SkyText Chinese GPT3
1.0.0
SkyText ist ein von Singularity Zhiyuan vorgebildetes chinesisches GPT3-Big-Modell, das verschiedene Aufgaben wie Chat, Q & A und chinesisch-englische Übersetzung ausführen kann. Neben der Implementierung grundlegender Chat, Dialogs, Fragen und Antworten kann dieses Modell auch chinesische und englische Übersetzungen, Inhaltsdauer, Kopplets, Schreiben alter Gedichte, Generieren von Rezepten, Reposts Dritter, Erstellen von Interviewfragen und anderen Funktionen unterstützen.

Einhundertvier Milliarden Parametermodell [vorübergehend geschlossen die Quelle, ein neues zehn Milliarden Parametermodell wird in Kürze veröffentlicht. Bleiben Sie also dran! 】 Https://huggingface.co/skywork/SkyText
Drei Milliarden Parametermodell https://huggingface.co/skywork/SkyTextTiny
Erfahrung und Testversion, bitte besuchen Sie die intelligente API -Versuch von Singularity Intelligent
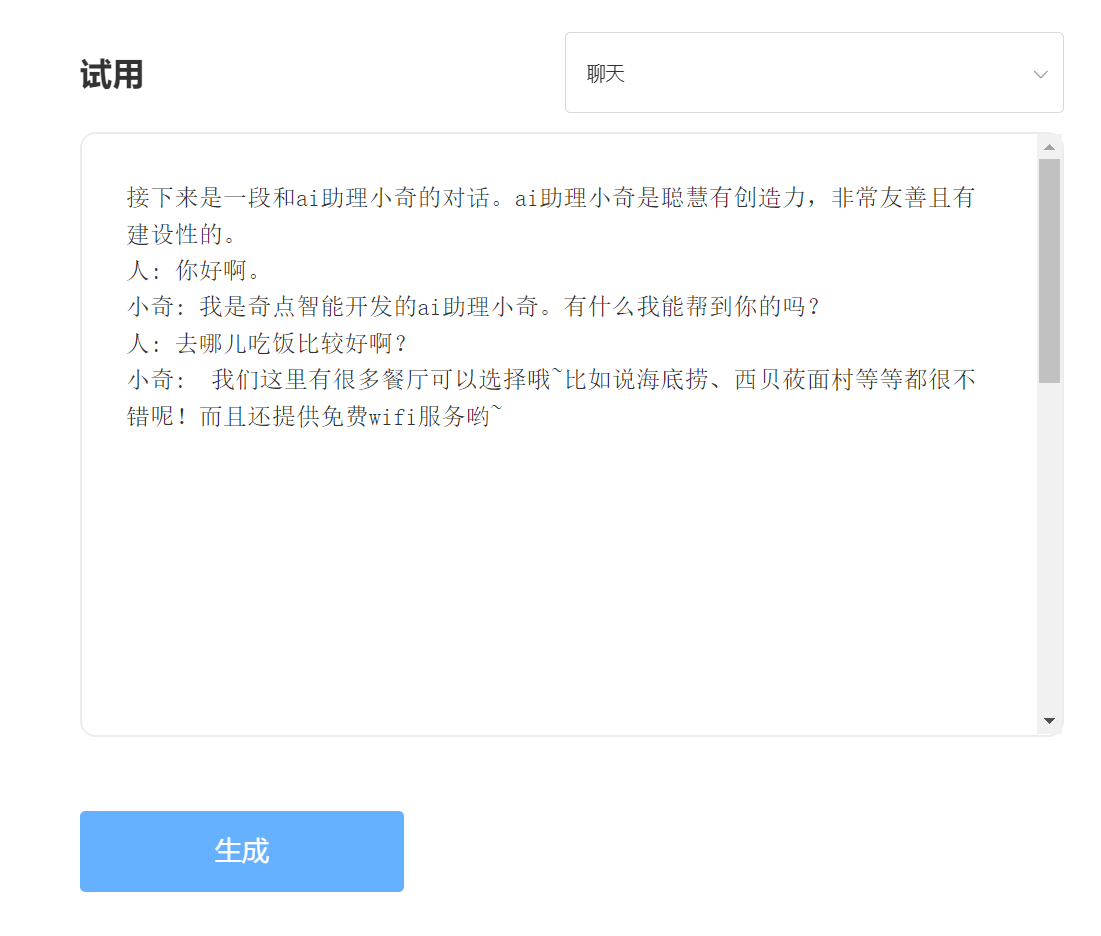
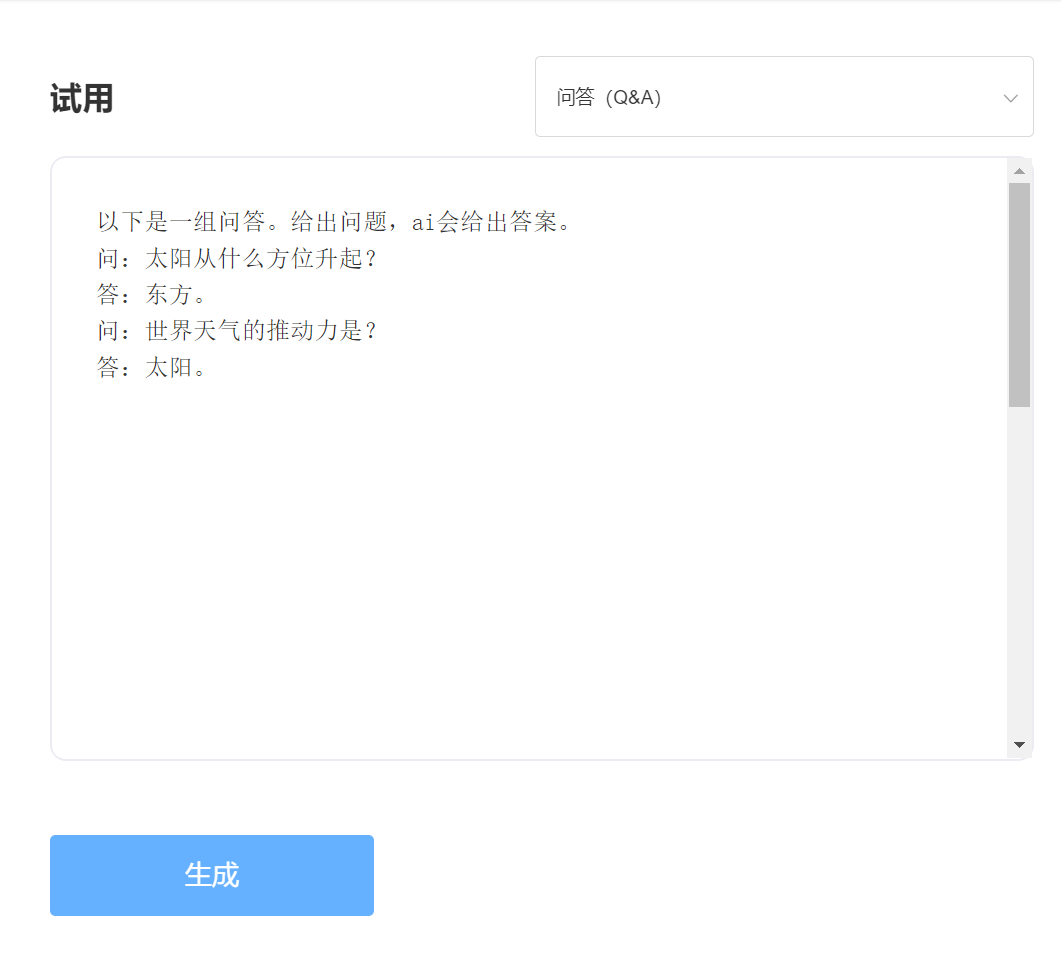
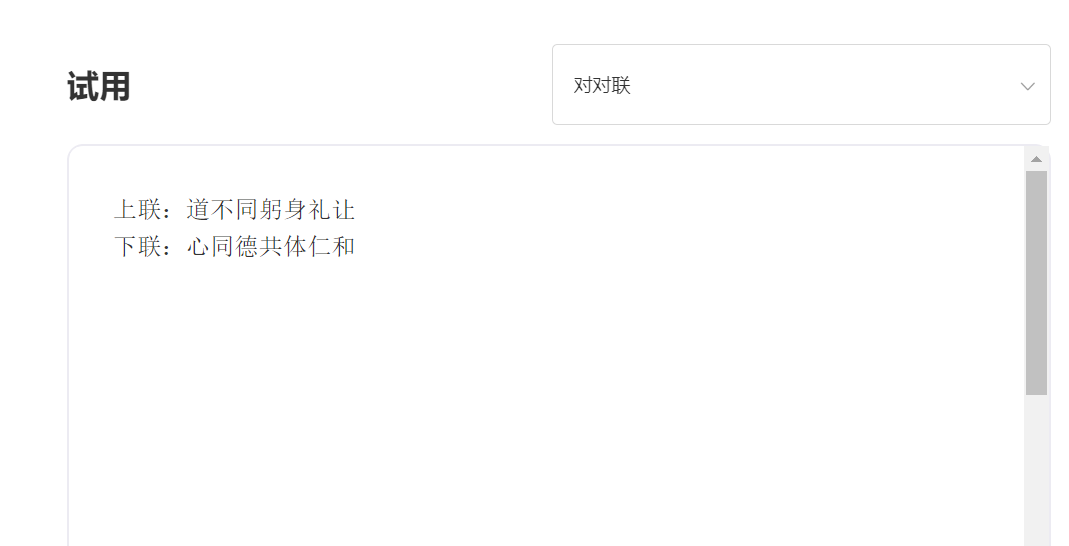
eingeben: 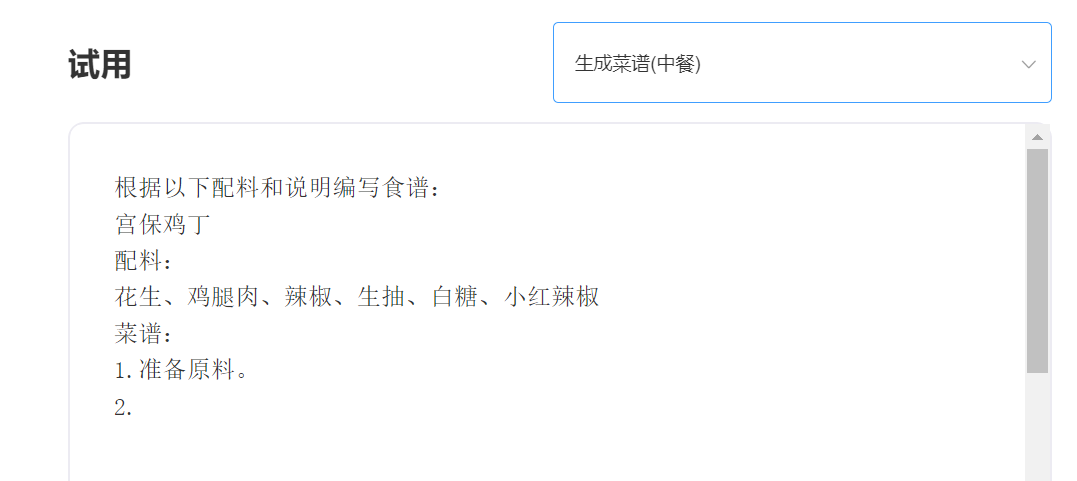
Ausgabe: 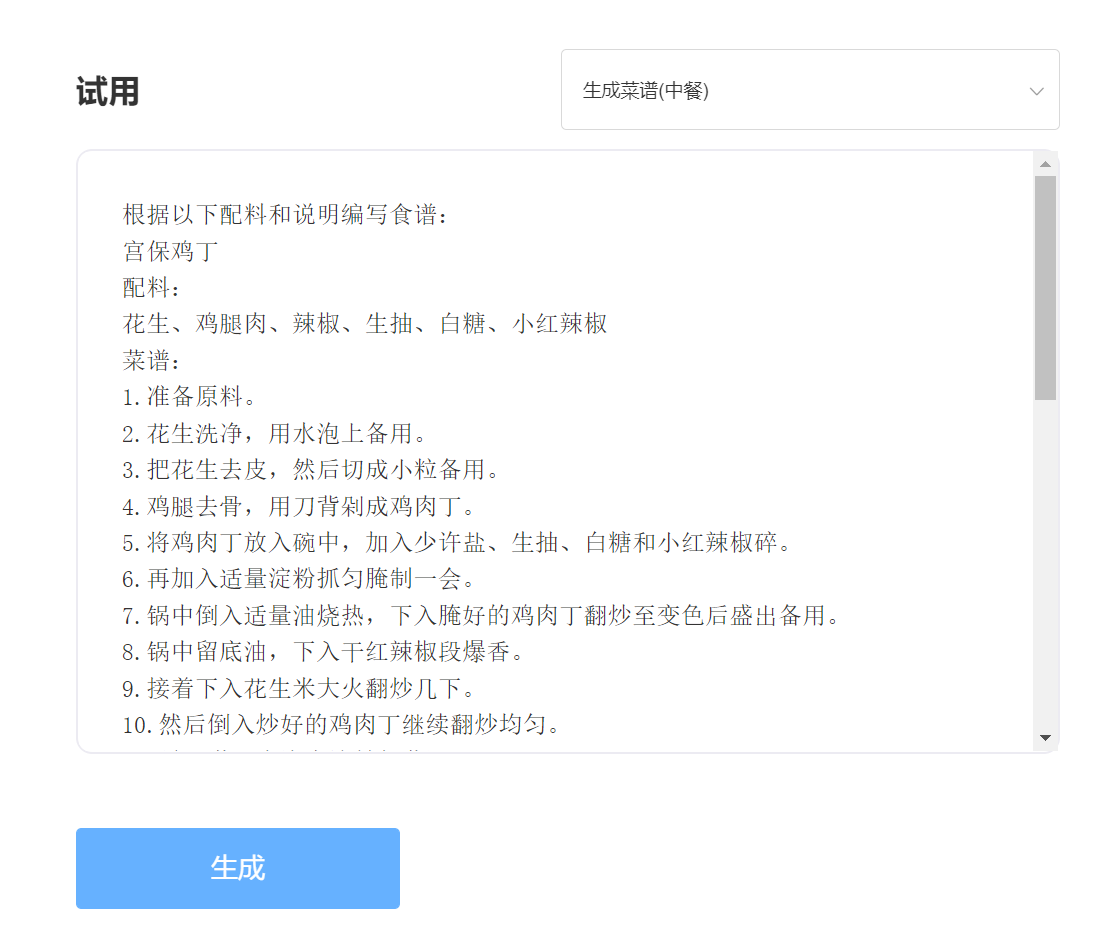
Technischer Vorteil 1: Datenreinigung mit mehr als 30 Prozessen
Mit der Entwicklung der NLP-Technologie sind vorgeschriebene große Modelle nach und nach zu einer der Kerntechnologien der künstlichen Intelligenz geworden. Vorausgebildete große Modelle erfordern normalerweise einen massiven Text, und Online-Text wird natürlich zur wichtigsten Quelle für Korpus. Die Qualität des Trainingskorpus beeinflusst zweifellos direkt die Wirksamkeit des Modells. Um ein Modell mit hervorragenden Funktionen zu trainieren, verwendete Singularity Intelligence mehr als 30 Reinigungsprozesse beim Reinigen von Daten. Die exquisiten Details haben hervorragende Modelleffekte erzeugt.
Technischer Vorteil 2: Chinesische Codierungsmethoden, die Chinesisch optimieren und innovieren
Auf dem Gebiet der großen Modelle vor dem Training wurde es immer von der englischen Gemeinschaft dominiert, und die Bedeutung von Big-Modelle vor dem Training in Chinesisch ist selbstverständlich. Im Gegensatz zum Pinyin-Text in englischer Sprache sollte die chinesische Eingangsmethode von vorgeborenen chinesischen Modellen offensichtlich unterschiedlich sein. Singularity Intelligence verwendet einzigartige chinesische Codierungsmethoden, die auf den Eigenschaften der chinesischen Sprache basieren, was eher mit chinesischen Sprachgewohnheiten entspricht und ein chinesisches Wörterbuch rekonstruiert, das für das Modellverständnis förderlicher ist.
—————————————————————————————————————————————————————
推荐
transformers>=4.18.0
# -*- coding: utf-8 -*-
from transformers import GPT2LMHeadModel
from transformers import AutoTokenizer
from transformers import TextGenerationPipeline
# 以 SkyWork/SkyText(13billions) 为例,还有 SkyWork/SkyTextTiny(2.6billions) 可用, 期待使用
model = GPT2LMHeadModel . from_pretrained ( "SkyWork/SkyText" )
tokenizer = AutoTokenizer . from_pretrained ( "SkyWork/SkyText" , trust_remote_code = True )
text_generator = TextGenerationPipeline ( model , tokenizer , device = 0 )
input_str = "今天是个好天气"
max_new_tokens = 20
print ( text_generator ( input_str , max_new_tokens = max_new_tokens , do_sample = True )) MIT -Lizenz