SkyText Chinese GPT3
1.0.0
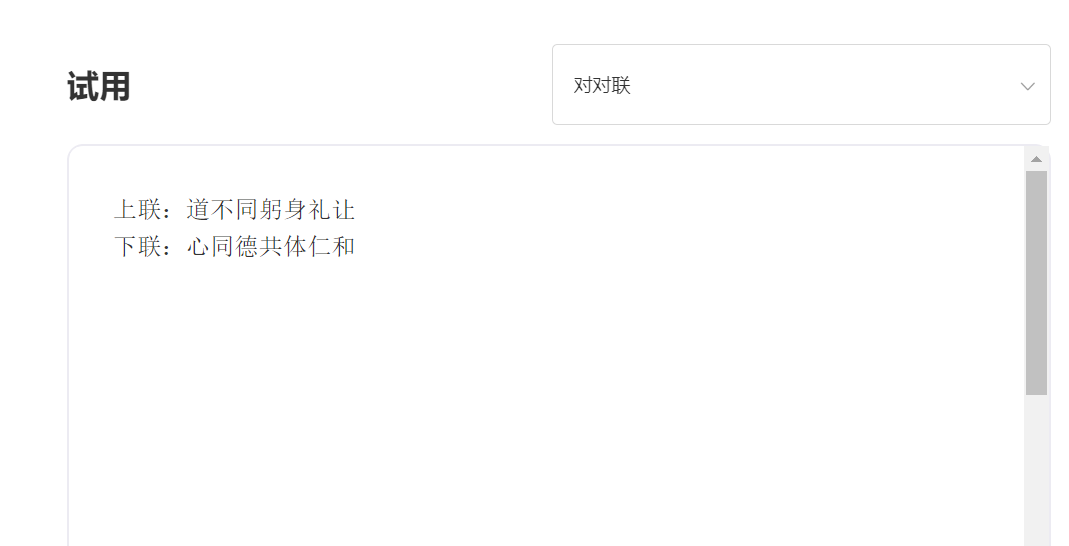
SkyText est un grand modèle chinois pré-formé GPT3 publié par la singularité Zhiyuan, qui peut effectuer différentes tâches telles que le chat, les questions et réponses et la traduction chinoise-anglais. En plus de mettre en œuvre le chat de base, le dialogue, les questions et les réponses, ce modèle peut également soutenir la traduction chinoise et anglaise, la continuation de contenu, les distiques, la rédaction de poèmes anciens, la génération de recettes, les republication des tiers, la création de questions d'entrevue et d'autres fonctions.

Un modèle de cent et quatre milliards de paramètres [a temporairement fermé la source, un nouveau modèle de paramètres de dix milliards sera publié bientôt, alors restez à l'écoute! 】 Https://huggingface.co/skywork/skytext
Modèle de paramètres de trois milliards https://huggingface.co/skywork/skytexttiny
Expérience et essai, veuillez visiter l'essai API intelligent de la singularité
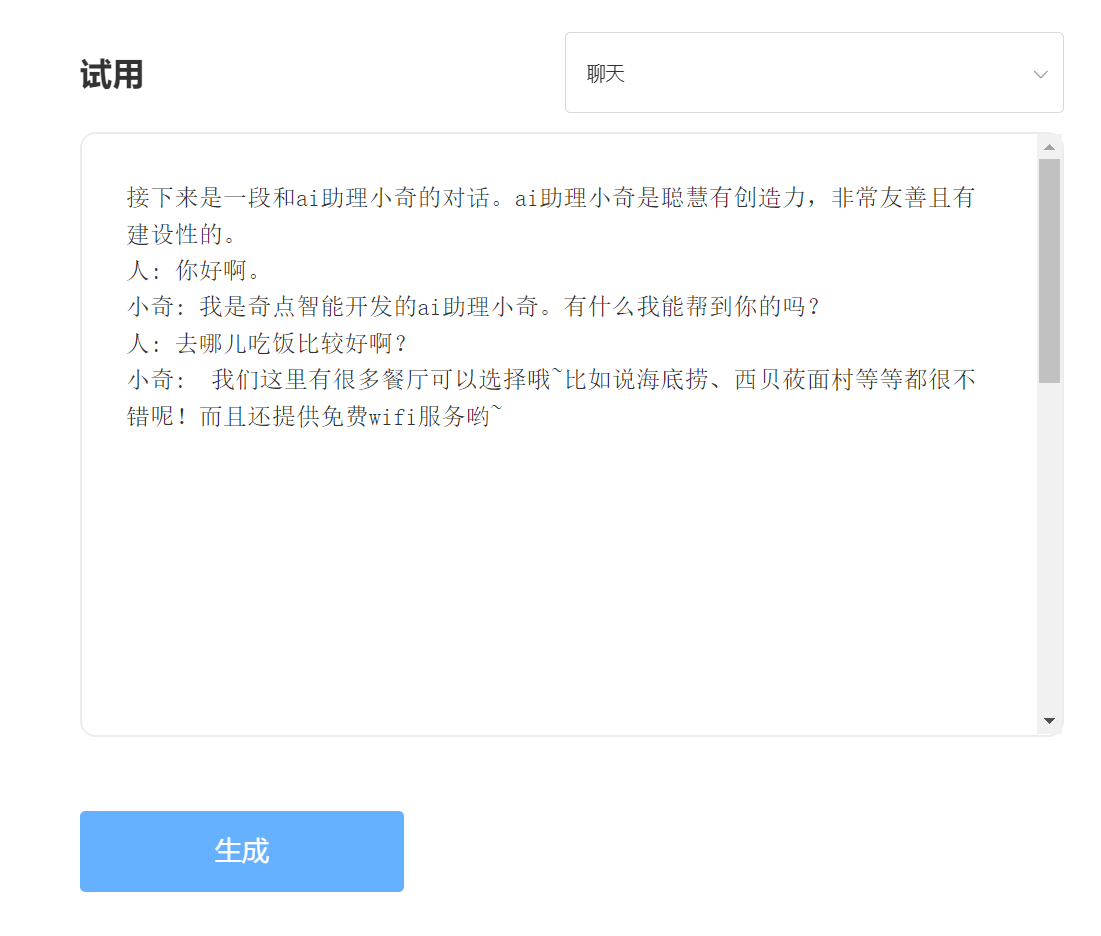
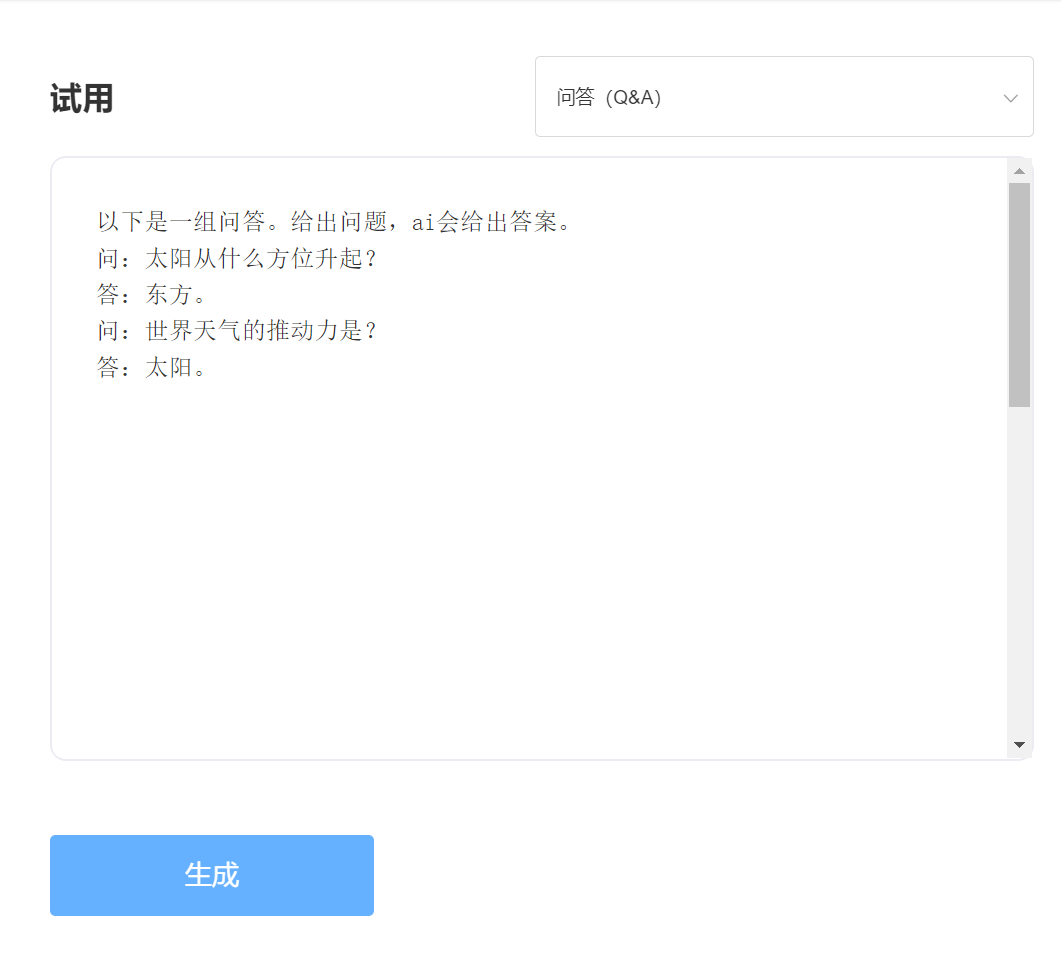
entrer: 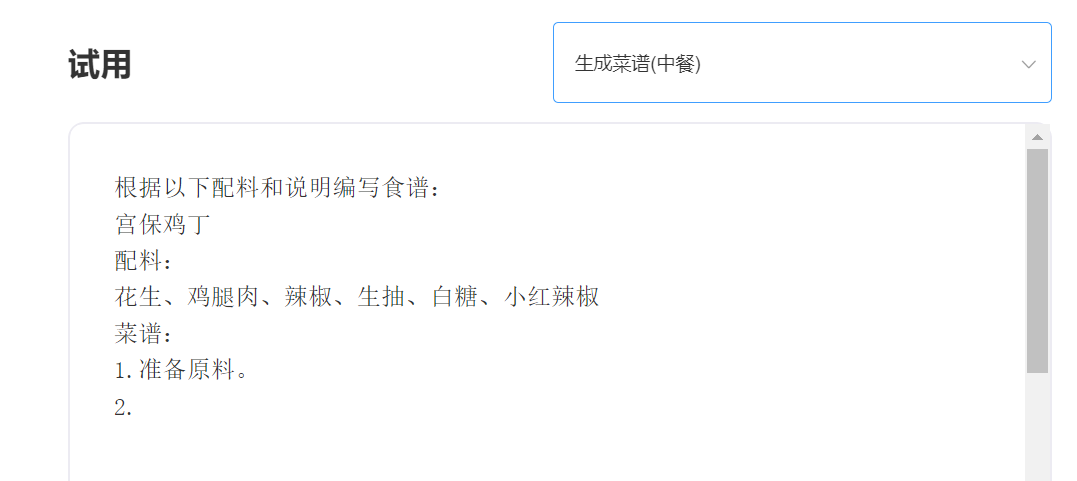
Sortir: 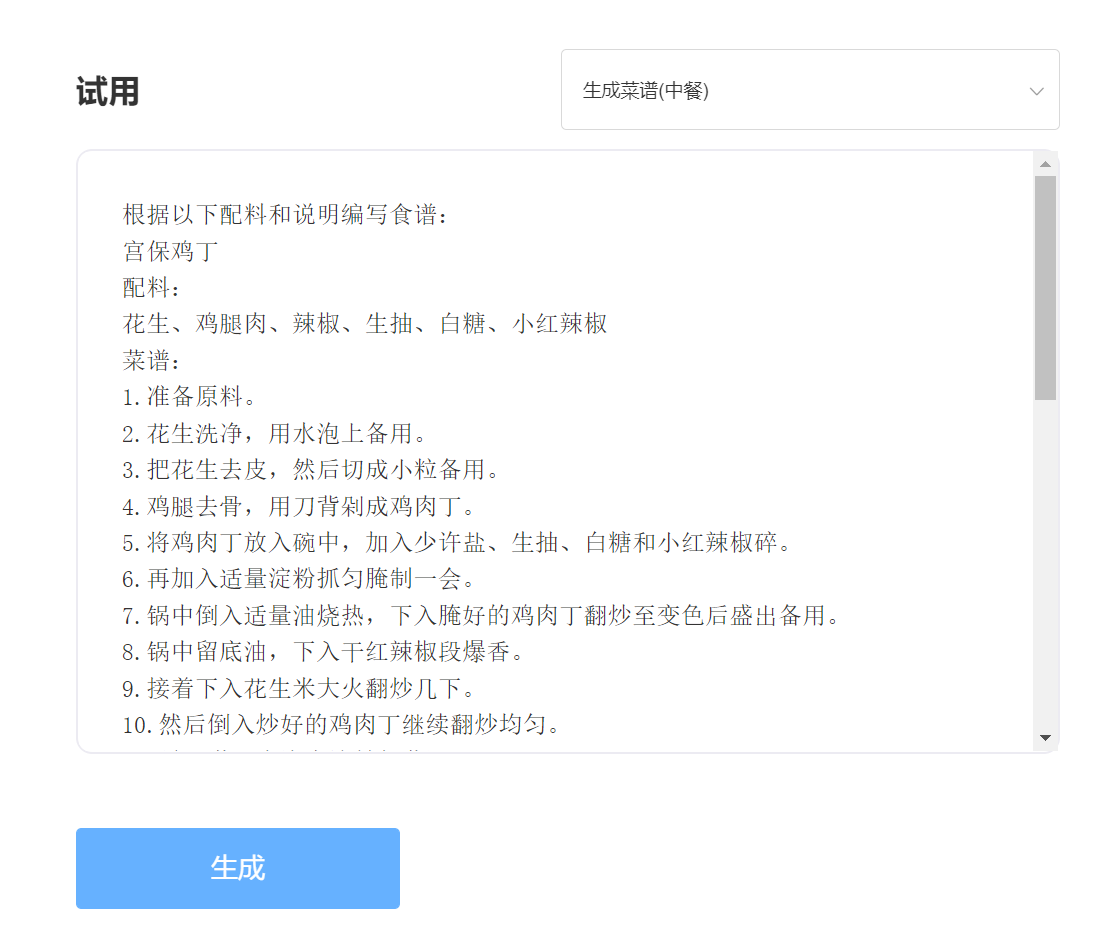
Avantage technique 1: Nettoyage des données avec plus de 30 processus
Avec le développement de la technologie PNL, les grands modèles pré-formés sont progressivement devenus l'une des technologies principales de l'intelligence artificielle. Les grands modèles pré-formés nécessitent généralement un texte massif pour être formé, et le texte en ligne devient naturellement la source la plus importante de corpus. La qualité du corpus de formation affecte sans aucun doute directement l'efficacité du modèle. Afin de former un modèle avec des capacités exceptionnelles, la singularité de l'intelligence a utilisé plus de 30 processus de nettoyage lors du nettoyage des données. Les détails exquis ont créé d'excellents effets de modèle.
Avantage technique 2: Méthodes de codage chinois qui optimisent et innovent le chinois
Dans le domaine des grands modèles avant la formation, il a toujours été dominé par la communauté anglaise, et l'importance des grands modèles pré-formation en chinois est évidente. Contrairement au texte Pinyin en anglais, la méthode d'entrée chinoise des modèles chinois pré-formée devrait évidemment être différente. Singelarity Intelligence utilise des méthodes de codage chinois uniques basées sur les caractéristiques de la langue chinoise, qui est plus conforme aux habitudes de langue chinoise et reconstruit un dictionnaire chinois plus propice à la compréhension du modèle.
——————————————————————————————————
推荐
transformers>=4.18.0
# -*- coding: utf-8 -*-
from transformers import GPT2LMHeadModel
from transformers import AutoTokenizer
from transformers import TextGenerationPipeline
# 以 SkyWork/SkyText(13billions) 为例,还有 SkyWork/SkyTextTiny(2.6billions) 可用, 期待使用
model = GPT2LMHeadModel . from_pretrained ( "SkyWork/SkyText" )
tokenizer = AutoTokenizer . from_pretrained ( "SkyWork/SkyText" , trust_remote_code = True )
text_generator = TextGenerationPipeline ( model , tokenizer , device = 0 )
input_str = "今天是个好天气"
max_new_tokens = 20
print ( text_generator ( input_str , max_new_tokens = max_new_tokens , do_sample = True )) Licence MIT