Chatbot for mental health
1.0.0
스크립트를 실행하기 전에 Python 버전 <= 3.8이 설치되어 있는지 확인하십시오 (바람직하게는 Python 3.8; Tensorflow와 같은 일부 라이브러리를 설치하는 데 필요).
이 프로젝트는 내 대학 교수의 자체 스크랩 된 데이터 세트가있는 연구 프로젝트를 위해 이루어졌습니다. 우리가 사용한 데이터 세트는 기밀입니다. 따라서 샘플 Kaggle 데이터 세트를 사용했습니다. 나는 연구 중에 그러한 자원으로 어려움을 겪었 기 때문에 파이썬에서 다른 챗봇을 처음부터 편집하기 위해 스크립트를 오픈 소스로 만들기로 결정했습니다.
2017 년에 National Mental Health Survey는 인도의 7 명 중 1 명이 우울증과 불안을 포함한 정신 장애로 고통 받고 있다고보고했습니다. 정신 건강에 대한 인식이 높아짐에 따라 개발의 주요 관심사가되었습니다. 인도의 약 1 억 5 천만 명이 중산층과 중산층이 잘 지내는 사람들보다 더 많은 부담에 직면 한 개입이 필요했습니다. 이 프로젝트는 정신 건강을보다 쉽게 접근 할 수 있도록 시도합니다. 이 대화 대리인은 임상의와 보완되어 효과적이고 유익하게 만들 수 있습니다.
챗봇은 다른 속성에 기초하여 분류 할 수 있습니다.
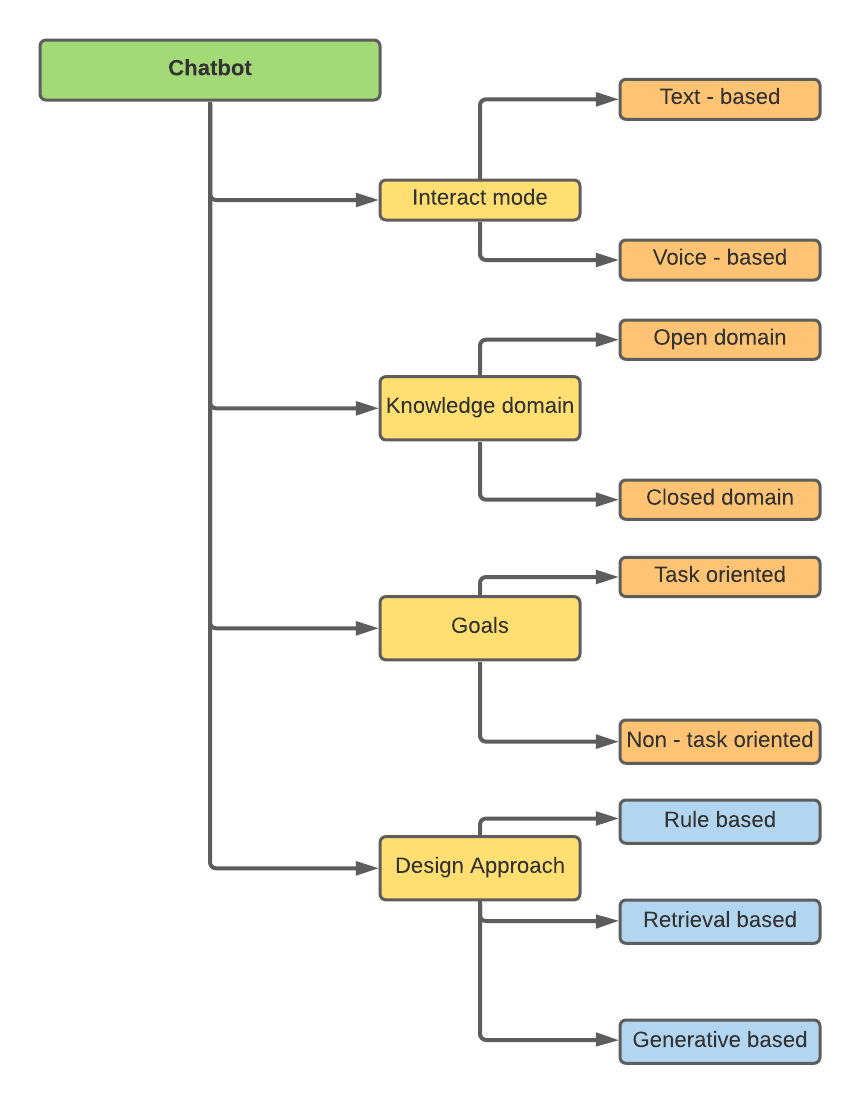
저의 연구는 설계 접근법, 즉 규칙 기반, 검색 기반 및 생성 기반과 관련이있었습니다.
데이터 세트는 Kaggle -Mental Health FAQ에서 픽업되었습니다. 이 데이터 세트는 정신 건강에 관한 98 개의 FAQ로 구성됩니다. QuestionId, Question 및 답변의 3 개의 열로 구성됩니다.
검색 챗봇을 훈련시키기 위해 CSV 파일은 수동으로 JSON 파일로 변환되었습니다 . 이것은 연구에 사용 된 원래 데이터 세트가 아니기 때문에 (읽기 소개) 모델을 훈련시키는 데 처음 20 행만 사용했습니다.
이 저장소는 세 가지 유형의 챗봇에 대한 3 개의 노트북으로 구성됩니다.
규칙 기반의 경우 TF-IDF는 데이터 미리 프로세싱을 위해 NLTK의 토큰 화기 와 함께 사용되었습니다. 처리 된 데이터는 예상 결과에 대해 테스트되었고 코사인 유사성을 평가에 사용 하였다.
검색 기반의 경우 몇 가지 머신 러닝 및 딥 러닝 모델이 교육을 받았습니다.
생성 기반 챗봇의 경우 NLP가 NLP를 사용하면 챗봇이 인간 대화의 패턴과 스타일을 배우고 모방 할 수 있기 때문에 NLP가 사용되었습니다. 그것은 당신이 로봇이 아닌 인간과 이야기하고 있다는 느낌을줍니다. 적절한 사전 정의 된 가능한 응답을 위해 메시지를 분류하기 위해 사용자 입력을 의도에 매핑합니다.
이 프로젝트에서 내가 가진 가장 큰 혼란은 챗봇이 검색 기반 모델에 CSV 대신 JSON 파일을 사용한 이유였습니다. 두 파일 유형을 비교하는 몇 가지 요점을 나열했습니다.
생성 기반 챗봇의 가능성을 더 연구하고 싶습니다. 현재 인코더 디코더 모델은 LSTM의 소형 특성으로 인해 디코더 층의 모든 종속성을 캡처 할 수 없습니다. LSTM 레이어 후 각 출력을 동적으로 해독하기 위해주의 레이어를 추가 할 수 있습니다.


