Chatbot for mental health
1.0.0
Sebelum Anda menjalankan skrip, pastikan Anda memiliki versi Python <= 3.8 diinstal (lebih disukai Python 3.8; diperlukan untuk menginstal beberapa perpustakaan seperti TensorFlow).
Proyek ini dilakukan untuk proyek penelitian di bawah seorang profesor di universitas saya dengan dataset yang dikeluarkan sendiri. Dataset yang kami gunakan bersifat rahasia; Oleh karena itu, saya telah menggunakan sampel Kaggle Dataset. Saya memutuskan untuk membuat skrip terbuka untuk membuat kompilasi chatbot yang berbeda dari awal di Python karena saya berjuang dengan sumber daya seperti itu selama penelitian saya.
Pada 2017, Survei Kesehatan Mental Nasional melaporkan bahwa satu dari tujuh orang di India menderita gangguan mental, termasuk depresi dan kecemasan. Meningkatnya kesadaran kesehatan mental telah menjadikannya perhatian utama perkembangan. Hampir 150 juta orang di India membutuhkan intervensi, di mana kelas rendah dan menengah menghadapi lebih banyak beban daripada orang-orang yang kaya. Proyek ini merupakan upaya untuk membuat kesehatan mental lebih mudah diakses. Agen percakapan ini dapat dilengkapi dengan dokter untuk membuatnya lebih efektif dan bermanfaat.
Chatbots dapat diklasifikasikan berdasarkan atribut yang berbeda -
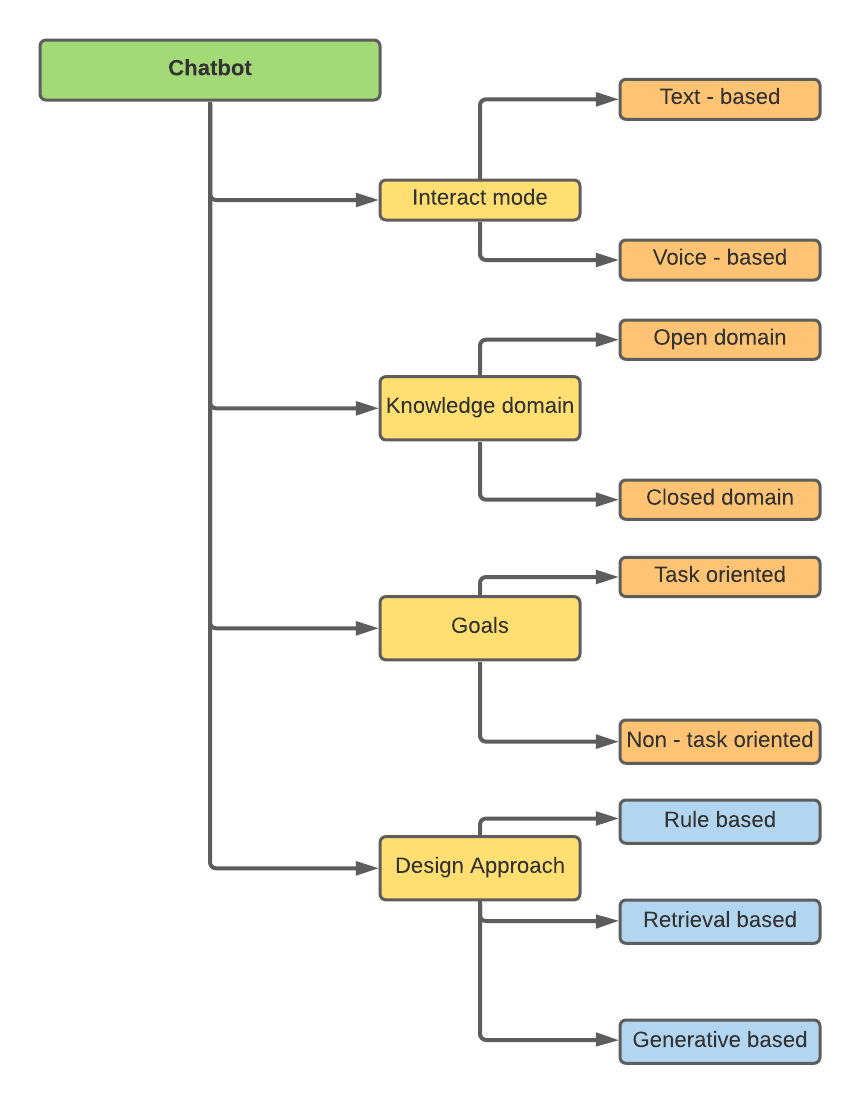
Penelitian saya terkait dengan pendekatan desain, yaitu, berbasis aturan, pengambilan berbasis, dan berbasis generatif.
Dataset diambil dari Kaggle - Mental Health FAQ. Dataset ini terdiri dari 98 FAQ tentang kesehatan mental. Terdiri dari 3 kolom - pertanyaan, pertanyaan, dan jawaban.
Perhatikan bahwa untuk melatih chatbot pengambilan, file CSV secara manual dikonversi ke file JSON . Karena ini bukan dataset asli yang digunakan untuk penelitian (baca intro), saya hanya menggunakan 20 baris pertama untuk melatih model.
Repositori terdiri dari tiga buku catatan untuk tiga jenis chatbots.
Untuk berbasis aturan, TF-IDF digunakan dengan tokenizer NLTK untuk preproses data. Data yang diproses diuji terhadap hasil yang diharapkan dan kesamaan kosinus digunakan untuk evaluasi.
Untuk berbasis pengambilan, beberapa model pembelajaran mesin dan pembelajaran mendalam dilatih,
Untuk chatbots berbasis generatif, NLP digunakan karena NLP memungkinkan chatbots untuk belajar dan meniru pola dan gaya percakapan manusia . Ini memberi Anda perasaan bahwa Anda berbicara dengan manusia, bukan robot. Ini memetakan input pengguna ke niat, dengan tujuan mengklasifikasikan pesan untuk respons yang mungkin ditentukan sebelumnya.
Selama proyek ini, kebingungan terbesar yang saya miliki adalah mengapa chatbot menggunakan file JSON alih-alih CSV untuk model berbasis pengambilan. Saya telah mendaftarkan beberapa poin yang membuat perbandingan antara kedua jenis file -
Saya ingin meneliti kemungkinan chatbot berbasis generatif lebih lanjut. Model encoder-decoder saat ini tidak dapat menangkap semua dependensi pada lapisan dekoder karena sifat kompak LSTM. Lapisan perhatian dapat ditambahkan setelah lapisan LSTM untuk memecahkan kode setiap output secara dinamis.


