SkyText Chinese GPT3
1.0.0
SkyText는 Chat, Q & A 및 중국어-영어 번역과 같은 다양한 작업을 수행 할 수있는 Singularity Zhiyuan이 발표 한 중국 GPT3 미리 훈련 된 큰 모델입니다. 기본 채팅, 대화, 질문 및 답변을 구현하는 것 외에도이 모델은 중국어 및 영어 번역, 콘텐츠 연속, 커플, 고대시 작성, 레시피 생성, 3 인칭 리포지드, 인터뷰 질문 및 기타 기능을 지원할 수 있습니다.

140 억 개의 매개 변수 모델 [일시적으로 소스를 닫으면 새로운 10 억 매개 변수 모델이 곧 출시 될 예정이므로 계속 지켜봐 주시기 바랍니다! https://huggingface.co/skywork/skytext
30 억 매개 변수 모델 https://huggingface.co/skywork/skytexttiny
경험 및 시험, Singularity Intelligent API 시험을 방문하십시오.
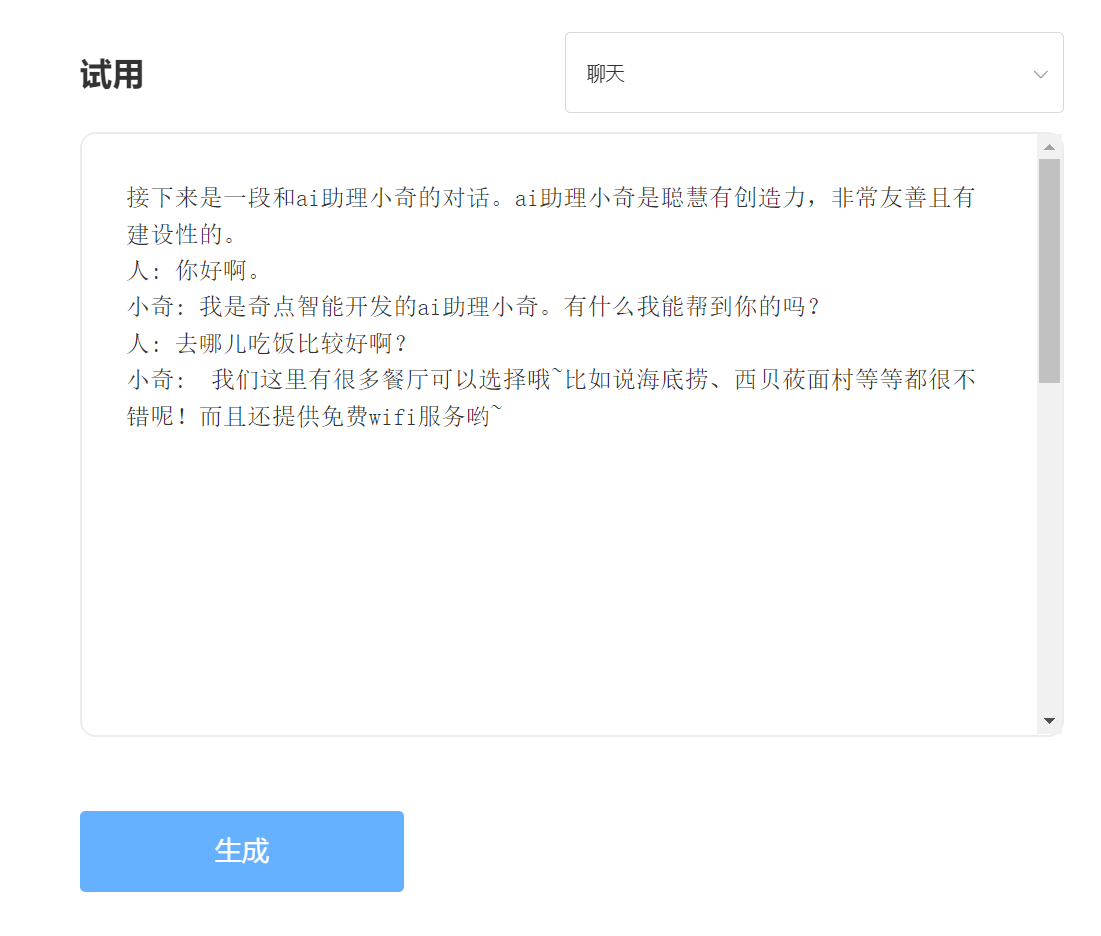
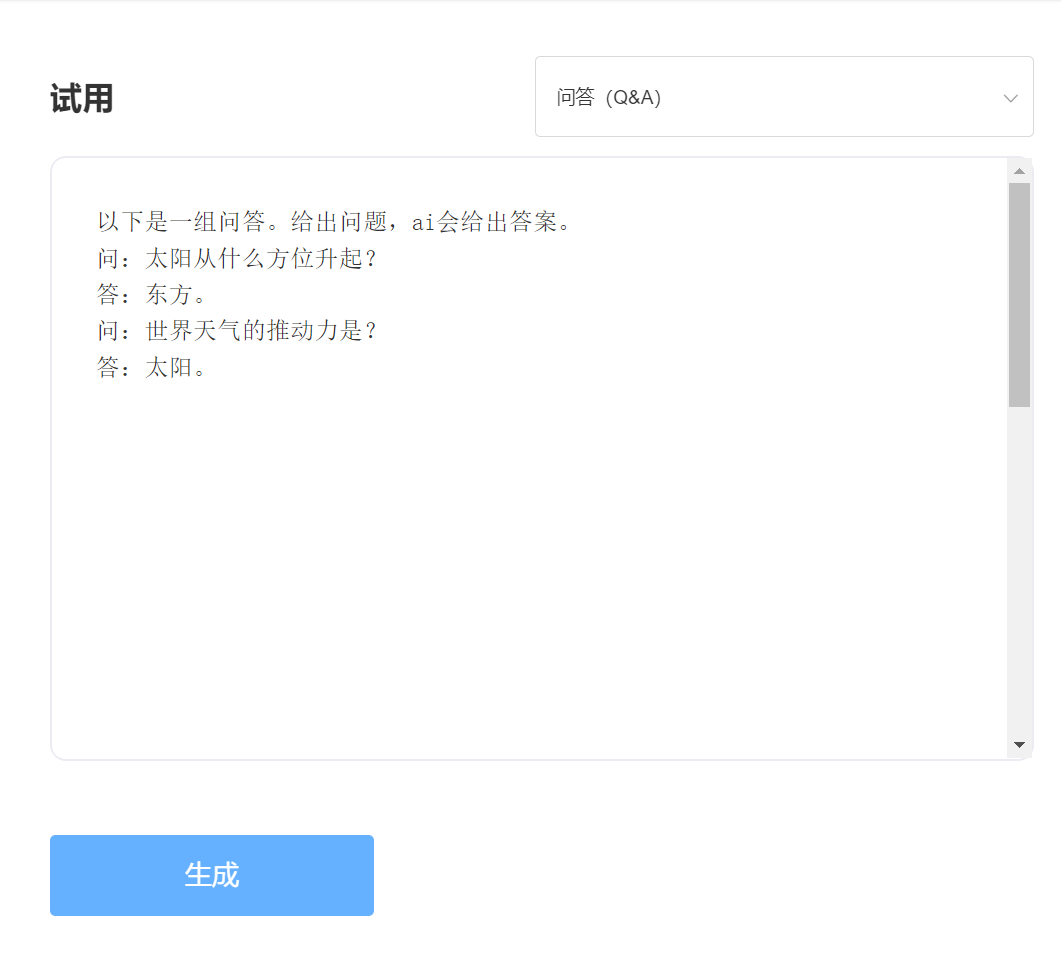
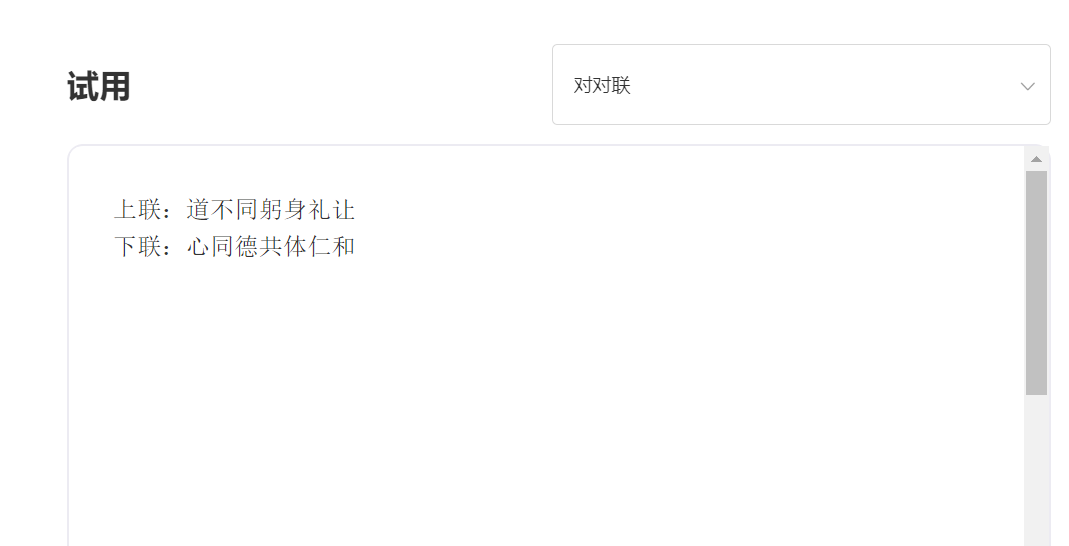
입력하다: 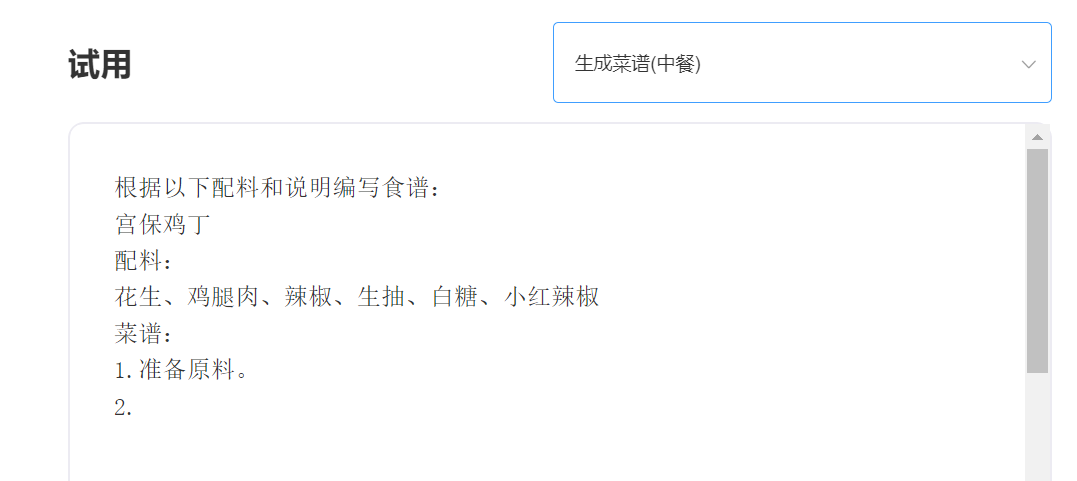
산출: 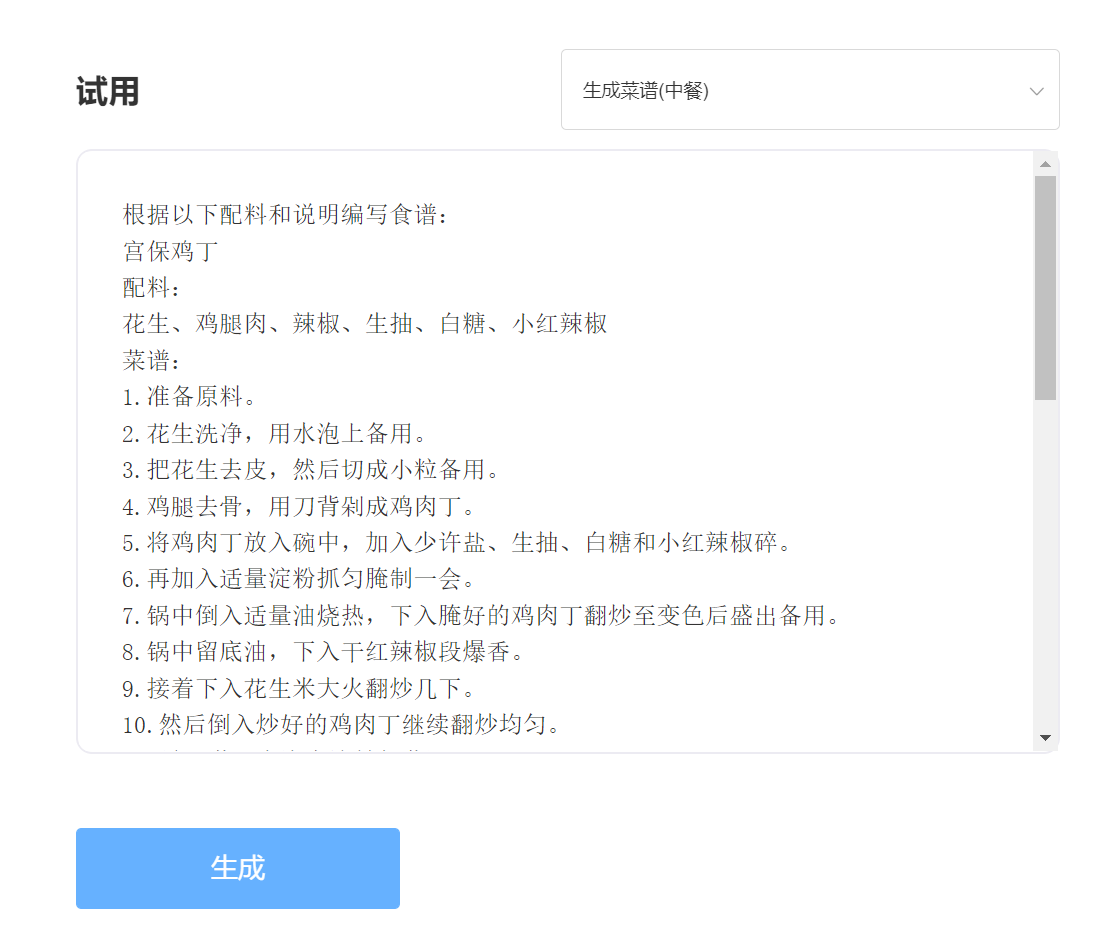
기술적 이점 1 : 30 개 이상의 프로세스가있는 데이터 청소
NLP 기술의 개발로 미리 훈련 된 대형 모델은 점차 인공 지능의 핵심 기술 중 하나가되었습니다. 미리 훈련 된 대형 모델은 일반적으로 대규모 텍스트를 훈련해야하며 온라인 텍스트는 자연스럽게 가장 중요한 코퍼스 소스가됩니다. 훈련 코퍼스의 품질은 의심 할 여지없이 모델의 효과에 직접적인 영향을 미칩니다. 뛰어난 기능으로 모델을 훈련시키기 위해 Singularity Intelligence는 데이터를 청소할 때 30 개 이상의 세척 과정을 사용했습니다. 절묘한 세부 사항은 우수한 모델 효과를 만들었습니다.
기술적 이점 2 : 중국어를 최적화하고 혁신하는 중국 코딩 방법
대형 모델을 사전 훈련하는 분야에서는 항상 영어 커뮤니티에 의해 지배되어 왔으며 중국어에서 큰 모델을 미리 훈련하는 것의 중요성은 자명합니다. 영어로 된 Pinyin 텍스트와 달리, 미리 훈련 된 중국 모델의 중국 입력 방법은 분명히 달라야합니다. Singularity Intelligence는 중국어 습관과 더 일치하는 중국어의 특성을 기반으로 고유 한 중국 인코딩 방법을 사용하며 모델 이해에 더 도움이되는 중국 사전을 재구성합니다.
—————————————————————————————————————-
推荐
transformers>=4.18.0
# -*- coding: utf-8 -*-
from transformers import GPT2LMHeadModel
from transformers import AutoTokenizer
from transformers import TextGenerationPipeline
# 以 SkyWork/SkyText(13billions) 为例,还有 SkyWork/SkyTextTiny(2.6billions) 可用, 期待使用
model = GPT2LMHeadModel . from_pretrained ( "SkyWork/SkyText" )
tokenizer = AutoTokenizer . from_pretrained ( "SkyWork/SkyText" , trust_remote_code = True )
text_generator = TextGenerationPipeline ( model , tokenizer , device = 0 )
input_str = "今天是个好天气"
max_new_tokens = 20
print ( text_generator ( input_str , max_new_tokens = max_new_tokens , do_sample = True )) MIT 라이센스