ont été résumés par chaque modèle, les documents restants ont été rejetés par au moins un modèle en raison de restrictions de contenu. En utilisant ces 831 documents, nous avons ensuite calculé le taux de cohérence factuel global (pas d'hallucinations) et le taux d'hallucination (100 - précision) pour chaque modèle. Le taux auquel chaque modèle refuse de répondre à l'invite est détaillé dans la colonne «Taux de réponse». Aucun des contenus envoyés aux modèles ne contenait du contenu illicite ou «non sûr pour le travail», mais le présent des mots déclencheurs était suffisant pour déclencher certains filtres de contenu. Les documents ont été prélevés principalement du CNN / Daily Mail Corpus. Nous avons utilisé une température de 0 lors de l'appel du LLMS.
Nous évaluons le taux de cohérence factuel de résumé au lieu de la précision factuelle globale car elle nous permet de comparer la réponse du modèle aux informations fournies. En d'autres termes, le résumé est fourni «factuellement cohérent» avec le document source. La détermination des hallucinations est impossible à faire pour toute question ad hoc car on ne sait pas précisément quelles données sur lesquelles chaque LLM est formée. De plus, avoir un modèle qui peut déterminer si une réponse a été hallucinée sans source de référence nécessite de résoudre le problème d'hallucination et de former vraisemblablement un modèle aussi grand ou plus grand que ces LLM évalués. Nous avons donc plutôt choisi de regarder le taux d'hallucination dans la tâche de résumé car il s'agit d'un bon analogue pour déterminer à quel point les modèles sont véridiques. De plus, les LLM sont de plus en plus utilisées dans les pipelines RAG (récupération de génération augmentée) pour répondre aux requêtes d'utilisateur, comme dans Bing Chat et l'intégration de chat de Google. Dans un système de chiffon, le modèle est déployé en tant que résumé des résultats de recherche, donc ce classement est également un bon indicateur pour la précision des modèles lorsqu'il est utilisé dans les systèmes de chiffon.
Vous êtes un bot de chat répondant aux questions à l'aide de données. Vous devez vous en tenir aux réponses fournies uniquement par le texte du passage fourni. On vous pose la question «Fournir un résumé concis du passage suivant, couvrant les principales informations décrites». <Passage>
Lors de l'appel de l'API, le jeton <Passage> a ensuite été remplacé par le document source (voir la colonne «source» dans cet ensemble de données).
Vous trouverez ci-dessous un aperçu détaillé des modèles intégrés et de leurs points de terminaison spécifiques:
gpt-3.5-turbo via la bibliothèque client Python d'Openai, spécifiquement via le point de terminaison chat.completions.create .gpt-4 .gpt-4-turbo-2024-04-09 , conformément à la documentation d'Openai.gpt-4o .gpt-4o-mini .o1-mini .o1-previewmeta-llama/Llama-2-xxb-chat-hf , où xxb peut être 7b , 13b et 70b , adapté à la capacité de chaque modèle.chat et en utilisant le modèle meta-llama/Llama-3-xxB-chat-hf , où xxB peut être 8B et 70B .Meta-Llama-3.1-405B-Instruct est accessible via l'API de Replicate en utilisant le modèle meta/meta-llama-3.1-405b-instruct .Meta-Llama-3.2-3B-Instruct est accessible via ensemble un point de terminaison AI chat en utilisant le modèle meta-llama/Llama-3.2-3B-Instruct-Turbo .Llama-3.2-11B-Vision-Instruct et Llama-3.2-90B-Vision-Instruct sont accessibles via ensemble un point de terminaison chat AI en utilisant le modèle meta-llama/Llama-3.2-11B-Vision-Instruct-Turbo et meta-llama/Llama-3.2-90B-Vision-Instruct-Turbo .command-r-08-2024 et du point de terminaison /chat .command-r-plus-08-2024 et du point de terminaison /chat .c4ai-aya-expanse-8b et c4ai-aya-expanse-32b . Pour plus d'informations sur les modèles de Cohere, reportez-vous à leur site Web.claude-2.0 pour l'appel API.claude-3-opus-20240229 pour l'appel de l'API.claude-3-sonnet-20240229 pour l'appel de l'API.claude-3-5-sonnet-20241022 pour l'appel de l'API.claude-3-5-haiku-20241022 pour l'appel de l'API.mistralai/Mixtral-8x22B-Instruct-v0.1 et le point de terminaison chat .mistral-large-latest .text-bison-001 , respectivement.gemini-pro de Google est incorporé pour un traitement linguistique amélioré, accessible sur Vertex AI.gemini-1.5-pro-001 sur le sommet AI.gemini-1.5-flash-001 sur le sommet AI.gemini-1.5-pro-002 sur Vertex AI.gemini-1.5-flash-002 sur Vertex AI.Pour une compréhension approfondie de la version et du cycle de vie de chaque modèle, en particulier celles offertes par Google, veuillez vous référer aux versions du modèle et aux cycles de vie sur Vertex AI.
amazon.titan-text-express-v1 .microsoft/WizardLM-2-8x22B et le point de terminaison chat .databricks/dbrx-instruct et du point de terminaison chat .snowflake/snowflake-arctic-instruct .chat AI avec le nom du modèle Qwen/Qwen2-72B-Instruct .deepseek-chat et du point de terminaison chat .grok-beta et du point de terminaison chat/completions . Sur Pourquoi utilisez-vous un modèle pour évaluer un modèle?
Réponse Il y a plusieurs raisons pour lesquelles nous avons choisi de le faire par rapport à une évaluation humaine. Bien que nous aurions pu croître une grande évaluation de l'échelle humaine, c'est une chose unique, cela ne s'allonge pas d'une manière qui nous permet de mettre à jour constamment le classement à mesure que les nouvelles API sont en ligne ou que les modèles sont mis à jour. Nous travaillons dans un domaine en mouvement rapide afin qu'un tel processus soit hors de données dès sa publication. Deuxièmement, nous voulions un processus reproductible que nous pouvons partager avec les autres afin qu'ils puissent l'utiliser eux-mêmes comme l'un des nombreux scores de qualité LLM qu'ils utilisent lors de l'évaluation de leurs propres modèles. Cela ne serait pas possible avec un processus d'annotation humaine, où les seules choses qui pourraient être partagées sont le processus et les étiquettes humaines. Il convient également de souligner que la construction d'un modèle pour détecter les hallucinations est beaucoup plus facile que de construire un modèle génératif qui ne produit jamais d'hallucinations. Tant que le modèle d'évaluation des hallucinations est fortement corrélé avec les jugements des évaluateurs humains, il peut être un bon indicateur pour les juges humains. Comme nous ciblons spécifiquement le résumé et non la question générale du «livre fermé», la LLM que nous avons formée n'a pas besoin d'avoir mémorisé une grande partie des connaissances humaines, elle doit simplement avoir une solide compréhension et une compréhension des langues qu'elle soutient (actuellement juste l'anglais, mais nous prévoyons d'étendre la couverture linguistique dans le temps).
Sur Et si le LLM refuse de résumer le document ou fournit une réponse d'un ou deux mots?
Réponse, nous les filtrons explicitement. Consultez notre article de blog pour plus d'informations. Vous pouvez voir la colonne «Taux de réponse» dans le classement qui indique le pourcentage de documents résumés, et la colonne de «longueur de résumé moyenne» détaillant les durées de résumé, montrant que nous n'avons pas obtenu de réponses très courtes pour la plupart des documents.
Sur Quelle version du modèle XYZ avez-vous utilisé?
Réponse Veuillez consulter la section API Détails pour les détails sur les versions du modèle utilisées et comment elles ont été appelées, ainsi que la date à laquelle le classement a été mis à jour pour la dernière fois. Veuillez nous contacter (créer un problème dans le dépôt) si vous avez besoin de plus de clarté.
Sur Qu'en est-il de Grok LLM de Xai?
Réponse actuellement (au 11/14/2023) Grok n'est pas accessible au public et nous n'avons pas accès. Ceux qui ont un accès anticipé que je soupçonne sont probablement légalement interdits de faire ce type d'évaluation sur le modèle. Une fois que le modèle est disponible via une API publique, nous chercherons à l'ajouter, ainsi que tout autre LLMS suffisamment populaire.
Sur Un modèle ne peut-il pas simplement marquer à 100% en ne fournissant aucune réponse ou des réponses très courtes?
Réponse, nous avons explicitement filtré ces réponses de chaque modèle, ne faisant l'évaluation finale que sur les documents pour lesquels tous les modèles ont fourni un résumé. Vous pouvez trouver plus de détails techniques dans notre article de blog sur le sujet. Voir aussi les colonnes «taux de réponse» et «longueur de résumé moyenne» dans le tableau ci-dessus.
Sur Un modèle de résumé extractif ne copie-t-il pas et collera-t-il à partir du score de résumé d'origine à 100% (0 hallucination) sur cette tâche?
Répondez absolument comme par définition, un tel modèle n'aurait pas d'hallucinations et fournirait un résumé fidèle. Nous ne prétendons pas évaluer la qualité du résumé, c'est-à-dire une tâche distincte et orthogonale , et devrait être évaluée indépendamment. Nous n'évaluons pas la qualité des résumés, seulement leur cohérence factuelle , comme nous le soulignons dans le billet de blog.
Sur Cela semble une métrique très piratable, car vous pouvez simplement copier le texte d'origine comme résumé
Répondre. C'est vrai, mais nous n'évaluons pas les modèles arbitraires sur cette approche, par exemple dans une compétition de Kaggle. Tout modèle qui le fait fonctionnerait mal à toute autre tâche qui vous tient à cœur. Je considérerais donc cela comme une métrique de qualité que vous exécuteriez aux côtés des autres évaluations que vous avez pour votre modèle, comme la qualité de résumé, la précision de répondant aux questions, etc. Mais nous ne recommandons pas de l'utiliser comme métrique autonome. Aucun des modèles choisis n'a été formé sur la production de notre modèle. Cela peut se produire à l'avenir, mais comme nous prévoyons de mettre à jour le modèle ainsi que les documents source, c'est donc un classement vivant, ce sera un événement improbable. C'est cependant également un problème avec toute référence LLM. Nous devons également souligner que cela s'appuie sur un grand nombre de travaux sur la cohérence factuelle où de nombreux autres universitaires ont inventé et affiné ce protocole. Voir nos références aux articles Summer et True de cet article de blog, ainsi que cette excellente compilation de ressources - https://github.com/edinburghnlp/awesome-hallucination-dection pour en savoir plus.
Sur Cela ne mesure pas définitivement toutes les façons dont un modèle peut halluciner
Répondre. Convenu. Nous ne prétendons pas avoir résolu le problème de la détection des hallucinations et prévoyons de développer et d'améliorer ce processus. Mais nous pensons que c'est un mouvement dans la bonne direction et fournit un point de départ bien nécessaire que tout le monde peut construire au-dessus.
Sur Certains modèles ne pouvaient halluciner qu'en résumant. Ne pourriez-vous pas simplement lui fournir une liste de faits bien connus et vérifier à quel point il peut les rappeler?
Répondre. Ce serait un mauvais test à mon avis. D'une part, sauf si vous avez formé le modèle, vous ne connaissez pas les données sur lesquelles elle a été formée, vous ne pouvez donc pas être sûr que le modèle anime sa réponse dans les données réelles sur lesquelles il a vu ou si elle est deviner. De plus, il n'y a pas de définition claire de «bien connu», et ces types de données sont généralement faciles à rappeler avec précision. La plupart des hallucinations, dans mon expérience certes subjective, proviennent du modèle de récupération d'informations qui est très rarement connue ou discutée, ou des faits pour lesquels le modèle a vu des informations contradictoires. Sans connaître les données source sur lesquelles le modèle a été formé, encore une fois, il est impossible de valider ce type d'hallucinations car vous ne saurez pas quelles données correspondent à ce critère. Je pense aussi qu'il est peu probable que le modèle ne hallucine que tout en résumant. Nous demandons au modèle de prendre des informations et de les transformer d'une manière qui est encore fidèle à la source. Ceci est analogue à de nombreuses tâches génératives en dehors du résumé (par exemple, écrivez un e-mail couvrant ces points ...), et si le modèle s'écarte de l'invite, c'est un échec à suivre les instructions, indiquant que le modèle aurait également du mal à suivre des tâches.
Sur C'est un bon début mais loin d'être définitif
Répondre. Je suis totalement d'accord. Il y a beaucoup plus à faire, et le problème est loin d'être résolu. Mais un «bon départ» signifie que, espérons-le, les progrès commenceront à être réalisés dans ce domaine, et en s'approvisionnement ouvert au modèle, nous espérons impliquer la communauté pour passer au niveau supérieur.


