SkyText Chinese GPT3
1.0.0
SkyText是由奇點智源發布的中文GPT3預訓練大模型,可以進行聊天、問答、中英互譯等不同的任務。 應用這個模型,除了可以實現基本的聊天、對話、你問我答外,還能支持中英文互譯、內容續寫、對對聯、寫古詩、生成菜譜、第三人稱轉述、創建採訪問題等多種功能。

一百四十億參數模型【暫時閉源,即將發布新的百億參數模型,敬請期待! 】 https://huggingface.co/SkyWork/SkyText
三十億參數模型https://huggingface.co/SkyWork/SkyTextTiny
體驗和試用,請訪問奇點智源API試用
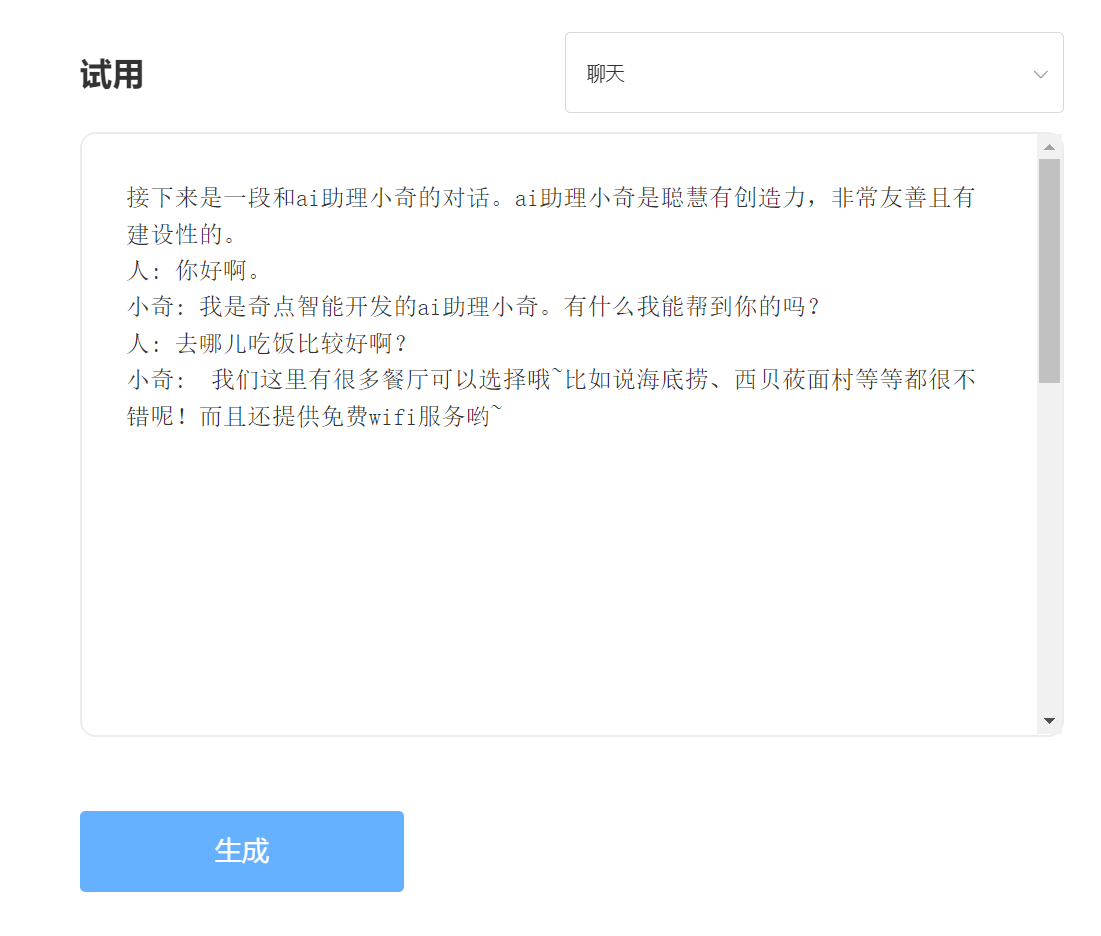
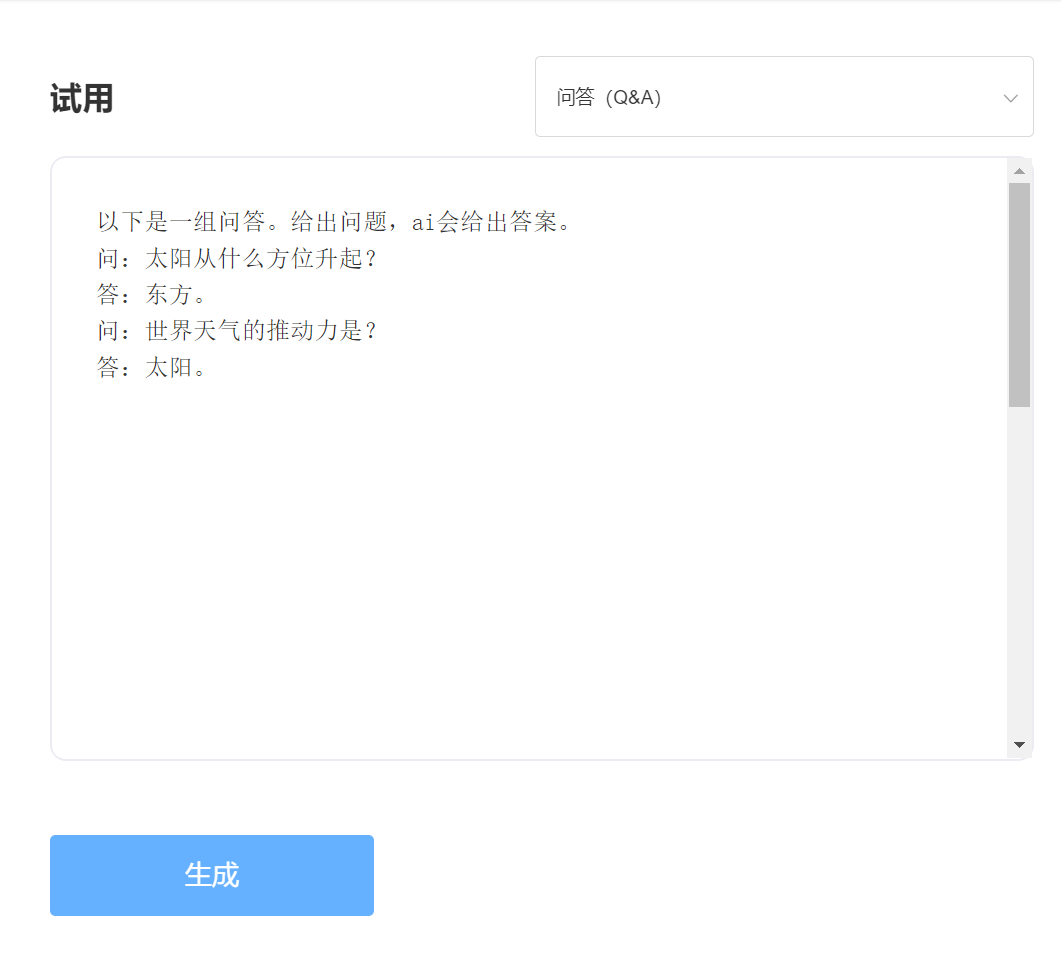
輸入: 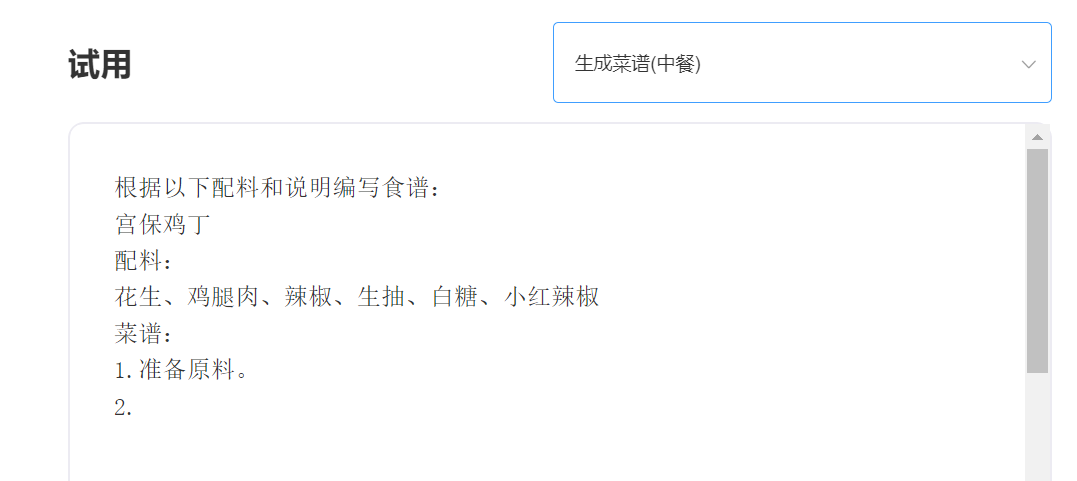
輸出: 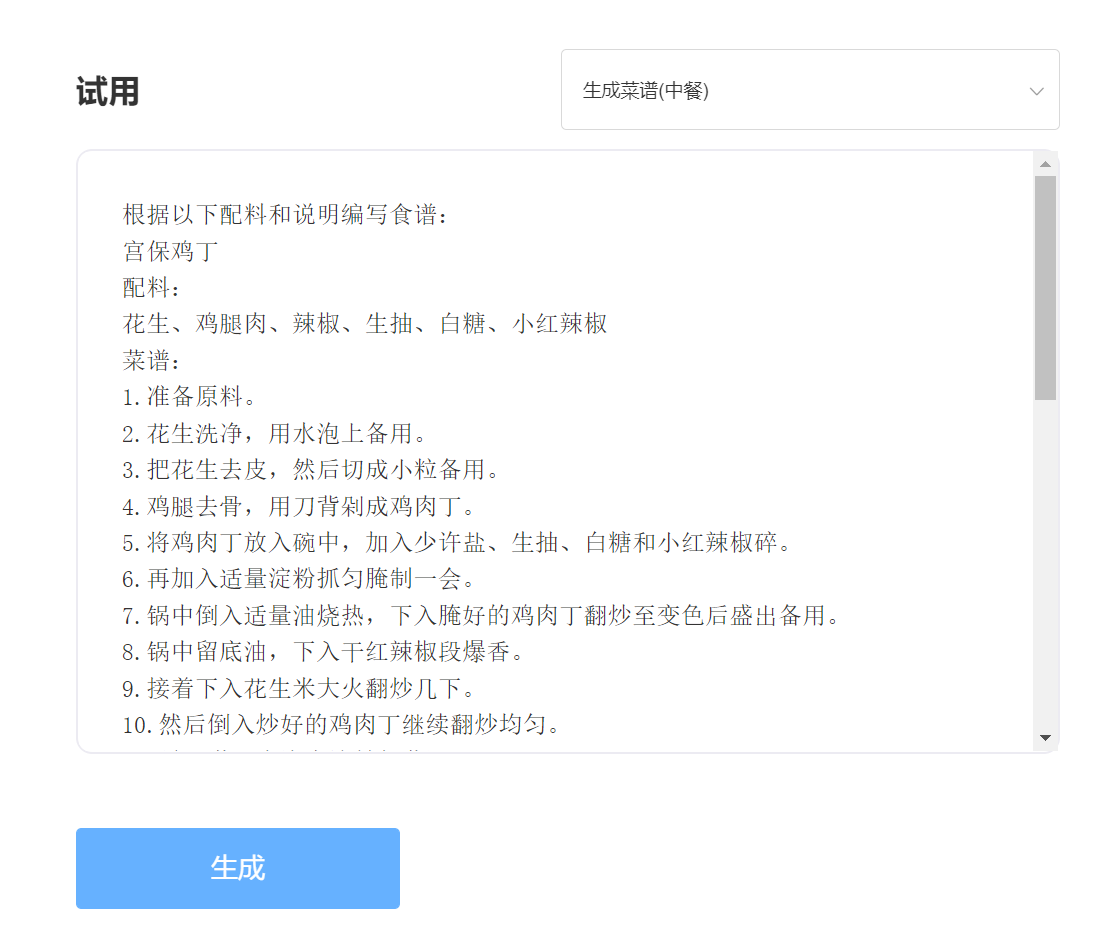
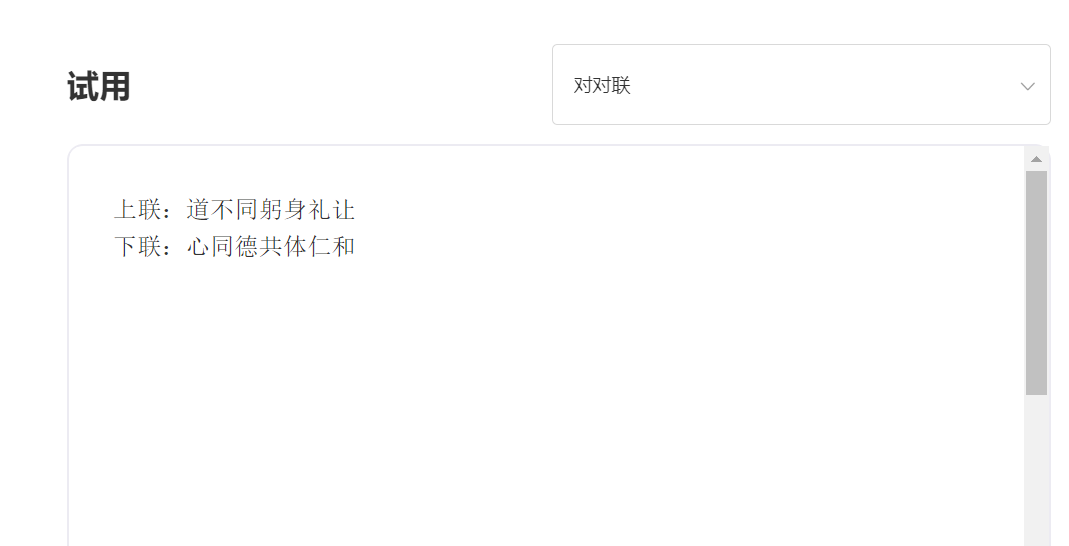
技術優勢一:30多道流程的數據清洗
隨著NLP技術的發展,預訓練大模型逐漸成為了人工智能的核心技術之一。預訓練大模型通常需要海量的文本來進行訓練,網絡文本自然成為了最重要的語料來源。而訓練語料的質量無疑直接影響著模型的效果。為了訓練出能力出眾的模型,奇點智源在數據清洗時使用了30多道的清洗流程。精益求精的細節處理,鑄造了卓越的模型效果。
技術優勢二:針對中文優化創新的中文編碼方式
曾經在預訓練大模型領域,一直是被英文社區主導著,而中文預訓練大模型的重要性不言而喻。不同於英文的拼音文字,中文預訓練大模型的中文輸入方式顯然應該有所不同。奇點智源針對中文的特點,優化創新使用了獨特的中文編碼方式,更加符合中文的語言習慣,重新構建出更利於模型理解的中文字典。
——————————————————————————————————
推荐
transformers>=4.18.0
# -*- coding: utf-8 -*-
from transformers import GPT2LMHeadModel
from transformers import AutoTokenizer
from transformers import TextGenerationPipeline
# 以 SkyWork/SkyText(13billions) 为例,还有 SkyWork/SkyTextTiny(2.6billions) 可用, 期待使用
model = GPT2LMHeadModel . from_pretrained ( "SkyWork/SkyText" )
tokenizer = AutoTokenizer . from_pretrained ( "SkyWork/SkyText" , trust_remote_code = True )
text_generator = TextGenerationPipeline ( model , tokenizer , device = 0 )
input_str = "今天是个好天气"
max_new_tokens = 20
print ( text_generator ( input_str , max_new_tokens = max_new_tokens , do_sample = True )) MIT License