Chatbot for mental health
1.0.0
قبل تشغيل البرامج النصية ، تأكد من تثبيت إصدار Python <= 3.8 (ويفضل أن يكون Python 3.8 ؛ مطلوبًا لتثبيت بعض المكتبات مثل TensorFlow).
تم تنفيذ هذا المشروع لمشروع بحثي تحت قيادة أستاذ في جامعتي مع مجموعة بيانات ذاتية النقر. مجموعة البيانات التي استخدمناها سرية ؛ وبالتالي ، لقد استخدمت مجموعة بيانات Kaggle عينة. قررت أن أجعل البرامج النصية مفتوحة المصدر لإجراء مجموعة من الدردشة المختلفة من الصفر في بيثون منذ أن ناضلت مع هذه الموارد أثناء بحثي.
في عام 2017 ، ذكرت المسح الوطني للصحة العقلية أن واحدًا من بين كل سبعة أشخاص في الهند يعانون من اضطرابات عقلية ، بما في ذلك الاكتئاب والقلق. جعل الوعي المتزايد بالصحة العقلية مصدر قلق رئيسي للتنمية. احتاج ما يقرب من 150 مليون شخص في الهند إلى تدخلات ، حيث واجهت الطبقة المنخفضة والمتوسطة عبئًا أكثر من الأشخاص الذين يتلقونها. هذا المشروع هو محاولة لجعل الصحة العقلية أكثر سهولة. يمكن أن يستكمل هذا العامل المحادثة مع الأطباء لجعله أكثر فاعلية ومثمرة.
يمكن تصنيف chatbots على أساس سمات مختلفة -
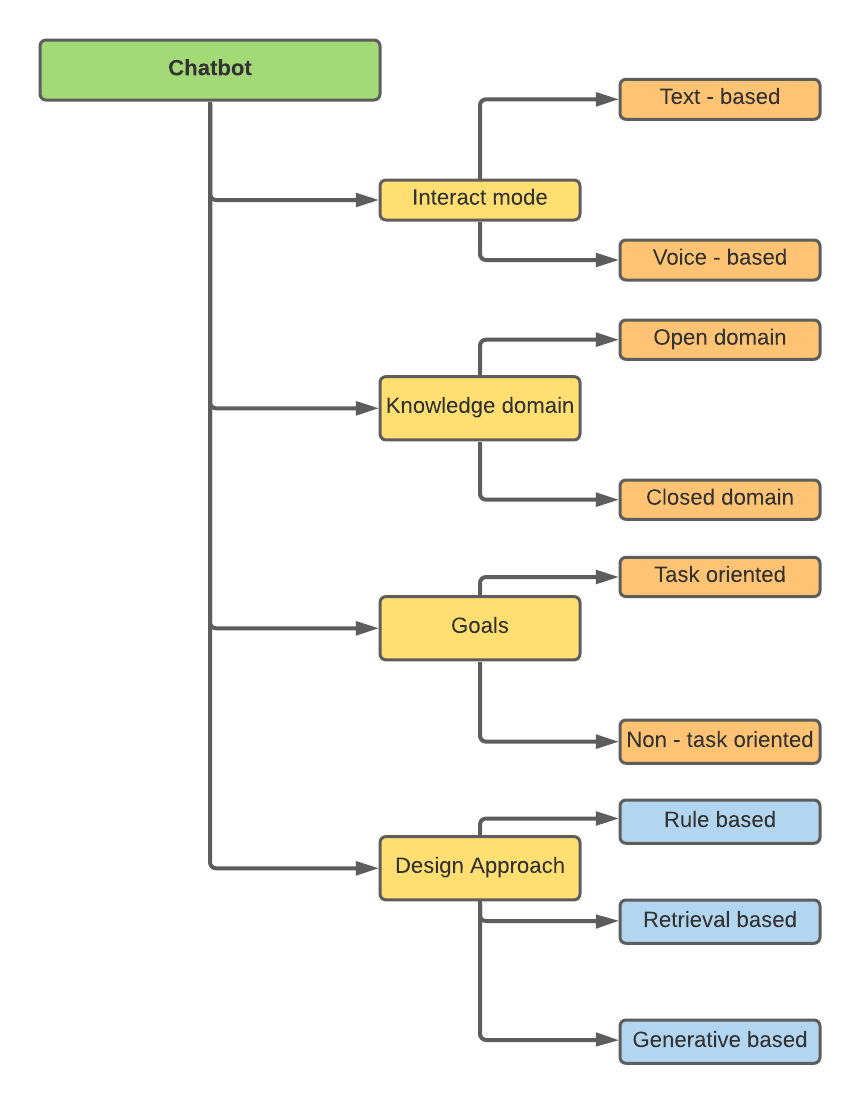
كان بحثي يرتبط بنهج التصميم ، وهي قائم على القواعد ، القائمة على الاسترجاع ، والقائمة على القائمة.
تم التقاط مجموعة البيانات من الأسئلة الشائعة حول الصحة العقلية. تتكون مجموعة البيانات هذه من 98 أسئلة وأجوبة حول الصحة العقلية. يتكون من 3 أعمدة - أسئلة وأسئلة وأجوبة.
لاحظ أنه لتدريب chatbot الاسترجاع ، تم تحويل ملف CSV يدويًا إلى ملف JSON . نظرًا لأن هذه ليست مجموعة البيانات الأصلية المستخدمة في البحث (قراءة مقدمة) ، فقد استخدمت فقط 20 صفًا لتدريب النموذج.
يتكون المستودع من ثلاثة أجهزة دفتر للأنواع الثلاثة من chatbots.
بالنسبة للقواعد المستندة إلى القواعد ، تم استخدام TF-IDF مع Tokenizer من NLTK من أجل معالجة البيانات. تم اختبار البيانات المعالجة مقابل النتيجة المتوقعة وتم استخدام تشابه جيب التمام للتقييم.
من أجل الاسترجاع ، تم تدريب العديد من نماذج التعلم الآلي والتعلم العميق ،
بالنسبة إلى chatbots المستندة إلى التداول ، تم استخدام NLP منذ أن تمكن NLP من chatbots من تعلم وتقليد أنماط وأنماط المحادثة البشرية . يمنحك الشعور بأنك تتحدث إلى إنسان ، وليس روبوتًا. يقوم بتخطيط إدخال المستخدم إلى نية ، بهدف تصنيف الرسالة للاستجابة المحتملة المحددة مسبقًا.
خلال هذا المشروع ، كان الالتباس الأكبر الذي كان لدي هو السبب في أن chatbot استخدم ملف JSON بدلاً من CSV للنموذج القائم على الاسترجاع. لقد أدرجت بعض النقاط التي تجعل المقارنة بين نوعي الملفات -
أرغب في البحث في إمكانيات chatbot المستندة إلى الأهمية. لا يمكن أن يلتقط نموذج الترميز المشفر الحالي جميع التبعيات في طبقة وحدة فك الترميز بسبب الطبيعة المدمجة لـ LSTM. يمكن إضافة طبقات الانتباه بعد طبقات LSTM لفك تشفير كل مخرج ديناميكيًا.


