SkyText Chinese GPT3
1.0.0
SkyText adalah model besar pra-terlatih GPT3 Cina yang dirilis oleh Singularity Zhiyuan, yang dapat melakukan tugas yang berbeda seperti obrolan, Q&A, dan terjemahan Cina-Inggris. Selain menerapkan obrolan dasar, dialog, pertanyaan dan jawaban, model ini juga dapat mendukung terjemahan bahasa Mandarin dan Inggris, kelanjutan konten, bait, menulis puisi kuno, menghasilkan resep, repost orang ketiga, membuat pertanyaan wawancara dan fungsi lainnya.

Model parameter seratus empat miliar [untuk sementara menutup sumber, model parameter sepuluh miliar baru akan segera dirilis, jadi tetaplah disini! 】 Https://huggingface.co/skywork/skytext
Tiga miliar model parameter https://huggingface.co/skywork/skytexttiny
Pengalaman dan Pengadilan, silakan kunjungi Singularity Intelligent API Trial
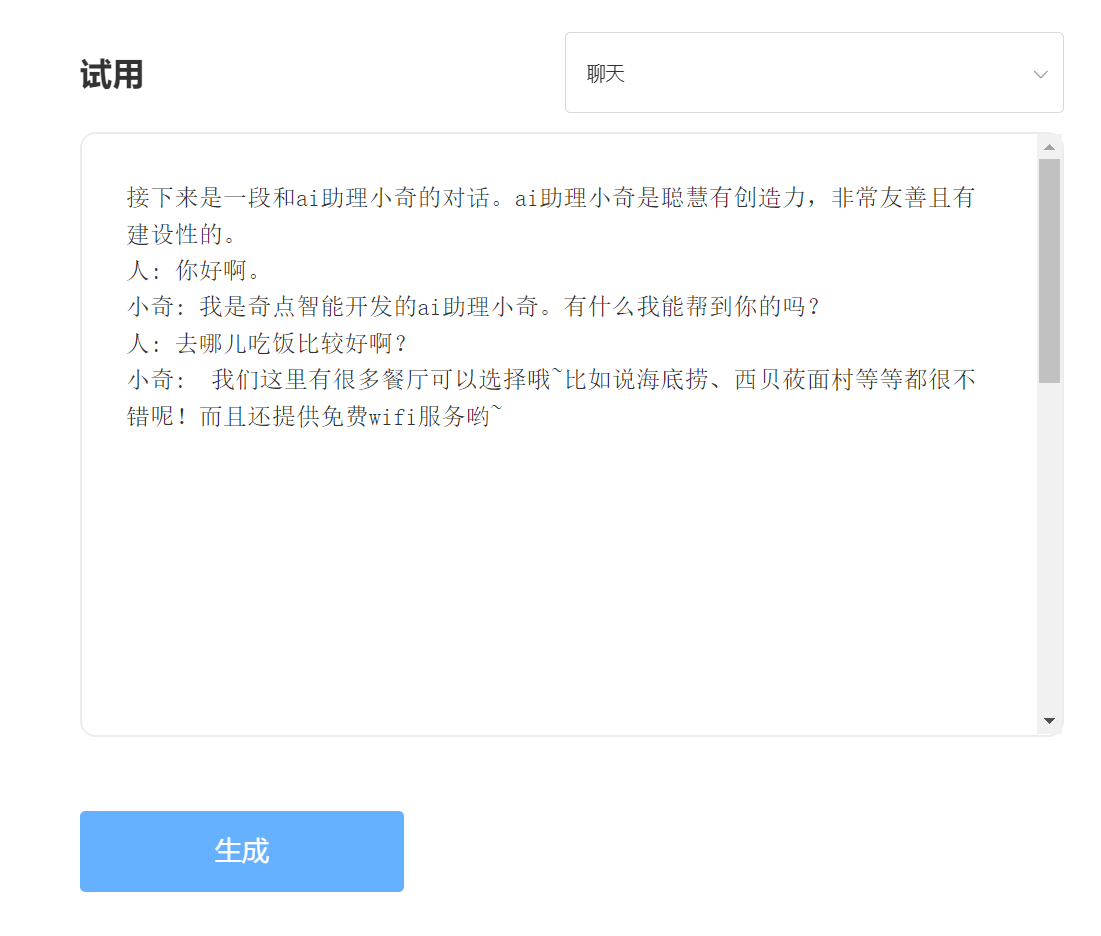
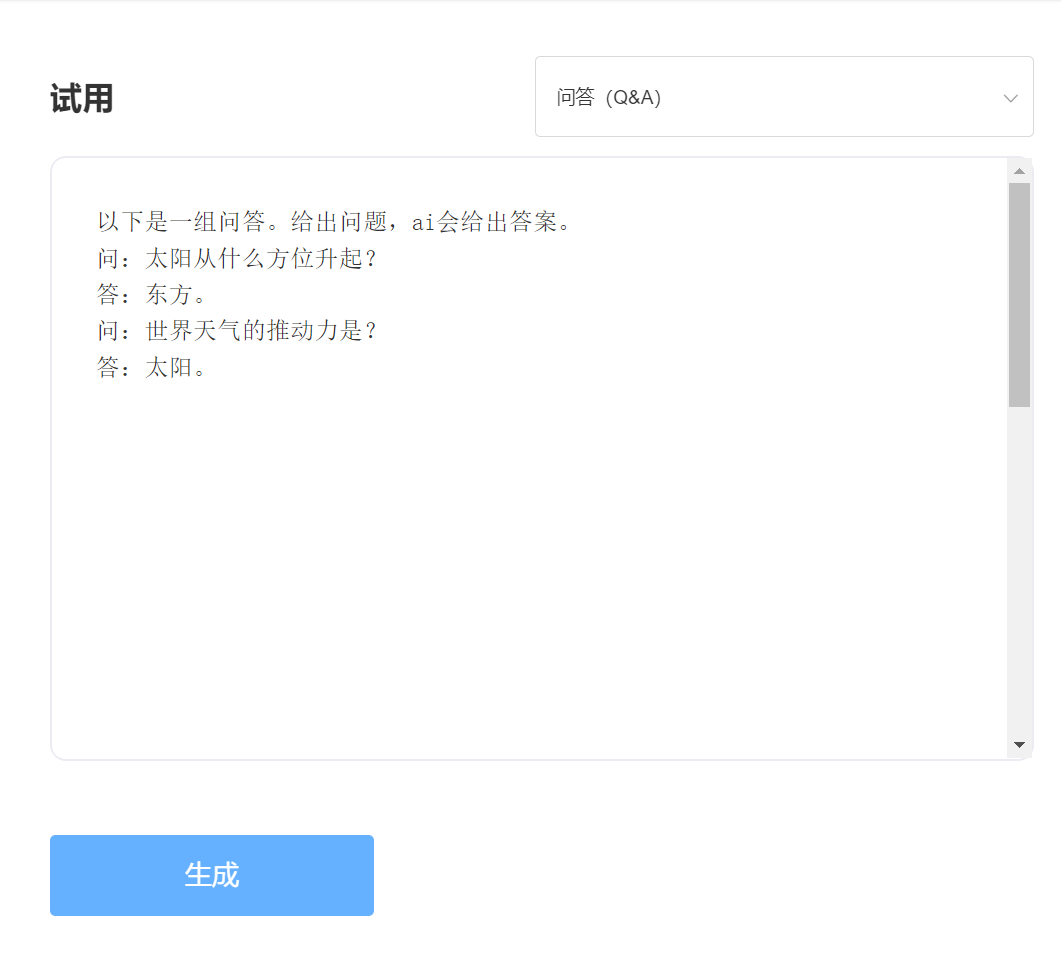
memasuki: 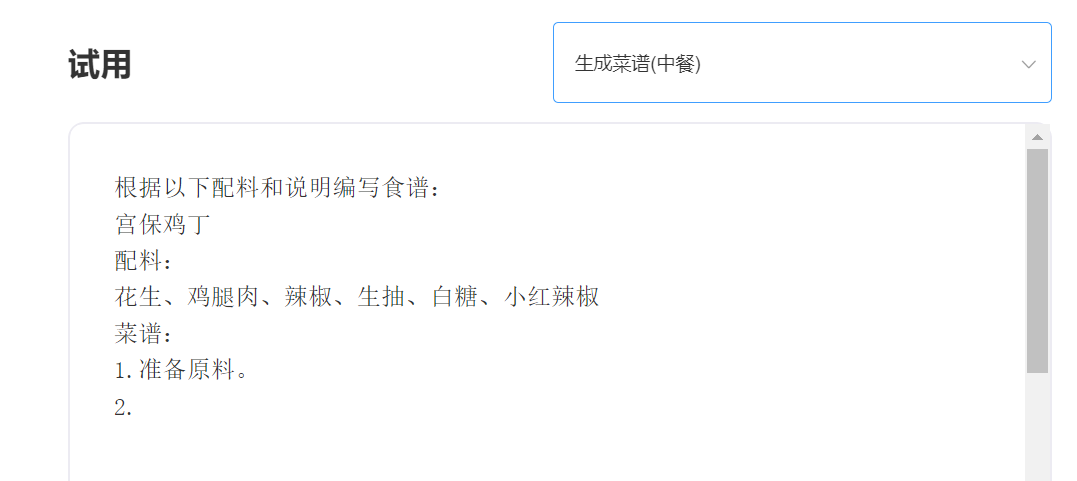
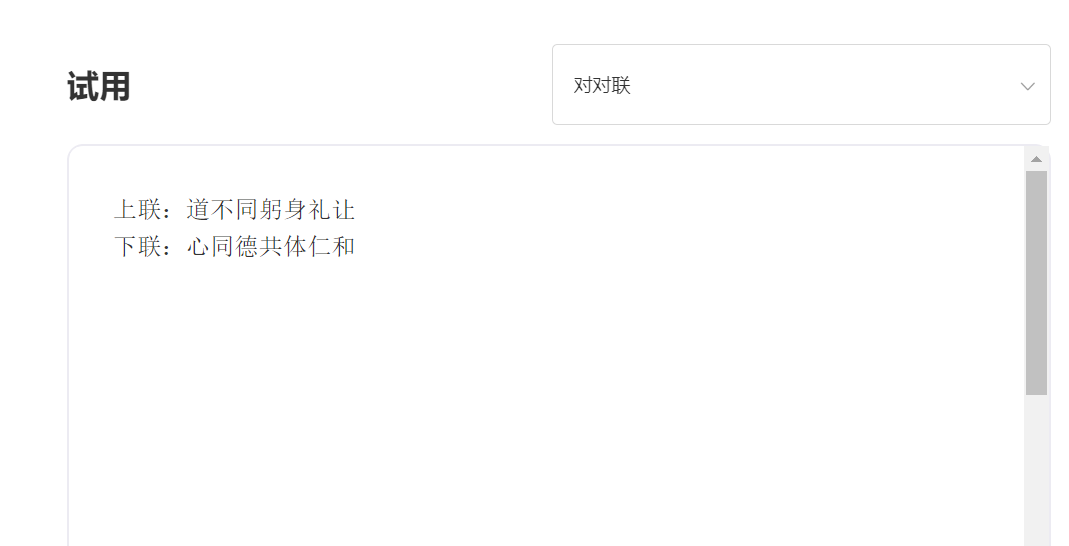
Keluaran: 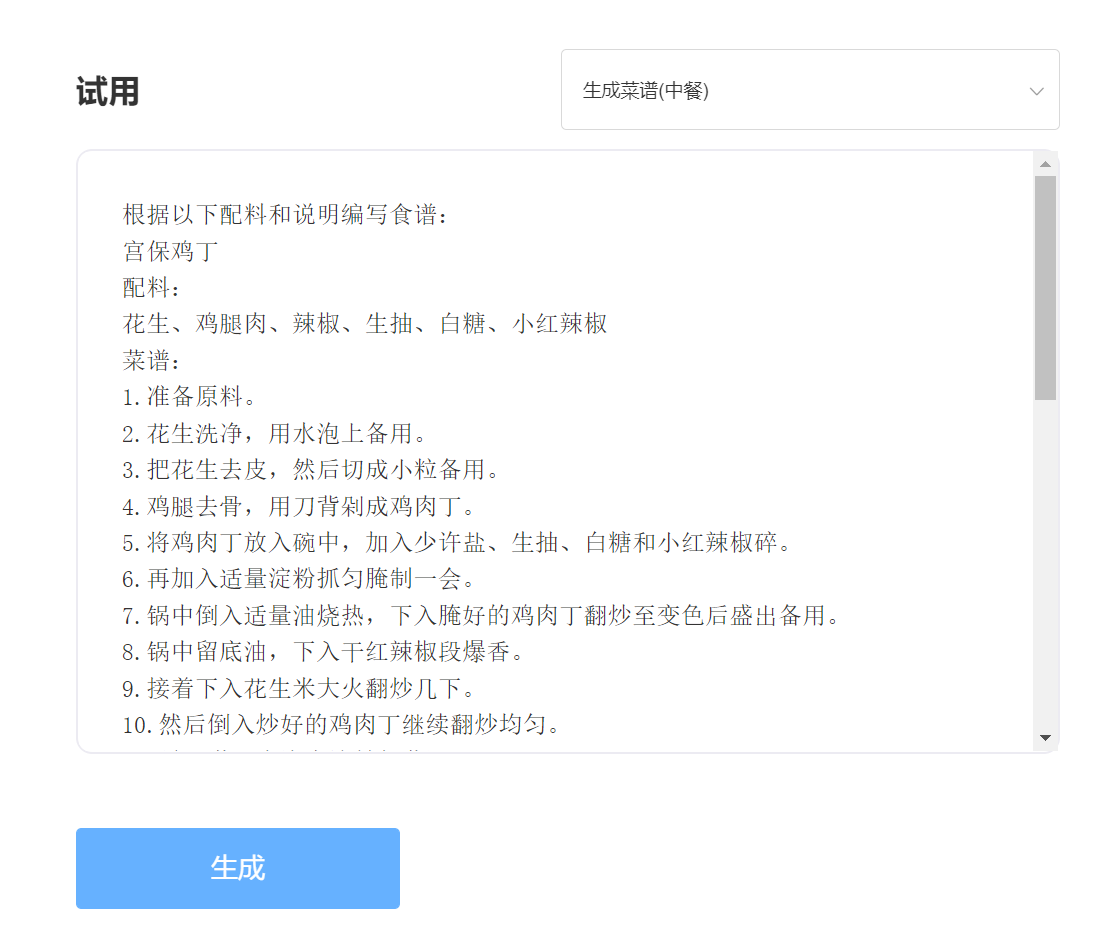
Keuntungan Teknis 1: Pembersihan Data dengan lebih dari 30 proses
Dengan pengembangan teknologi NLP, model-model besar yang terlatih secara bertahap telah menjadi salah satu teknologi inti kecerdasan buatan. Model besar yang sudah terlatih biasanya membutuhkan teks besar untuk dilatih, dan teks online secara alami menjadi sumber korpus terpenting. Kualitas corpus pelatihan tidak diragukan lagi secara langsung mempengaruhi efektivitas model. Untuk melatih model dengan kemampuan luar biasa, intelijen singularitas menggunakan lebih dari 30 proses pembersihan saat membersihkan data. Detail yang sangat indah telah menciptakan efek model yang sangat baik.
Keuntungan Teknis 2: Metode Pengkodean Cina yang mengoptimalkan dan berinovasi Cina
Di bidang model besar pra-pelatihan, itu selalu didominasi oleh komunitas Inggris, dan pentingnya model-model besar pra-pelatihan dalam bahasa Cina terbukti dengan sendirinya. Berbeda dengan teks pinyin dalam bahasa Inggris, metode input Cina dari model Cina yang sudah terlatih jelas harus berbeda. Singularity Intelligence menggunakan metode pengkodean Cina yang unik berdasarkan karakteristik bahasa Cina, yang lebih sesuai dengan kebiasaan bahasa Cina dan merekonstruksi kamus Cina yang lebih kondusif untuk memodelkan pemahaman.
———————————————————————————————-
推荐
transformers>=4.18.0
# -*- coding: utf-8 -*-
from transformers import GPT2LMHeadModel
from transformers import AutoTokenizer
from transformers import TextGenerationPipeline
# 以 SkyWork/SkyText(13billions) 为例,还有 SkyWork/SkyTextTiny(2.6billions) 可用, 期待使用
model = GPT2LMHeadModel . from_pretrained ( "SkyWork/SkyText" )
tokenizer = AutoTokenizer . from_pretrained ( "SkyWork/SkyText" , trust_remote_code = True )
text_generator = TextGenerationPipeline ( model , tokenizer , device = 0 )
input_str = "今天是个好天气"
max_new_tokens = 20
print ( text_generator ( input_str , max_new_tokens = max_new_tokens , do_sample = True )) Lisensi MIT