Chatbot for mental health
1.0.0
在运行脚本之前,请确保安装了Python版本<= 3.8(最好是Python 3.8;安装某些库(例如TensorFlow)所需的必需)。
该项目是为我的大学教授带有自绑数据集的研究项目完成的。我们使用的数据集是机密的;因此,我使用了示例Kaggle数据集。我决定将脚本开源,以制作Python中从头开始的不同聊天机器人的汇编,因为我在研究过程中为这种资源而苦苦挣扎。
2017年,《国家心理健康调查》报告说,印度七分之一的人患有精神障碍,包括抑郁症和焦虑。人们对心理健康的认识越来越大,这使其成为发展的主要关注点。印度近1.5亿人需要干预措施,那里的低矮和中产阶级面临的负担比富裕的人更负担。该项目试图使心理健康更容易获得。这种对话剂可以与临床医生相辅相成,使其更有效和富有成果。
聊天机器人可以根据不同属性进行分类 -
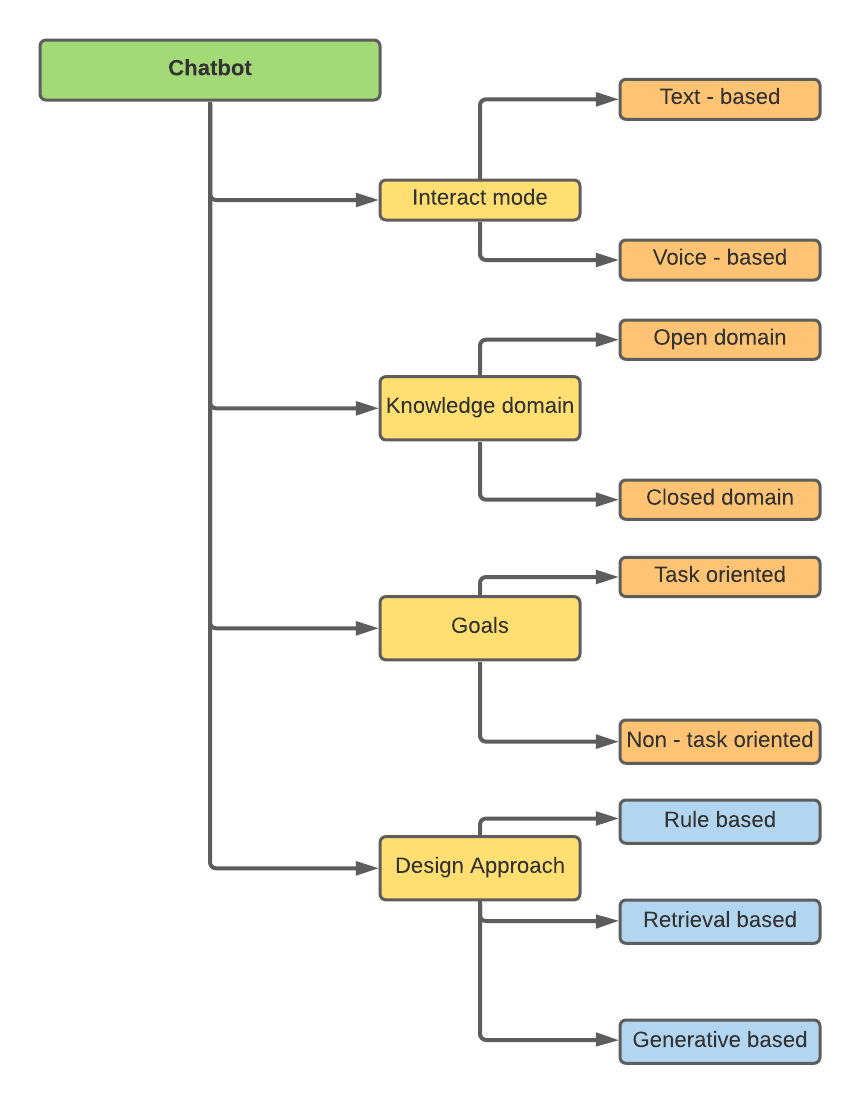
我的研究与设计方法有关,即基于规则,基于检索和基于生成的方法。
该数据集是从Kaggle拾取的 - 心理健康常见问题解答。该数据集由98个关于心理健康的常见问题解答。它由3列组成 - 问题,问题和答案。
请注意,要训练检索聊天机器人,将CSV文件手动转换为JSON文件。由于这不是用于研究的原始数据集(阅读介绍),因此我仅使用了前20行来训练模型。
存储库由三种类型的聊天机器人组成的三个笔记本。
对于基于规则的,将TF-IDF与NLTK的令牌使用,以进行数据进行处理。针对预期结果测试了处理后的数据,并使用余弦相似性进行评估。
对于基于检索的,几种机器学习和深度学习模型进行了培训,
对于基于生成的聊天机器人,使用NLP,因为NLP使聊天机器人可以学习和模仿人类对话的模式和样式。它使您感到自己正在与人交谈,而不是机器人。它将用户输入映射到意图,目的是将消息分类为适当的预定义响应。
在这个项目中,我遇到的最大混乱是为什么聊天机器人使用JSON文件而不是CSV进行基于检索的模型。我已经列出了一些点,以使两种文件类型之间的比较 -
我想进一步研究基于生成的聊天机器人的可能性。由于LSTM的紧凑性,当前的编码器模型无法捕获解码器层中的所有依赖项。可以在LSTM层之后添加注意图层以动态解码每个输出。


