Chatbot for mental health
1.0.0
Antes de executar os scripts, verifique se você possui uma versão python <= 3.8 instalada (de preferência Python 3.8; necessária para instalar algumas bibliotecas como o TensorFlow).
Este projeto foi realizado para um projeto de pesquisa sob um professor da minha universidade com um conjunto de dados auto-embrulhado. O conjunto de dados que usamos é confidencial; Por isso, usei um amostra de conjunto de dados Kaggle. Decidi fazer os scripts abertos para fazer uma compilação de diferentes chatbots do zero em Python desde que lutei com esses recursos durante minha pesquisa.
Em 2017, a Pesquisa Nacional de Saúde Mental informou que uma em cada sete pessoas na Índia sofria de transtornos mentais, incluindo depressão e ansiedade. A crescente conscientização da saúde mental tornou a preocupação primária do desenvolvimento. Quase 150 milhões de pessoas na Índia precisavam de intervenções, onde a classe baixa e média enfrentava mais fardo do que as pessoas abastadas. Este projeto é uma tentativa de tornar a saúde mental mais acessível. Esse agente de conversação pode ser complementado com os médicos para torná -lo mais eficaz e frutífero.
Os chatbots podem ser classificados com base em diferentes atributos -
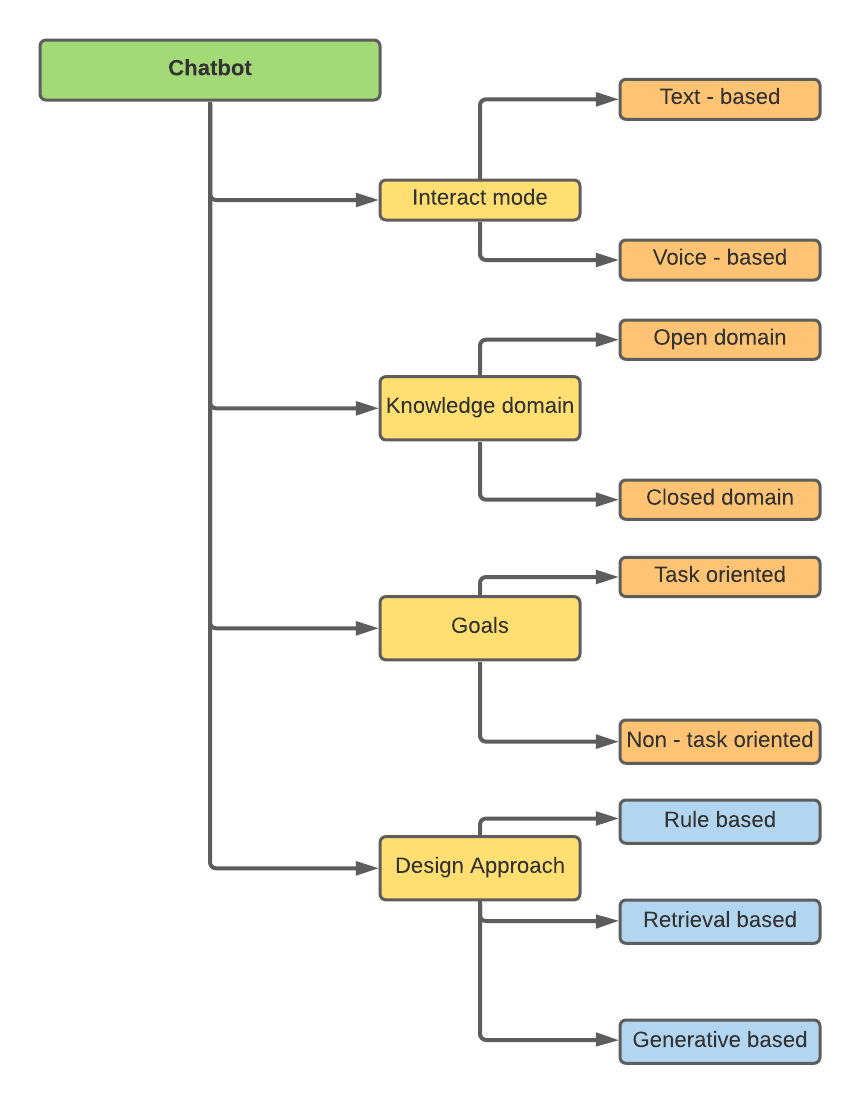
Minha pesquisa estava relacionada às abordagens de design, a saber, baseadas em regras, baseadas em recuperação e baseadas em generativas.
O conjunto de dados foi escolhido em Kaggle - Perguntas frequentes sobre saúde mental. Esse conjunto de dados consiste em 98 perguntas frequentes sobre saúde mental. Consiste em 3 colunas - questionídeos, perguntas e respostas.
Observe que, para treinar o chatbot de recuperação, o arquivo CSV foi convertido manualmente em um arquivo JSON . Como esse não é o conjunto de dados original usado para a pesquisa (leia a introdução), usei apenas as primeiras 20 linhas para treinar o modelo.
O repositório consiste em três cadernos para os três tipos de chatbots.
Para baseado em regras, o TF-IDF foi usado com o Tokenizer da NLTK para preprocissão de dados. Os dados processados foram testados contra o resultado esperado e a similaridade de cosseno foi usada para avaliação.
Para a recuperação, vários modelos de aprendizado de máquina e aprendizado profundo foram treinados,
Para chatbots baseados em generativos, o PNL foi usado, pois o PNL permite que os chatbots aprendam e imitem os padrões e estilos de conversas humanas . Dá a você a sensação de que você está falando com um humano, não um robô. Ele mapeia a entrada do usuário para uma intenção, com o objetivo de classificar a mensagem para uma resposta possível predefinida apropriada.
Durante esse projeto, a maior confusão que tive foi por que o chatbot usou um arquivo JSON em vez do CSV para o modelo baseado em recuperação. Eu listei alguns pontos que fazem a comparação entre os dois tipos de arquivo -
Quero pesquisar ainda mais as possibilidades do chatbot generativo. O modelo atual do codificador decodificador não pode capturar todas as dependências na camada decodificadora devido à natureza compacta do LSTM. As camadas de atenção podem ser adicionadas após as camadas LSTM para decodificar cada saída dinamicamente.


