SkyText Chinese GPT3
1.0.0
SkyText is a Chinese GPT3 pre-trained big model released by Singularity Zhiyuan, which can perform different tasks such as chat, Q&A, and Chinese-English translation. In addition to implementing basic chat, dialogue, questions and answers, this model can also support Chinese and English translation, content continuation, couplets, writing ancient poems, generating recipes, third-person reposts, creating interview questions and other functions.

One hundred and four billion parameter model [Temporarily closed the source, a new ten billion parameter model will be released soon, so stay tuned! 】 https://huggingface.co/SkyWork/SkyText
Three billion parameter model https://huggingface.co/SkyWork/SkyTextTiny
Experience and trial, please visit the Singularity Intelligent API trial
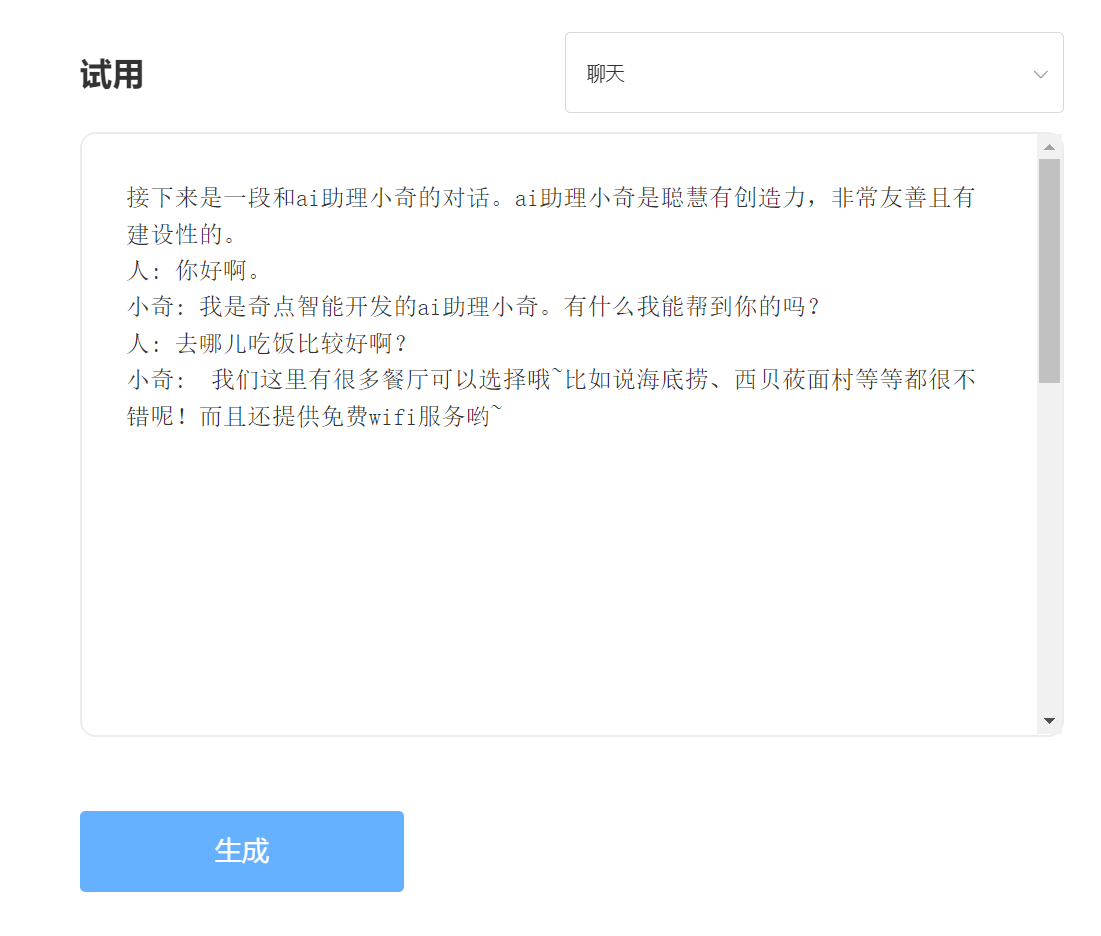
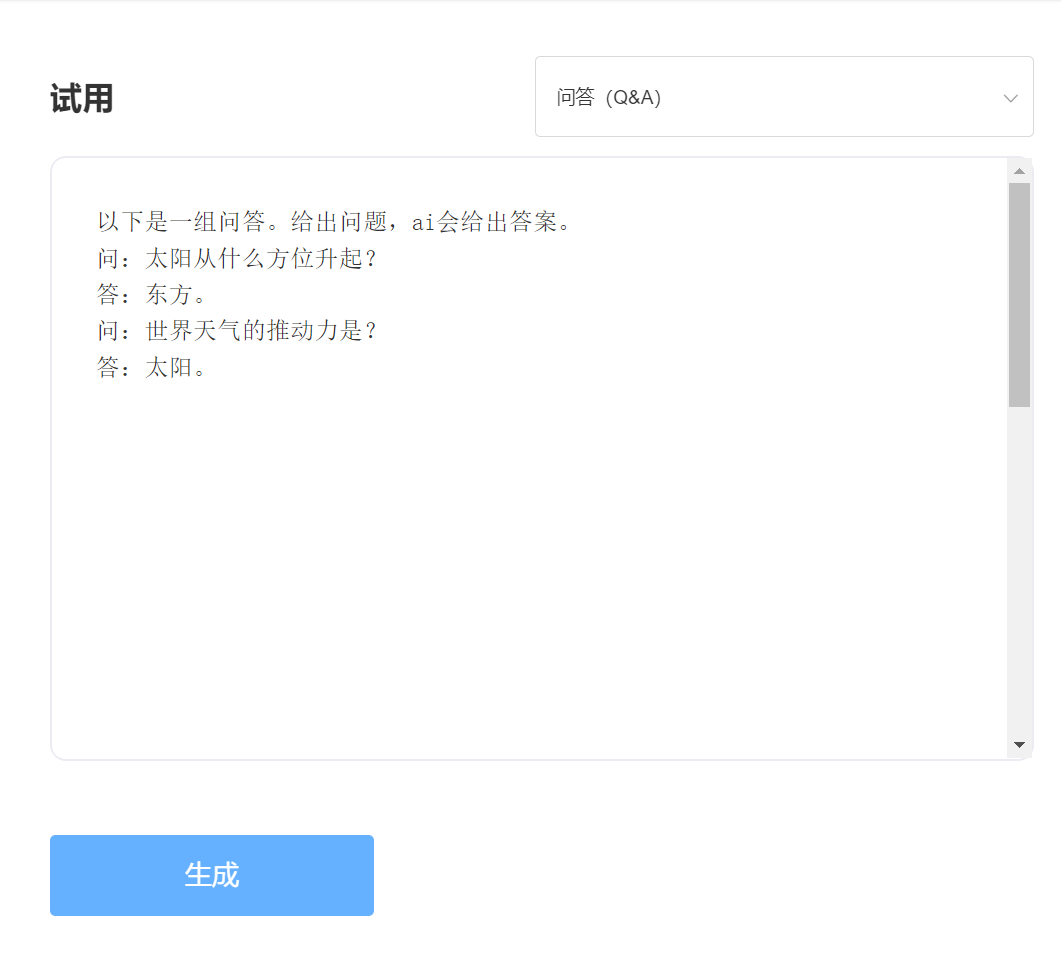
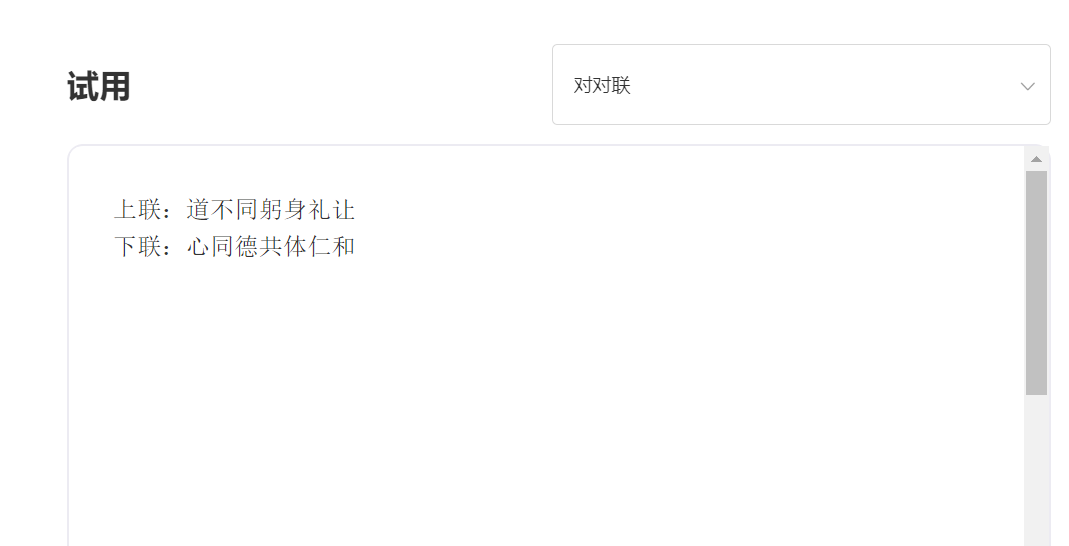
enter: 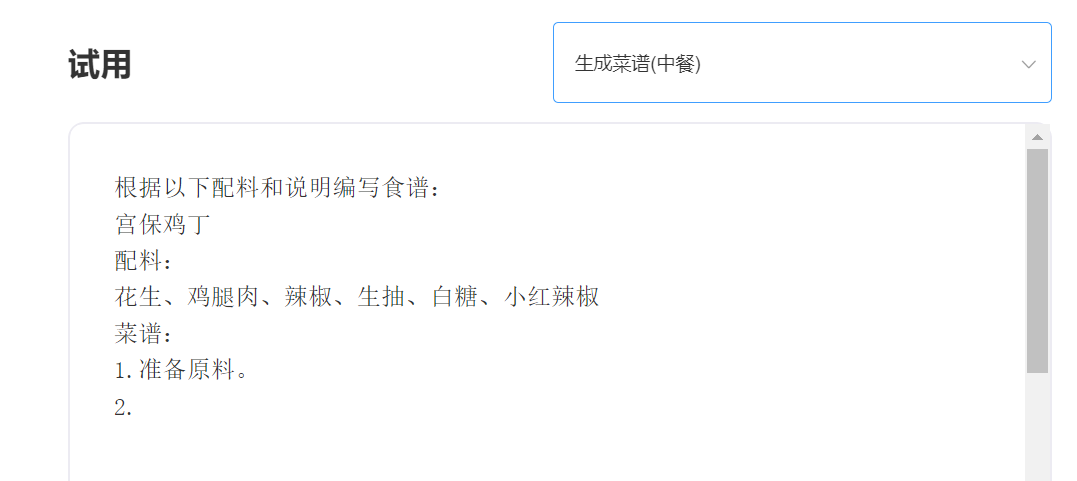
Output: 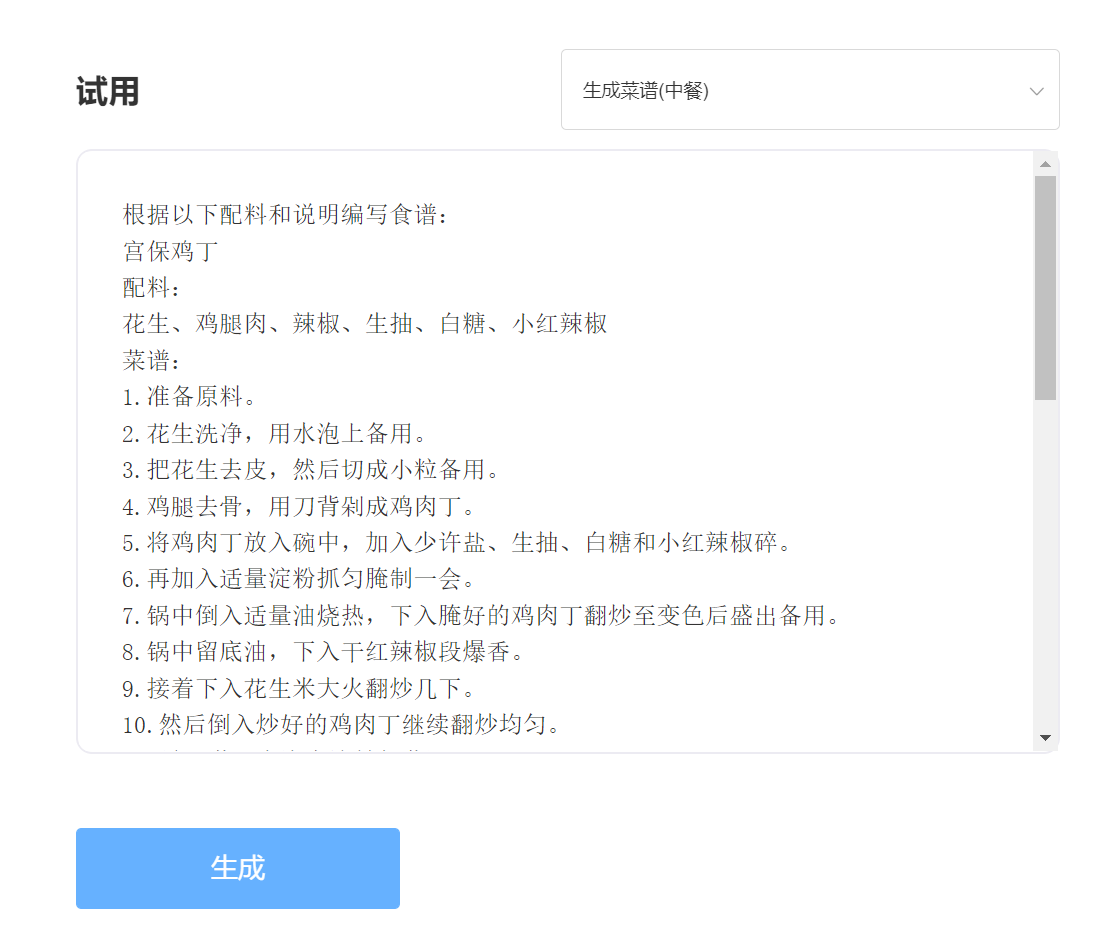
Technical Advantage 1: Data Cleaning with More than 30 Processes
With the development of NLP technology, pre-trained large models have gradually become one of the core technologies of artificial intelligence. Pre-trained large models usually require massive text to be trained, and online text naturally becomes the most important source of corpus. The quality of the training corpus undoubtedly directly affects the effectiveness of the model. In order to train a model with outstanding capabilities, Singularity Intelligence used more than 30 cleaning processes when cleaning data. The exquisite details have created excellent model effects.
Technical Advantage 2: Chinese coding methods that optimize and innovate Chinese
In the field of pre-training big models, it has always been dominated by the English community, and the importance of pre-training big models in Chinese is self-evident. Unlike the pinyin text in English, the Chinese input method of pre-trained Chinese models should obviously be different. Singularity Intelligence uses unique Chinese encoding methods based on the characteristics of Chinese language, which is more in line with Chinese language habits and reconstructs a Chinese dictionary that is more conducive to model understanding.
———————————————————————————————
推荐
transformers>=4.18.0
# -*- coding: utf-8 -*-
from transformers import GPT2LMHeadModel
from transformers import AutoTokenizer
from transformers import TextGenerationPipeline
# 以 SkyWork/SkyText(13billions) 为例,还有 SkyWork/SkyTextTiny(2.6billions) 可用, 期待使用
model = GPT2LMHeadModel . from_pretrained ( "SkyWork/SkyText" )
tokenizer = AutoTokenizer . from_pretrained ( "SkyWork/SkyText" , trust_remote_code = True )
text_generator = TextGenerationPipeline ( model , tokenizer , device = 0 )
input_str = "今天是个好天气"
max_new_tokens = 20
print ( text_generator ( input_str , max_new_tokens = max_new_tokens , do_sample = True )) MIT License