Chatbot for mental health
1.0.0
Stellen Sie vor dem Ausführen der Skripte sicher, dass Sie die Python -Version <= 3.8 installiert haben (vorzugsweise Python 3.8; erforderlich, um einige Bibliotheken wie TensorFlow zu installieren).
Dieses Projekt wurde für ein Forschungsprojekt unter einem Professor an meiner Universität mit einem selbstgekratzten Datensatz durchgeführt. Der von uns verwendete Datensatz ist vertraulich; Daher habe ich ein Beispielkaggle -Datensatz verwendet. Ich beschloss, die Skripte offen zu machen, um in Python verschiedene Chatbots von Grund auf neu zu erstellen, da ich während meiner Forschung mit solchen Ressourcen zu kämpfen hatte.
Im Jahr 2017 berichtete die Nationale Umfrage zur psychischen Gesundheit, dass einer von sieben Menschen in Indien an psychischen Störungen litt, einschließlich Depressionen und Angstzuständen. Das zunehmende Bewusstsein für psychische Gesundheit hat es zu einem wichtigen Anliegen der Entwicklung gemacht. Fast 150 Millionen Menschen in Indien brauchten Interventionen, bei denen die niedrige und die Mittelklasse mehr Belastung ausgesetzt war als die wohlhabenden Menschen. Dieses Projekt ist ein Versuch, die psychische Gesundheit zugänglicher zu machen. Dieser Konversationsmittel kann durch Kliniker ergänzt werden, um es effektiver und fruchtbarer zu machen.
Chatbots können auf der Grundlage verschiedener Attribute klassifiziert werden -
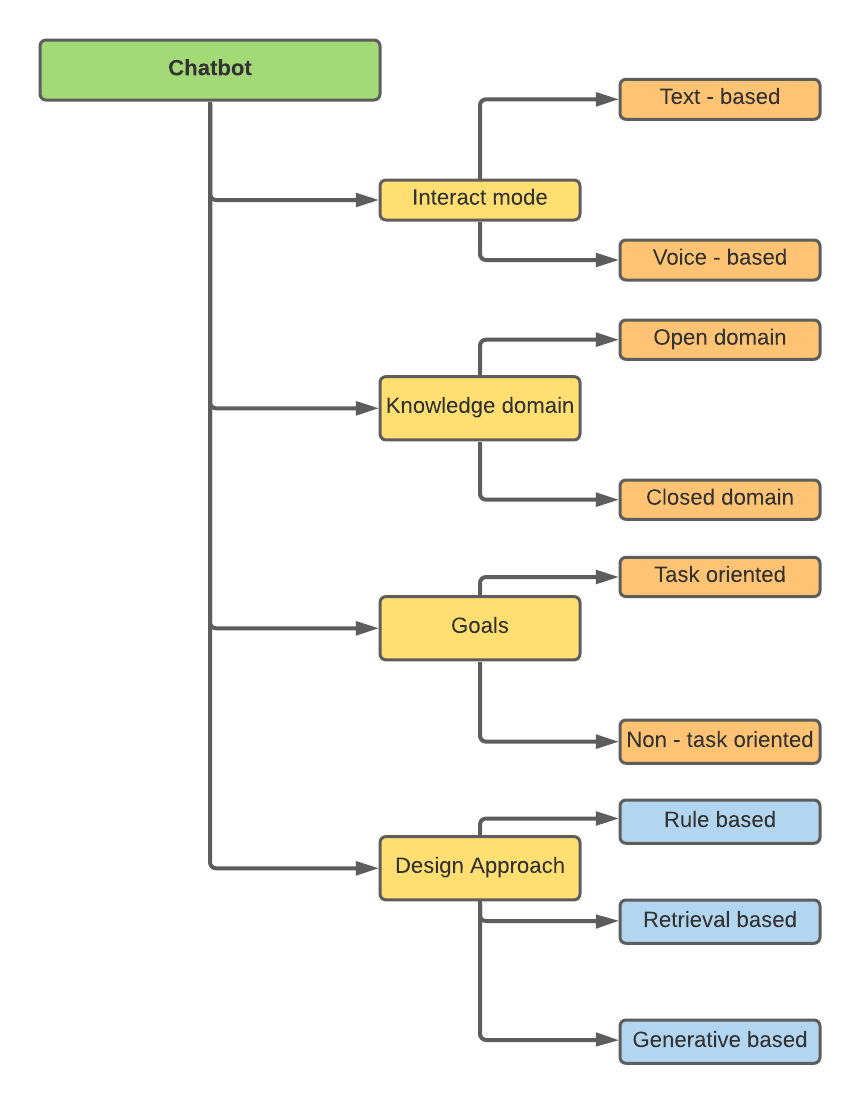
Meine Forschung bezogen sich auf die Designansätze, nämlich regelbasierte, retrievalbasierte und generativbasierte.
Der Datensatz wurde von Kaggle - FAQ für psychische Gesundheit abgeholt. Dieser Datensatz besteht aus 98 FAQs über die psychische Gesundheit. Es besteht aus 3 Spalten - Frage, Fragen und Antworten.
Beachten Sie, dass die CSV -Datei, um den Abruf -Chatbot zu trainieren, manuell in eine JSON -Datei konvertiert wurde . Da dies nicht der ursprüngliche Datensatz ist, der für die Forschung verwendet wird (Intro lesen), habe ich nur die ersten 20 Zeilen für das Training des Modells verwendet.
Das Repository besteht aus drei Notizbüchern für die drei Arten von Chatbots.
Für regelbasierte TF-IDF wurde mit dem Tokenizer von NLTK zur Datenerprozessierung verwendet. Die verarbeiteten Daten wurden gegen das erwartete Ergebnis getestet und die Ähnlichkeit der Kosinus zur Bewertung wurde verwendet.
Für den Abruf basiert wurden mehrere Modelle für maschinelles Lernen und Deep Learning ausgebildet,
Für generative Chatbots wurde NLP verwendet, da NLP Chatbots ermöglicht, die Muster und Stile menschlicher Konversation zu lernen und nachzuahmen . Es gibt Ihnen das Gefühl, dass Sie mit einem Menschen sprechen, nicht mit einem Roboter. Es ordnet die Benutzereingabe auf eine Absicht zu, mit dem Ziel, die Nachricht für eine geeignete vordefinierte mögliche Antwort zu klassifizieren.
Während dieses Projekts verwendete der Chatbot die größte Verwirrung, warum der Chatbot eine JSON-Datei anstelle von CSV für das retrievalbasierte Modell verwendete. Ich habe einige Punkte aufgeführt, die den Vergleich zwischen den beiden Dateitypen machen -
Ich möchte die Möglichkeiten des generativen Chatbots weiter erforschen. Das aktuelle Encoder-Decoder-Modell kann aufgrund der kompakten Natur von LSTM nicht alle Abhängigkeiten in der Decoderschicht erfassen. Aufmerksamkeitsebenen können nach LSTM -Ebenen hinzugefügt werden, um jeden Ausgang dynamisch zu dekodieren.


