Chatbot for mental health
1.0.0
Antes de ejecutar los scripts, asegúrese de tener la versión de Python <= 3.8 instalada (preferiblemente Python 3.8; requerida para instalar algunas bibliotecas como TensorFlow).
Este proyecto se realizó para un proyecto de investigación bajo un profesor de mi universidad con un conjunto de datos autoportado. El conjunto de datos que utilizamos es confidencial; Por lo tanto, he usado un conjunto de datos Kaggle de muestra. Decidí hacer los guiones de código abierto para hacer una compilación de diferentes chatbots desde cero en Python ya que luché con tales recursos durante mi investigación.
En 2017, la Encuesta Nacional de Salud Mental informó que una de cada siete personas en la India sufría de trastornos mentales, incluidos la depresión y la ansiedad. La creciente conciencia de la salud mental lo ha convertido en una preocupación principal del desarrollo. Casi 150 millones de personas en la India necesitaban intervenciones, donde la clase baja y media enfrentaba más carga que las personas acomodadas. Este proyecto es un intento de hacer que la salud mental sea más accesible. Este agente de conversación puede complementarse con médicos para que sea más efectivo y fructífero.
Los chatbots se pueden clasificar sobre la base de diferentes atributos -
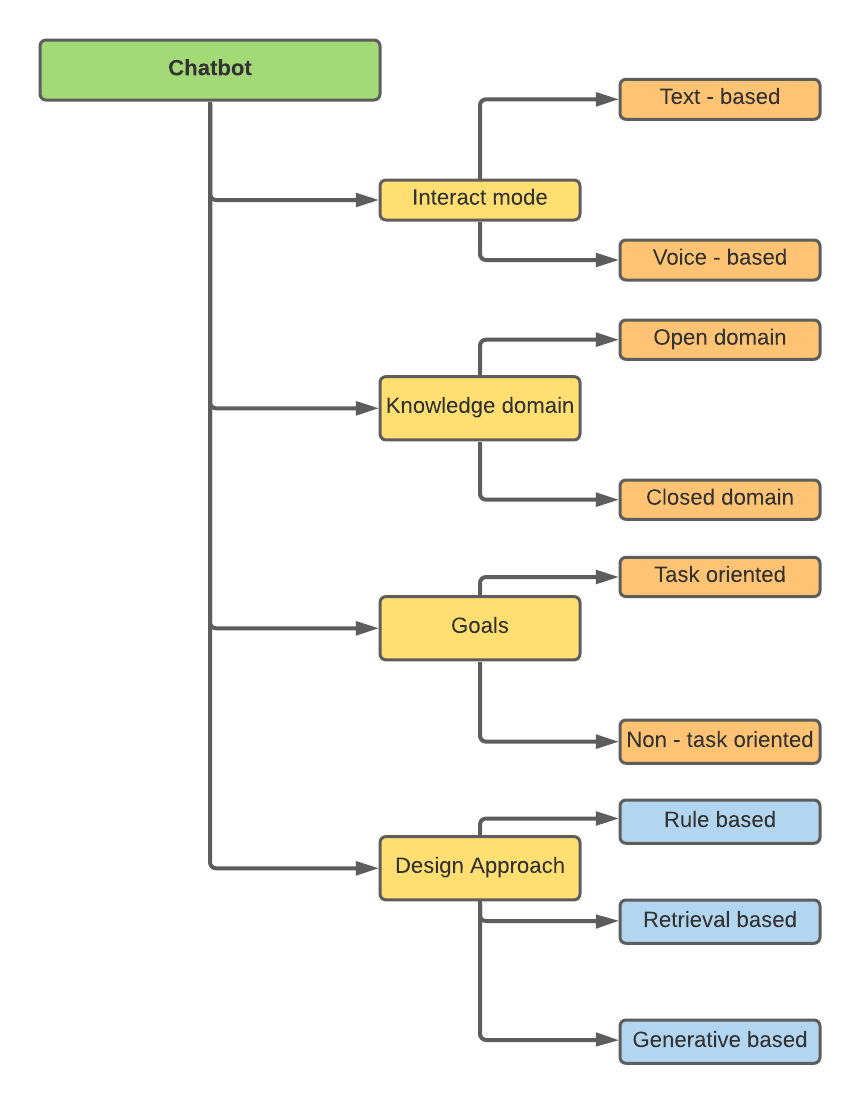
Mi investigación se relacionó con los enfoques de diseño, a saber, basados en reglas, basados en la recuperación y basados en generación.
El conjunto de datos fue recogido de Kaggle - Preguntas frecuentes de salud mental. Este conjunto de datos consta de 98 preguntas frecuentes sobre la salud mental. Consiste en 3 columnas: cuestionidad, preguntas y respuestas.
Tenga en cuenta que para entrenar el chatbot de recuperación, el archivo CSV se convirtió manualmente en un archivo JSON . Dado que este no es el conjunto de datos original utilizado para la investigación (leer introducción), he usado solo las primeras 20 filas para capacitar al modelo.
El repositorio consta de tres cuadernos para los tres tipos de chatbots.
Para el TF-IDF basado en reglas se utilizó con el tokenizador de NLTK para el preprocesamiento de datos. Los datos procesados se probaron con el resultado esperado y se utilizó la similitud de coseno para la evaluación.
Para la recuperación, se capacitaron varios modelos de aprendizaje automático y de aprendizaje profundo,
Para los chatbots basados en generación, se usó NLP ya que NLP permite a los chatbots aprender e imitar los patrones y estilos de la conversación humana . Te da la sensación de que estás hablando con un humano, no un robot. Mapea la entrada del usuario a una intención, con el objetivo de clasificar el mensaje para una posible respuesta predefinida apropiada.
Durante este proyecto, la mayor confusión que tuve fue por qué el chatbot usó un archivo JSON en lugar de CSV para el modelo basado en la recuperación. He enumerado algunos puntos que hacen la comparación entre los dos tipos de archivos:
Quiero investigar más las posibilidades del chatbot basado en generación. El modelo actual de codificador del codificador no puede capturar todas las dependencias en la capa del decodificador debido a la naturaleza compacta de LSTM. Se pueden agregar capas de atención después de las capas LSTM para decodificar cada salida dinámicamente.


