SkyText Chinese GPT3
1.0.0
SkyText هو نموذج كبير من GPT3 الذي تم تدريبه مسبقًا من تأليف Singularity Zhiyuan ، والذي يمكنه أداء مهام مختلفة مثل الدردشة والأسئلة والأجوبة والترجمة الصينية-الإنجليزية. بالإضافة إلى تنفيذ الدردشة الأساسية والحوار والأسئلة والأجوبة ، يمكن لهذا النموذج أيضًا أن يدعم الترجمة الصينية والإنجليزية ، واستمرار المحتوى ، والاقتران ، وكتابة القصائد القديمة ، وتوليد الوصفات ، وإعادة نشر الشخص الثالث ، وإنشاء أسئلة المقابلة وغيرها من الوظائف.

مائة وأربعة مليارات نموذج معلمة [أغلق المصدر مؤقتًا ، سيتم إصدار نموذج جديد لعشرة مليارات من المعلمات ، لذا ترقبوا! 】 https://huggingface.co/skywork/skytext
نموذج معلمة ثلاثة مليارات https://huggingface.co/skywork/skytexttiny
الخبرة والمحاكمة ، يرجى زيارة تجربة API الذكية المفرد
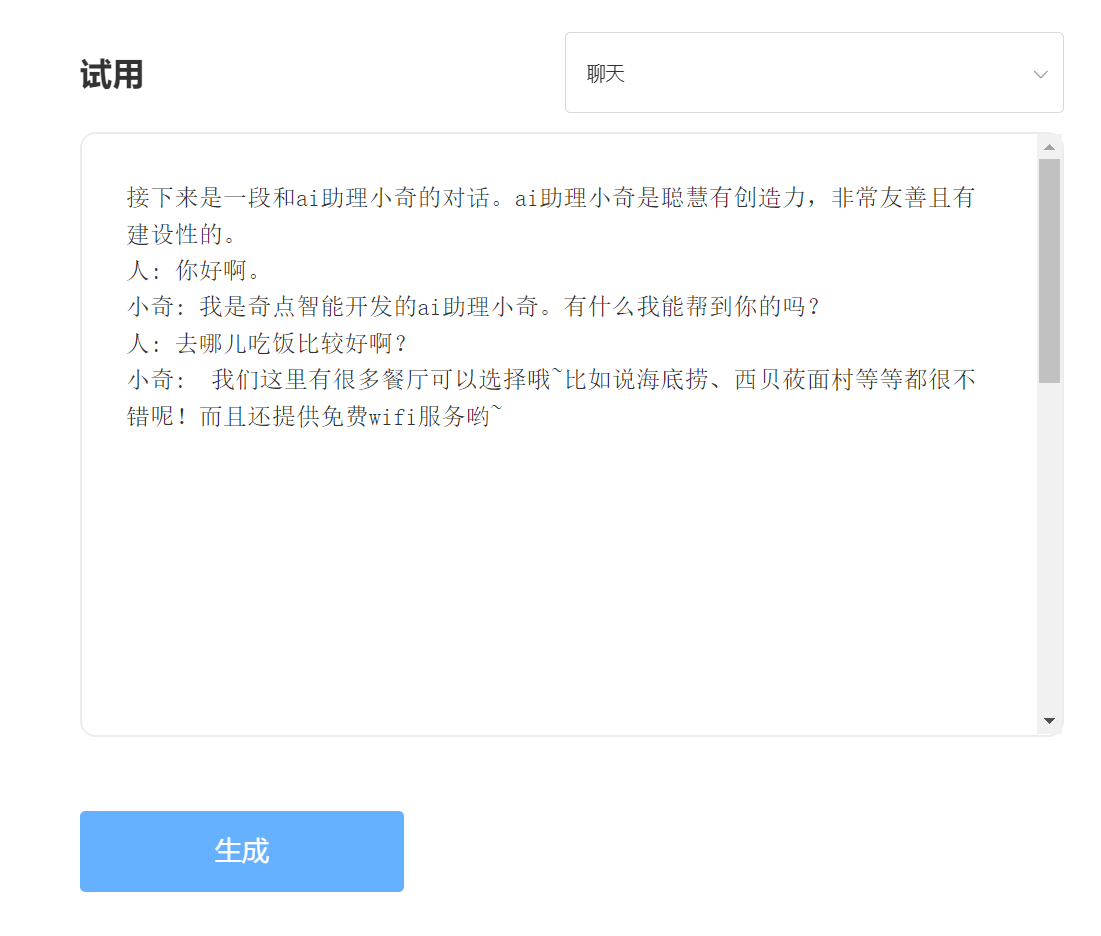
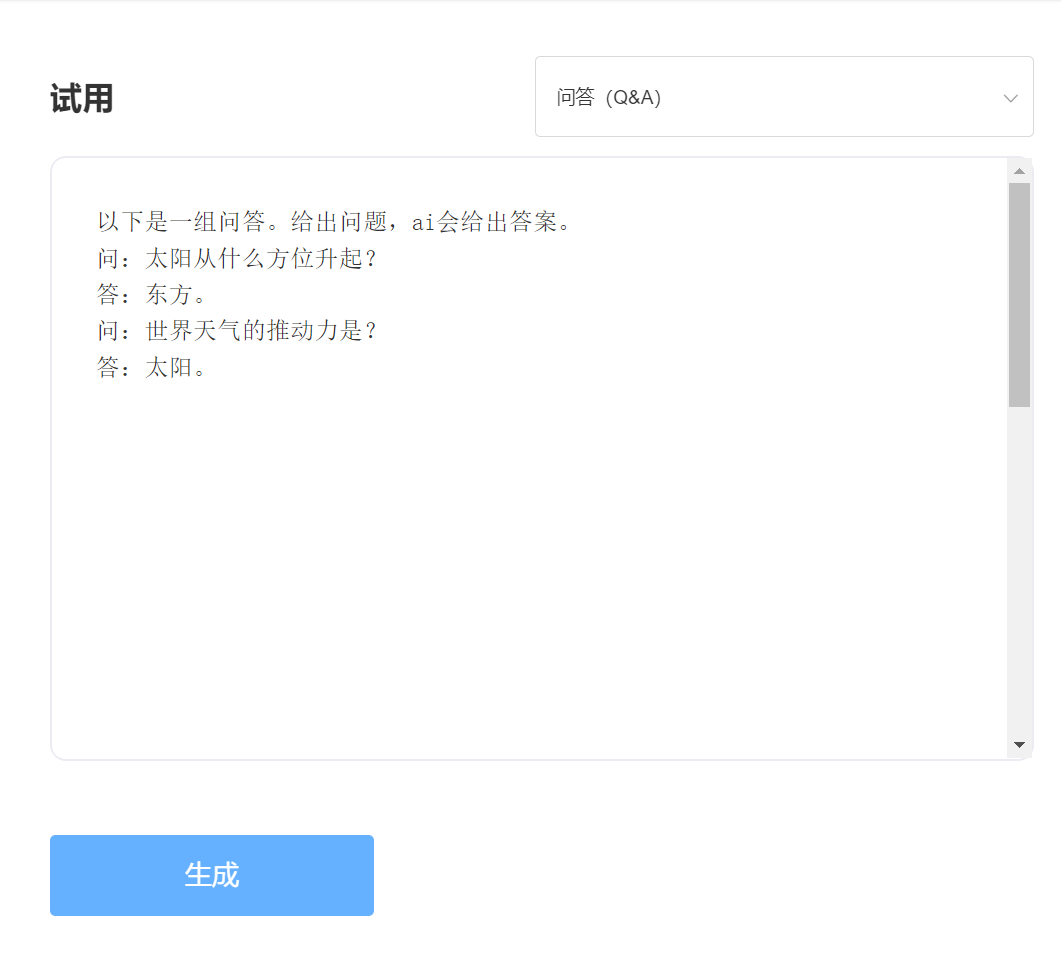
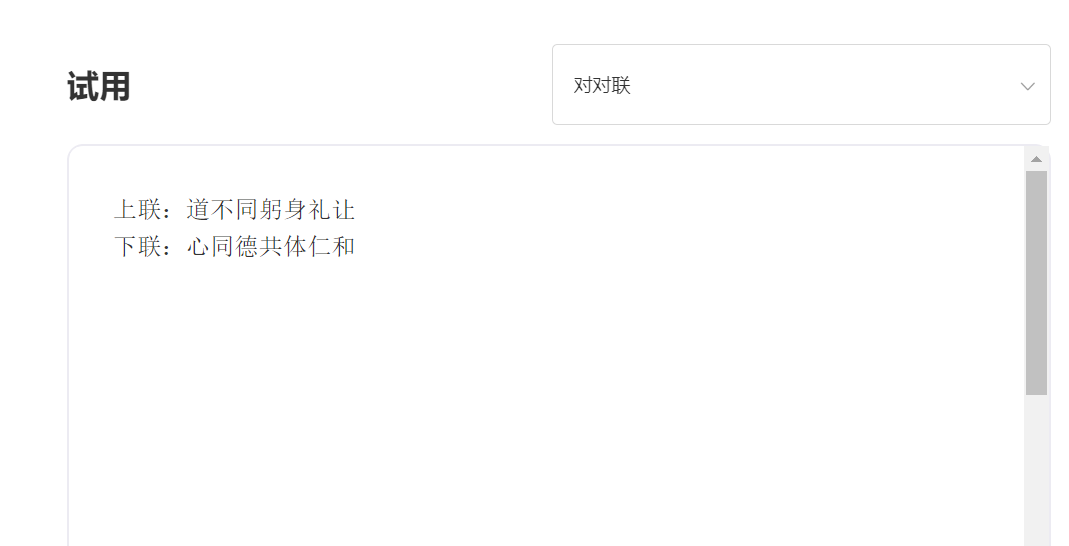
يدخل: 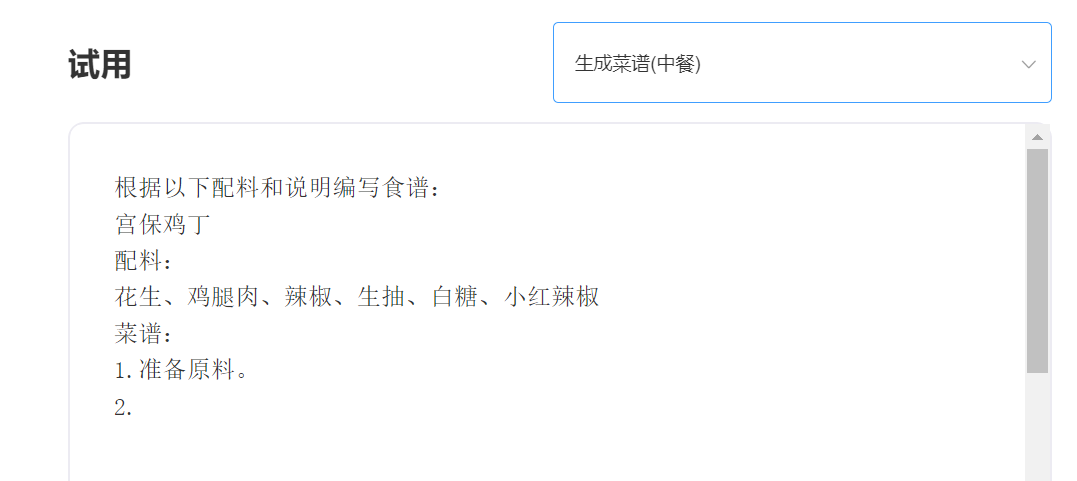
الإخراج: 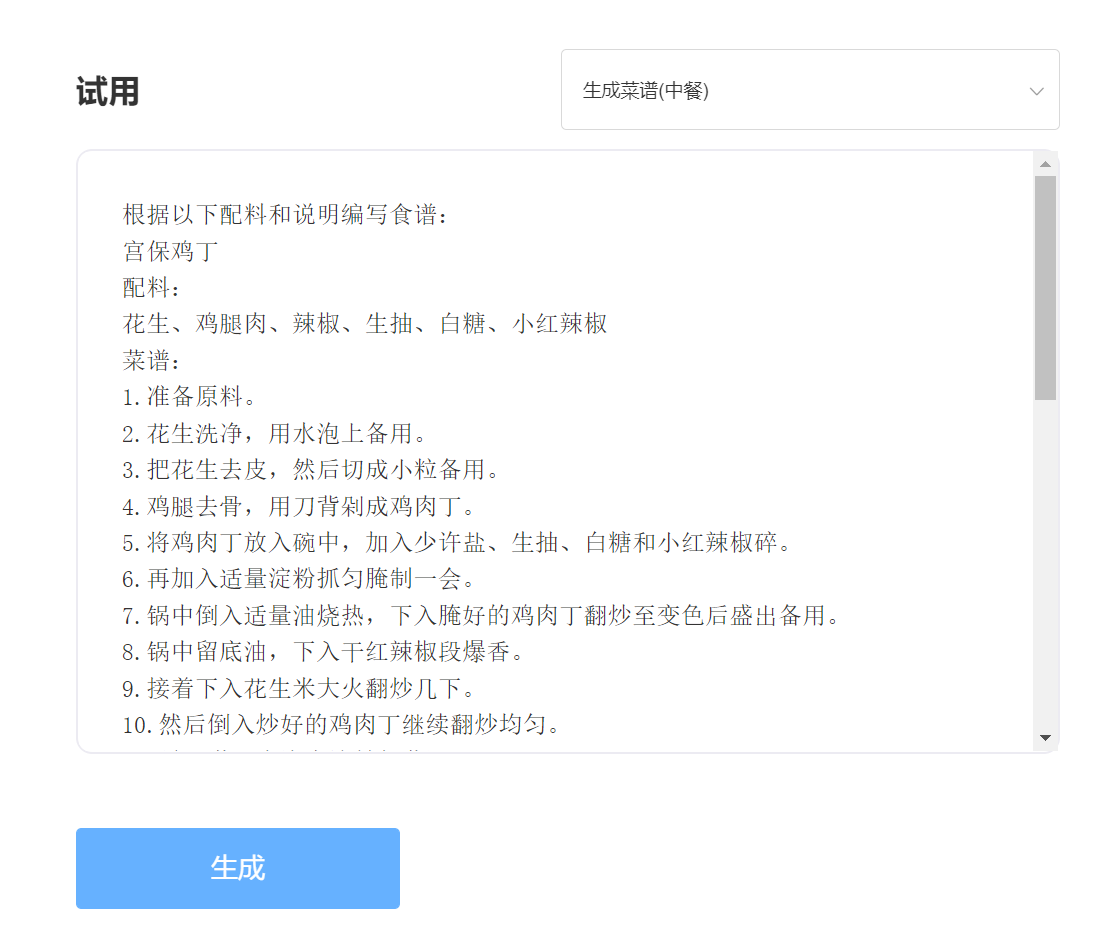
الميزة الفنية 1: تنظيف البيانات بأكثر من 30 عملية
مع تطوير تقنية NLP ، أصبحت النماذج الكبيرة المدربة مسبقًا واحدة من التقنيات الأساسية للذكاء الاصطناعي. عادة ما تتطلب النماذج الكبيرة المدربة مسبقًا أن يتم تدريب نص ضخم ، ويصبح النص عبر الإنترنت بشكل طبيعي هو مصدر الجسم الأكثر أهمية. لا شك أن جودة مجموعة التدريب تؤثر بشكل مباشر على فعالية النموذج. من أجل تدريب نموذج ذي قدرات متميزة ، استخدمت الذكاء المفرد أكثر من 30 عملية تنظيف عند تنظيف البيانات. التفاصيل الرائعة خلقت تأثيرات نموذج ممتازة.
الميزة الفنية 2: طرق الترميز الصينية التي تعمل على تحسين وابتكار الصينية
في مجال النماذج الكبيرة قبل التدريب ، كان يهيمن عليه المجتمع الإنجليزي دائمًا ، وأهمية النماذج الكبيرة قبل التدريب باللغة الصينية هي بديهية. على عكس نص Pinyin باللغة الإنجليزية ، من الواضح أن طريقة الإدخال الصينية للنماذج الصينية التي تم تدريبها مسبقًا مختلفة. يستخدم الذكاء التفرد أساليب ترميز صينية فريدة من نوعها تستند إلى خصائص اللغة الصينية ، والتي تتماشى أكثر مع عادات اللغة الصينية ويعيد بناء قاموس صيني أكثر ملاءمة لفهم النماذج.
————————————————————————————————————————————————————————–
推荐
transformers>=4.18.0
# -*- coding: utf-8 -*-
from transformers import GPT2LMHeadModel
from transformers import AutoTokenizer
from transformers import TextGenerationPipeline
# 以 SkyWork/SkyText(13billions) 为例,还有 SkyWork/SkyTextTiny(2.6billions) 可用, 期待使用
model = GPT2LMHeadModel . from_pretrained ( "SkyWork/SkyText" )
tokenizer = AutoTokenizer . from_pretrained ( "SkyWork/SkyText" , trust_remote_code = True )
text_generator = TextGenerationPipeline ( model , tokenizer , device = 0 )
input_str = "今天是个好天气"
max_new_tokens = 20
print ( text_generator ( input_str , max_new_tokens = max_new_tokens , do_sample = True )) رخصة معهد ماساتشوستس للتكنولوجيا