Chatbot pour la santé mentale
Mises à jour (2024)
- Correction des problèmes liés aux scripts Python ne fonctionnant pas en raison des versions et méthodes de bibliothèque obsolète
- Ajouter des exigences.txt pour une installation facile des dépendances
Avant d'exécuter les scripts, assurez-vous d'avoir une version Python <= 3.8 installée (de préférence Python 3.8; requise pour installer certaines bibliothèques comme TensorFlow).
Ce projet a été réalisé pour un projet de recherche sous un professeur de mon université avec un ensemble de données autonome. L'ensemble de données que nous avons utilisé est confidentiel; Par conséquent, j'ai utilisé un exemple de jeu de données Kaggle. J'ai décidé de faire des scripts ouverts pour faire une compilation de différents chatbots à partir de zéro à Python, car j'ai lutté avec de telles ressources lors de mes recherches.
Motivation derrière ce projet
En 2017, la National Mental Health Survey a rapporté qu'une personne sur sept en Inde souffrait de troubles mentaux, notamment la dépression et l'anxiété. La conscience croissante de la santé mentale en a fait une principale préoccupation du développement. Près de 150 millions de personnes en Inde avaient besoin d'interventions, où la classe basse et moyenne faisait face à plus de fardeau que les personnes aisées. Ce projet est une tentative de rendre la santé mentale plus accessible. Cet agent conversationnel peut être complété par des cliniciens pour le rendre plus efficace et fructueux.
Classifications de chatbots
Les chatbots peuvent être classés sur la base de différents attributs -
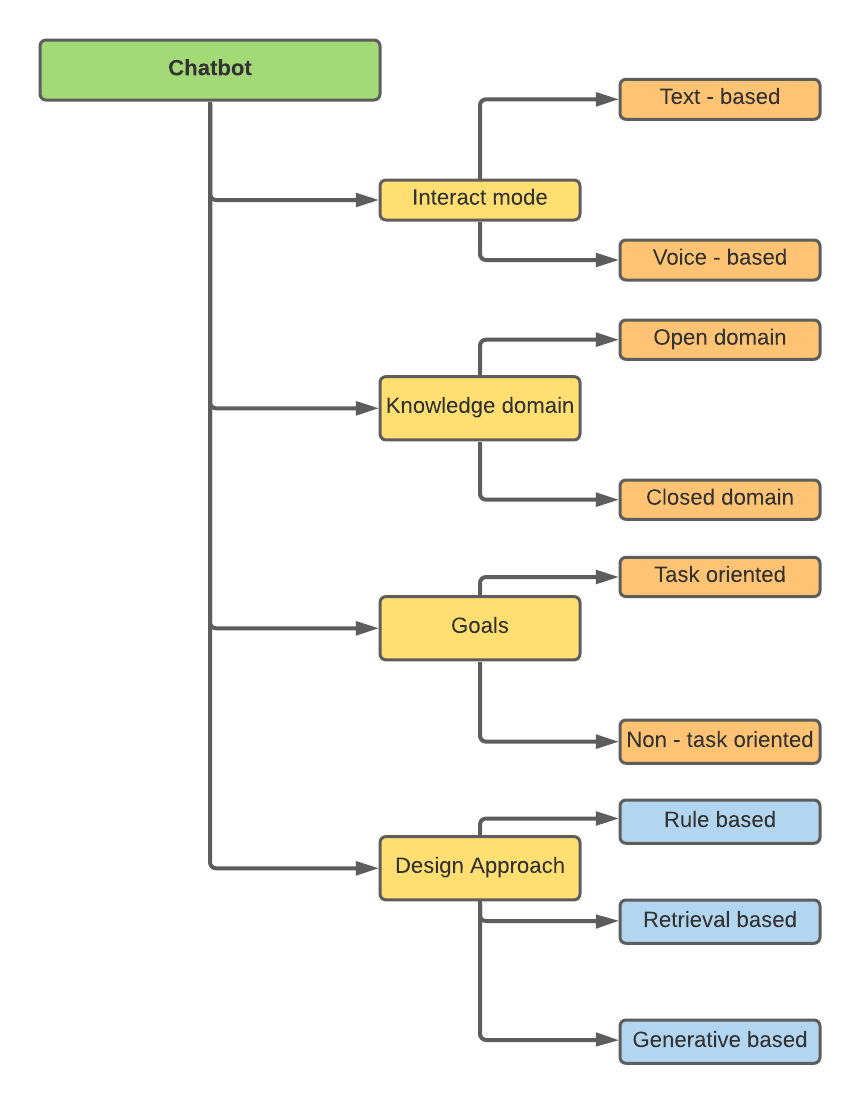
Mes recherches étaient liées aux approches de conception, à savoir, basées sur des règles, basées sur la récupération et génératives.
- Chatbots basés sur des règles: un chatbot basé sur des règles utilise une cartographie simple basée sur des règles ou une correspondance de motifs pour sélectionner les réponses dans les ensembles de réponses prédéfinies. Ces systèmes ne produisent pas de nouveau texte; Au lieu de cela, ils choisissent une réponse dans une liste prédéterminée.
- Chatbots basés sur la récupération: un chatbot basé sur la récupération utilise des ensembles d'apprentissage automatique comme heuristique pour l'évaluation. Semblable aux chatbots basés sur des règles, ils ne génèrent pas de nouveaux textes.
- Chatbots basés sur des générations: les modèles génératifs ne reposent pas sur des réponses prédéfinies. Ils proposent de nouvelles réponses à partir de zéro. Les techniques de traduction automatique sont généralement utilisées dans les modèles génératifs, mais au lieu de traduire d'une langue à une autre, nous «traduisons» de l'entrée à la sortie (réponse). Des modèles génératifs sont utilisés pour la création car ils apprennent de zéro.
Aperçu des robots formés
L'ensemble de données a été récupéré de Kaggle - FAQ de la santé mentale. Cet ensemble de données se compose de 98 FAQ sur la santé mentale. Il se compose de 3 colonnes - questionId, questions et réponses.
Notez que pour former le chatbot de récupération, le fichier CSV a été converti manuellement en fichier JSON . Comme ce n'est pas l'ensemble de données original utilisé pour la recherche (lire l'intro), je n'ai utilisé que les 20 premières lignes pour la formation du modèle.
Le référentiel se compose de trois cahiers pour les trois types de chatbots.
Pour les règles, TF-IDF a été utilisée avec le tokenizer de NLTK pour le processus de procédure de données. Les données traitées ont été testées par rapport au résultat attendu et la similitude du cosinus a été utilisée pour l'évaluation.
Pour la récupération, plusieurs modèles d'apprentissage automatique et d'apprentissage en profondeur ont été formés,
- Vanille RNN
- LSTM
- Bi - lstm
- Gru
- Les modèles de récupération CNN sont formés sur les fichiers JSON. Pour tous les modèles ci-dessus, la régularisation a été utilisée et sur la base des précisions de formation et de validation et la perte, le meilleur modèle a été conservé pour les comparaisons finales. Il a été observé que l' architecture CNN a donné les meilleurs résultats . Le modèle consistait en 3 couches - réseau neuronal convolutionnel (CNN) + une couche d'intégration + et une couche entièrement connectée.
Pour les chatbots génératifs, la NLP a été utilisée car la NLP permet aux chatbots d'apprendre et d'imiter les modèles et les styles de conversation humaine . Cela vous donne le sentiment que vous parlez à un humain, pas un robot. Il mappe l'entrée utilisateur dans une intention, dans le but de classer le message pour une réponse possible prédéfinie.
- Un modèle d'encodeur-décodeur a été formé sur le fichier CSV. Endoder-Deccoder est un modèle SEQ2SEQ, également appelé le modèle d'encodeur-décodeur, utilise une mémoire à court terme - LSTM pour la génération de texte à partir du corpus d'entraînement.
- Que fait le modèle SEQ2SEQ ou Encodeur-Deccoder en mots simples? Il prédit un mot donné dans l'entrée de l'utilisateur, puis chacun des mots suivants est prévu en utilisant la probabilité de probabilité que ce mot se produise.
JSON contre CSV
Au cours de ce projet, la plus grande confusion que j'ai eu était la raison pour laquelle le chatbot a utilisé un fichier JSON au lieu de CSV pour le modèle basé sur la récupération. J'ai répertorié certains points qui font la comparaison entre les deux types de fichiers -
- JSON stocke les données d'une manière hiérarchique, ce qui est mieux pour un chatbot basé sur la récupération, étant donné que le chatbot nécessiterait des balises et des contextes.
- Un chatbot basé sur la récupération est formé pour donner la meilleure réponse en fonction d'un pool de réponses prédéfinies. Ces réponses prédéfinies sont en nombre fini. Une balise doit être fournie pour le mappage d'entrée à sortie. Pour le dire simplement, l'entrée donnée par l'utilisateur (le contexte) est identifiée par la balise fournie. Sur la base de la meilleure balise prévue, l'utilisateur est montré l'une des réponses prédéfinies . Par conséquent, le stockage de ce type de données dans un fichier JSON est plus facile en raison de sa compacité et de sa structure hiérarchique.
- Un fichier CSV a été utilisé pour stocker les données du chatbot génératif. Un chatbot génératif ne nécessite pas de balises pour faire des prédictions . Ces données sont plus faciles à stocker dans un fichier CSV car nous n'avons besoin que de deux colonnes - le texte d'entrée et le texte de sortie. L'ajout ou la suppression des données serait plus facile dans ce cas par rapport à un fichier JSON.
Objectifs futurs
Je veux rechercher davantage les possibilités du chatbot génératif. Le modèle actuel de coder-décodeur ne peut pas capturer toutes les dépendances dans la couche de décodeur en raison de la nature compacte de LSTM. Les couches d'attention peuvent être ajoutées après les couches LSTM pour décoder chaque sortie dynamiquement.


