Chatbot for mental health
1.0.0
スクリプトを実行する前に、Pythonバージョン<= 3.8がインストールされていることを確認してください(できればPython 3.8; Tensorflowなどのライブラリをインストールするために必要です)。
このプロジェクトは、私の大学の教授の下で、自立したデータセットを持つ研究プロジェクトのために行われました。使用したデータセットは機密です。したがって、サンプルKaggleデータセットを使用しました。私は、研究中にそのようなリソースに苦労していたので、Pythonでゼロから異なるチャットボットを編集するためにスクリプトをオープンソースにすることにしました。
2017年、全国メンタルヘルス調査は、インドの7人に1人がうつ病や不安を含む精神障害に苦しんでいると報告しました。メンタルヘルスに対する意識の高まりにより、開発の主な関心が高まっています。インドのほぼ1億5,000万人が介入を必要としていました。そこでは、低中流階級と中流階級が裕福な人々よりも多くの負担に直面していました。このプロジェクトは、メンタルヘルスをよりアクセスしやすくする試みです。この会話エージェントは、臨床医を補完して、より効果的で実り多いものにすることができます。
チャットボットは、さまざまな属性に基づいて分類できます -
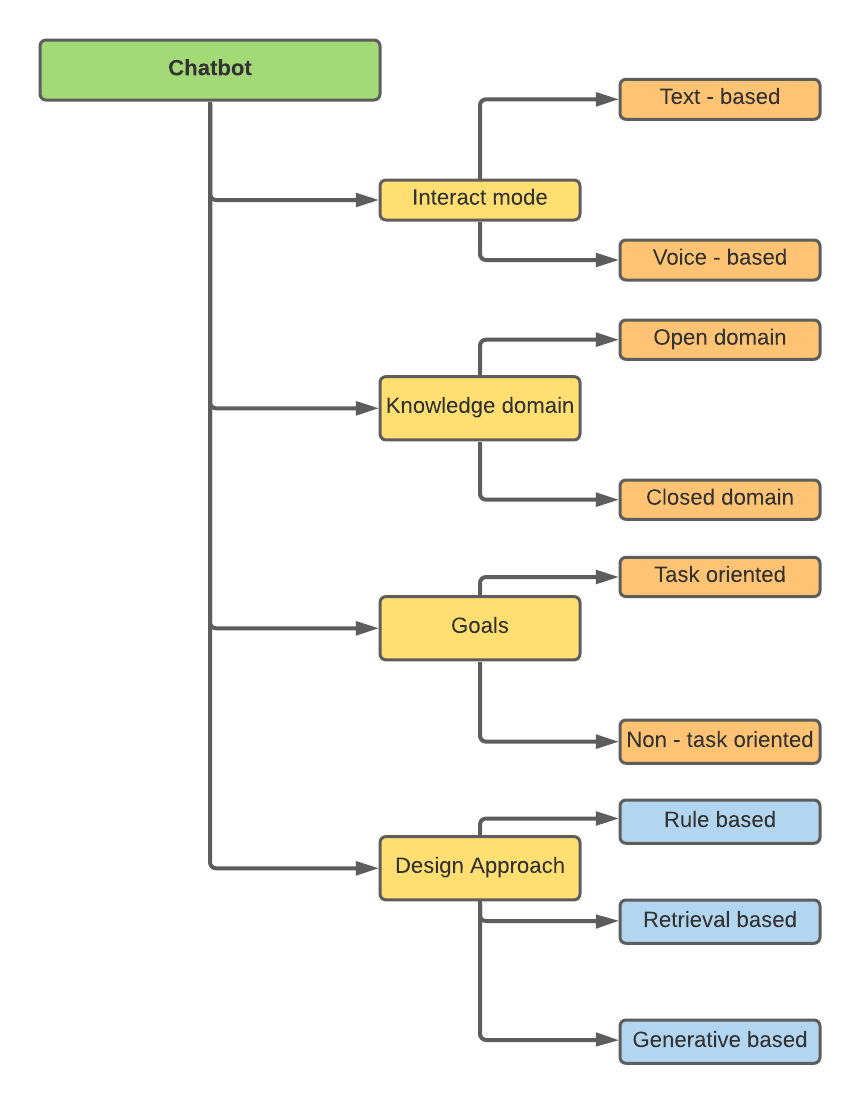
私の研究は、設計アプローチ、すなわちルールベース、検索ベース、および生成ベースに関連していました。
データセットは、Kaggle -Mental Health FAQからピックアップされました。このデータセットは、メンタルヘルスに関する98のFAQで構成されています。質問、質問、回答の3つの列で構成されています。
検索チャットボットをトレーニングするために、CSVファイルはJSONファイルに手動で変換されたことに注意してください。これは研究に使用される元のデータセットではないため(イントロを読む)、モデルのトレーニングに最初の20行のみを使用しました。
リポジトリは、3種類のチャットボット用の3つのノートブックで構成されています。
ルールベースの場合、 TF-IDFは、データ処理のためにNLTKのトークンザーとともに使用されました。処理されたデータは、予想される結果に対してテストされ、コサインの類似性が評価に使用されました。
検索ベースのために、いくつかの機械学習と深い学習モデルが訓練されました、
生成ベースのチャットボットの場合、 NLPはチャットボットが人間の会話のパターンとスタイルを学習して模倣できるため、NLPが使用されました。それはあなたがロボットではなく、人間と話しているという感覚をあなたに与えます。適切な事前定義された可能な応答のためにメッセージを分類することを目的として、ユーザーの入力を意図にマッピングします。
このプロジェクト中、私が持っていた最大の混乱は、Chatbotが検索ベースのモデルにCSVの代わりにJSONファイルを使用した理由です。 2つのファイルタイプを比較するいくつかのポイントをリストアップしました -
生成ベースのチャットボットの可能性をさらに調査したいと思います。現在のエンコーダーデコーダーモデルは、LSTMのコンパクトな性質のため、デコーダーレイヤーのすべての依存関係をキャプチャできません。 LSTMレイヤーの後に注意レイヤーを追加して、各出力を動的にデコードできます。


