Chatbot for mental health
1.0.0
在運行腳本之前,請確保安裝了Python版本<= 3.8(最好是Python 3.8;安裝某些庫(例如TensorFlow)所需的必需)。
該項目是為我的大學教授帶有自綁數據集的研究項目完成的。我們使用的數據集是機密的;因此,我使用了示例Kaggle數據集。我決定將腳本開源,以製作Python中從頭開始的不同聊天機器人的彙編,因為我在研究過程中為這種資源而苦苦掙扎。
2017年,《國家心理健康調查》報告說,印度七分之一的人患有精神障礙,包括抑鬱症和焦慮。人們對心理健康的認識越來越大,這使其成為發展的主要關注點。印度近1.5億人需要干預措施,那裡的低矮和中產階級面臨的負擔比富裕的人更負擔。該項目試圖使心理健康更容易獲得。這種對話劑可以與臨床醫生相輔相成,使其更有效和富有成果。
聊天機器人可以根據不同屬性進行分類 -
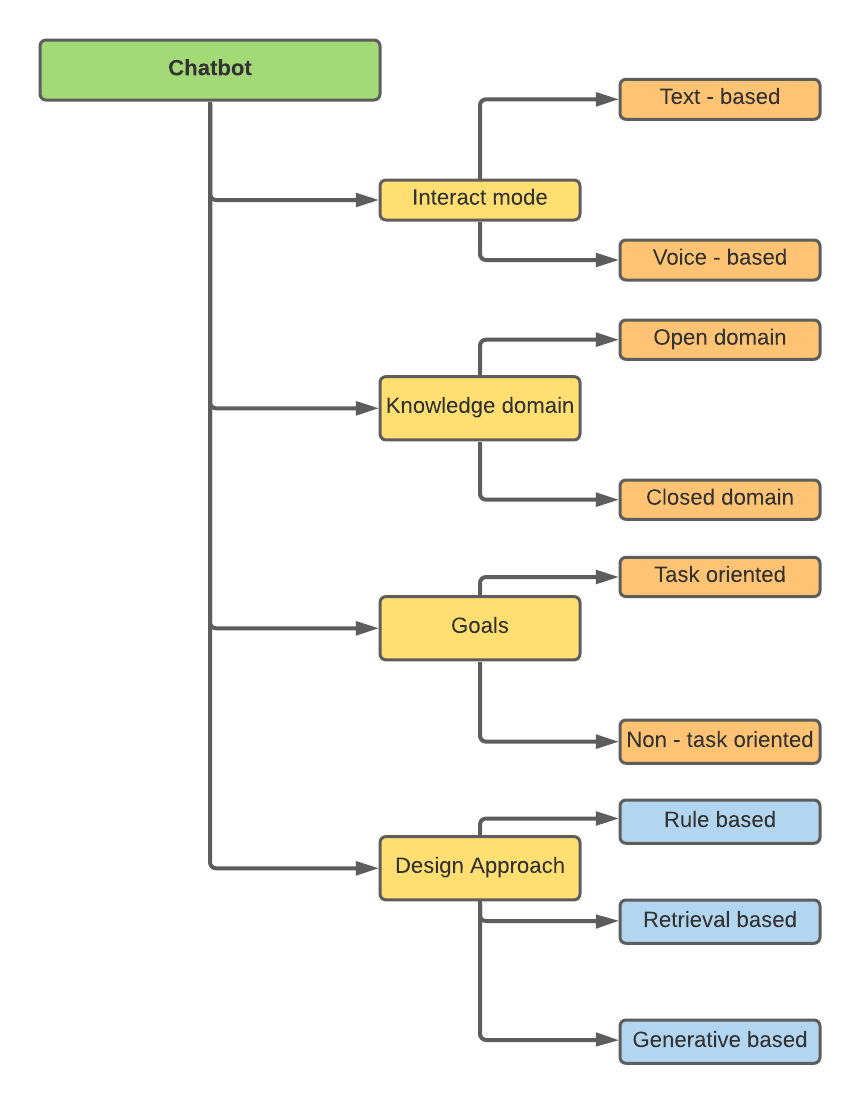
我的研究與設計方法有關,即基於規則,基於檢索和基於生成的方法。
該數據集是從Kaggle拾取的 - 心理健康常見問題解答。該數據集由98個關於心理健康的常見問題解答。它由3列組成 - 問題,問題和答案。
請注意,要訓練檢索聊天機器人,將CSV文件手動轉換為JSON文件。由於這不是用於研究的原始數據集(閱讀介紹),因此我僅使用了前20行來訓練模型。
存儲庫由三種類型的聊天機器人組成的三個筆記本。
對於基於規則的,將TF-IDF與NLTK的令牌使用,以進行數據進行處理。針對預期結果測試了處理後的數據,並使用餘弦相似性進行評估。
對於基於檢索的,幾種機器學習和深度學習模型進行了培訓,
對於基於生成的聊天機器人,使用NLP,因為NLP使聊天機器人可以學習和模仿人類對話的模式和样式。它使您感到自己正在與人交談,而不是機器人。它將用戶輸入映射到意圖,目的是將消息分類為適當的預定義響應。
在這個項目中,我遇到的最大混亂是為什麼聊天機器人使用JSON文件而不是CSV進行基於檢索的模型。我已經列出了一些點,以使兩種文件類型之間的比較 -
我想進一步研究基於生成的聊天機器人的可能性。由於LSTM的緊湊性,當前的編碼器模型無法捕獲解碼器層中的所有依賴項。可以在LSTM層之後添加註意圖層以動態解碼每個輸出。


