Chatbot for mental health
1.0.0
Прежде чем запустить сценарии, убедитесь, что у вас установлена версия Python <= 3.8 (предпочтительно Python 3.8; необходимо для установки некоторых библиотек, таких как Tensorflow).
Этот проект был сделан для исследовательского проекта под руководством профессора в моем университете с самостоятельным набором данных. Набор данных, который мы использовали, является конфиденциальным; Следовательно, я использовал образец набора данных Kaggle. Я решил сделать сценарии с открытым исходным кодом, чтобы сделать сборник различных чат-ботов с нуля в Python, так как я боролся с такими ресурсами во время своих исследований.
В 2017 году Национальное обследование психического здоровья сообщило, что каждый из семи человек в Индии страдал от психических расстройств, включая депрессию и беспокойство. Растущая осведомленность о психическом здоровье сделала его основной проблемой развития. Почти 150 миллионов человек в Индии нуждались в вмешательствах, где низкий и средний класс столкнулся с большим бременем, чем зажиточные люди. Этот проект является попыткой сделать психическое здоровье более доступным. Этот разговорной агент может быть дополнен клиницистами, чтобы сделать его более эффективным и плодотворным.
Чат -боты могут быть классифицированы на основе различных атрибутов -
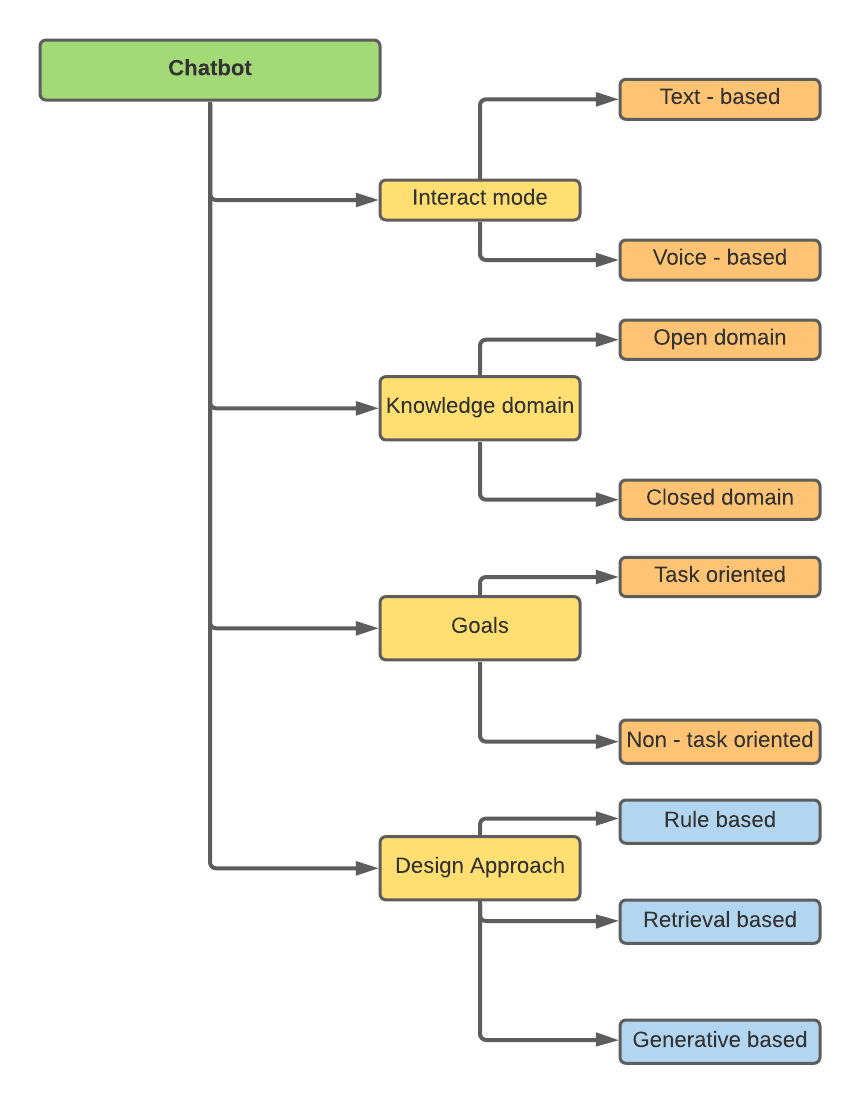
Мое исследование было связано с подходами к проектированию, а именно, основанным на правилах, на основе поиска и на основе генерации.
Набор данных был взят из FAQ Kaggle - психическое здоровье. Этот набор данных состоит из 98 часто задаваемых вопросов о психическом здоровье. Он состоит из 3 столбцов - вопроса, вопросов и ответов.
Обратите внимание, что для обучения поиска чат -бота файл CSV был вручную преобразован в файл JSON . Поскольку это не оригинальный набор данных, используемый для исследования (читать Intro), я использовал только первые 20 строк для обучения модели.
Репозиторий состоит из трех ноутбуков для трех типов чат -ботов.
Для на основе правил TF-IDF использовался с токенизатором NLTK для обработки данных. Обработанные данные были протестированы с ожидаемым результатом, и для оценки использовалось сходство косинуса .
Для поиска, несколько моделей машинного обучения и глубокого обучения были обучены,
Для генеративных чат-ботов NLP использовался с тех пор, как NLP позволяет чат-ботам учиться и имитировать шаблоны и стили человеческого разговора . Это дает вам ощущение, что вы разговариваете с человеком, а не с роботом. Он отображает ввод пользователя с целью с целью классификации сообщения для соответствующего предопределенного возможного ответа.
Во время этого проекта самая большая путаница, которую я испытал, заключалась в том, почему чат-бот использовал файл JSON вместо CSV для модели на основе поиска. Я перечислил некоторые моменты, которые проводят сравнение между двумя типами файлов -
Я хочу дальше исследовать возможности чат-бота на основе генерации. Текущая модель энкодера-декодера не может запечатлеть все зависимости в слое декодера из-за компактной природы LSTM. Слои внимания могут быть добавлены после динамического декодирования каждого выхода.


