SkyText Chinese GPT3
1.0.0
SkyTextは、Ching Zhiyuanによってリリースされた中国のGPT3事前訓練を受けたビッグモデルであり、チャット、Q&A、中国語と英語の翻訳などのさまざまなタスクを実行できます。 基本的なチャット、対話、質問、回答の実装に加えて、このモデルは中国と英語の翻訳、コンテンツの継続、カプレット、古代の詩の執筆、レシピの生成、サードパーソンのレポスト、インタビューの質問やその他の機能をサポートすることもできます。

1,000億パラメーターモデル[ソースを一時的に閉じて、新しい100億パラメーターモデルがまもなくリリースされるため、お楽しみに! https://huggingface.co/skywork/skytext
30億パラメーターモデルhttps://huggingface.co/skywork/skytexttiny
経験と試験、特異点インテリジェントAPIトライアルにアクセスしてください
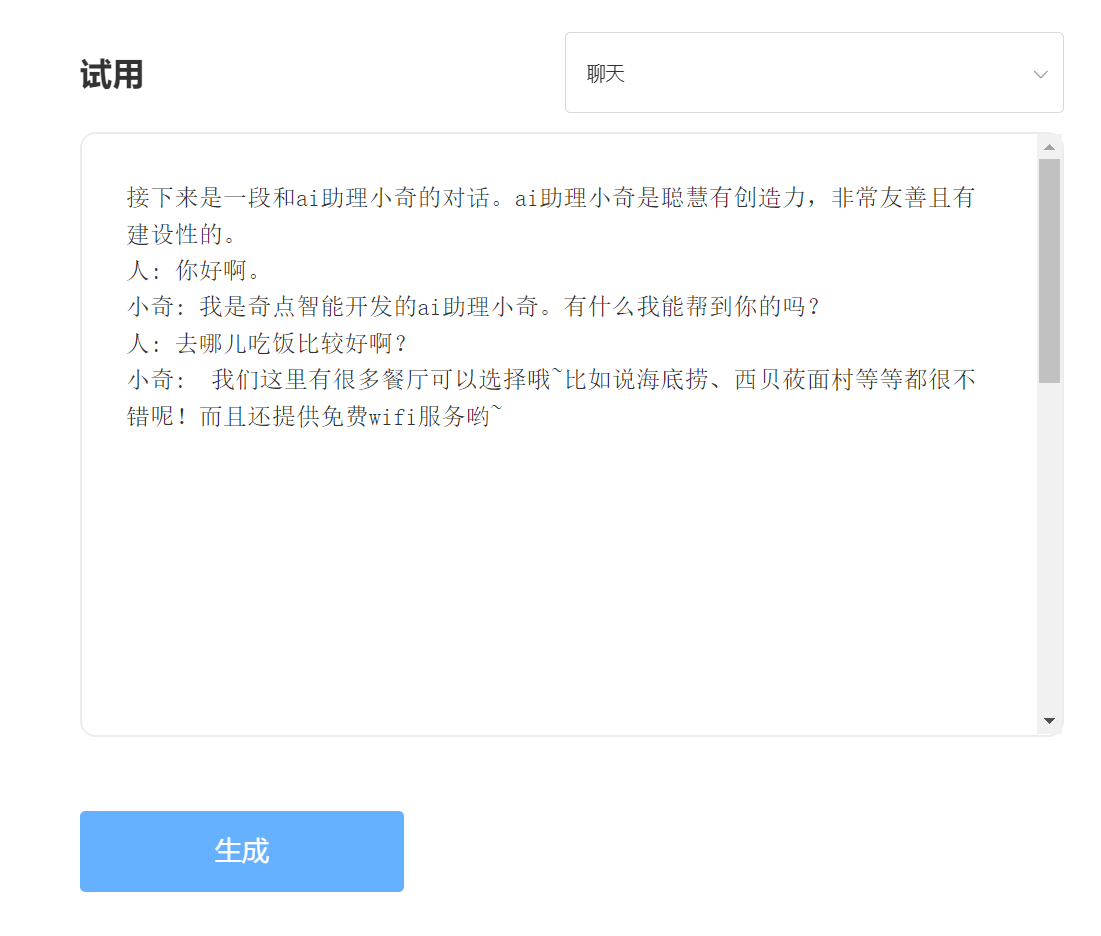
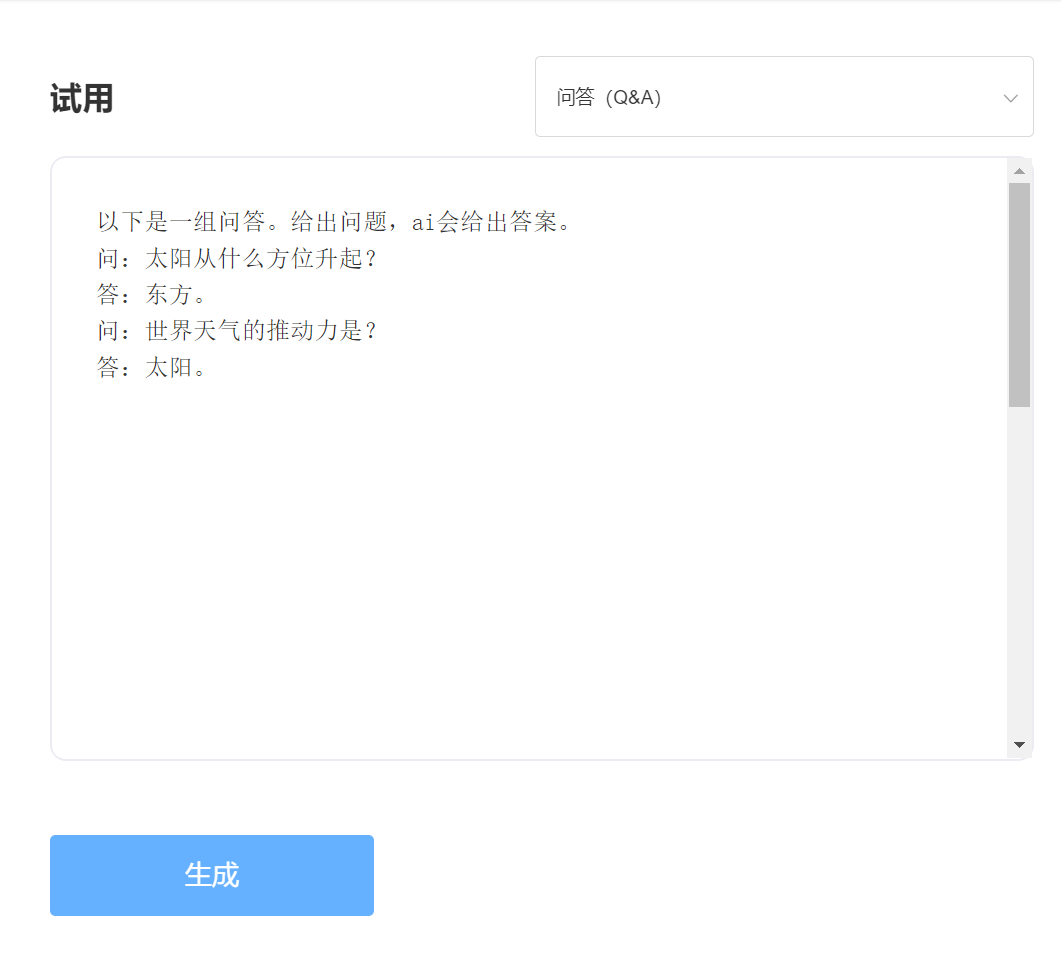
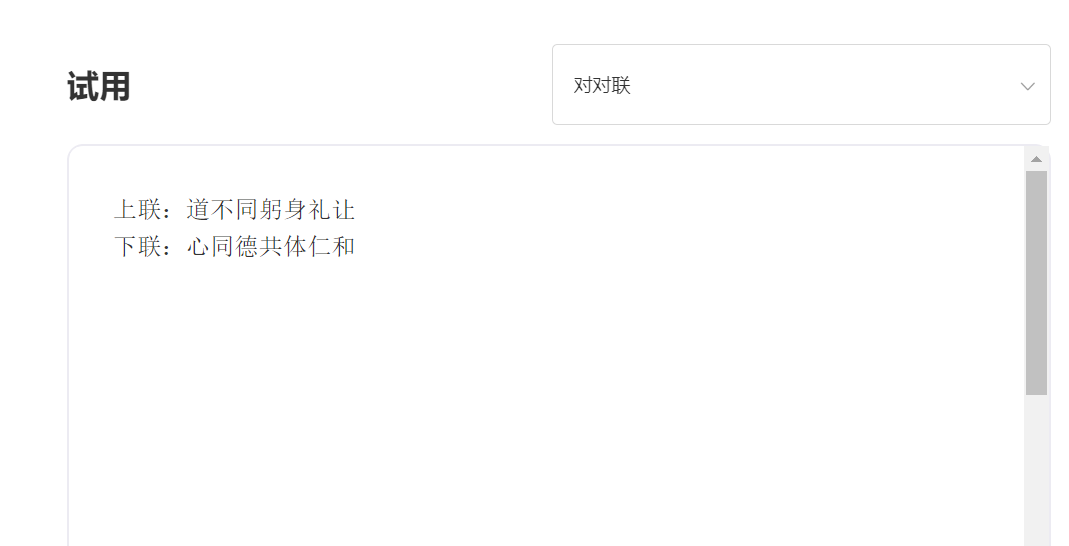
入力: 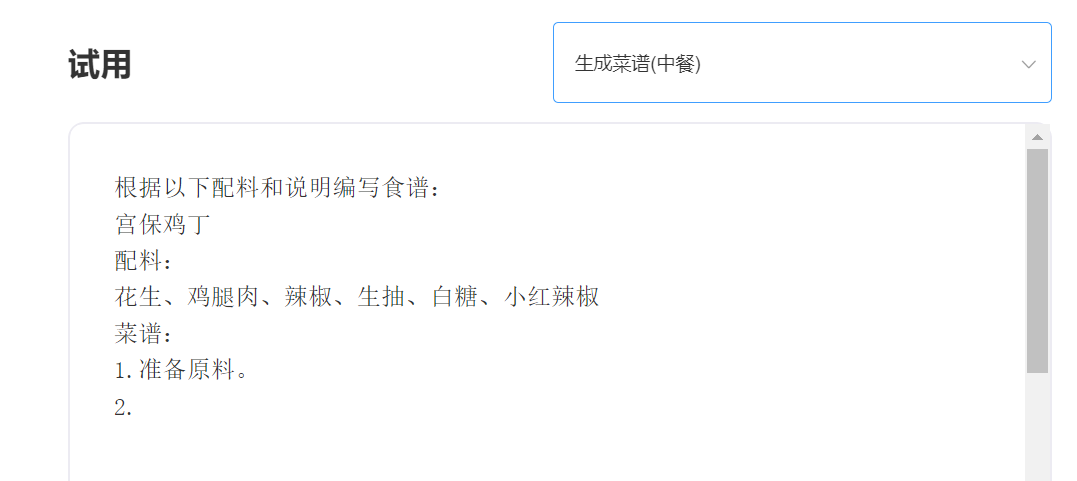
出力: 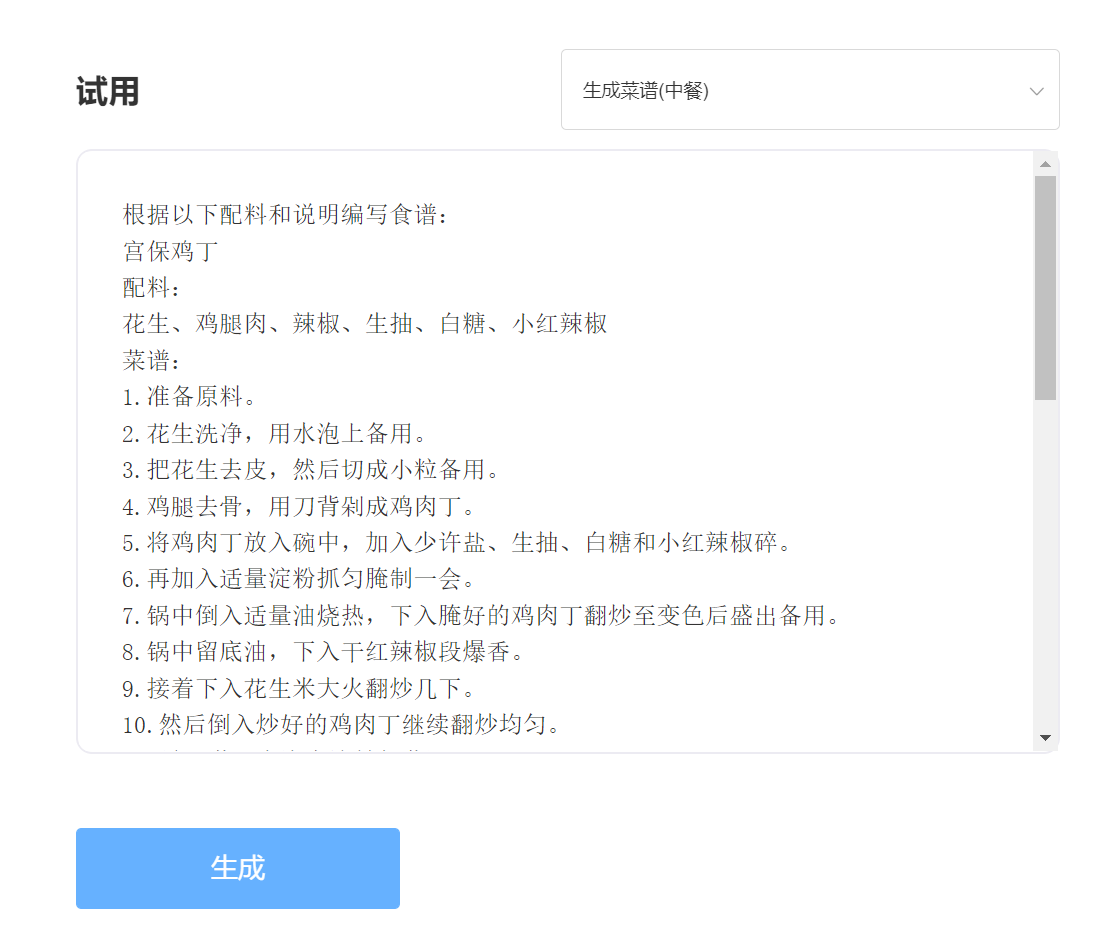
技術的利点1:30を超えるプロセスによるデータクリーニング
NLPテクノロジーの開発により、事前に訓練された大型モデルは、徐々に人工知能のコアテクノロジーの1つになりました。通常、事前に訓練された大規模なモデルでは、大規模なテキストを訓練する必要があり、オンラインテキストは自然にコーパスの最も重要なソースになります。トレーニングコーパスの品質は、間違いなくモデルの有効性に直接影響します。優れた機能を備えたモデルをトレーニングするために、特異点インテリジェンスは、データをクリーニングするときに30を超えるクリーニングプロセスを使用しました。絶妙な詳細は、優れたモデル効果を生み出しました。
技術的利点2:中国語を最適化して革新する中国のコーディング方法
トレーニング前の大きなモデルの分野では、それは常に英語のコミュニティに支配されており、中国語でのトレーニング前の大きなモデルの重要性は自明です。英語のピンインテキストとは異なり、事前に訓練された中国モデルの中国の入力方法は明らかに異なるはずです。特異性インテリジェンスは、中国語の特性に基づいたユニークな中国のエンコーディング方法を使用します。これは、中国語の習慣に沿ったものであり、モデルの理解をより助長する中国の辞書を再構築します。
--————————————————————————————————————————
推荐
transformers>=4.18.0
# -*- coding: utf-8 -*-
from transformers import GPT2LMHeadModel
from transformers import AutoTokenizer
from transformers import TextGenerationPipeline
# 以 SkyWork/SkyText(13billions) 为例,还有 SkyWork/SkyTextTiny(2.6billions) 可用, 期待使用
model = GPT2LMHeadModel . from_pretrained ( "SkyWork/SkyText" )
tokenizer = AutoTokenizer . from_pretrained ( "SkyWork/SkyText" , trust_remote_code = True )
text_generator = TextGenerationPipeline ( model , tokenizer , device = 0 )
input_str = "今天是个好天气"
max_new_tokens = 20
print ( text_generator ( input_str , max_new_tokens = max_new_tokens , do_sample = True )) MITライセンス