SkyText Chinese GPT3
1.0.0
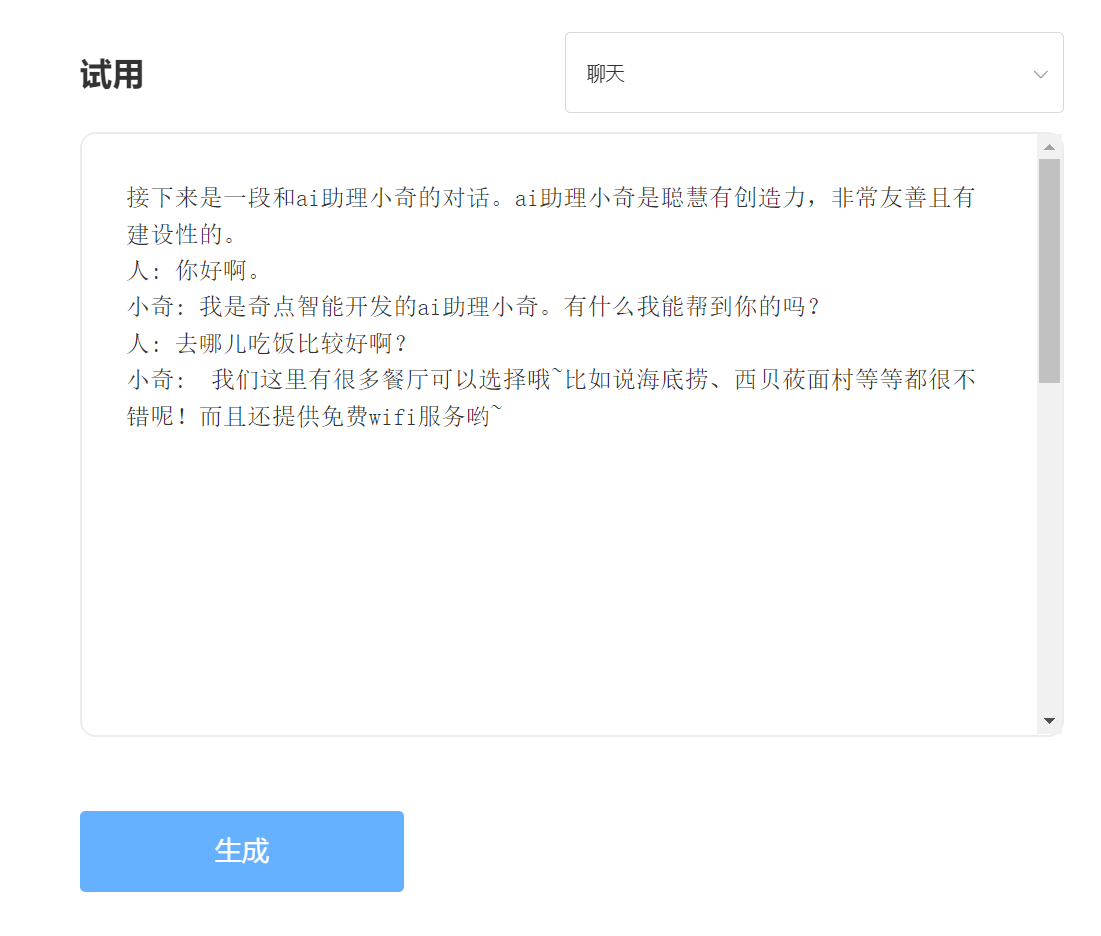
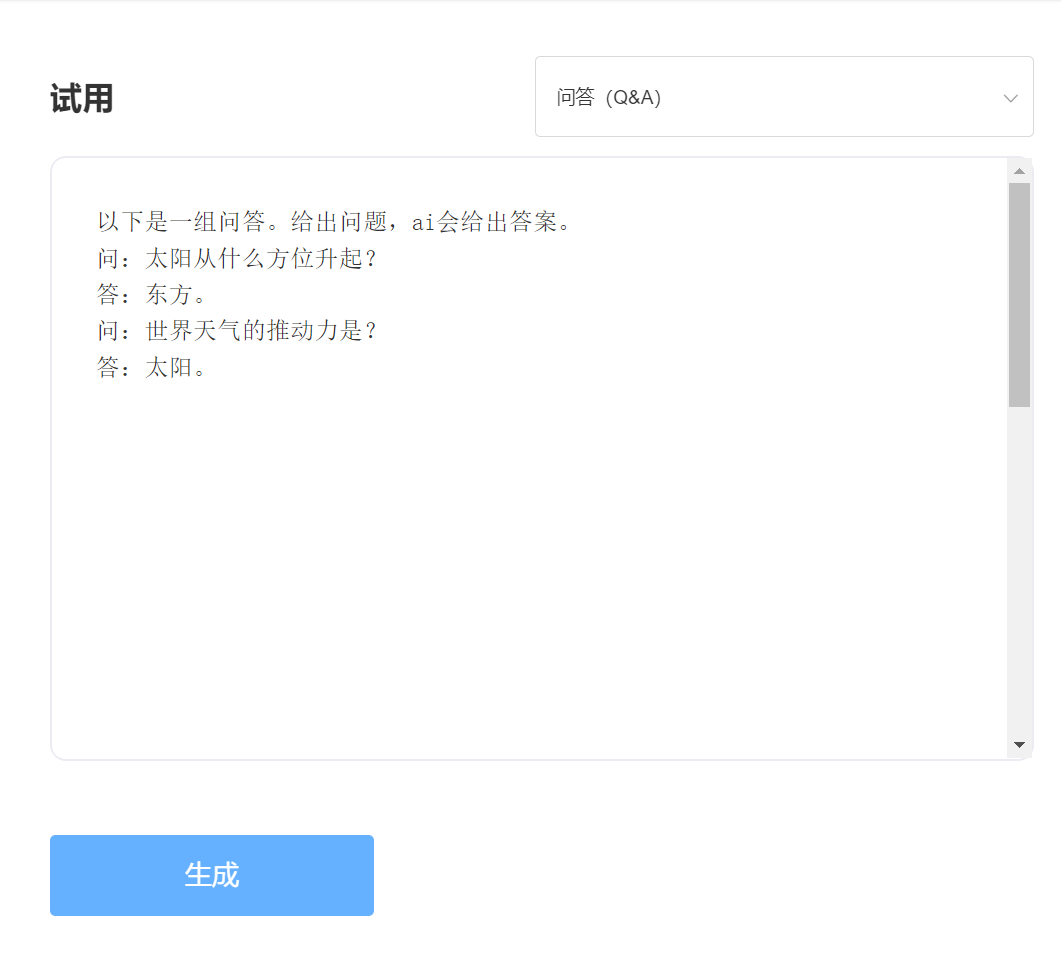
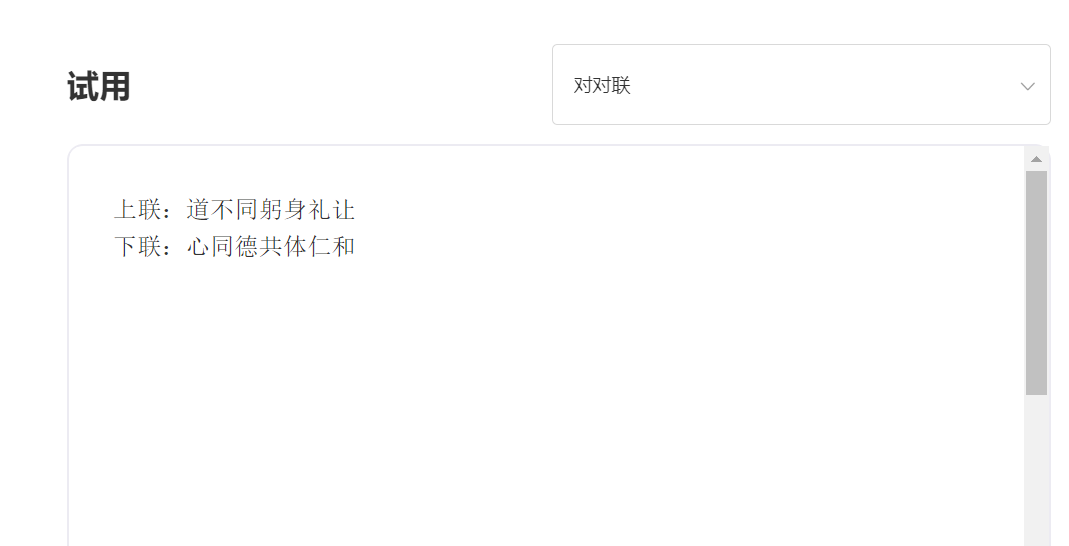
A SkyText é um grande modelo chinês GPT3, lançado pela Singularity Zhiyuan, que pode executar tarefas diferentes, como bate-papo, perguntas e respostas e tradução chinesa-inglês. Além de implementar bate-papo básico, diálogo, perguntas e respostas, esse modelo também pode suportar tradução em chinês e inglês, continuação de conteúdo, dísticos, escrever poemas antigos, geração de receitas, repostos de terceira pessoa, criar perguntas de entrevista e outras funções.

Cento e quatro bilhões de parâmetros modelo [Fechou temporariamente a fonte, um novo modelo de parâmetros de dez bilhões será lançado em breve, então fique atento! 】 Https://huggingface.co/skywork/skytext
Três bilhões de parâmetros modelo https://huggingface.co/skywork/skytexttiny
Experiência e julgamento, visite o estudo Singularity Intelligent API
digitar: 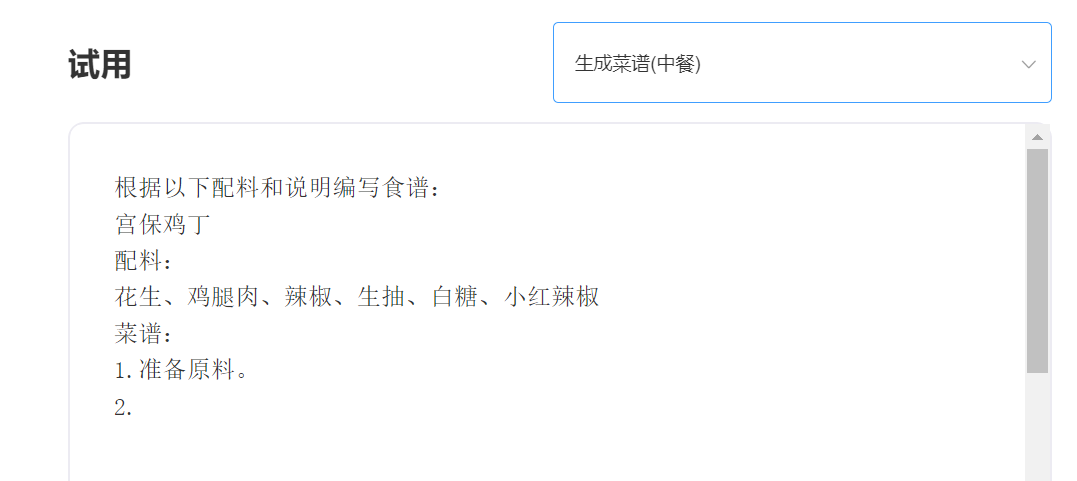
Saída: 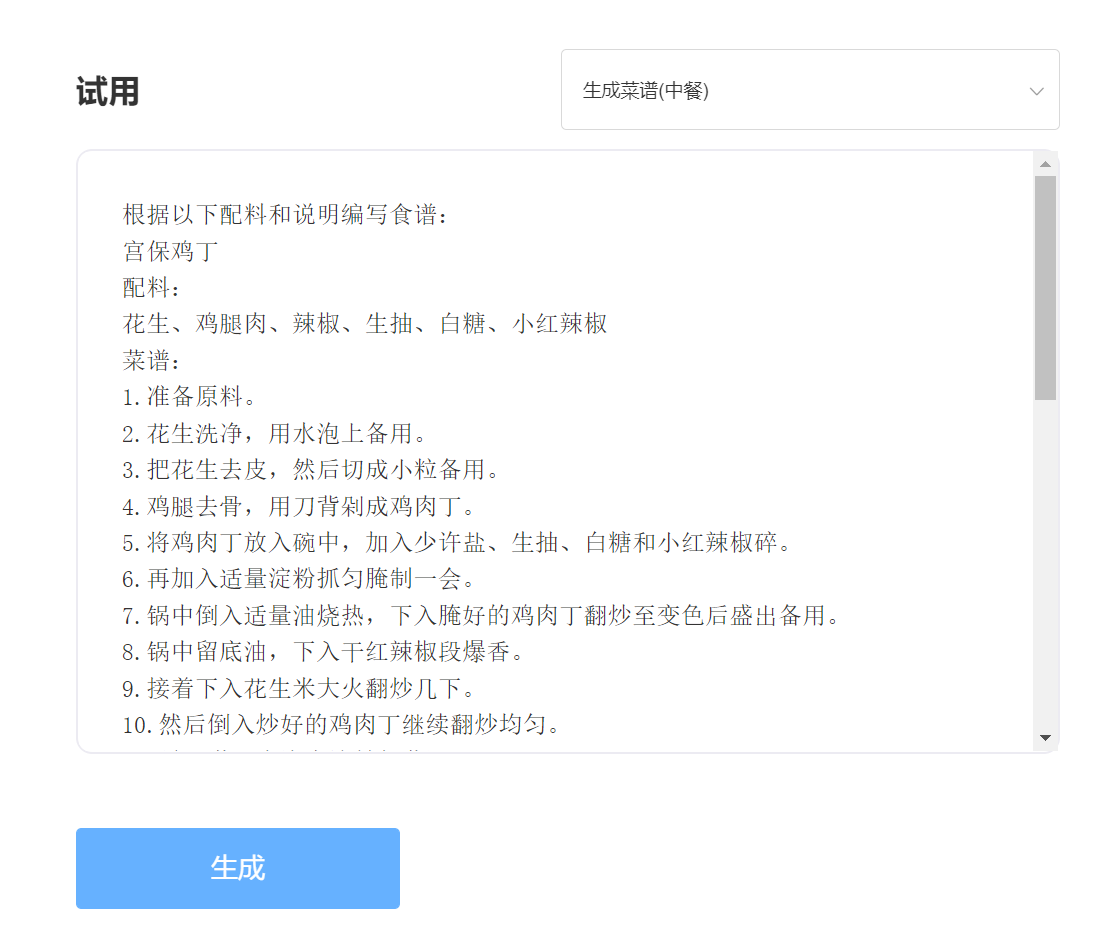
Vantagem técnica 1: Limpeza de dados com mais de 30 processos
Com o desenvolvimento da tecnologia PNL, os grandes modelos pré-treinados se tornaram gradualmente uma das principais tecnologias de inteligência artificial. Modelos grandes pré-treinados geralmente exigem um texto maciço a ser treinado, e o texto on-line naturalmente se torna a fonte mais importante de corpus. A qualidade do corpus de treinamento, sem dúvida, afeta diretamente a eficácia do modelo. Para treinar um modelo com recursos excelentes, a Singularity Intelligence usou mais de 30 processos de limpeza ao limpar os dados. Os detalhes requintados criaram excelentes efeitos de modelo.
Vantagem Técnica 2: Métodos de codificação chinesa que otimizam e inovam chinês
No campo dos grandes modelos de pré-treinamento, sempre foi dominado pela comunidade inglesa, e a importância de o pré-treinamento de grandes modelos em chinês é evidente. Ao contrário do texto pinyin em inglês, o método de entrada chinês de modelos chineses pré-treinados deve ser obviamente diferente. A inteligência de singularidade utiliza métodos exclusivos de codificação chinesa com base nas características da língua chinesa, que estão mais alinhadas com os hábitos da língua chinesa e reconstrói um dicionário chinês que é mais propício para modelar a compreensão.
—————————————————————————————————
推荐
transformers>=4.18.0
# -*- coding: utf-8 -*-
from transformers import GPT2LMHeadModel
from transformers import AutoTokenizer
from transformers import TextGenerationPipeline
# 以 SkyWork/SkyText(13billions) 为例,还有 SkyWork/SkyTextTiny(2.6billions) 可用, 期待使用
model = GPT2LMHeadModel . from_pretrained ( "SkyWork/SkyText" )
tokenizer = AutoTokenizer . from_pretrained ( "SkyWork/SkyText" , trust_remote_code = True )
text_generator = TextGenerationPipeline ( model , tokenizer , device = 0 )
input_str = "今天是个好天气"
max_new_tokens = 20
print ( text_generator ( input_str , max_new_tokens = max_new_tokens , do_sample = True )) MIT Licença