Chatbot for mental health
1.0.0
ก่อนที่คุณจะเรียกใช้สคริปต์ตรวจสอบให้แน่ใจว่าคุณมีรุ่น Python <= 3.8 ติดตั้ง (ควรมี Python 3.8; จำเป็นสำหรับการติดตั้งไลบรารีบางอย่างเช่น TensorFlow)
โครงการนี้ทำเพื่อโครงการวิจัยภายใต้ศาสตราจารย์ที่มหาวิทยาลัยของฉันด้วยชุดข้อมูลที่สาดด้วยตนเอง ชุดข้อมูลที่เราใช้เป็นความลับ ดังนั้นฉันจึงใช้ชุดข้อมูล Kaggle ตัวอย่าง ฉันตัดสินใจที่จะทำให้สคริปต์โอเพนซอร์สเพื่อรวบรวม chatbots ที่แตกต่างกันตั้งแต่เริ่มต้นใน Python เนื่องจากฉันต่อสู้กับทรัพยากรดังกล่าวในระหว่างการวิจัยของฉัน
ในปี 2560 การสำรวจสุขภาพจิตแห่งชาติรายงานว่าหนึ่งในเจ็ดคนในอินเดียได้รับความทุกข์ทรมานจากความผิดปกติทางจิตรวมถึงภาวะซึมเศร้าและความวิตกกังวล การรับรู้ที่เพิ่มขึ้นของสุขภาพจิตทำให้เป็นข้อกังวลหลักของการพัฒนา เกือบ 150 ล้านคนในอินเดียต้องการการแทรกแซงที่ซึ่งชนชั้นต่ำและชนชั้นกลางต้องเผชิญกับภาระมากกว่าคนดี โครงการนี้เป็นความพยายามที่จะทำให้สุขภาพจิตสามารถเข้าถึงได้มากขึ้น ตัวแทนการสนทนานี้สามารถเสริมด้วยแพทย์เพื่อให้มีประสิทธิภาพและมีผลมากขึ้น
แชทบอทสามารถจำแนกได้บนพื้นฐานของแอตทริบิวต์ที่แตกต่างกัน -
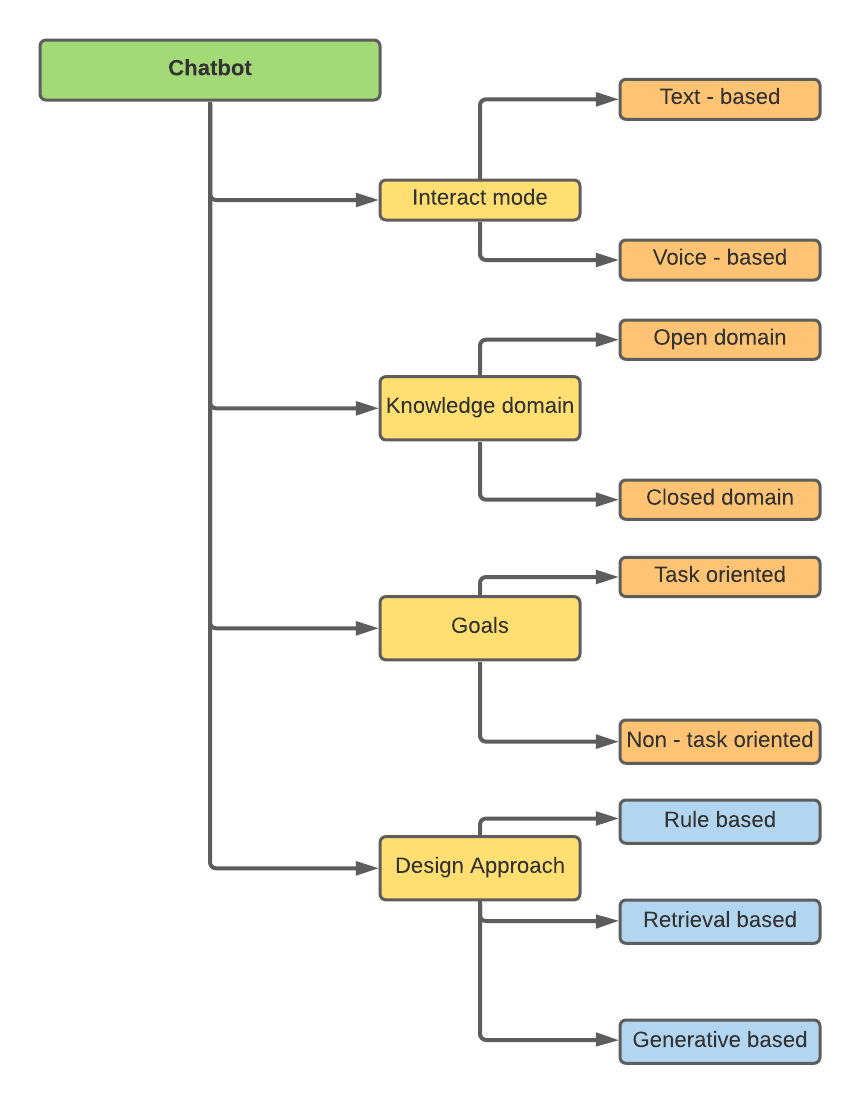
การวิจัยของฉันเกี่ยวข้องกับวิธีการออกแบบคือกฎพื้นฐานการดึงข้อมูลและการกำเนิด
ชุดข้อมูลถูกหยิบขึ้นมาจาก Kaggle - คำถามที่พบบ่อยด้านสุขภาพจิต ชุดข้อมูลนี้ประกอบด้วยคำถามที่พบบ่อย 98 เรื่องเกี่ยวกับสุขภาพจิต ประกอบด้วย 3 คอลัมน์ - คำถามคำถามและคำตอบ
โปรดทราบว่าในการฝึกอบรม chatbot ดึงไฟล์ CSV ถูกแปลงเป็นไฟล์ JSON ด้วยตนเอง เนื่องจากนี่ไม่ใช่ชุดข้อมูลต้นฉบับที่ใช้สำหรับการวิจัย (อ่านอินโทร) ฉันจึงใช้เฉพาะ 20 แถวแรกสำหรับการฝึกอบรมแบบจำลอง
ที่เก็บประกอบด้วยโน้ตบุ๊กสามใบสำหรับแชทบอทสามประเภท
สำหรับกฎตามกฎ TF-IDF ใช้กับ โทเค็นของ NLTK สำหรับการประมวลผลข้อมูล ข้อมูลที่ประมวลผลได้รับการทดสอบกับผลลัพธ์ที่คาดหวังและ ความคล้ายคลึงกันของโคไซน์ ใช้สำหรับการประเมินผล
สำหรับการดึงข้อมูลการเรียนรู้ของเครื่องจักรและการเรียนรู้อย่างลึกซึ้งได้รับการฝึกอบรม
สำหรับ chatbots ที่ใช้กำเนิดมาใช้ NLP ถูกนำมาใช้เนื่องจาก NLP ช่วยให้แชทบอทสามารถเรียนรู้และเลียนแบบรูปแบบและรูปแบบของการสนทนาของมนุษย์ มันทำให้คุณรู้สึกว่าคุณกำลังคุยกับมนุษย์ไม่ใช่หุ่นยนต์ มันแมปอินพุตผู้ใช้เข้ากับเจตนาโดยมีจุดประสงค์ในการจำแนกข้อความสำหรับการตอบสนองที่กำหนดไว้ล่วงหน้าที่เหมาะสม
ในระหว่างโครงการนี้ความสับสนที่ยิ่งใหญ่ที่สุดที่ฉันมีคือสาเหตุที่ chatbot ใช้ไฟล์ JSON แทน CSV สำหรับโมเดลการดึงข้อมูล ฉันได้ระบุบางจุดที่ทำให้การเปรียบเทียบระหว่างสองประเภทไฟล์ -
ฉันต้องการค้นคว้าความเป็นไปได้ของ Chatbot ที่ใช้กำเนิด โมเดลตัวเข้ารหัส Decoder ปัจจุบันไม่สามารถจับการพึ่งพาทั้งหมดในชั้นถอดรหัสได้เนื่องจากลักษณะที่กะทัดรัดของ LSTM สามารถเพิ่มเลเยอร์ความสนใจได้หลังจากเลเยอร์ LSTM เพื่อถอดรหัสแต่ละเอาต์พุตแบบไดนามิก


